

公共資源速遞
5 個公共數據集:
- 3EED 語言驅動三維理解數據集
- X-Dance 圖像驅動舞蹈動作數據集
- PhysToolBench 物理工具任務數據集
- OST-Bench 時空場景理解基準數據集
- Astrophysical Objects Image 天體物理物體圖像數據集
4 個公共教程:
- SAM3:視覺分割模型
- FLUX.2-dev:圖像生成與編輯模型
- Supertonic:基於 ONNX 的極速 TTS 語音合成模型
- Eigen-Banana:使用 Qwen-Image-Edit LoRA 快速圖像編輯
訪問官網立即使用:http://openbayes.com
公共數據集
- 3EED 語言驅動三維理解數據集
3EED 數據集共包含 20,367 個時間對齊的多模態幀,覆蓋車輛、無人機與四足機器人三類平台。數據提供 128,735 個三維目標框以及 22,439 條經過人工驗證的語言指代表達,是當前規模較大的三維視覺指代數據集之一。
在線使用:
https://go.openbayes.com/MB6Ol
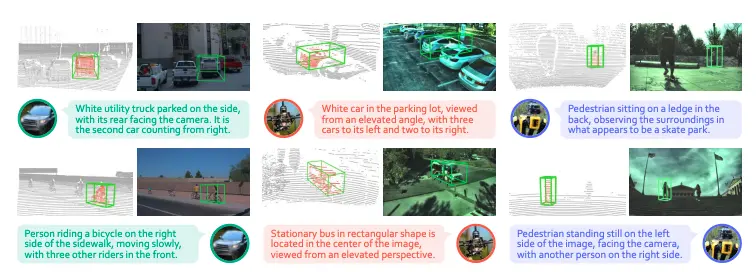
數據集示例
2. X-Dance 圖像驅動舞蹈動作數據集
X-Dance 數據集包含 12 段驅動視頻,其中 8 段為高動態舞蹈動作,4 段為低幅度日常行為,涵蓋運動模糊、遮擋、姿態劇變等多種真實場景變化。針對每段動作,數據集構建多源參考圖像,包括動漫角色、半身照片、跨風格人物以及姿態差異顯著的圖像,用於模擬空間結構不一致與時間起點不連續等情況。
在線使用:
https://go.openbayes.com/m1mdE

數據集示例
3. OST-Bench 時空場景理解數據集
OST-Bench 數據集包含約 1,400 個真實室內三維場景,並基於探索軌跡生成約 10,000 條多輪時序問答樣本,旨在評估模型的在線時空場景理解能力。場景來自多個室內三維數據源,並基於統一的物體與語義標註進行處理。
在線使用:
https://go.openbayes.com/k1zHC

數據集示例
4. PhysToolBench 物理工具任務數據集
PhysToolBench 數據集包含超過 1,000 條圖像–文本樣本,覆蓋日常生活、工業操作、户外作業與專業場景等多種環境,旨在評估模型在物理工具識別、理解與創造方面的能力。數據依據任務複雜度劃分為易、中、難三個等級,並構建三類核心任務:工具創造、工具識別與工具理解。
在線使用:
https://go.openbayes.com/Y8QY1
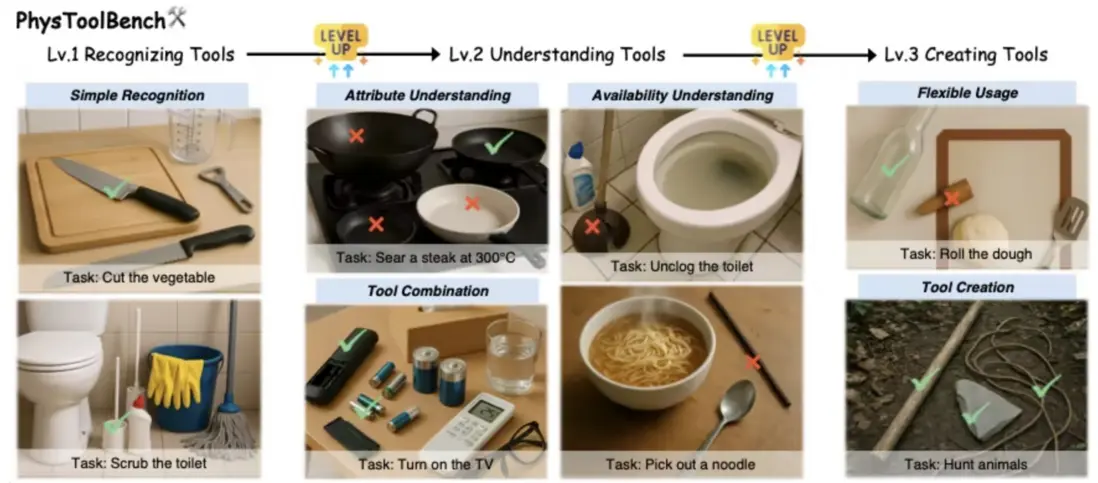
數據集示例
5. Astrophysical Objects Image 天體物理物體圖像數據集
Astrophysical Objects Image 是一個面向天文學與天體物理研究的深度學習圖像數據集,數據集圖像來自多個公開天文數據源,按照類別組織為 12 類天體文件夾,所有圖像均按類別規範存放。
在線使用:
https://go.openbayes.com/rzRTk

數據集示例
公共教程
1. SAM3:視覺分割模型
SAM3 是 Meta AI 發佈的先進計算機視覺模型,支持通過文本短語、圖像示例和視覺提示完成圖像與視頻中的對象檢測、分割與跟蹤。模型具備開放詞彙能力,可實時修正分割結果,並在零樣本條件下保持穩定泛化。在圖像與視頻分割任務中,SAM3 的表現達到前代系統的兩倍,並進一步擴展至 3D 重建領域,為家居預覽、創意編輯與科研場景提供更強大的視覺基礎能力。
在線運行:
https://go.openbayes.com/4WT0m

項目示例
2. FLUX.2-dev:圖像生成與編輯模型
FLUX.2 是 Black Forest Labs 發佈的新一代 AI 圖像生成模型,專為專業創意工作流程打造。模型支持最多 10 張參考圖輸入,能夠生成最高 4MP 分辨率的高質量畫面,並在細節刻畫與文本渲染方面表現突出。基於視覺語言模型與流變換器架構的結合,FLUX.2 全面提升了圖像生成的穩定性與真實感,為設計、廣告與數字內容生產提供更高效的視覺創作能力。
在線運行:
https://go.openbayes.com/5anAh
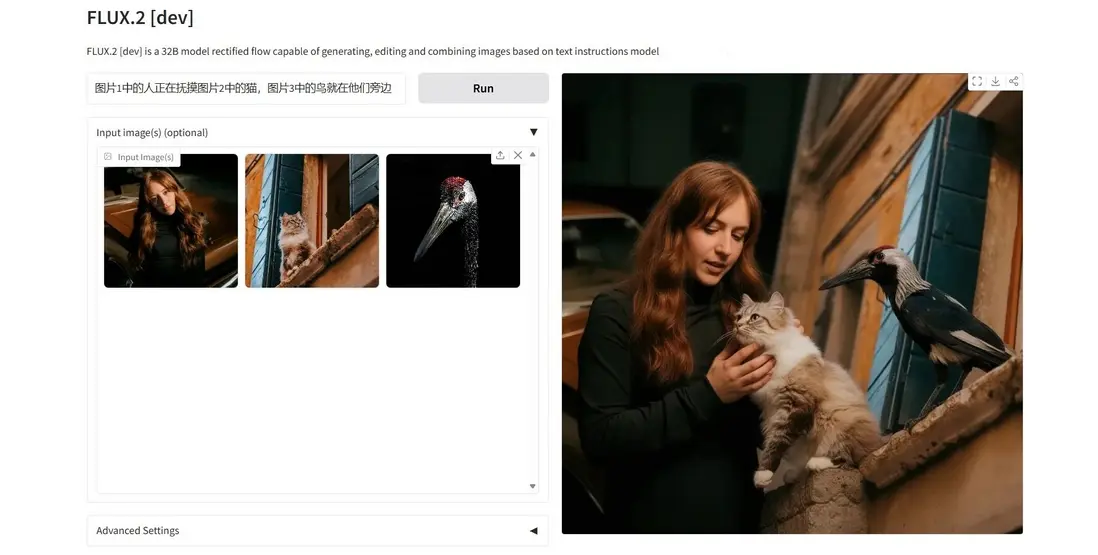
項目示例
3. Supertonic:基於 ONNX 的極速 TTS 語音合成模型
Supertonic 是 Supertone 推出的本地文本轉語音引擎,基於 ONNX Runtime 開發,重點優化低延遲與高並發表現。它在保證高質量語音合成的同時大幅降低硬件門檻,可在桌面端、服務器及邊緣設備實現完全離線的實時推理。得益於其本地化特性,Supertonic 特別適用於隱私敏感場景及對實時交互要求較高的應用,如數字人、遊戲語音與本地語音助手。
在線運行:
https://go.openbayes.com/D1Rza
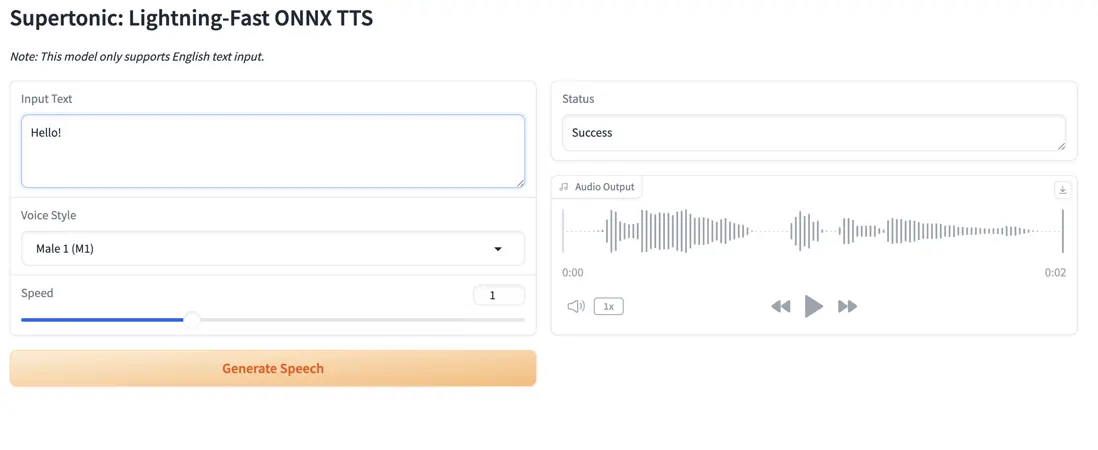
項目示例
4. Eigen-Banana:使用 Qwen-Image-Edit LoRA 快速圖像編輯
Eigen-Banana-Qwen-Image-Edit 是 Eigen AI 推出的基於 Qwen-Image-Edit 的 LoRA 適配模型,面向高質量且高效率的文本驅動圖像編輯。模型基於 Apple 的 Pico-Banana-400K 數據集訓練,在物體調整、風格轉換等多類編輯任務中表現優異,並通過減少推理步驟顯著提升編輯速度。該模型適用於創意設計、圖像增強與快速原型圖生成等場景。
在線運行:
https://go.openbayes.com/OSyCV
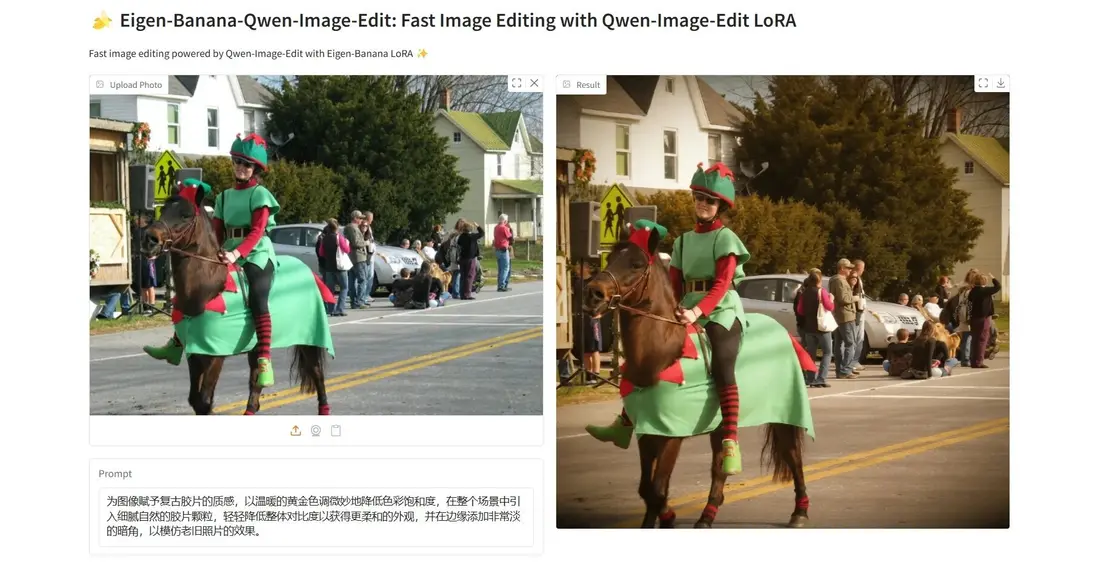
項目示例