

MVCC
多版本併發控制(Multi-version Concurrency Control, MVCC)是一種通過維護數據多個版本來實現併發控制的技術。其基本思想是為每次事務生成一個新版本的數據,在讀數據時選擇不同版本的數據即可以實現對事務結果的完整性讀取。在使用MVCC 時,每個事務都是基於一個已生效的基礎版本進行更新,事務可以並行進行,從而可以產生一種圖狀結構。

如圖所示,基礎數據的版本為1,同時產生了兩個事務:事務A與事務B。這兩個事務都各自對數據進行了一些本地修改,這些修改只有事務自己可見,不影響真正的數據。之後事務A首先提交,生成數據版本2;基於數據版本2,又發起了事務C,事務C繼續提交,生成了數據版本3;最後事務B提交,此時事務B的結果需要與事務C的結果合併,如果數據沒有衝突,即事務B沒有修改事務A與事務C修改過的變量,那麼事務B可以提交,否則事務B提交失敗。
事務在基於基礎數據版本做本地修改時,為了不影響真正的數據,通常有兩種做法。
1)將基礎數據版本中的數據完全拷貝出來再修改;
2)每個事務中只記錄更新操作,而不記錄完整的數據,讀取數據時再將更新操作應用到用基礎版本的數據從而計算出結果。
MVCC的設計理念深受版本控制系統(如Git)的影響,其工作流程與版本控制系統的操作流程高度相似。在事務處理中,上述兩種策略各有優勢,完整拷貝策略簡單直觀,但可能佔用較多存儲空間;增量記錄策略則更為高效,能有效減少存儲開銷。
MVCC的工作流程在很大程度上類似於版本控制系統(如Git)的操作流程,可以説,Git等版本控制系統的設計理念深受MVCC思想的影響。
事務處理
MVCC重點不在於併發控制,而在於實現事務(Transaction)。假設在一個關係型數據庫中,更新操作以事務進行,每個事務包括對若干行數據的更新操作。更新事務必須具有原子性,即事務中的所有更新操作要麼同時生效,要麼都不生效。
在事務無法生效,即需要進行事務回滾時,通常會依賴於回滾日誌(Undo Log)。回滾日誌是一種專門用於事務恢復的日誌技術,它詳細記錄了事務在執行過程中對數據的所有修改。若事務失敗或系統崩潰,回滾日誌能夠用於將數據恢復至事務開始前的狀態。
以MySQL為例,在MVCC中,對於每次更新操作,舊值會被保存到一條回滾日誌日誌中,即它是該記錄的舊版本。隨着更新次數的增加,所有的版本都會通過回滾指針(Roll Pointer)連接成一個鏈表,稱之為版本鏈。鏈首就是最新的記錄,鏈尾就是最早的舊記錄。
舉個例子,比如有個事務A插入了一條新記錄:insert into user(id, name) values(1, '張三')。
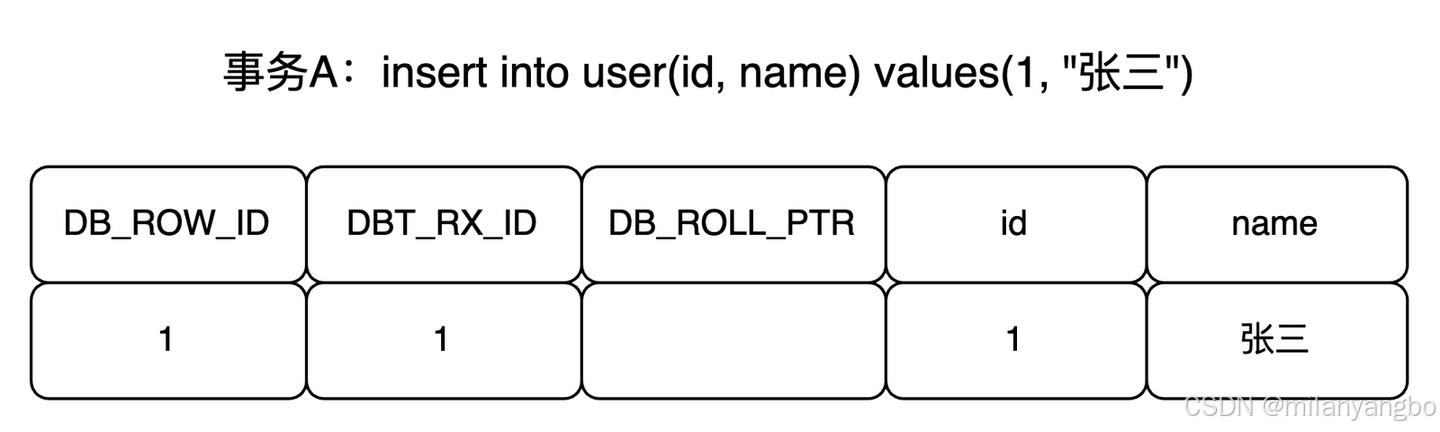
現在來了一個事務B對該記錄的name做出了修改,改為“李四”。
在事務B修改該行數據時,數據庫會先對該行加鎖,然後把該行數據拷貝到回滾日誌中作為舊記錄,即在回滾日誌中有當前行的拷貝副本。
拷貝完畢後,修改該行name為“李四”,並且修改該行的事務ID為當前事務B的ID, 並將回滾指針指向拷貝到回滾日誌的副本記錄,即表示上一個版本就是它,事務提交後,釋放鎖。
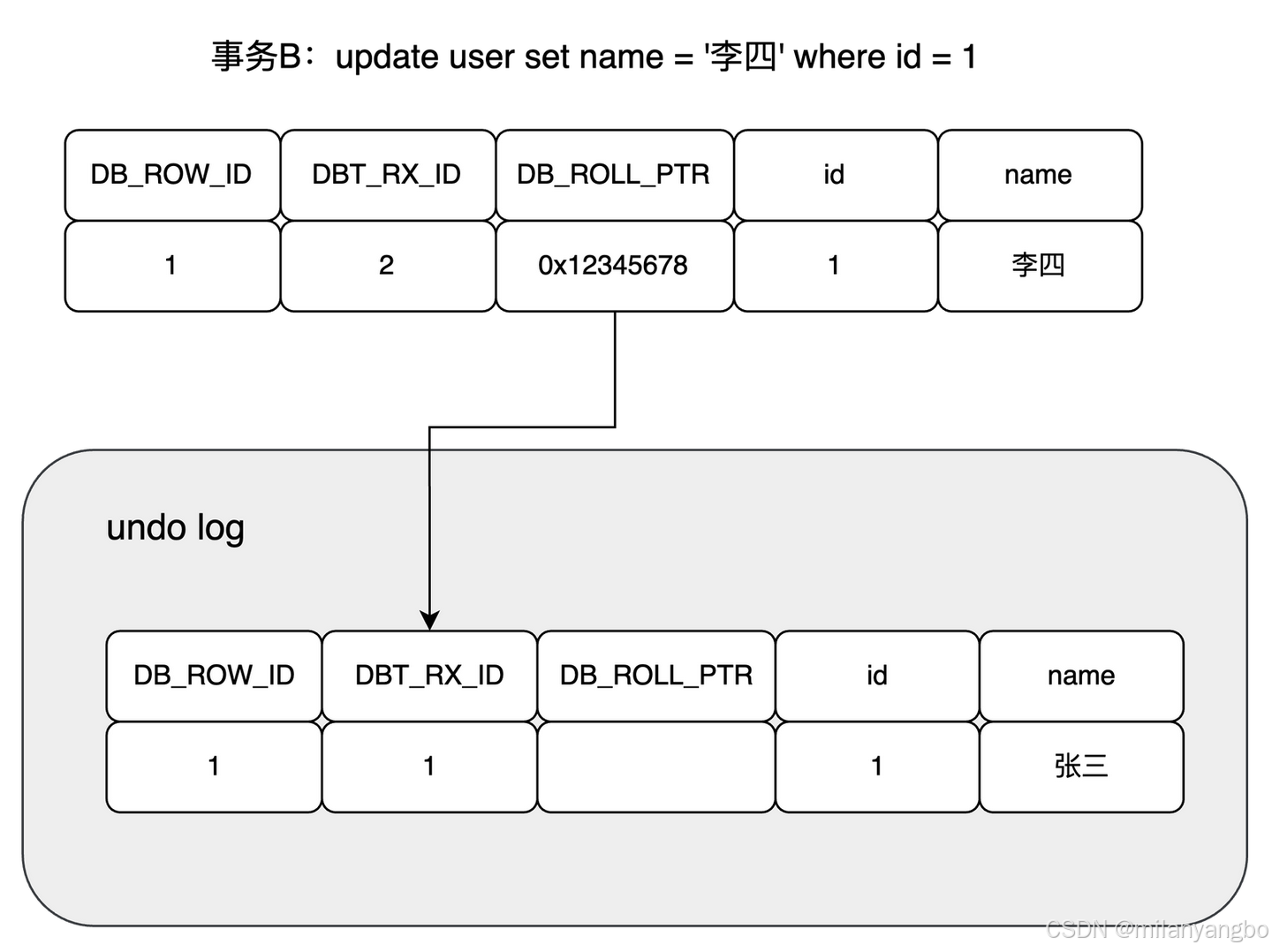
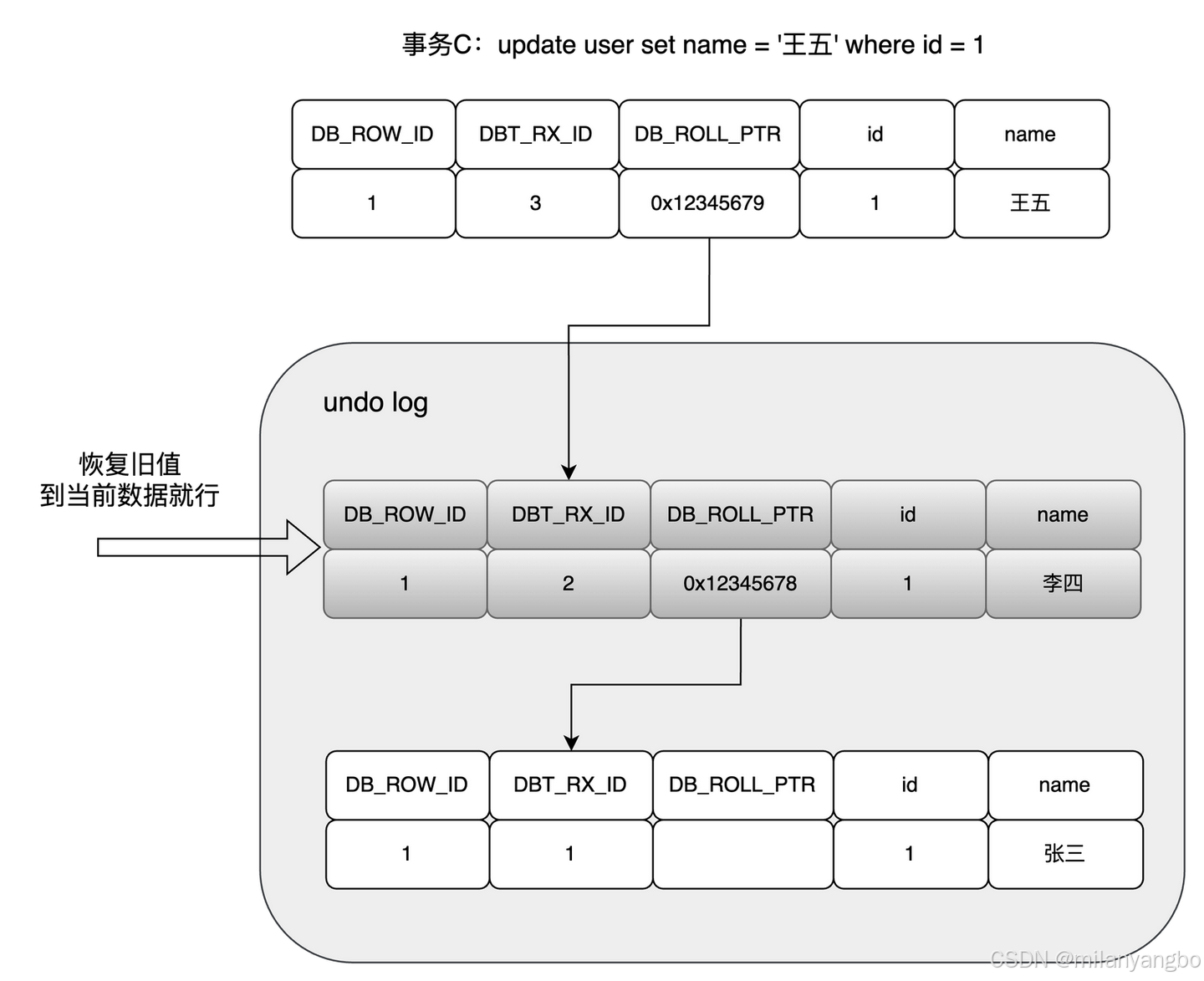
此時又來了個事務C修改同一個記錄,將name修改為“王五”。
在事務C修改該行數據時,數據庫也先為該行加鎖,然後把該行數據拷貝到回滾日誌中,作為舊記錄,發現該行記錄已經有回滾日誌了,那麼最新的舊數據作為鏈表的表頭,插在該行記錄的回滾日誌最前面。

現在想回滾到事務B,name值為“李四”的時候,只需通過回滾日誌的鏈表指針順着列表找到對應的回滾日誌日誌,將舊值恢復到數據行即可。
隔離級別
事務隔離級別是數據庫系統中用於控制併發訪問的機制,以確保數據的一致性和完整性。常見的事務隔離級別包括:讀未提交(Read Uncommitted)、讀已提交(Read Committed)、可重複讀(Repeatable Read)、序列化(Serializable)。
1)讀未提交:讀未提交隔離級別允許事務讀取其他事務未提交的數據,可能導致髒讀(Dirty Read)。寫操作可能使用鎖,但讀操作不等待其他事務的鎖釋放。
transaction T1 {
// 不使用鎖
read(data);
// 寫操作
write(data);
commit();
}
transaction T2 {
// 不使用鎖
read(data); // 可能從T1讀到未提交的數據
// 寫操作
write(data);
commit();
}
2)讀已提交:只允許事務讀取其他事務已提交的數據,防止髒讀。讀操作通常使用共享鎖(Shared Lock),且在讀取後立即釋放。寫操作使用排他鎖(Exclusive Lock),直到事務提交時釋放。
transaction T1 {
// 寫操作使用排他鎖
lock(exclusive, data);
write(data);
commit();
// 釋放排他鎖
unlock(exclusive, data);
}
transaction T2 {
// 讀操作使用共享鎖
lock(shared, data);
read(data); // 只讀取已提交的數據
// 讀取數據以後,立即釋放共享鎖
unlock(shared, data);
// 寫操作使用排他鎖
lock(exclusive, data);
write(data);
commit();
// 釋放排他鎖
unlock(exclusive, data);
}
3)可重複讀:確保事務在整個過程中讀取的數據一致,防止不可重複讀。讀操作使用共享鎖,並保持直到事務結束。寫操作使用排他鎖直到事務結束。此外,為防止幻讀,可能還需要使用間隙鎖(Gap Lock),以鎖定數據間隙。
transaction T1 {
// 寫操作使用排他鎖
lock(exclusive, data);
write(data);
commit();
// 釋放排他鎖
unlock(exclusive, data);
}
transaction T2 {
// 讀操作使用共享鎖
lock(shared, data);
read(data); // 在整個事務中讀取一致的數據
// 間隙鎖隱式通過查詢條件鎖定範圍(如`WHERE id BETWEEN 1 AND 10`)
lock(gap, range_data);
read(range_data); // 鎖定間隙,防止幻讀
// 寫操作使用排他鎖
lock(exclusive, data);
write(data);
commit();
// 釋放共享鎖、間隙鎖和排他鎖
unlock(exclusive, data);
unlock(gap, range_data);
unlock(shared, data);
}
3)序列化:確保事務完全隔離,防止幻讀,提供最高的隔離級別。使用範圍鎖(Range Lock)等機制,鎖定數據的範圍,確保事務之間的完全隔離,防止幻讀。
transaction T1 {
// 對讀和寫操作,使用範圍鎖
lock(range, data);
read(data);
write(data);
commit();
// 釋放範圍鎖
unlock(range, data);
}
transaction T2 {
// 對讀和寫操作,使用範圍鎖
lock(range, data);
read(data); // 避免幻讀
write(data);
commit();
// 釋放範圍鎖
unlock(range, data);
}
MySQL默認選用可重複讀作為事務隔離級別,這主要得益於其通過多版本併發控制機制,在事務啓動時即創建數據快照。這一設計確保了同一事務內多次讀取操作的結果保持一致,從而有效規避了讀已提交級別下可能出現的不可重複讀問題。
與此同時,InnoDB存儲引擎通過運用間隙鎖和臨鍵鎖(Next-Key Lock)技術,對索引範圍進行鎖定,顯著降低了幻讀現象(多次讀取同一數據範圍時,由於其他事務的插入或刪除操作,導致每次讀取的結果集不同)的發生概率。這是讀已提交級別所無法實現的,因為該級別無法對索引範圍進行如此精細的鎖定。
儘管在併發寫場景下,讀已提交級別的性能可能稍勝一籌,但可重複讀級別通過快照讀(無需加鎖)與當前讀(需加鎖)的巧妙結合,在保障數據一致性的同時,也維持了較高的系統性能。
此外,MySQL在設計上更傾向於優先避免數據異常,特別是在處理銀行賬户、金融交易等關鍵業務場景時,數據的一致性和完整性至關重要。當然,用户仍可根據實際需求,手動將事務隔離級別切換至讀已提交,以適應高併發寫入場景的特殊要求。
總結:從硬抗到疏導,駕馭流量的藝術
緩存層設計需在即時響應和擴展性之間權衡:本地內存訪問速度快,但容量有限;跨節點共享數據則會增加網絡延遲。同時,要防範緩存穿透(過濾無效請求)、緩存擊穿(對熱點數據進行加鎖控制)和緩存雪崩(分散緩存過期時間)等問題。
消息隊列通過異步解耦機制,兼顧實時性與系統容錯能力。Kafka利用分區順序寫入特性處理海量數據流,RocketMQ則藉助二次確認與補償機制,確保資金交易等場景無差錯。
數據庫層藉助日誌追加記錄操作軌跡,採用版本快照隔離讀寫操作。查詢時訪問固定版本的數據,避免鎖衝突;更新時生成新版本,確保事務的完整性。
併發系統設計的精髓,並非是追求單一組件的極致性能,而是一種關於“流動”與“控制”的藝術。它要求不再將壓力視為需要硬抗的敵人,而是將其視為需要引導和疏解的能量。通過分層設計,將一個巨大而不可控的壓力問題,分解為一系列更小、更清晰、更易於管理的子問題,並在每一層都做出最恰當的權衡與取捨。
很高興與你相遇!如果你喜歡本文內容,記得關注哦!!!