業務痛點:
AI推理是AI領域中將大模型轉化為應用效果與商業價值的核心技術,但在實際生產部署中仍然面臨着多樣化算力場景下的效率低與可部署性成本高,高併發、長上下文LLM推理場景中的性能和資源利用率瓶頸。
根因分析:
- 用户體驗與資源效率瓶頸:當前長上下文LLM推理的首Token延時普遍在數百毫秒至秒級,且長上下文場景下KV緩存顯存佔用呈線性增長,嚴重製約Agent的響應效率與部署規模;傳統靜態批處理無法適配動態負載,導致短請求被長請求阻塞(對頭阻塞問題)。
- 企業生產級場景挑戰:企業生產場景,普遍存在高推理成本、多樣化算力(GPU算力 + 國產化算力)利用率低、SLA難以保障、生產級規模部署管理複雜等問題。
- 雲原生AI全棧挑戰:現有云原生調度(如Kubernetes)缺乏LLM感知能力,無法優化KV緩存生命週期、動態批處理等場景。
高性能AI推理服務化框架方案
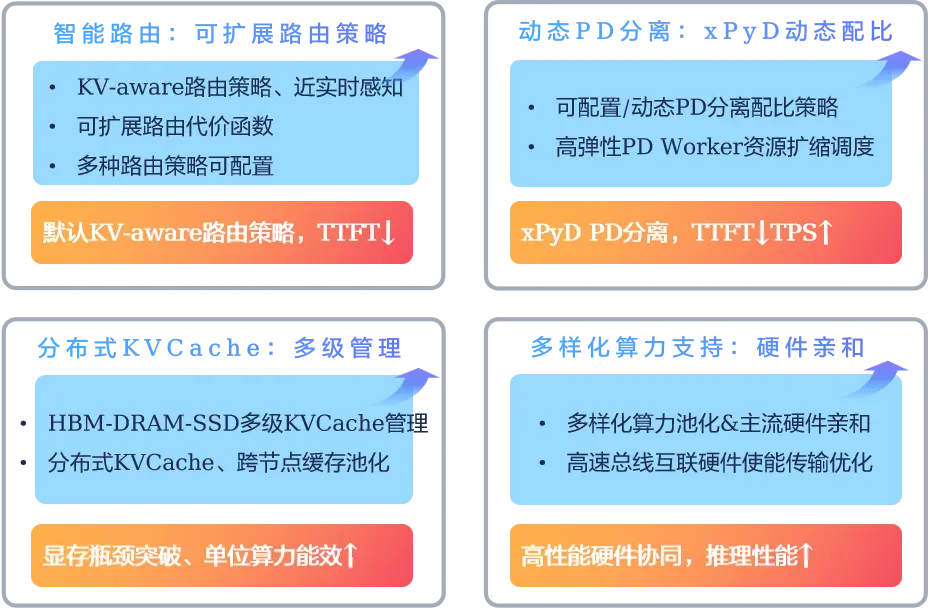
openFuyao通過“聚焦智能動態路由 + xPyD計算動態資源管理調度 + 分佈式KVCache/KVCache優化 + 端到端易用性 + 推理場景可觀測體系”高性能、可擴展子系統的構建,致力於系統性突破當前LLM推理的瓶頸,同時面向超節點場景進一步加速,支持靈衢、CXL、NVLink等高速總線:

- 首Token延時(TTFT)降低:智能路由與緩存命中策略優化、近實時集羣節點負載感知。
- 推理吞吐提升:彈性xPyD分離架構升級、高性能彈性配比。
- N/S、E/W全局顯存瓶頸突破:多級KVCache、集羣KVCache池化;結合高性能傳輸協議和去中心化高性能硬件,進一步降低KVCache傳輸延遲。
- 資源利用率提升:通過動態資源調度配比和異構算力池化進一步提升資源利用率。