


開發者朋友們大家好:
這裏是 「RTE 開發者日報」 ,每天和大家一起看新聞、聊八卦。我們的社區編輯團隊會整理分享 RTE(Real-Time Engagement) 領域內「有話題的技術」、「有亮點的產品」、「有思考的文章」、「有態度的觀點」、「有看點的活動」,但內容僅代表編輯的個人觀點,歡迎大家留言、跟帖、討論。
本期編輯:@瓚an、@鮑勃
01 有話題的技術
1、DeepSeek V3.2 正式版發佈:推理比肩 GPT-5,首推 Speciale 版本拿下奧數金牌
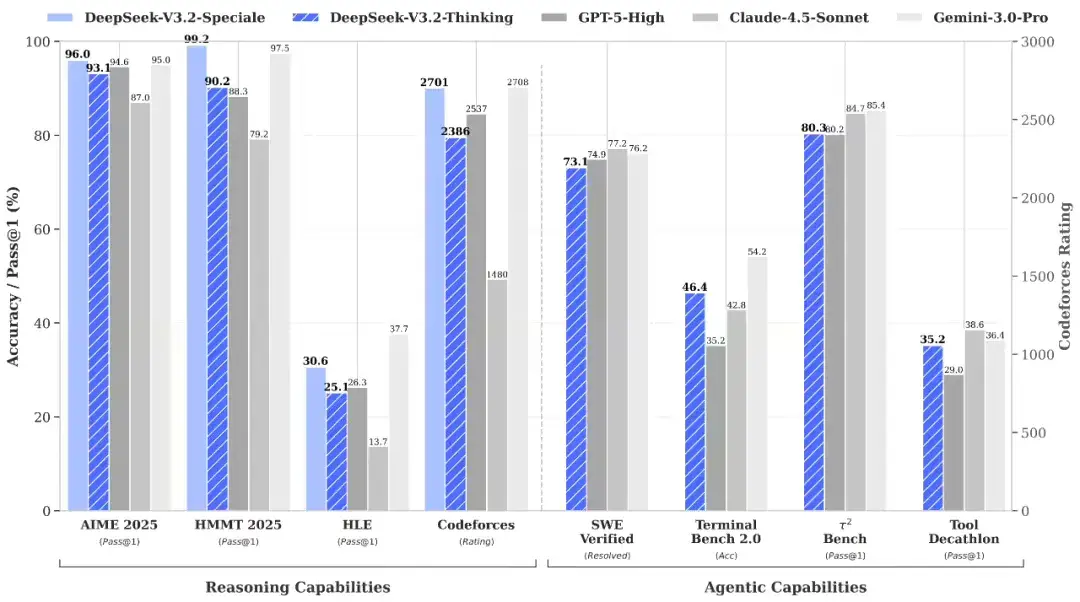
昨天,深度求索 DeepSeek 正式發佈了 V3.2 系列模型,包括標準版「DeepSeek-V3.2」與增強版「DeepSeek-V3.2-Speciale」。
官方測試顯示,該模型在公開推理類 Benchmark 中達到了 GPT-5 水平,僅略低於 Gemini-3.0-Pro。同時,相比 Kimi-K2-Thinking,V3.2 輸出更為簡潔,大幅降低了計算開銷與用户等待時間。
DeepSeek-V3.2 還首次實現了「思考模式下的工具調用」,通過大規模 Agent 訓練數據合成方法,顯著提升了模型的泛化能力。這一功能使模型能夠在複雜任務中多輪思考並調用工具,最終給出更詳盡準確的回答。
官方表示,在高度複雜任務上,Speciale 模型大幅優於標準版本,但消耗的 Tokens 也顯著更多,成本更高。目前,DeepSeek-V3.2-Speciale 僅供研究使用,不支持工具調用,暫未針對日常對話與寫作任務進行專項優化。
DeepSeek-V3.2 的思考模式也增加了對 Claude Code 的支持,用户可以通過將模型名改為 deepseek-reasoner,或在 Claude Code CLI 中按 Tab 鍵開啓思考模式進行使用。但需要注意的是,思考模式未充分適配 Cline、RooCode 等使用非標準工具調用的組件,官方建議用户在使用此類組件時繼續使用非思考模式。
技術報告:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2/resolv...
DeepSeek V3.2 開源地址:
DeepSeek-V3.2
HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2
ModelScope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2
DeepSeek-V3.2-Speciale
HuggingFace:
https://huggingface.co/deepseek-ai/DeepSeek-V3.2-Speciale
ModelScope:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V3.2-Speciale
(@IT 之家)
2、Microsoft 研究揭示:空間音頻可將 AI 同聲傳譯理解度翻倍

Microsoft 的一項最新研究指出,在 AI 實時語音翻譯中,使用「空間音頻」(Spatial Audio)技術,即將翻譯語音與發言者在屏幕上的位置相匹配,可將聽眾的理解度提升一倍以上。這一發現為各大視頻會議平台提供了一個技術上可行且效果顯著的優化方向,有望極大改善跨語言協作的溝通體驗。
-
技術突破:理解度翻倍,定位更清晰
研究表明,當翻譯語音來自與發言者屏幕位置匹配的左/右聲道時,聽眾正確回答理解性問題的機率是傳統(非空間)音頻的兩倍以上。該技術在多人快速輪流發言時效果尤其顯著,能有效幫助用户辨別「誰説了什麼」。
-
體驗對比:空間音頻完勝單耳收聽
與會者普遍認為「空間音頻」模式「更容易理解」且「能清晰分辨發言者」。與之形成鮮明對比的是「單耳翻譯」(Monaural)模式,它產生了最低的理解度得分,並被用户評價為「令人困惑」和「容易疲勞」。
-
最佳實踐:保留音色,平衡音量
研究還發現兩個關鍵的 UX 細節:1)保留不同發言者獨特的聲音音色有助於區分人物;2)調低而非完全靜音原始語音,可以在減少干擾的同時,保留髮言者的身份線索,從而創造最佳體驗。
-
平台建議:技術可行且影響巨大
研究人員建議,會議平台應將翻譯音頻與發言者的屏幕位置對齊,並提供一個「原始語音 ↔ 翻譯語音」的平衡滑塊供用户調節。鑑於大多數現代耳機和設備已支持「空間音頻」,這一改進在技術上是完全可行的。
論文地址:
https://arxiv.org/pdf/2511.09525
( @Slator)
3、ElevenLabs 進軍韓國,打造亞洲語音 AI 中心

英國人工智能音頻公司 ElevenLabs 正式宣佈進軍韓國市場,並計劃在韓國建立其亞洲語音 AI 中心。該公司將推出本地化的韓語語音模型,並提供名人語音授權,以推動 K-content(韓流內容)在全球的傳播。
語音 AI 技術: ElevenLabs 擁有先進的基於 AI 的 Text-to-Speech(TTS)技術,能夠將文本實時轉化為人類語音,並支持語音克隆、AI 配音和音效生成。
韓語本地化: 為進軍韓國市場,ElevenLabs 投入大量資源,組建了專門團隊並聘請專家,開發了能夠準確捕捉和渲染韓語特有發音、語調和情感的模型。
K-content 全球化: ElevenLabs 的「Eleven v3」模型支持超過 70 種語言,能夠完美還原原始情感和細微差別,旨在幫助克服 K-content(如 K-pop 和 K-drama)的語言障礙,並計劃與韓國名人合作推出 AI 配音產品。
企業級應用: 該技術已獲得 5000 萬月活躍用户,75% 的 Fortune 500 公司是其客户,並在韓國吸引了 Naver、LG Uplus、Krafton Inc。 等領先企業使用。Nvidia、Deutsche Telekom 等公司也已投資 ElevenLabs。
亞洲橋頭堡: ElevenLabs 選擇韓國作為其進入亞洲市場的關鍵橋頭堡,看好韓國快速增長的 AI 市場、對創新的快速接納能力以及全球領先的內容影響力。
ElevenLabs 已在韓國設立了第六個辦事處,並立即開始本地化韓語語音模型的開發和應用。公司計劃將該技術應用於韓國的內容和遊戲產業,並改進客户服務中心的 AI 體驗。
(@CHOSUNBIZ)
02 有亮點的產品
1、豆包手機助手發佈技術預覽版,首款工程機亮相,現已售罄
昨天,豆包宣佈其全新手機 AI 助手「豆包手機助手」以技術預覽版的形式正式亮相。
據悉,字節跳動與努比亞為這款工程機的首銷備貨量為 3 萬台。**目前,購買頁面顯示「已售罄」,購買需預約等待下次開售。
官方強調,該機型僅為技術預覽用途,並不承諾功能的成熟度,普通消費者需謹慎選擇。值得注意的是,豆包官方還明確表示不打算做手機。這款工程樣機的具體配置如下: 配備高通驍龍 8 至尊版處理器;但是搭載 6.78 英寸 1264 × 2800 LTPO 屏幕;後置三顆 50MP 攝像頭,涵蓋主攝、超廣角與長焦,均支持光學防抖;前置具備自動對焦功能;提供 16GB + 512GB 存儲組合; 電池容量為 6000mAh,支持 90W 有線快充、15W 無線充電及 5W 反向充電;機身重量約 212g,支持超聲波屏下指紋、NFC、紅外、USB 3.2Gen1,並配備 5 麥克風與雙揚聲器。
上述消息公佈後,中興通訊股價昨天上午強勢漲停,報 46.30 元,成交金額超 139 億,封單金額超 40 億元,其 H 股也漲超 11%。
( @APPSO)
2、可靈 AI 推出全球首個統一多模態視頻引擎 O1

昨天晚間,可靈視頻正式上線 O1 模型,宣稱這是全球首個統一多模態視頻大模型,定位為全能創作引擎,旨在通過單一輸入框實現跨模態任務的無縫融合,打破傳統視頻生成的功能割裂問題。
據介紹,該模型引入 MVL(多模態視覺語言)交互架構,並結合 Chain-of-thought 技術,賦予系統更強的常識推理與事件推演能力。
官方表示,O1 模型能夠在同一界面下處理照片、視頻與文字等多模態輸入,用户僅需通過簡單對話即可完成複雜的創作編輯。
在功能層面,O1 模型支持多主體視角構建與自由組合,確保視頻主體在不同鏡頭間保持一致性與穩定性。
同時,用户可靈活組合多種技能,一次生成多樣化創意變化,並可自由設定 3 至 10 秒的生成時長,以掌控敍事節奏。
此外,可靈 AI 宣佈自 12 月 1 日起至 12 月 14 日,將舉辦為期 5 天的「全能靈感周」,並推出會員年卡限時 6.6 折優惠活動,以吸引更多創作者體驗該新模型。
( @APPSO)
3、米哈遊聯合創始推出「貓貓」互動娛樂 AI 模型
據 36 氪報道,米哈遊聯合創始人蔡浩宇在美國創立的 AI 公司 Anuttacon 近日上線了一款全新 AI 聊天大模型「AnuNeko」。
該產品以黑貓為默認形象,強調個性化與互動性,區別於傳統的工具型 AI,更像是具備情緒與獨立思考的「夥伴」。
「AnuNeko」的註冊商標已於 2025 年 9 月 29 日提交美國 USPTO,涵蓋軟件、AI 角色與娛樂等多個領域。用户可選擇兩種不同風格的虛擬貓角色:回答犀利的「異國短毛貓」Exotic Shorthair 與更温和的「橘貓」Orange Cat。

報道認為,蔡浩宇的目標並非僅限於推出一款聊天機器人,而是藉此探索 AI 在遊戲生態中的應用。
在今年 8 月,Anuttacon 曾發佈實驗性 AI 遊戲《羣星低語》,玩家通過與 AI 角色對話推動劇情發展,體現了高自由度與 AI 自主性。此次「AnuNeko」的上線,或許是進一步測試 AI 在互動娛樂中的潛力。
在全球範圍內,Google、育碧、字節跳動等企業也在佈局 AI + 遊戲:
- Google DeepMind 推出的 SIMA 2 能在 3D 虛擬世界中自主學習與推理;
- 字節的「Lumine」在《原神》中展現出跨場景泛化能力;
- 育碧的 NEO NPCs 則已能實時分析玩家語音並制定策略。這些案例顯示,AI 正逐步成為遊戲產業的核心驅動力。
報道指出,與傳統強調執行力的智能體不同,Anuttacon 的策略是讓 AI 更「像人」,具備情緒與個性。這一方向或許能為未來互動娛樂帶來新的突破:真正吸引玩家的並非完美答案,而是充滿生命力的對話與陪伴。
https://anuneko.com
( @APPSO)
03 有態度的觀點
1、馬斯克最新預言:AI 可在三年內終結美國「債務危機」
12 月 1 日消息,自 2022 年 ChatGPT 問世後,AI 迅速被視為醫療、農業、能源等各領域的萬能工具。不過馬斯克的看法卻更進一步,他認為 AI 與機器人技術才是解決美國債務危機的關鍵。在日前播出的一檔播客節目中,馬斯克表示:「美國債務問題只有一個出口,那就是 AI。」
他補充道:「擺脱美國日益加深的財政漏洞的唯一途徑是由 AI 和機器人驅動的生產力提高。這幾乎是解決美國債務危機的唯一辦法,但這可能會導致嚴重的通貨緊縮。」美國財政部數據顯示,截至 11 月 26 日,美國國債已經達到 38.34 萬億美元,是十年前的兩倍多。
馬斯克進一步指出,AI 未將生產力提高到足以推動經濟產出增速超過通貨膨脹的程度,但這種情況即將改變。他補充稱:「估計三年或更短的時間內,商品和服務產出將超過通貨膨脹率。」
(@雷鋒網 、@快科技)
04 Real-Time AI Demo
1、在 Mac 上離線運行 Qwen3omni-30b,實現語音對話,延遲 3~5 秒
來自 X 上的開發者 ZachBladi(@hellopanghe):
隆重推出 Joi:一款專為 Mac 設計的原生應用,提供端到端的音頻聊天體驗,一切運行在本地!🍎🎙
在 M3 Max (36GB) 上運行 Qwen3omni-30b-a3b-instruct (4-bit):⚡️ 「思考」速度:約 30 token/秒 🔊 首音頻響應時間:3-5 秒
私密、沉浸、無審查。
https://github.com/hellopahe/joi
( @hellopanghe\@X)
05 社區黑板報
招聘、項目分享、求助……任何你想和社區分享的信息,請聯繫我們投稿。(加微信 creators2022,備註「社區黑板報」)
1、 活動推薦:AI+3D 場景合作交流會,北京,12 月 4 日



閲讀更多 Voice Agent 學習筆記:瞭解最懂 AI 語音的頭腦都在思考什麼
寫在最後:
我們歡迎更多的小夥伴參與 「RTE 開發者日報」 內容的共創,感興趣的朋友請通過開發者社區或公眾號留言聯繫,記得報暗號「共創」。
對於任何反饋(包括但不限於內容上、形式上)我們不勝感激、並有小驚喜回饋,例如你希望從日報中看到哪些內容;自己推薦的信源、項目、話題、活動等;或者列舉幾個你喜歡看、平時常看的內容渠道;內容排版或呈現形式上有哪些可以改進的地方等。

作者提示: 個人觀點,僅供參考