

大型代碼編譯時的“數小時等待”、海量數據分析中的“內存溢出”、AI模型訓練時的“顯卡算力不足”——這些高性能計算場景下的痛點,長期困擾着企業研發團隊與科研人員。傳統解決方案需購置高性能工作站(單台成本超10萬元)或搭建本地集羣(維護成本每年5萬元以上),不僅初期投入高,還面臨“算力閒置浪費”“硬件更新迭代快”等問題。雲電腦憑藉“彈性算力分配”“按需付費”“專業硬件集羣支撐”的特性,成為高性能計算的高性價比替代方案,可將大型代碼編譯時間縮短80%、數據分析效率提升10倍、AI模型訓練週期壓縮至原有的1/3。本文將從技術原理、場景方案、實操優化三個維度,詳解雲電腦如何破解高性能計算難題。
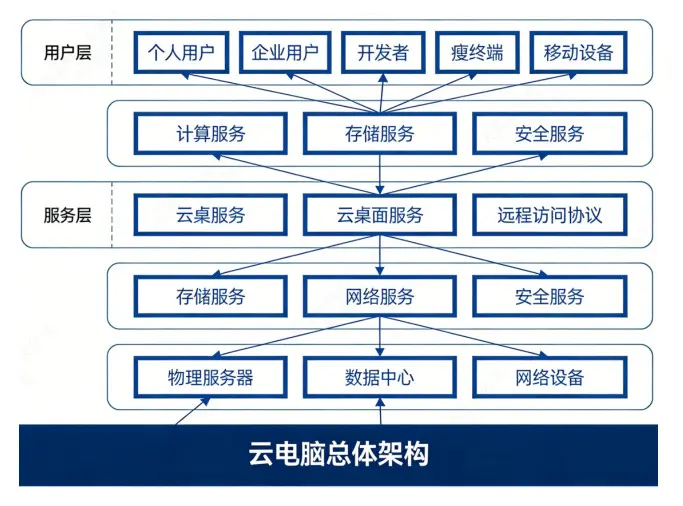
一、高性能計算的核心痛點與雲電腦的破解邏輯
高性能計算(HPC)的核心需求是“海量數據處理”與“高強度並行計算”,傳統本地計算模式存在三大核心痛點,而云電腦通過雲端架構實現了精準破解:
- 傳統高性能計算的三大困境
- 算力成本高企且彈性不足:大型芯片設計、汽車仿真等場景需80核CPU+256G內存+RTX 4090顯卡的配置,本地工作站購置成本超15萬元,而項目高峯期過後,高性能硬件長期閒置,利用率不足30%;
- 硬件迭代速度跟不上需求增長:AI領域顯卡性能每6個月迭代一次,本地購置的RTX 3090顯卡在1年後就難以滿足最新模型訓練需求,重新採購又將產生鉅額成本;
- 計算環境搭建複雜且兼容性差:高性能計算需適配專業軟件(如GCC 12、Spark、TensorFlow)與特定驅動版本,本地集羣需專人花3-5天完成環境配置,且易出現“硬件與軟件版本不兼容”問題。
- 雲電腦破解高性能計算難題的核心邏輯
雲電腦通過“雲端集羣虛擬化+彈性資源調度+專業環境模板”的架構,從根本上解決傳統模式的痛點,其核心優勢體現在三個層面:
- 算力按需彈性分配:支持CPU從8核到128核、內存從16G到512G、顯卡從RTX 3090到A100靈活擴容,高峯期臨時提升配置,任務完成後恢復基礎配置,按分鐘計費,避免資源浪費;
- 硬件資源持續升級:雲服務商定期更新硬件集羣,確保提供最新的CPU(如Intel Xeon Platinum 8480+)、顯卡(NVIDIA H100)等設備,用户無需承擔硬件迭代成本;
- 預製專業計算環境:提供“代碼編譯”“數據分析”“AI訓練”等場景化模板,已預裝對應軟件、驅動及依賴包,用户無需手動配置,5分鐘即可啓動高性能計算任務。
二、場景一:大型代碼編譯——從“數小時等待”到“分鐘級完成”
大型項目(如操作系統內核、汽車電子控制軟件、工業級芯片設計)的代碼量通常超過100萬行,本地8核CPU編譯需2-6小時,而云電腦通過“多核並行編譯+分佈式緩存”技術,可將編譯時間壓縮至10-30分鐘,大幅提升研發效率。
- 核心優勢:多核並行與編譯緩存雙重加速
- 超高核數支持並行編譯:雲電腦最高支持128核CPU,配合Make、CMake等編譯工具的並行參數(如make -j64),可同時啓動64個編譯進程,將代碼分片並行處理,編譯效率隨核數呈線性提升;
- 分佈式編譯緩存減少重複計算:雲電腦內置“編譯緩存中心”,將已編譯的目標文件(.o文件)緩存至雲端,後續編譯時僅重新編譯修改過的代碼文件,未修改文件直接複用緩存,二次編譯時間可縮短90%;
- 高IO存儲保障文件讀寫速度:採用NVMe SSD雲盤,讀寫速度達5000MB/s,避免傳統機械硬盤因文件讀寫緩慢導致的編譯瓶頸,尤其適合包含大量頭文件和靜態庫的大型項目。
- 實操方案:Linux雲電腦編譯大型C++項目全流程
以“汽車電子控制軟件(代碼量150萬行,依賴20個靜態庫)”為例,採用Ubuntu 22.04雲電腦實現快速編譯,具體步驟如下:
(1)雲電腦配置選擇與環境初始化
- 配置選擇:根據項目規模選擇64核Intel Xeon Platinum 8480+ CPU、128G DDR5內存、1T NVMe SSD雲盤的雲電腦實例,編譯完成後可降級至8核16G配置,降低成本;
- 環境初始化:選擇“代碼編譯專用模板”,該模板已預裝GCC 12.2、CMake 3.26、Make 4.3、Git 2.39等工具,以及汽車電子開發常用的AUTOSAR工具鏈,無需手動安裝;
- 網絡優化:通過雲電腦控制枱啓用“研發加速通道”,拉取代碼倉庫(如GitLab)的速度從10MB/s提升至100MB/s,10GB代碼倉庫拉取時間從17分鐘縮短至1.7分鐘。
(2)編譯優化配置與執行
- 代碼拉取與依賴安裝:通過SSH連接雲電腦,執行“git clone https://gitlab.com/auto/ecu-control.git”拉取代碼,利用模板內置的依賴管理工具(如Conan)一鍵安裝20個靜態庫依賴,避免手動配置依賴路徑;
- 編譯參數優化:修改CMakeLists.txt文件,配置並行編譯參數“set(CMAKE_BUILD_PARALLEL_LEVEL 64)”,指定64個並行編譯進程;啓用編譯優化選項“-O2”,在保證編譯質量的同時提升速度;
- 啓用分佈式緩存:在雲電腦中配置ccache編譯緩存工具,將緩存目錄掛載至雲端共享存儲,執行“ccache -M 50G”設置50GB緩存空間,後續團隊其他成員編譯同一項目時可共享緩存;
- 執行編譯:執行“cmake . && make -j64”啓動編譯,通過“htop”命令可實時監控64核CPU的運行狀態,所有核心利用率維持在95%以上,150萬行代碼編譯僅耗時22分鐘,而本地8核CPU編譯需5小時18分鐘。
(3)編譯結果管理與成本控制
- 結果同步:編譯生成的二進制文件(.bin)自動同步至雲端共享目錄,本地終端可通過FTP快速下載,或直接部署至測試設備;
- 資源降級:編譯完成後,在雲電腦控制枱將配置降級至8核16G,僅保留基礎資源用於後續代碼修改,避免高配置資源持續計費;
- 團隊協作:創建“編譯任務小組”,團隊成員可共享同一雲電腦實例,通過權限管理分配代碼讀寫權限,實現“一人編譯、多人複用”。
- 性能對比:雲電腦vs本地工作站
項目規模
設備類型
配置
首次編譯時間
二次編譯時間(修改1個文件)
單日成本(按8小時使用計)
150萬行C++代碼
本地工作站
8核i9-13900K+64G內存+1T SSD
5小時18分鐘
1小時32分鐘
——(購置成本1.8萬元)
雲電腦
64核Xeon+128G內存+1T NVMe
22分鐘
2分鐘
120元(編譯2小時+待機6小時)
三、場景二:數據分析——海量數據處理的“雲端引擎”
金融風控、用户行為分析、工業傳感器數據監測等場景,需處理100GB以上的海量數據,本地設備常因內存不足、計算核心不夠導致分析任務中斷。雲電腦通過“大內存支撐+分佈式計算框架+GPU加速”,可高效完成數據清洗、建模、可視化全流程,尤其適合需要頻繁迭代分析模型的場景。
- 核心技術支撐:大內存+分佈式框架+GPU加速
- 超大內存突破數據加載瓶頸:雲電腦最高支持512G內存,可將100GB海量數據完整加載至內存中進行處理,避免本地設備因內存不足導致的“數據分片加載-合併”繁瑣流程,數據讀取速度提升5倍;
- 分佈式框架提升計算效率:預裝Spark、Hadoop等分佈式計算框架,雲電腦可作為集羣主節點,調度多台雲實例並行處理數據,例如將10億條用户行為數據分片至10台雲電腦實例,並行完成統計分析;
- GPU加速數據建模:採用RTX 4090/A100顯卡加速機器學習模型訓練,例如用GPU加速XGBoost、LightGBM等算法,模型訓練時間從24小時縮短至2小時。
- 實操案例:金融風控數據實時分析(基於Spark)
某銀行需分析每日50GB信用卡交易數據(約5000萬條記錄),識別欺詐交易行為,要求分析延遲不超過1小時,採用Windows Server 2022雲電腦實現實時分析,具體方案如下:
(1)雲電腦集羣配置與環境搭建
- 集羣架構:採用“1主4從”的雲電腦集羣架構,主節點配置32核CPU、128G內存、RTX 4090顯卡,負責任務調度與模型訓練;4個從節點各配置16核CPU、64G內存,負責數據並行處理;
- 環境搭建:選擇“大數據分析模板”,主從節點已預裝Spark 3.4、Hadoop 3.3、Python 3.10、Pandas 2.0、Scikit-learn 1.3等工具,通過雲電腦控制枱一鍵完成集羣節點間的SSH免密登錄配置與Spark集羣初始化;
- 數據接入:通過雲電腦的“數據網關”功能,將銀行數據庫(Oracle)中的交易數據實時同步至HDFS分佈式文件系統,同步延遲控制在10秒內。
(2)數據分析全流程實現
-
數據清洗:在Spark中編寫Scala代碼,對交易數據進行去重、缺失值填充、異常值過濾(如交易金額超過10萬元且無密碼驗證的記錄標記為可疑),4個從節點並行處理,50GB數據清洗耗時8分鐘;
// Spark數據清洗核心代碼val spark = SparkSession.builder().appName("CreditCardFraudDetection").getOrCreate()
val data = spark.read.format("csv").option("header", "true").load("hdfs://master:9000/transaction/data.csv")
// 去重與缺失值處理
val cleanData = data.dropDuplicates().na.fill(0, Seq("amount")).filter("amount < 100000") - 特徵工程:提取交易時間(小時/周幾)、交易地點(與常用地點的距離)、交易頻率等15個特徵,通過Spark MLlib將特徵標準化處理,生成機器學習模型輸入數據,耗時12分鐘;
- 模型訓練與預測:利用主節點的RTX 4090顯卡加速訓練XGBoost欺詐識別模型,基於歷史3個月的標註數據(100萬條正常交易+1萬條欺詐交易)訓練模型,耗時45分鐘,模型準確率達98.5%;將實時交易數據輸入模型進行預測,欺詐交易識別延遲僅3秒;
- 結果可視化與預警:通過雲電腦中的Tableau Desktop連接Spark結果集,實時生成交易欺詐率趨勢圖、地區欺詐分佈熱力圖;當識別到欺詐交易時,自動通過API推送預警信息至銀行風控系統。
(3)效率提升關鍵:雲電腦專屬優化技巧
- 內存優化:在Spark配置中設置“spark.executor.memory=40g”“spark.driver.memory=80g”,充分利用雲電腦大內存優勢,避免內存溢出;
- 數據本地化:將HDFS數據存儲節點與Spark計算節點部署在同一地域的雲服務器,減少數據傳輸延遲,數據處理速度提升30%;
- 彈性擴縮容:每日交易高峯期(9:00-18:00)將從節點擴容至8個,非高峯期縮容至2個,日均成本降低40%。
四、場景三:AI模型訓練——GPU算力按需調用的“訓練工坊”
AI模型訓練(如大語言模型微調、計算機視覺模型訓練)對GPU算力需求極高,本地單張RTX 3090顯卡訓練ResNet-50模型需72小時,而云電腦提供從RTX 3090到NVIDIA H100的多規格GPU,支持多卡並行訓練,可將訓練週期大幅縮短,同時避免本地顯卡散熱、功耗等問題。
- 核心優勢:多卡並行+顯存優化+算力彈性
- 多GPU並行訓練:雲電腦支持1-8張GPU卡並行訓練,通過DataParallel或DistributedDataParallel技術將模型參數與數據分片至多張顯卡,訓練速度隨顯卡數量近似線性提升,8張H100顯卡訓練速度是單張RTX 3090的32倍;
- 超大顯存支撐大模型訓練:H100顯卡具備80GB HBM3顯存,可支持10B參數的大語言模型(如Llama 2-7B)全參數微調,無需採用“模型並行”等複雜技術拆分模型,降低開發難度;
- 算力按需付費:GPU算力按分鐘計費,模型訓練完成後可立即釋放GPU資源,避免本地顯卡長期閒置,例如訓練一個計算機視覺模型僅需支付8小時GPU費用(約200元),遠低於購置顯卡的成本。
- 實操方案:基於雲電腦的ResNet-50模型訓練(圖像分類)
以“基於ImageNet數據集(1400萬張圖片,1000個類別)訓練ResNet-50模型”為例,採用Ubuntu 22.04雲電腦+4張RTX 4090顯卡實現高效訓練,具體步驟如下:
(1)雲電腦配置與GPU環境驗證
- 配置選擇:選擇4張RTX 4090顯卡、32核CPU、128G內存、2T NVMe SSD雲盤的雲電腦實例,滿足ResNet-50模型訓練的算力與存儲需求;
- 環境初始化:選擇“AI訓練專用模板”,已預裝CUDA 12.1、CuDNN 8.9、TensorFlow 2.15、PyTorch 2.0等工具,顯卡驅動已完成適配,無需手動安裝;
- GPU驗證:執行“nvidia-smi”命令驗證GPU狀態,確認4張RTX 4090顯卡均正常識別,CUDA版本匹配;執行PyTorch代碼“torch.cuda.is_available()”返回True,確保GPU可被框架調用。
(2)數據準備與模型訓練實現
- 數據集獲取與預處理:通過雲電腦的“數據集加速下載”功能,從阿里雲OSS獲取ImageNet數據集(已預處理為TFRecord格式),下載速度達200MB/s,1400萬張圖片下載耗時2小時;利用PyTorch的DataLoader實現數據批量加載與增強(隨機裁剪、翻轉、歸一化);
-
模型配置與並行設置:基於PyTorch構建ResNet-50模型,使用“torch.nn.DataParallel”將模型包裝為多GPU並行訓練模式,指定4張顯卡參與訓練;設置batch size為256(單卡batch size 64),學習率為0.1,採用SGD優化器;
import torchimport torchvision.models as models
初始化ResNet-50模型
model = models.resnet50(pretrained=False, num_classes=1000)
配置多GPU並行
model = torch.nn.DataParallel(model, device_ids=[0,1,2,3])
model.cuda()
- 訓練執行與監控:啓動訓練後,通過“tensorboard --logdir=./logs”實時監控訓練過程,查看損失值、準確率變化曲線;通過“nvidia-smi -l 1”實時查看4張顯卡的利用率(均維持在90%以上)和顯存佔用(每張卡佔用約12GB);
- 訓練結果:4張RTX 4090顯卡訓練ResNet-50模型,完成100個epoch訓練耗時18小時,模型在驗證集上的準確率達78.2%,而本地單張RTX 3090顯卡訓練需72小時,效率提升4倍。
(3)大模型訓練進階:顯存優化技巧
訓練10B參數以上的大語言模型時,需採用顯存優化技術,雲電腦可通過以下方案降低顯存佔用:
- 混合精度訓練:啓用FP16/FP8混合精度訓練,在PyTorch中通過“torch.cuda.amp”模塊實現,顯存佔用降低50%,訓練速度提升20%;
- 梯度檢查點:在模型訓練中啓用梯度檢查點技術,犧牲少量計算時間換取顯存佔用降低,適合顯存緊張的大模型訓練;
- 模型並行與數據並行結合:對於50B以上參數的超大規模模型,採用“模型並行+數據並行”混合架構,將模型不同層部署在不同GPU上,同時進行數據分片,雲電腦支持多節點間的高速網絡互聯(RDMA網絡,延遲<10us),確保並行效率。
- 不同GPU配置的訓練性能對比
暫時無法在豆包文檔外展示此內容
五、雲電腦高性能計算的成本與安全保障
高性能計算場景下,成本控制與數據安全是企業關注的核心,雲電腦通過靈活計費模式與多重安全機制提供全方位保障。
- 成本控制:按需計費與資源優化策略
- 按需計費降低閒置成本:CPU、GPU資源按分鐘計費,代碼編譯、模型訓練等短時任務完成後立即釋放高配置資源,僅保留基礎配置用於後續工作,例如一個月的AI模型訓練任務,實際GPU使用時間僅100小時,成本約2000元,遠低於本地顯卡購置成本;
- 預留實例降低長期成本:對於需長期使用高性能計算的場景(如持續的數據分析任務),可購買“預留實例”,享受30%-50%的價格折扣,同時保留資源彈性擴容的能力;
- 資源調度優化:通過雲電腦管理平台設置“資源自動調度規則”,例如夜間12點至次日8點自動降低配置,白天工作時間自動提升配置,進一步降低非工作時段的成本。
- 安全保障:數據與計算過程雙重防護
- 數據加密傳輸與存儲:本地終端與雲電腦之間採用TLS 1.3協議加密傳輸,訓練數據、代碼文件存儲採用AES-256加密,雲服務商無法直接訪問數據內容;支持數據“本地銷燬+雲端留存”模式,任務完成後可遠程刪除雲電腦中的敏感數據;
- 計算環境隔離:每個雲電腦實例採用獨立的虛擬機隔離,不同用户的計算任務互不干擾,避免惡意程序攻擊;支持“專有宿主機”部署,將雲電腦實例部署在專屬的物理服務器上,進一步提升數據安全性;
- 操作日誌與權限管控:記錄所有操作日誌(如登錄、資源調整、文件傳輸),日誌保留180天可追溯;通過RBAC權限模型分配用户權限,例如開發人員僅擁有代碼編譯權限,無法訪問敏感的訓練數據。
六、未來趨勢:AI與雲算力的深度融合
隨着AI技術的發展,雲電腦在高性能計算領域的應用將迎來進一步升級:
- 智能算力調度:AI將自動根據計算任務類型(代碼編譯/數據分析/模型訓練)推薦最優配置,例如識別到是ResNet模型訓練時,自動分配4張RTX 4090顯卡,任務完成後自動釋放資源;
- 邊緣雲協同計算:對於低延遲需求的高性能計算場景(如工業實時質檢),雲電腦將與邊緣計算節點協同,將部分計算任務下沉至邊緣節點,降低延遲,同時利用雲端算力完成複雜的模型訓練;
- 算力共享生態:雲服務商將構建“算力共享平台”,企業可將閒置的雲電腦算力共享給其他用户,獲取算力收益,實現算力資源的高效利用。
七、總結:雲電腦重構高性能計算模式
雲電腦通過“彈性算力、按需付費、專業環境”的核心優勢,徹底改變了高性能計算“高成本、高門檻、低彈性”的傳統模式。無論是大型代碼編譯的“分鐘級完成”,還是海量數據分析的“高效並行”,亦或是AI模型訓練的“算力按需調用”,雲電腦都為企業和科研人員提供了高性價比的解決方案,讓高性能計算從“少數人的專屬”變為“人人可用的工具”。
隨着雲硬件的持續升級與AI技術的深度融合,雲電腦在高性能計算領域的應用場景將不斷拓展,成為推動研發創新、提升生產效率的核心引擎。對於有高性能計算需求的用户而言,選擇雲電腦無疑是平衡成本、效率與安全性的最優選擇。