


開發者朋友們大家好:
這裏是 「RTE 開發者日報」,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@瓚an、@鮑勃**
01 有話題的技術
1、字節跳動 Seed 推出 GR-RL,機器人首次完成真機穿鞋帶

昨天,字節跳動 Seed Research 團隊正式發佈最新研究成果 GR-RL,在真實機器人平台上首次實現了「連續為整隻鞋穿鞋帶」的複雜操作。
字節跳動稱,這一突破標誌着視覺-語言-動作(VLA)模型在精細靈巧任務上的能力邊界被顯著拓展。
團隊指出,主流模仿學習存在兩大缺陷:人類演示數據的「次優性」以及訓練與推理之間的「執行錯位」,導致模型在毫米級精度任務中頻繁失敗。
為此,Seed 團隊選擇真機強化學習路徑,提出了多階段訓練框架,包括離線數據篩選、數據增強以及在線強化學習。
在雙臂機器人 ByteMini-v2 上,GR-RL 將穿鞋帶任務成功率從監督學習基線 GR-3 的 45.7% 提升至 83.3%,失敗率減少近 70%。
其中,數據過濾、鏡像增強和在線強化學習均對性能提升貢獻顯著。實驗中,模型展現出類似人類的「糾錯智能」,在鞋帶滑落或擺放位置不佳時能主動調整並重試,體現了對任務物理邏輯的理解,而非單純軌跡記憶。
團隊認為,強化學習經驗應進一步蒸餾回基礎 VLA 模型,以構建兼具高精度操作與強大泛化能力的通用策略。
論文鏈接:
https://arxiv.org/abs/2512.01801
項目主頁:
https://seed.bytedance.com/gr_rl
( @APPSO)
2、AWS 發佈 Amazon Nova 2 Omni 預覽版:行業首個多模態推理與圖像生成一體化模型
AWS 宣佈推出 Amazon Nova 2 Omni 的預覽版,這是一款行業首創的、集成了多模態推理與圖像生成能力的通用模型。該模型能夠處理文本、圖像、視頻和語音輸入,並生成文本和圖像輸出,極大地簡化了多模態 AI 應用的開發和管理。
該模型支持 100 萬 token 的上下文窗口,文本處理支持 200+ 語言,語音輸入支持 10 種語言。能夠通過自然語言生成和編輯高質量圖像,實現角色一致性、圖像內文本渲染及對象/背景修改。
該模型可進行多説話人對話的轉錄、翻譯和摘要。具備靈活的推理控制,確保在不同用例下的性能、準確性和成本效益。 可用於營銷內容創作、客户支持電話轉錄、視頻分析以及帶視覺輔助的文檔生成等多樣化任務。
Amazon Nova 2 Omni 目前處於預覽階段,Nova Forge 客户可申請早期訪問。
https://aws.amazon.com/about-aws/whats-new/2025/12/amazon-nov...
(@AWS News Blog)
3、Amazon Nova 2 Sonic 發佈:端到端、多語言切換、跨模態交互
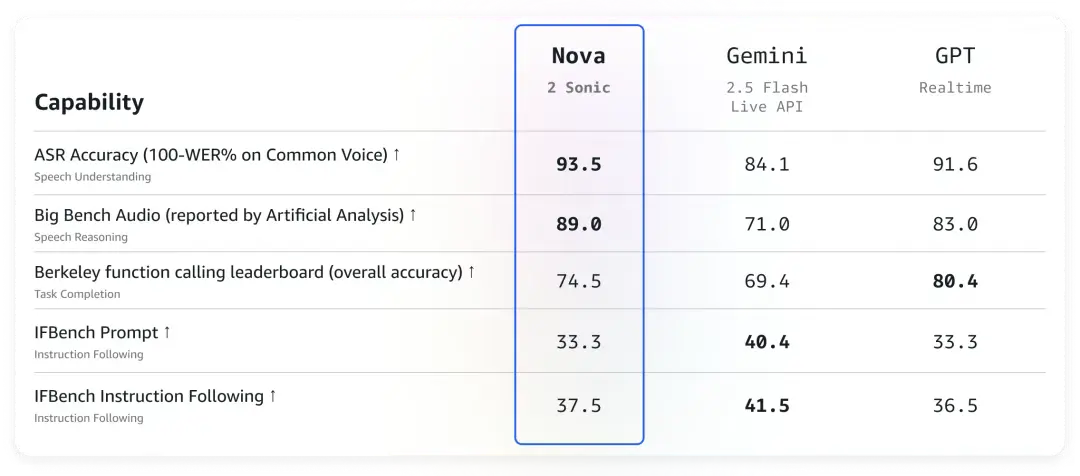
AWS 發佈了 Amazon Bedrock 的新一代語音到語音(speech-to-speech)基礎模型 Amazon Nova 2 Sonic。該模型在對話質量、成本效益和語音理解方面實現了行業領先,能夠為開發者構建更自然、更具人情味的語音應用程序,實現突破性的實時語音交互體驗。
- 突破性對話質量: Nova 2 Sonic 在保持對話連貫性和人類偏好方面表現出色,能夠自然處理用户打斷,並提供富有表現力的男性和女性聲音,支持多語言的流暢切換(code-switching)。
- 增強的智能與可靠性: 該模型在 Big Bench Audio、BFCL 和 ComplexFuncBench 等關鍵評估基準上表現優異,展現了更強的推理能力、更準確的功能調用和更復雜的任務處理能力。ASR 準確性也得到提升,能更好地處理數字、短語及 8KHz 電話語音。
- 多語言與 Polyglot 聲音: 除了原有的語言,Nova 2 Sonic 新增了葡萄牙語和印地語支持。其創新的「Polyglot Voices」功能允許同一聲音在同一對話中無縫切換語言,極大地簡化了為全球用户構建多語言應用。
- 跨模態交互: 用户可以在同一會話中混合使用文本和語音輸入,例如先輸入文本,再通過語音進行迴應,實現更靈活的交互方式。
- 高級多智能體能力: Nova 2 Sonic 支持異步工具調用,允許 AI 在後台運行外部工具或服務的同時,繼續響應用户輸入,從而處理更復雜的多步驟任務,保持對話的流暢性和響應性。
- 深度集成: 模型已直接集成到 Amazon Connect、Vonage、Twilio 等主流電話服務提供商以及 LiveKit 和 Pipecat 等媒體平台,簡化了在現有呼叫中心基礎設施或新電話服務中的部署。
Amazon Nova 2 Sonic 已通過 Amazon Bedrock 提供通用可用性,模型 ID 為 amazon.nova-2-sonic-v1:0。該模型在 US East (N。 Virginia), US West (Oregon), Asia Pacific (Tokyo), 和 Europe (Stockholm) AWS 區域可用。定價與原 Nova Sonic 保持一致。
(@AWS News Blog)
4、Kyutai 團隊創立新語音 AI 公司 Gradium,種子輪融資 7000 萬美元

初創公司 Gradium 今日宣佈成功完成 7000 萬美元種子輪融資,投資方包括前谷歌首席執行官埃裏克·施密特、法國電信億萬富翁澤維爾·尼爾和 Yann LeCun 等投資者。
正式推出同名核心引擎 Gradium 是一種開創性的「音頻語言模型」(Audio LLM),它將語音的生成、轉錄、轉換和對話統一到一個單一的神經網絡架構中。該模型旨在實現超真實、富有情感表達、低延遲且高效可擴展的語音交互。最終使自然、實時的語音成為人機交互的默認界面。
其創始團隊與非營利實驗室 Kyutai 有着深厚淵源,該實驗室在多模態 LLM 領域取得了顯著進展,包括在 2024 年開源了實時對話模型 Moshi。
首席執行官 Neil Zeghidour 已退出 Kyutai 的日常工作,但將加入其董事會。他表示這家非營利組織仍致力於開發開源 AI 模型和研究的使命。這家初創公司目前有八名員工。
公司由四位來自 Meta 和 Google DeepMind 的生成式音頻領域先驅者聯合創立。他們不僅在神經網絡音頻編解碼器和音頻語言模型等方面做出開創性貢獻,還共同創建了非營利實驗室 Kyutai。
目前 Gradium 已支持英語、法語、德語、西班牙語和葡萄牙語的實時轉錄和合成功能。其技術已應用於醫療、客户支持、市場研究中的語音智能體,以及遊戲 NPC 和數字廣告中的虛擬形象。
開發者和企業可以通過訪問 gradium.ai 探索 Demo、試用 API。
體驗 demo:https://gradium.ai/#demo
(@Gradium Blog、@Bloomberg)
02 有亮點的產品
1、Hedy AI 推出「Topic Insights」,首創跨會話會議智能技術
Hedy AI 發佈了其最新功能「Topic Insights」,這是行業內首個能夠跨多個相關會議分析模式的技術。該功能解決了現有會議 AI 平台在處理連續性對話方面的短板,通過理解討論如何隨時間演變,提供了真正的對話連續性,從而幫助專業人士更好地跟蹤決策和進展。
- 跨會話模式識別: 「Topic Insights」能夠識別反覆出現的主題,追蹤不斷髮展的討論,並突出在無限相關對話中利益相關者立場的變動。
- 智能會議準備: 在開始新會議時,用户將收到 AI 生成的準備筆記,其中包含之前會議中已做出的承諾、待解決的問題以及未解決的事項。
- 情境感知分析: 該智能體能自動識別對話類型,併為商業會議、醫療諮詢、學術講座、面試等九種不同專業場景應用專門的分析框架。
- 行業預測: 預計到 2030 年,全球會議智能市場將達到 136 億美元,而 67% 的專業人士認為會議準備是一項主要的生產力挑戰,凸顯了該功能的重要性。
- 技術創新: 該功能得益於突破性的對話 AI 架構,包括保持會話上下文的「Contextual Memory Architecture」和零幻覺設計,確保所有洞察均基於實際內容。
「Topic Insights」已立即面向所有 Hedy Pro 訂閲用户推出,支持 iOS、Android、macOS 和 Windows 平台。該功能包含在 Hedy Pro 訂閲中,價格為每月 9.99 美元,每年 69.99 美元,或一次性終身訪問 199 美元。此外,還提供每月 5 小時使用量的免費套餐。
(@GlobeNewswire)
2、AI 情感交互枱燈「Ongo」發佈,玩具總動員編劇參與設計
昨天,互動機器人公司 InteractionLabs 宣佈正式發佈 AI 枱燈 Ongo,定位為「有生命的枱燈」,除具備照明功能外,還能通過人工智能與用户進行情感交互。
該產品由 CEO Karim Rkha Chaham 與 CTO Julien Ajdenbaum 共同開發,創意總監為曾獲奧斯卡提名的玩具總動員編劇 Alec Sokolow。
Ongo 的設計強調情感智能與環境感知。它能夠識別用户的面部表情,感知工作節奏,並通過光線與動作進行迴應,幫助用户在專注時自動調暗燈光,營造安靜氛圍。
此外,設備捕捉到的視覺數據僅在端側處理,確保隱私安全,並配備可磁吸的遮光鏡片以提供完全的隱私模式。
在功能層面,Ongo 的交互邏輯由故事化設計驅動,旨在減少用户對屏幕的依賴,成為桌面上的情感夥伴。有開發者提出,未來 Ongo 或可結合健康監測模型,實現水分與血糖水平的檢測。
發售不久後,CEO Karim 在 X 上宣佈,首批 100 台 Ongo 已售罄,並將開放新的購買名額。
( @APPSO)
03 有態度的觀點
1、英偉達 CFO 否認「AI 泡沫」論
NVIDIA 靠 AI 成為全球首個 5 萬億美元市值的科技巨頭,儘管現在股價比高峯跌落了 10%,也引發了 AI 泡沫的爭議,但 NVIDIA 對此堅決否認。
該公司 CFO Colette Kress 表示,她並不認為人工智能領域存在泡沫,相反的是,她預計未來市場將發生重大轉型。
預計到 2030 年,在對加速計算需求不斷增長的推動下,數據中心基礎設施規模可能達到 3 萬億至 4 萬億美元。
Colette Kress 還提到,目前出貨的大多數 NVIDIA AI 芯片都是用於構建新的數據中心基礎設施,而不是替換現有設備。
她還表示,到 2026 年,NVIDIA 手中 Blackwell 和 Rubin 兩款 GPU 芯片訂單額高達 5000 億美元(超過 3.5 萬億元)。
而且這些訂單還不包括 NVIDIA 目前正就 OpenAI 下一階段協議所做的任何工作,Colette Kress 稱 NVIDIA 與 OpenAI 完成一份最終協議,OpenAI 正繼續沿着他們的道路前進,NVIDIA 相信與他們的合作永遠不會停止。
(@AI 數字經濟)
04 社區黑板報
招聘、項目分享、求助……任何你想和社區分享的信息,請聯繫我們投稿。(加微信 creators2022,備註「社區黑板報」)
1、活動推薦:Interspeech 2026 丨首屆音頻推理挑戰賽
由來自上海交通大學、南洋理工大學、倫敦瑪麗女王大學、卡內基梅隆大學、英偉達、阿里巴巴、微軟的研究者們聯合舉辦的 Interspeech 2026 音頻推理挑戰賽現已開啓!本次挑戰賽旨在解決當前大型音頻語言模型(LALM)推理能力有限且不穩定的問題,聚焦於複雜聲學場景下的思維鏈(CoT)推理能力。挑戰賽設有以下兩個賽道:
- 單模型賽道 (Single Model Track): 聚焦於基於開源模型進行數據創新與訓練創新,提升模型內在的推理能力。
- 智能體賽道 (Agent Track): 聚焦於基於開源模型的系統級編排與工具調用能力。
挑戰賽將會同時測評模型結果和推理過程的準確性與邏輯性,希望本次挑戰能夠激發音頻推理領域新的模型創新和系統創新。所有參賽隊伍均可以在 Interspeech 2026 主會提交系統報告或研究論文,歡迎大家報名參加,相聚悉尼!
賽事官網:https://audio-reasoning-challenge.github.io/
請注意報名截止時間是 2026 年 1 月 15 日,只有成功註冊的隊伍才可以後續在 leaderboard 開啓後提交。



閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與「RTE 開發者日報」內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

作者提示: 個人觀點,僅供參考