


開發者朋友們大家好:
這裏是 「RTE 開發者日報」 ,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@瓚an、@鮑勃
01 有話題的技術
1、Dexmal 原力靈機提出 GeoVLA,打破 2D 視覺枷鎖,讓機器人看懂三維世界
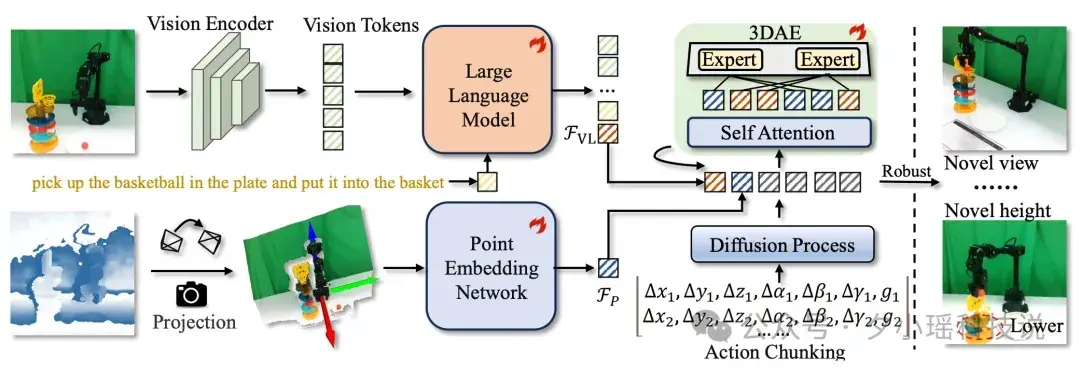
Dexmal 原力靈機提出 GeoVLA 框架,採用雙流架構在保留 VLM 語義理解能力的同時,引入專用的點雲嵌入網絡 PEN 和空間感知動作專家 3DAE,直接利用深度圖生成的點雲數據,賦予機器人真正的三維幾何感知能力。
GeoVLA 是一個全新的端到端框架,其流程包含三個關鍵組件的協同工作:
- 語義理解流:利用預訓練的 VLM(如 Prismatic-7B)處理 RGB 圖像和語言指令,提取融合後的視覺-語言特徵。
- 幾何感知流:利用點雲嵌入網絡 PEN 處理由深度圖轉換而來的點雲,獨立提取高精度的 3D 幾何特徵。
- 動作生成流:通過 3D 增強動作專家 3DAE 融合上述兩種特徵,生成精確的動作序列。
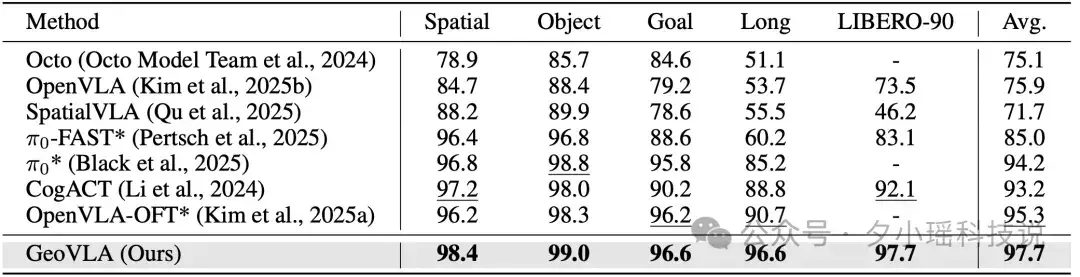
LIBERO 評測結果

ManiSkill2 評測結果

真機任務評測結果
GeoVLA 在仿真和真機實驗中均展現出對傳統 2D VLA 模型的壓倒性優勢,證明顯式 3D 表徵在複雜操作中的不可替代性。
論文名稱:
GeoVLA: Empowering 3D Representation in Vision-Language-Action Models
論文鏈接:
https://arxiv.org/html/2508.09071v2
項目主頁:
https://linsun449.github.io/GeoVLA/
(@Dexmal 原力靈機)
2、SAM-Audio 優化版發佈:剔除冗餘編碼器,消費級 GPU 環境下運行
針對 Meta 近期發佈的「SAM-Audio」音軌分割大模型,第三方開發者通過移除視覺引導相關的非核心組件,實現了顯著的顯存優化。該版本使 Large 模型擺脱了對 A100 等高端計算卡的依賴,在主流消費級遊戲卡上即可實現高精度的文本引導音頻分離。
- 顯存佔用下降約 90%:通過剔除用於視頻點擊引導的視覺編碼器和排序器,Large 版本的運行顯存從原始的 90GB 壓縮至約 10GB,Small 版本僅需 4-6GB VRAM。
- 全功能文本引導分離:保留了核心的 Text-Guided 能力,支持通過「Natural Language Prompt」精確描述提取目標,例如輸入「人聲」、「鼓聲」或「狗叫聲」即可實現特定聲源的剝離。
- 支持視頻音軌直接處理:原生支持視頻文件上傳,系統會自動提取音頻流並進行分割處理,同時提供「Stem Mixer」功能,支持實時對比原始音頻、提取分軌與殘留背景音。
- 工程化部署門檻清零:開發者封裝了「一鍵安裝包」,集成了環境配置與 GUI 界面,並支持波形可視化,使原本複雜的實驗室模型轉化為即插即用的生產力工具。
開源項目,提供一鍵安裝包,現已在 GitHub 發佈並支持在主流 Windows 消費級 GPU 環境下運行。
Github:
https://github.com/0x0funky/audioghost-ai
( @Github、@karminski3\@X)
3、上海聯合商湯發佈「雲宇星空」大模型,支持自然語言調用三維空間數據


近日,上海市規劃資源局聯合商湯大裝置正式上線全國規資領域首個基礎大模型「雲宇星空大模型」(專業版)。該模型通過 6000 億參數的行業深度訓練,將 AI 從簡單的文本問答推向複雜的時空決策智能,實現了規資業務從「靜態藍圖」向「數據驅動自適應調節」的工程化落地。
該模型具備五大核心能力:有問必答、智能調圖、自動統計、圖像識別與自動生成報告,覆蓋從知識檢索、空間分析到決策支撐的完整工作閉環。
- 6000 億參數「1+6」多模態架構:基於商湯底層能力構建,包含 1 個行業基座模型與 6 個垂類模型,通過「智能調度引擎」協調多智能體(agent)協作,支持對文本、圖像及空間數據的跨模態理解。
- 原生支持矢量數據庫與空間分析:區別於通用 LLM,該模型後台掛載矢量數據庫,支持自然語言調用二/三維空間數據,可實現「圖文聯動」。例如,通過指令直接調取滬派江南水鄉實景風貌或在地圖上高亮特定土地出讓地塊。
- 「坤輿經略」專屬語料庫確保 98% 準確率:由規資專家生產高質量問答與思維鏈(CoT),構建全國首個行業全貫通語料庫。實測顯示,其專有名詞準確率達 98%,人工問答點贊率約 95%,遠超通用模型在同等場景下約 40% 的得分。
- 數據「產品化」脱敏供給機制:針對政務數據敏感性,探索出一條按需供給、脱敏處理後產品化的路徑,打通了銀聯消費數據等外部因子,用於動態優化 15 分鐘生活圈等城市規劃指標。
目前專業版已部署於政務內網,嵌入「一廳八室」等核心業務系統;公眾版正在開發中,計劃通過智能接口形式向社會開放空間數據能力。
(@智東西)
02 有亮點的產品
1、比亞迪 x 火山引擎官宣座艙深度合作:豆包將融入 DiLink

據 36 氪報道,比亞迪與火山引擎在「FORCE 原動力大會」宣佈達成智能座艙深度合作,豆包大模型深度融入比亞迪 DiLink 系統,覆蓋語音交互、內容推薦與出行服務等多場景。
當前,座艙大模型合作已覆蓋比亞迪旗下仰望、騰勢、方程豹、王朝、海洋五大品牌的全量在售車型,並同步拓展至智能進入(全場景數字鑰匙)、座艙娛樂與智能語音等領域。
比亞迪集團高級副總裁、汽車新技術研究院院長楊冬生表示:「火山引擎和比亞迪在智能座艙領域的合作,從聯合開發到上車落地僅用時 4 個月,這不僅展現了雙方高效協同的『中國速度』,更是開放生態的活力。」
雙方在大會現場以騰勢 N8L 展示了基於豆包大模型的座艙體驗:車載語音助手可實時檢索互聯網動態資訊,並深度整合抖音集團生態的內容矩陣,以內容卡片與短視頻等多元形式提供問答服務,覆蓋從休閒聊天到專業查詢的需求。
除座艙合作外,火山引擎與字節跳動 Seed 團隊、比亞迪在鋰電池研發領域持續開展「AI for Science」聯合探索:通過聯合實驗室等形式,三方共建「AI + 高通量聯合實驗室」,圍繞快充、壽命與安全等課題推進動力電池技術進步。
( @APPSO)
2、消息稱 Meta 已啓動 Quest 4 研發,超輕量級頭顯 Quest Air 延期至後年
據外媒報道,Meta 已決定將其超輕量級頭顯 Quest Air 延期至 2027 年上半年,目前該公司已啓動定位遊戲場景的 Quest 4 頭顯研發工作。據介紹,Meta 這一 Quest Air 頭顯採用分體式設計,配備獨立計算單元,原本計劃明年(2026 年)推出,主要面向混合現實辦公、觀影等及其他以坐姿為主的使用場景,但如今被推遲發佈,這是因為 Meta 計劃為團隊「留出更多喘息空間,把細節打磨到位」。
此外,外媒透露 Meta 已正式啓動下一代主線頭顯 Quest 4 的研發工作,該產品將聚焦沉浸式遊戲體驗,相較 Quest 3 帶來「幅度明顯的升級」,同時還將顯著降低產品製造成本。這暗示 Meta 可能逐步放棄長期以來通過補貼壓低硬件售價的策略,轉而推動旗下 Reality Labs 虛擬現實業務向盈利方向過渡。
需要指出的是,Meta 的硬件路線圖向來變化頻繁,在產品正式發佈前,公司內部往往會反覆立項、調整甚至取消項目。只有當某款設備真正接近量產和上市時,相關信息才會逐漸變得清晰。在此之前,Quest Air / Quest 4 兩款產品的具體規格及上市時間,都存在大幅變更的可能性。
(@IT 之家)
3、2025 兒童 AI 硬件圖譜:290 億市場規模下的多模態智能體演進與高退貨率博弈
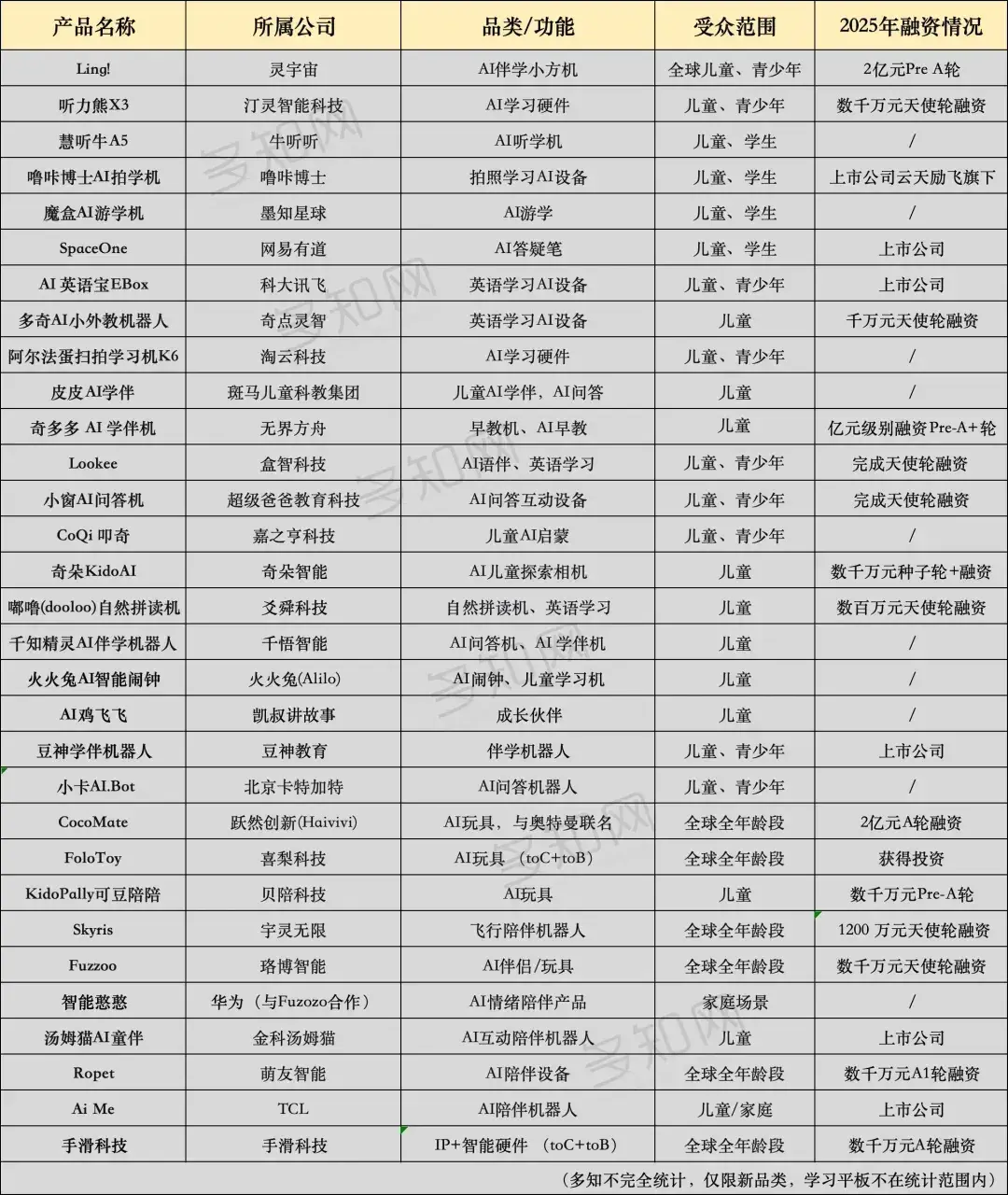
2025 年兒童 AI 硬件賽道爆發,超 15 家公司融資,30 餘款新品面市。市場核心正從傳統的「內置語音盒」向具備多模態交互能力的「智能體」演進,但在供應鏈極速迭代的同時,行業仍面臨用户滿意度低及部分產品退貨率高達 40% 的技術與商業化瓶頸。
- 研發週期極端分化:深圳供應鏈體系下,基於公版方案的模仿款產品僅需 1 個月即可面市;而深度集成的 AI 硬件產品(含自研模型策略與軟硬結合架構)研發週期普遍在 1 到 1.5 年。
- 交互邏輯分歧:行業出現兩種主流技術路線。一種是以「Lookee」為代表的「無屏純語音」方案,旨在降低用眼負擔;另一種是以「Ling!小方機」為代表的「屏幕作為表達器官」方案,屏幕不用於內容消費,而是配合攝像頭進行多模態物理世界識別(World to Classroom)。
- 高退貨率與留存挑戰:電商平台數據顯示,AI 玩具類產品滿意度不足 21%,部分品牌退貨率在 40%-50% 波動。原因在於單純「情緒價值」的交互頻次難以維持,功能性(如英語口語、百科問答)正成為抗退貨的核心指標。
- 成本結構與訂閲制轉型:由於 LLM 調用產生持續 API 費用,國內硬件商正試圖借鑑海外市場經驗,將單純的硬件銷售模式轉向「硬件+訂閲制」。目前海外用户對訂閲制接受度較高,國內市場仍處於成本攤薄的探索期。
- IP 與內容壁壘:以「躍然創新」為代表的廠商通過引入「奧特曼」、「小豬佩奇」等頂級 IP 授權,利用 IP 溢價抵消硬件同質化競爭,將 AI 交互視為 IP 資產的價值延伸。
目前已有超 30 款產品在售或處於眾籌階段,價格跨度從百元以下(簡單語音盒)到 1500 元以上(多模態機器人),主要通過電商渠道及達人直播驅動銷售。
(@多知)
4、混元支持 ETC 首款 AI 智能體,有問必答可執行的暢行搭子
最近,基於混元大模型,騰訊雲和安徽驛路微行科技有限公司聯合推出 ETC「助手 Agent」,只需通過文本或語音發出指令,智能體即可精準理解並高效執行。
官方數據顯示,自今年 4 月啓動內測以來,該智能體已服務超百萬用户,問答準確率達 95%,問題解決率達 90%。
ETC 助手基於騰訊混元大模型,創新性地融合多模態交互技術,讓用户不僅可以通過傳統的文本輸入方式提問,更可體驗 AI 增強的語音交互方式獲取 ETC 服務。
在多個應用場景中,「助手 Agent」更像是一位圍繞用户真正所需,有問必答、可諮詢可執行的「暢行搭子」。
無論是 「OBU 設備如何安裝」 的基礎諮詢,還是 「幫我查通行記錄、開發票」 的複合需求,用户通過文本或語音發出指令,智能體即可精準理解並高效執行。在出行場景中,用户只需對助手 Agent 説出:「開啓暢行模式」,智能體調高設備靈敏度,獲得設備快識別、高速快抬杆的暢快通行體驗。
在感知層,以智能硬件為切入點,「助手 Agent」可通過 105 種狀態監測算法實時採集設備運行數據,並藉助語音交互與關鍵狀態播報,讓「服務找人」有據可依。
在智能核心層,「助手 Agent」引入了涵蓋行業規則、服務流程的通用知識庫,並基於騰訊混元等底層大模型,構建了穩定可信的 ETC 基礎服務能力。
在此基礎上,「助手 Agent」在執行層,既可作為行業百科答疑解惑,也能作為服務專家提供一站式支持,更可實現語音直接控制設備,達成「所説即所得」的自然交互。
(@騰訊混元)
03 有態度的觀點
1、劉知遠:2030—2035 年可實現 AGI

據騰訊科技報道,清華大學計算機系副教授劉知遠及其團隊的研究登上《自然 · 機器智能》封面,正式提出用於量化大模型「能力密度」的「密度法則」(Densing Law)。
基於對 51 個主流大模型的回測,該研究指出 2023 年至 2025 年間,大模型的智能密度以每 3.5 個月翻倍的速度加速演進,意味着每 100 天即可用一半參數量達到當前最優模型的相當性能,成本也隨之減半。
劉知遠直言,若一家模型公司發佈新品後「3 至 6 個月無法收回成本」,商業模式將難以為繼,因為後來者很快能以四分之一的資源實現同等能力。
「用 AI 製造 AI」被其視為 AI 時代生產力的標誌與產業突圍方向。 劉知遠將「密度法則」與「規模法則」(Scaling Law)視為「硬幣的兩面」:
- 前者強調通過架構、數據治理與學習方法的持續創新,用更小的參數承載更強能力;
- 後者則刻畫參數規模擴張帶來的能力持續上升。
他指出,在 ChatGPT 引發全球投入後,密度翻倍週期由約 5 個月收縮至約 3.5 個月,速度遠快於摩爾定律的 18 個月節奏。這一趨勢使雲端 API 服務競爭極度激烈,最終可能只剩擁有海量用户與強大技術迭代能力的頭部廠商;與此同時,約束條件清晰、對功耗與響應時延敏感的「端側智能」將成為創業公司更具確定性的機會窗口。
關於多模態進展,劉知遠將 Google 最新發布的 Gemini 3 視為里程碑:在圖像生成中對文字的高一致性與可控性體現了模型對世界理解與生成過程的「逐層細化」。
他推測該能力不僅依賴 Diffusion,也很可能融入自迴歸思想,從而實現生成一致性的新範式;這也印證了密度法則的外延——只要某種智能能力可被實現,未來一定能在更小的終端上運行,如手機、PC 或車載芯片。
他對 AI 的長期影響持樂觀態度,認為 2030—2035 年可實現全球普惠的 AGI,互聯網的主體將不再只是人類,還會有數不盡的智能體;雖然訓練廠商會收斂,但「AGI 發展還沒收斂」,推理算力需求將爆炸式增長,人機協同將成為常態。
( @APPSO)


閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

作者提示:個人觀點,僅供參考