

公共資源速遞
6 個公共數據集:
- Freebayes_Benchmark 基準測試集
- DiaMoE-TTS 多方言語音表音數據集
- APEX 人工智能生產力評測基準數據集
- BWA_Benchmark(SBC)基準測試集
- DeePMD-kit_Example 勢能模型示例數據集
- Facial Emotion Recognition 面部情感識別數據集
5 個公共教程 :
- DiffVox: 聲音區分效果模型
- HunyuanWorld-Mirror:3D 世界生成模型
- PaddleOCR-VL:多模態文檔解析
- LongCat-Video:美團開源的AI視頻生成模型
- 一鍵部署 SmolLM3-3B:3B 級長上下文雙模推理模型
訪問官網立即使用:http://openbayes.com
公共數據集
1.Freebayes_Benchmark 基準測試集
Freebayes_Benchmark 是一個用於評估 FreeBayes 變異檢測工具性能的標準基準集,包含公開測序樣本的 BAM/FASTA 文件與可復現運行參數。該數據集結構完整,可用於比較不同版本、構建方式及硬件平台下的運行速度與結果一致性,適合作為本地環境驗證與管線優化的參考。
在線使用:
https://go.openbayes.com/K67hu
2. DiaMoE-TTS 多方言語音表音數據集
DiaMoE-TTS 是一個面向多方言 TTS 任務的語音表音數據集,基於多種開源方言語料構建,並採用統一的 IPA 表音體系進行了標準化處理。數據覆蓋多類型方言,結構規範,可直接用於方言建模、跨方言遷移學習與零樣本語音合成研究。
在線使用:
https://go.openbayes.com/u0aIC
3. APEX 人工智能生產力評測基準數據集
APEX 是用於評估前沿 AI 模型在高價值知識工作中表現的綜合基準,涵蓋投行、諮詢、法律與基礎醫療四類專業任務。數據集包含 200 個真實案例及可解釋評分標準,可直接用於模型的專業能力測評與跨領域執行力分析。
在線使用:
https://go.openbayes.com/NJBCO
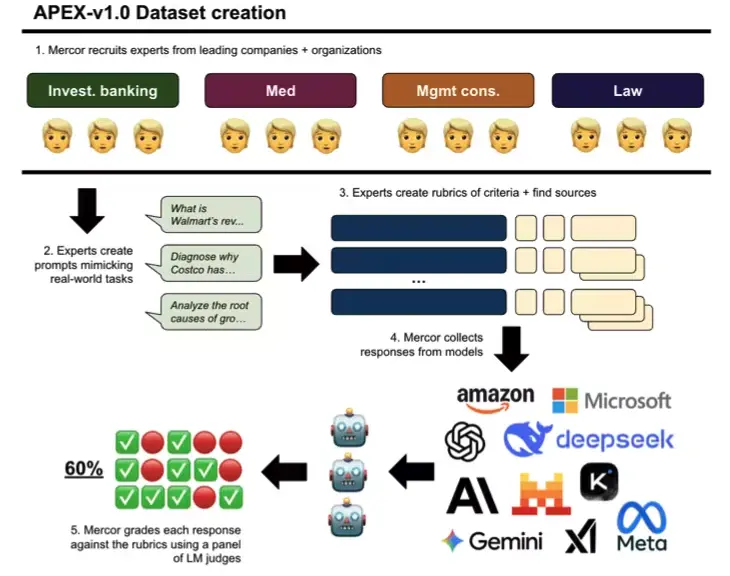
數據集構建流程
4. BWA_Benchmark(SBC)基準測試集
BWA_Benchmark(SBC)用於評估 BWA 在單板計算機及移動設備等資源受限平台上的比對性能。基準提供大腸桿菌參考基因組、真實短讀序列與統一運行參數,可用於比較不同 CPU 架構、系統位寬和線程配置下的比對效率與可用性。
在線使用:
https://go.openbayes.com/rENCg
5. DeePMD-kit_Example 勢能模型示例數據集
DeePMD-kit_Example 是 DeePMD-kit 提供的官方示例集,涵蓋多種體系的訓練樣例、模型配置與分子動力學任務設置。數據組織清晰,可作為驗證環境配置、學習勢能模型構建流程與搭建自定義 Deep Potential 模型的標準模板。
在線使用:
https://go.openbayes.com/1DpRF
6. Facial Emotion Recognition 面部情感識別數據集
Facial Emotion Recognition 數據集是一個用於面部情緒分類的標準基準,涵蓋 7 類基礎情緒,並基於 FER2013 與 RAF-DB 融合構建。所有圖像均經過統一的人臉篩選與 RGB 規範化處理,數據結構清晰、質量穩定。數據集提供標準情緒標籤,可直接用於情緒識別模型訓練、驗證與相關人機交互研究。
在線使用:
https://go.openbayes.com/ULoBC

數據集示例
公共教程
1. DiffVox: 聲音區分效果模型
DiffVox 是由索尼 AI、索尼集團與倫敦瑪麗女王大學聯合發佈的新一代人聲音效風格遷移模型。其核心通過推理時優化技術與高斯先驗約束,能夠在不犧牲混音參數合理性的情況下,將原始幹聲精準轉化為高度貼近目標參考的聲音風格效果。作為專注於人聲風格建模的先進系統,DiffVox 能捕捉並重建豐富的音效分佈特徵,為音樂製作、音頻後期和聲效生成提供專業級智能支持。
在線運行:
https://go.openbayes.com/gh7EQ
項目示例
2.PaddleOCR-VL:多模態文檔解析
PaddleOCR-VL 是面向文檔解析場景的高效視覺語言模型,以緊湊的 PaddleOCR-VL-0.9B 為核心。模型結合動態分辨率視覺編碼器與 ERNIE-4.5-0.3B 語言模型,可精準解析文本、表格、公式、圖表等複雜文檔結構,同時支持 109 種語言。PaddleOCR-VL 在頁面級與元素級任務上均達成行業領先(SOTA)表現,並保持極低資源開銷與高速推理,非常適用於企業級文檔自動化、金融票據理解與多語言檔案解析等大規模落地場景。
在線運行:
https://go.openbayes.com/kxl4t
項目示例
3. HunyuanWorld-Mirror:3D 世界生成模型
HunyuanWorld-Mirror 是騰訊混元團隊於 2025 年發佈的高性能 3D 世界重建模型。支持多視圖圖像與視頻等多模態輸入,可輸出點雲、深度圖、相機姿態等多類型三維幾何結果。其純前饋架構可在單張顯卡上實現處理 8–32 視圖的秒級推理,結合動態先驗注入與課程學習策略,有效提升對複雜場景的幾何表達能力。HunyuanWorld-Mirror 在 3D 點雲重建與端到端 3DGS 重建任務中展現了行業領先的細節還原與幾何精度。
在線運行:
https://go.openbayes.com/B8sCb
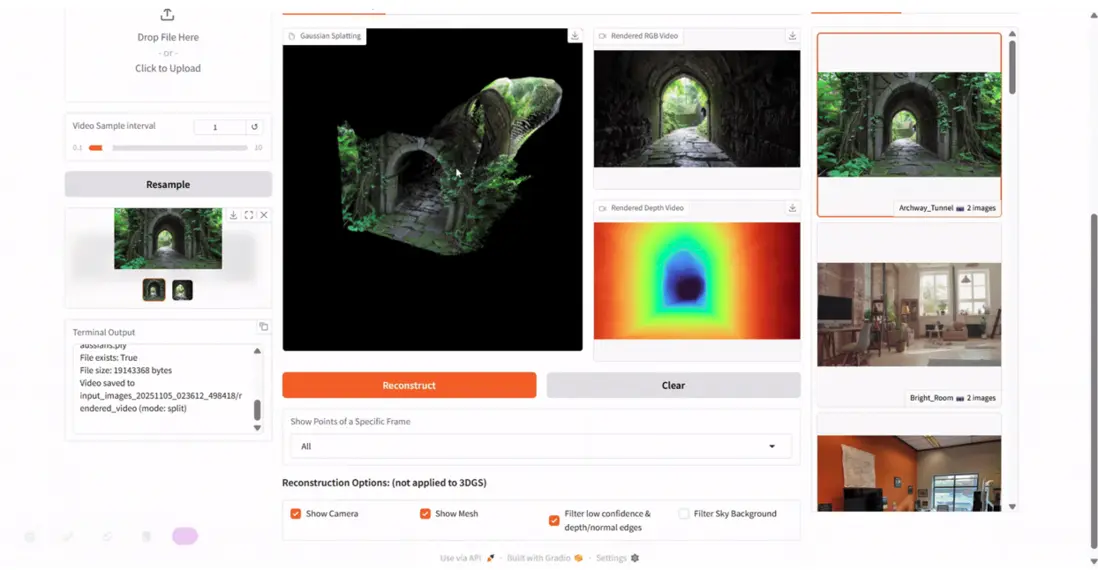
項目示例
4. LongCat-Video:美團開源的AI視頻生成模型
LongCat-Video 是美團 LongCat 團隊開源的 136 億參數視頻生成大模型,專為文本到視頻(T2V)、圖像到視頻(I2V)和視頻續寫任務而設計。通過多獎勵強化學習(GRPO)優化,模型在長視頻一致性、高分辨細節生成和時序穩定性方面均達到領先水平。得益於開源特性與卓越的生成能力,LongCat-Video 在內部及公共基準測試上表現可與先進商用系統相媲美,為高質量長視頻生產提供了強大工具鏈。
在線運行:
https://go.openbayes.com/ph6Iy
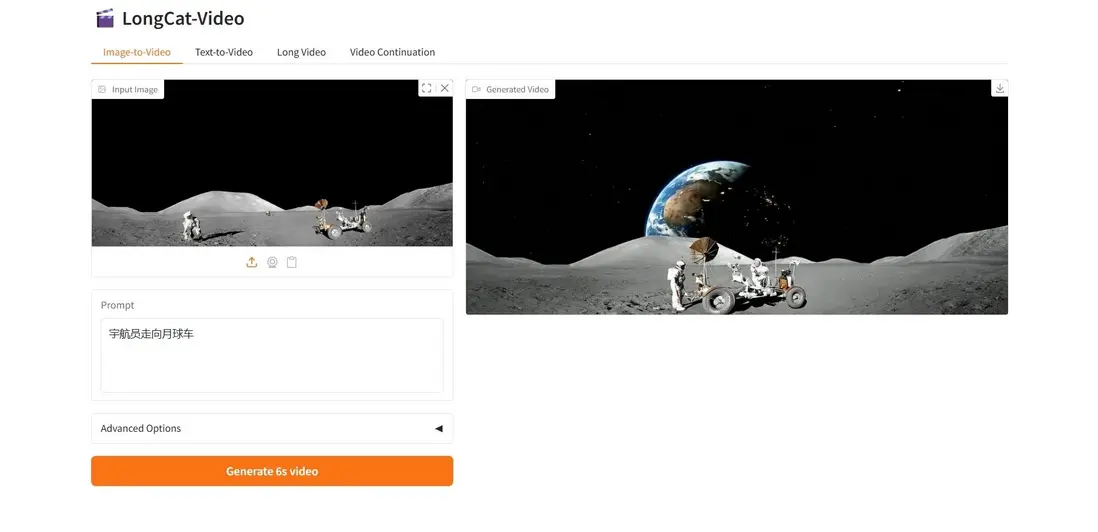
項目示例
5. 一鍵部署 SmolLM3-3B:3B 級長上下文雙模推理模型
SmolLM3-3B 是 Hugging Face TB 團隊於 2025 年 7 月開源推出的輕量級長上下文推理模型。作為一款僅 3B 參數卻定位於「端側性能天花板”的開源模型,它在緊湊規模下依然展現出強大的多語言處理能力、長序列理解能力與雙模態推理能力。依託高效量化技術與推理優化策略,SmolLM3-3B 能在資源受限的設備上穩定運行,並在多項任務中實現接近更大模型的表現,非常適合本地化部署與移動端 AI 應用落地。
項目示例
在線運行:
https://go.openbayes.com/imofO