

Disruptor,這一由英國金融巨頭LMAX匠心打造的高性能併發框架,自誕生之初便肩負着在處理生產者-消費者問題時,追求極致吞吐量與超低延遲的使命。令人矚目的是,LMAX公司憑藉Disruptor框架,成功將訂單處理速度飆升至每秒600萬次交易(Transactions Per Second,TPS)的驚人水平,這一成就無疑彰顯了Disruptor在併發處理領域的非凡實力。
然而,Disruptor的價值遠不止於一個框架那麼簡單。它更是一種顛覆性的併發設計思想,為涉及併發、緩衝區管理、生產者-消費者模型以及事件處理等複雜場景的程序,提供了一種革命性的性能提升方案。
無鎖隊列
生產者-消費者問題(Producer-Consumer Problem,PCP),作為併發編程中的經典難題,一直困擾着無數開發者。它描述的是生產者和消費者在
共享緩衝區中的協同工作場景,其中的關鍵挑戰在於如何妥善處理生產者和消費者速度不匹配的問題。必須確保,在生產者向緩衝區添加數據時,緩
衝區不會因溢出而崩潰;同時,在消費者從緩衝區獲取數據時,緩衝區也不會因空置而停滯。
有界緩衝區(Bounded-Buffer),作為生產者-消費者問題的一個特定實例,其緩衝區容量是固定的。這種限制雖然帶來了額外的複雜性,但也為優化併發性能提供了機會。當緩衝區滿時,生產者必須耐心等待,直到消費者消費了部分數據以騰出空間;反之,當緩衝區為空時,消費者也必須靜待時機,直到生產者添加了新的數據。為了協調這種複雜的交互,通常需要藉助同步機制,如信號量、條件變量或互斥鎖等。
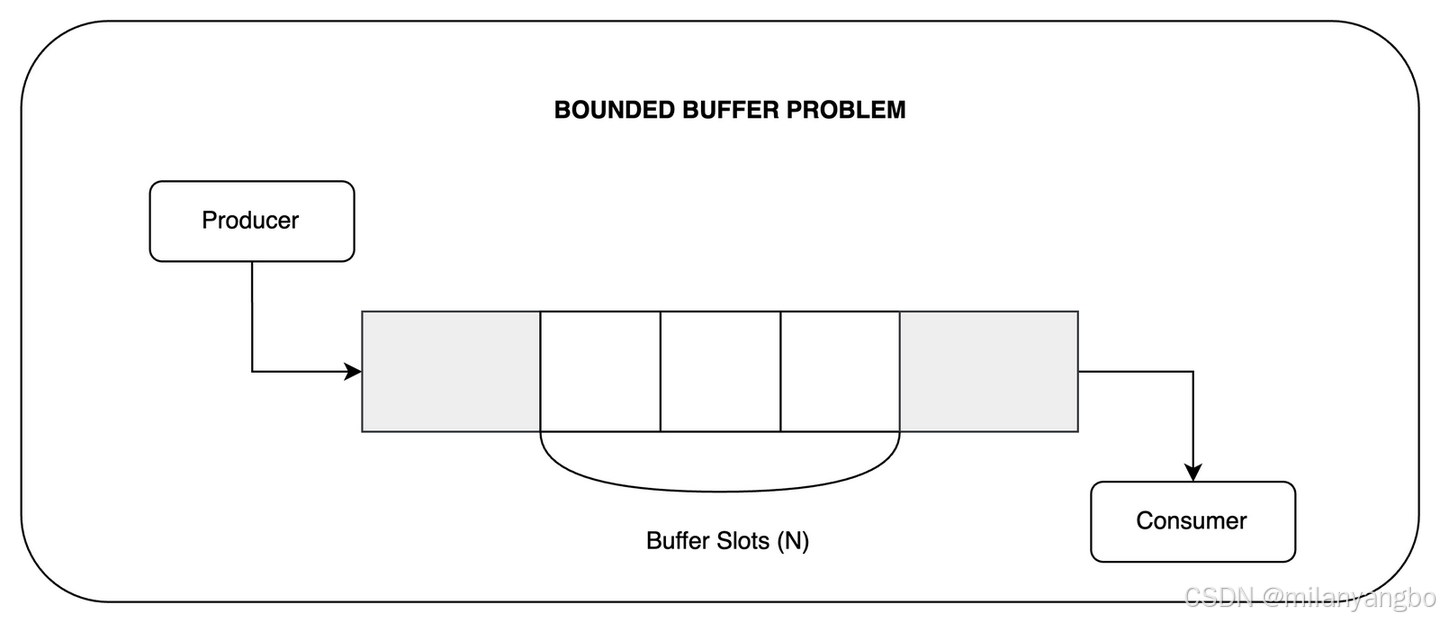
以下代碼片段展示了有界緩衝區的一種典型實現方式,它巧妙地運用了鎖和條件變量來解決同步問題。
// 生產者緩存區處理
// 條件變量empty
Condition empty;
// 持有互斥鎖
lock (mutex);
do{
// 等待直到沒有元素的buffer slot大於0
// 至少需要一個沒有元素的buffer slot
wait (empty);
}while (true)
// 執行添加元素到buffer slot的操作
put(element)
// 通知條件變量full
signal (full);
// 釋放鎖
unlock (mutex);
// 消費者緩存區處理
// 條件變量full
Condition full;
// 持有互斥鎖
lock (mutex);
do{
// 等待直到有元素的buffer slot大於0
// 至少需要一個有元素的buffer slot
wait (full);
}while (true)
// 執行移除buffer slot元素的操作
remove(element)
// 通知條件變量empty
signal (empty);
// 釋放鎖
unlock (mutex);
儘管上述實現通過鎖和條件變量有效解決了有界緩衝區的同步問題,但在實際編程中,加鎖操作往往會帶來不容忽視的性能開銷。鎖的獲取和釋放,會觸發線程的休眠與喚醒,進而引發額外的上下文切換開銷。如果臨界區代碼段過長,鎖的爭用問題將愈發嚴重,最終成為制約系統性能的瓶頸。
Disruptor的論文中,一項實驗直觀展現了鎖機制對系統性能的深遠影響。該實驗聚焦於一個簡單的64位計數器,對其進行了高達5億次的自增操作。測試結果令人驚訝。
1)單線程無鎖情況:僅需300毫秒,便輕鬆完成了5億次自增操作。
2)單線程加鎖情況:耗時急劇增加至10,000毫秒,性能下降了數十倍。
3)雙線程加鎖情況:耗時更是飆升至224,000毫秒,比單線程無鎖實現慢了近1000倍!
面對如此巨大的性能差異,Disruptor提出了其獨到的解決方案:無鎖(lock-free)編程。
鎖,作為併發編程中的常見控制技術,其背後藴含着兩種截然不同的併發控制策略:樂觀併發控制(Optimistic Concurrency Control,OCC)與悲觀併發控制(Pessimistic Concurrency Control,PCC)。而樂觀鎖,並非傳統意義上的鎖,而是一種基於驗證的併發協議。它秉持着“多線程間數據競爭概率較低”的樂觀假設,允許多個線程在不加鎖的情況下直接操作共享數據。僅在提交時,通過精妙的驗證機制檢測是否存在衝突。一旦檢測到衝突(如數據被其他線程修改),便迅速回滾操作並重試。這一機制的核心,正是依賴於原子指令CAS來實現數據的同步更新,確保了併發操作的安全與高效。
在併發編程的實踐中,主要有兩種途徑來實現線程安全。
1)加鎖方式:通過互斥鎖、讀寫鎖等機制,確保同一時間只有一個線程能夠訪問共享資源,從而避免數據競爭。但這種方式往往伴隨着性能開銷和死鎖風險。
2)原子變量CAS:利用CAS指令的原子性,實現無鎖編程。這種方式在多數情況下能夠顯著提升併發性能,成為現代併發編程的熱門選擇。
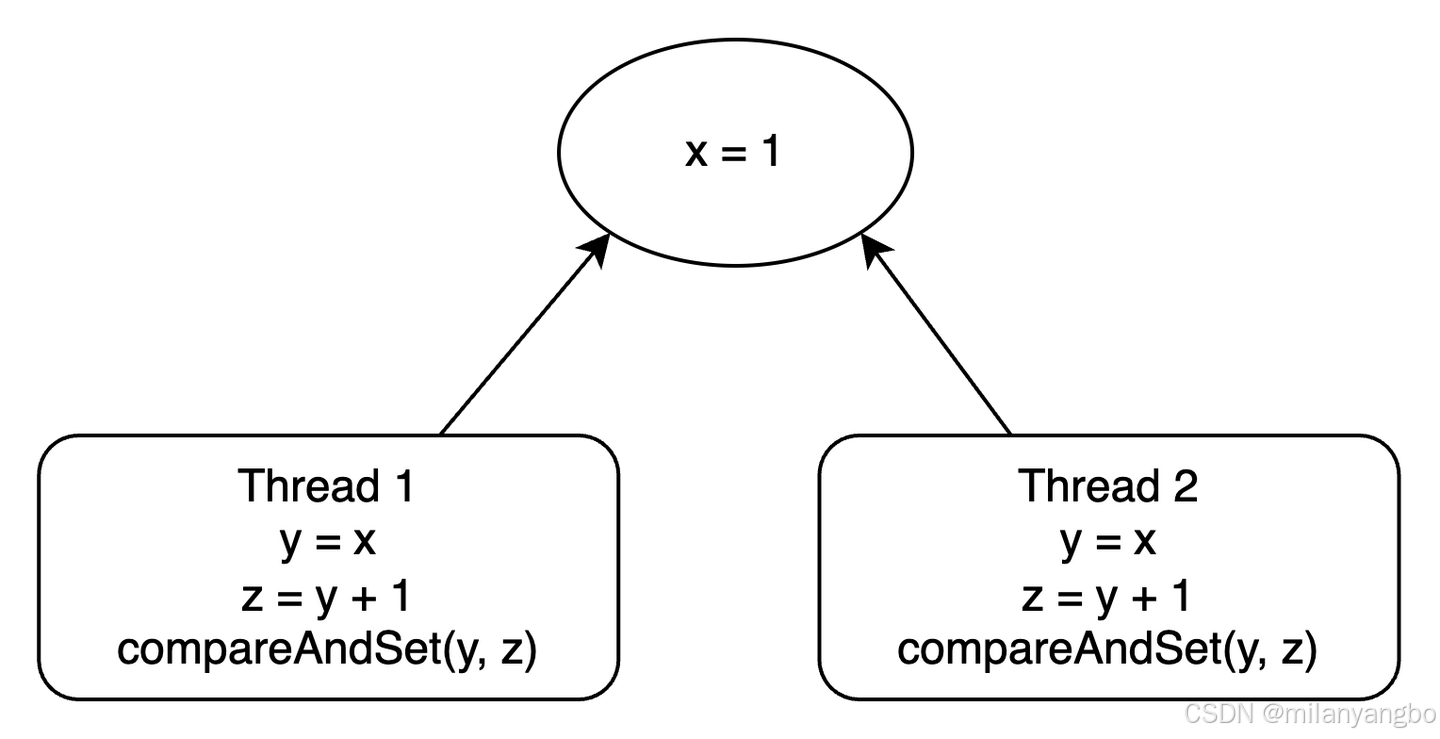
無鎖隊列(Lock-free Queue)的實現,正是CAS指令在併發編程中的典型應用。早在1994年,John D. Valois便在其論文《Implementing Lock-Free Queues》中,系統地研究瞭如何使用無鎖數據結構實現先進先出(FIFO)隊列。他提出了一種基於鏈表結構的無鎖隊列設計,通過CAS操作確保入隊和出隊操作的原子性,從而實現了高效且線程安全的隊列操作。
以下代碼,展示了無鎖隊列的一種典型實現。
// 進隊列操作
EnQueue(x) {
q = new record(); // 創建新節點
q.value = x; // 設置節點值
q.next = null; // 初始化next指針
p = tail; // 獲取當前尾節點
oldp = p; // 保存舊尾節點指針
do {
while (p.next != null) // 遍歷至鏈表末尾
// 獲取最新的next
p = p.next;
// 如果p.next非預期舊值null, 表明p.next已被修改
} while( CAS(p.next, null, q) != true);
// 如果當前tail等於oldp時,説明tail沒有被修改,將tail設為q
CAS(tail, oldp, q);
}
// 出隊列操作
DeQueue()
{
do{
p = head; // 獲取當前頭節點
if (p.next == null) { // 隊列為空時返回特殊值
return empty_queue;
}
// 如果head非預期舊值p, 表明head已被修改
while( CAS(head, p, p.next) != true);
return p.next.value; // 返回出隊元素的值
}
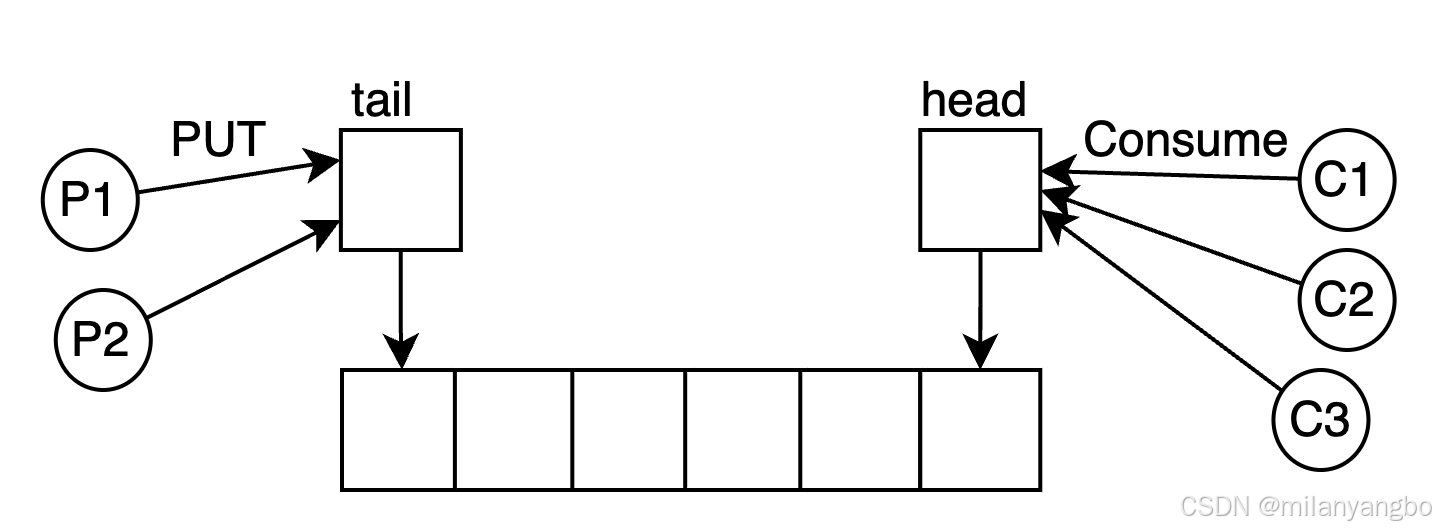
Ring Buffer
Ring Buffer,又稱環形緩衝區或循環緩衝區,是一種極具特色的無鎖隊列實現方式,在計算機科學領域有着廣泛的應用。它不僅能夠實現對隊列頭尾元素的無鎖併發控制,還能巧妙解決生產者和消費者之間的協調難題。值得一提的是,Ring Buffer並非Disruptor框架的獨家發明,早在Linux內核中就已有了它的身影。
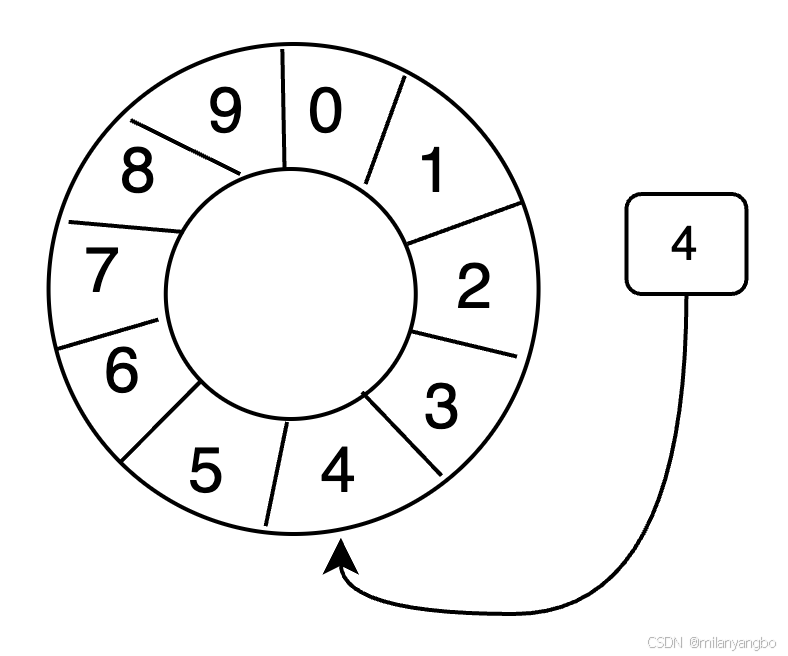
Ring Buffer是一種特殊的數據結構,它採用固定大小的數組來存儲數據,數據在數組中的存儲方式宛如一個環。當緩衝區被填滿時,新寫入的元素會覆蓋最早寫入的元素,這種特性使得它在處理流式數據時非常高效。為了進一步提升效率,數組中的元素在初始化時會一次性全部創建,減少了運行時的動態分配開銷。
在消費者消費數據時,Ring Buffer遵循空間局部性原理。處理器會將內存中的當前元素及其後面連續的元素一次性加載進處理器緩存中,從而提升處理器處理元素的速度。這種設計充分利用了現代處理器的緩存機制,使得數據訪問更加高效。
Ring Buffer使用一個遞增指針來指向緩衝區中下一個可用的元素。隨着數據的不斷填充,這個指針會持續增加,直到繞過整個環。要找到緩衝區中當前指針指向的元素,可以通過取模操作來實現。
index mod array length = array index
當緩衝區長度2^n,通過位運算,可以加快定位的速度。
index & (array length-1) = array index
例如,當index為9,array length為8時,取模運算9 % 8可以用9 & (8 - 1)來代替,即1001 & 0111 = 0001 = 1。這種位運算的優化使得Ring Buffer在定位元素時更加迅速。
Disruptor框架在使用Ring Buffer時,可以細分為以下幾種場景。
1)單生產者單消費者:由於兩個線程分別操作不同的指針,因此不需要鎖,實現了無鎖併發。
2)多消費者:每個消費者各自控制自己的指針,依次讀取每個元素。此時只需保證生產者指針不會超過最慢的消費者即可,同樣不需要鎖。
3)多生產者:多個線程共用一個寫指針,此時需要考慮多線程問題。Disruptor使用CAS操作來保證多線程安全。例如,申請寫入n個元素時,會檢查是否有n個元素可以寫入,並返回最大的指針下標。每個生產者會被分配一段獨享的空間鎖,以確保數據的一致性。
4)生產者與消費者速度不匹配:當生產者生產速度超過消費者消費速度時,生產者會採用休眠策略(如休眠1ns)來等待。反之,消費者則可能採用自旋或加鎖等待策略,以在處理器資源和性能之間做出取捨。
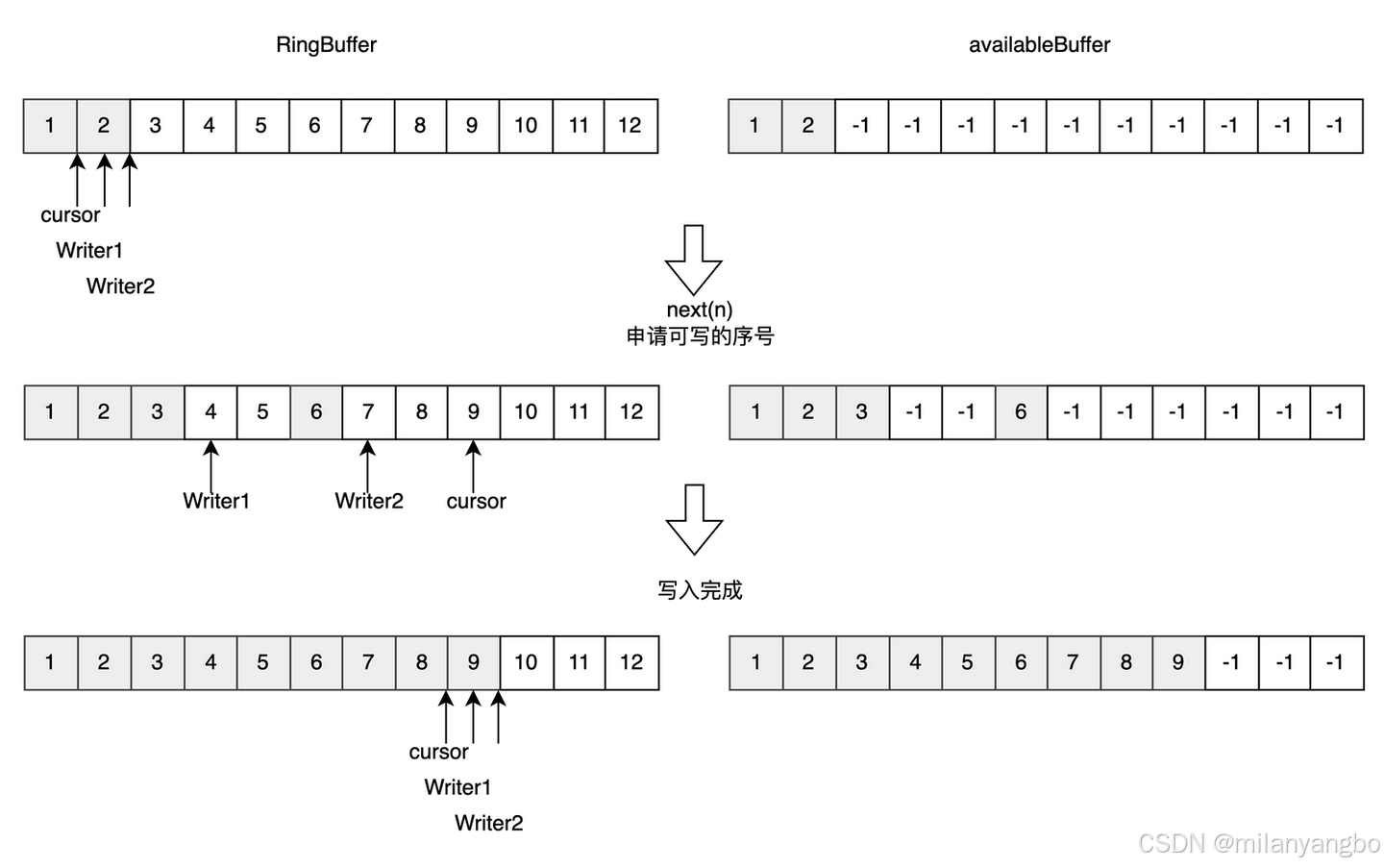
以下代碼,展示瞭如何通過CAS操作來嘗試獲取Ring Buffer中的可用空間,並確保了多線程環境下的安全性。
// 嘗試獲取可用緩衝區空間
public long tryNext(int n) throws InsufficientCapacityException
{
// ......
long current,next;
do
{
// 此處先將寫指針的當前值備份一下
current = cursor.get();
// 預計寫指針將要移動到的位置
next = current + n;
// 判斷是否可用的緩衝區空間
if (!hasAvailableCapacity(gatingSequences, n, current)){
throw InsufficientCapacityException.INSTANCE;
}
// 通過cas判斷申請的空間是否已經被其他生產者佔據
}while (!cursor.compareAndSet(current, next));
return next;
}
緩存行填充
內存的訪問速度與處理器運行速度之間存在顯著差距,這種速度不匹配會導致處理器頻繁等待數據,降低整體計算效率。為解決這一問題,現代處理器在內存與處理器之間引入了多級緩存系統(L1/L2/L3 Cache),其中緩存行(Cache Line)是緩存的基本單位。
1)典型緩存行大小:現代處理器普遍採用64字節緩存行(部分舊處理器為32字節)。
2)空間局部性原理:緩存行設計利用了程序訪問數據的空間局部性,即處理器傾向於訪問連續的內存塊。通過一次性加載整個緩存行(如64字節),處理器可高效讀取多個相鄰數據項,顯著提升訪問效率。
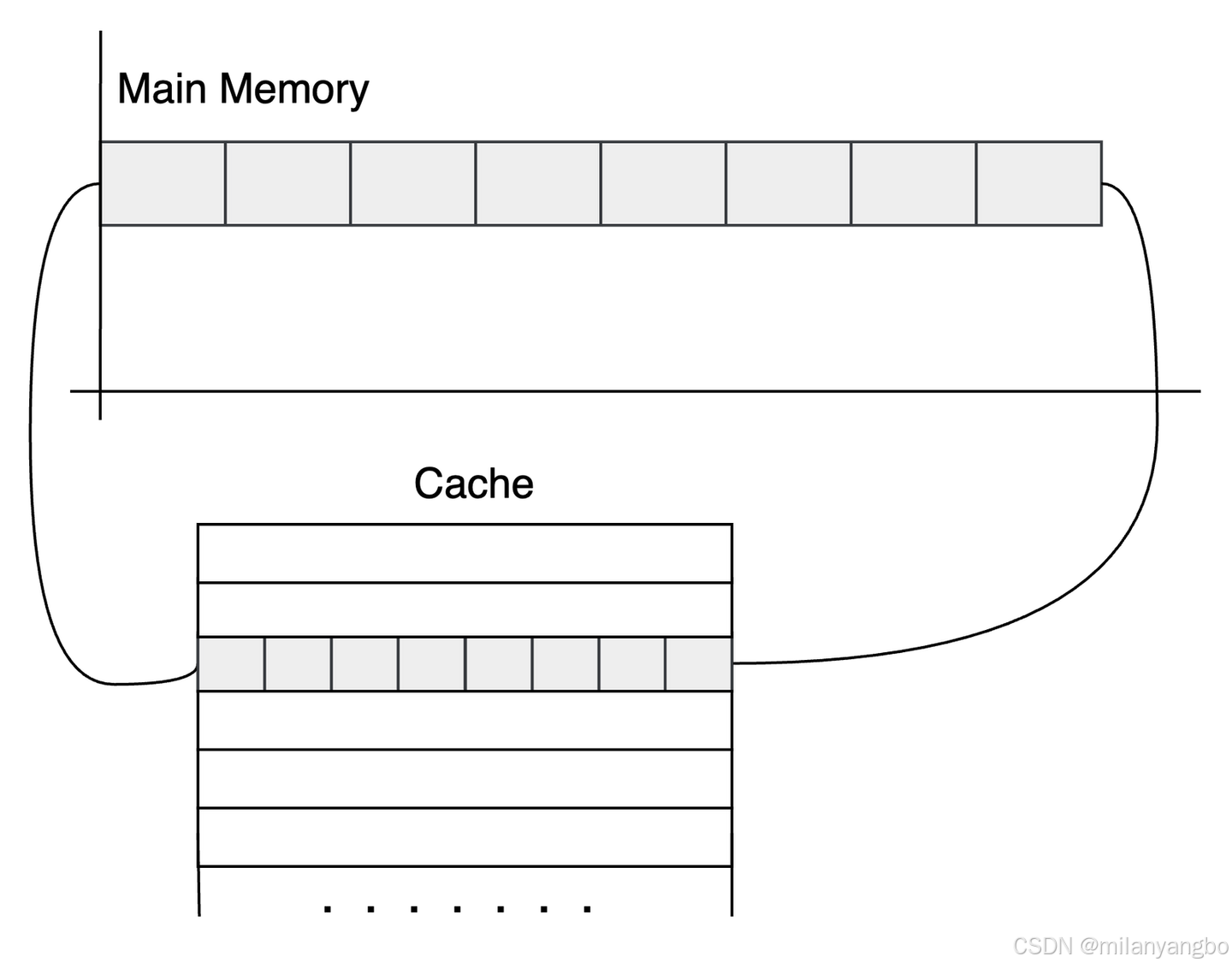
以Java語言為例,一個long類型的變量佔用8字節的內存空間,因此在一個64字節的緩存行中,理論上可以存儲8個long類型的變量。這種設計使得處理器在讀取數據時,能夠一次性從內存中讀取多個連續的數據項,從而顯著提高數據訪問的效率。這就是所謂的空間局部性原理,它是計算機系統設計中的一種重要優化策略。
public class CacheLineEffect {
// 考慮一般緩存行大小是64字節,一個 long 類型佔8字節
static long[][] arr;
public static void main(String[] args) {
arr = new long[1024 * 1024][];
for (int i = 0; i < 1024 * 1024; i++) {
arr[i] = new long[8]; // 每個緩存行存儲8個long變量
for (int j = 0; j < 8; j++) {
arr[i][j] = 0L;
}
}
long sum = 0L;
// 利用緩存行的特性,連續訪問同一緩存行內的數據,觸發緩存命中,性能更高。
for (int i = 0; i < 1024 * 1024; i+=1) {
for(int j =0; j < 8;j++){
sum = arr[i][j];
}
}
// 不利用緩存行的特性,導致頻繁的緩存未命中,需從主內存加載數據,性能顯著下降。
for (int i = 0; i < 8; i+=1) {
for(int j =0; j < 1024 * 1024;j++){
sum = arr[j][i];
}
}
}
}
然而,緩存行的這種 "免費加載" 特性存在潛在問題。假設一個生產者和一個消費者各自持有一個 long 類型指針,若這兩個指針位於同一個緩存行,當生產者線程修改其指針值時,整個緩存行會被標記為 "髒",導致消費者線程的緩存指針值失效,需重新從主內存加載。
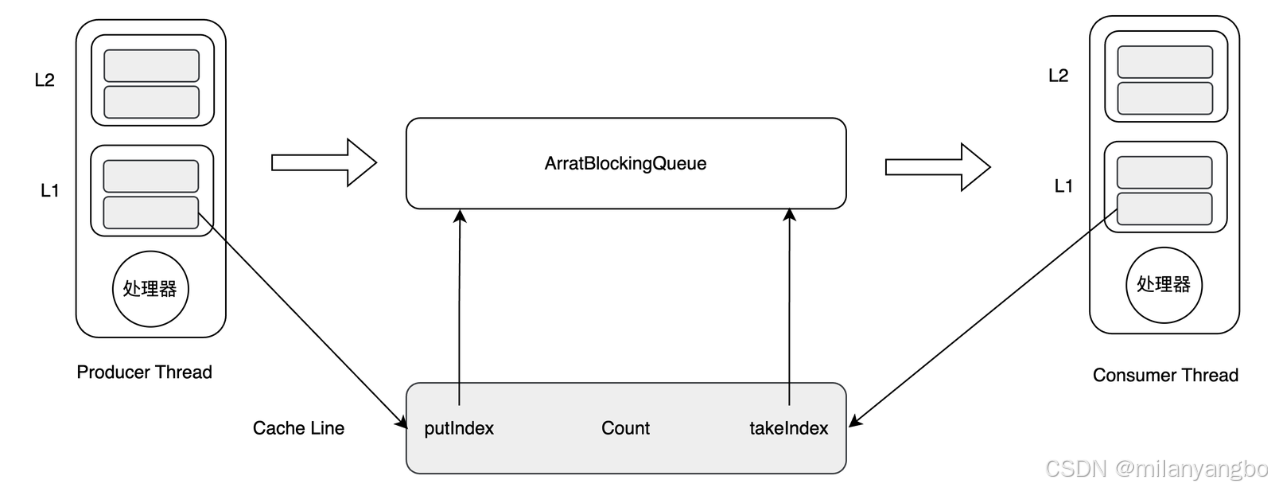
在多核處理器中,為了保證每個核的緩存視圖的一致性,通常會採用緩存一致性協議(如MESI協議)。當一個核在其緩存中修改了數據,其他核的相同緩存行就會被標記為無效,即使它要訪問的數據並未被修改。
這種無法充分利用緩存行特性的現象,被稱為緩存行偽共享(False sharing)。由於緩存行偽共享,線程需要頻繁地從主內存中重新加載數據,這會導致大量的緩存未命中,嚴重影響性能。同時,由於緩存一致性協議的存在,偽共享還會增加處理器間的同步開銷。
為了解決偽共享問題,Disruptor框架採用了緩衝行填充(Cache line padding)的技術,通過增加填充來確保Ring Buffer的指針不會和其他變量同時存在於一個緩存行中。這樣,就避免了偽共享,消除了與其他變量的意外衝突,減少了不必要的緩存未命中。
public long p1, p2, p3, p4, p5, p6, p7; // cache line padding
private volatile long cursor = INITIAL_CURSOR_VALUE;
public long p8, p9, p10, p11, p12, p13, p14; // cache line padding
未完待續
很高興與你相遇!如果你喜歡本文內容,記得關注哦!!!