

公共資源速遞
5 個公共數據集:
- FirstAidQA 急救知識問答數據集
- PhysDrive 駕駛員生理測試數據集
- PolypSense3D 息肉尺寸感知數據集
- Envision 多階段事件視覺生成數據集
- Care-PD 帕金森三維步態評估數據集
8 個公共模型:
- SAM 3
- Z-Image-Turbo
- Ovis-Image-7B
- Ministral-3-14B
- LongCat-Image
- Open-AutoGLM
- VibeVoice-Realtime-0.5B
- Eigen-Banana-Qwen-Image-Edit
5 個公共教程:
- RFdiffusion3:蛋白質設計模型
- Open-AutoGLM:手機端智能助理
- MarkItDown 微軟開源的文檔轉換工具
- LongCat-Image:雙語文本驅動圖像生成系統
- LightOnOCR-1B-Interface:面向複雜文檔的高速 OCR 引擎
訪問官網立即使用:http://openbayes.com
公共數據集
1. FirstAidQA 急救知識問答數據集
FirstAidQA 包含 5,500 條高質量文本問答對,全部圍繞急救與應急響應場景構建。數據內容覆蓋急救操作流程、緊急處置方法與安全注意事項,問答結構清晰、專業性強。所有樣本均基於權威急救教材生成,文本形式統一,適合用於急救知識問答與應急場景下的語言模型訓練與評測。
在線使用:
https://go.openbayes.com/kVEdl
2. PhysDrive 駕駛員生理測試數據集
PhysDrive 包含約 24 小時(約 150 萬幀)的多模態駕駛數據,採集自 48 名駕駛員的真實駕駛過程。每位受試者完成 6 個約 5 分鐘的駕駛片段,覆蓋多種光照條件、車型、駕駛動作與道路環境。數據同步提供 RGB 視頻、近紅外視頻與毫米波雷達信號,並配套多類生理真值標註,適合用於非接觸式生理測量與駕駛員狀態分析。
在線使用:
https://go.openbayes.com/Qe9U0

數據集示例
3. PolypSense3D 息肉尺寸感知數據集
PolypSense3D 是一個多源內鏡數據集,由虛擬仿真、實體仿體與真實臨牀三類數據組成。虛擬數據包含 32,000+ 幀,提供 RGB、密集深度、分割掩碼與相機參數;實體仿體數據基於 3D 打印結腸模型採集,包含精確尺寸標註;臨牀數據來自真實內鏡檢查,提供凍結幀、分割結果與基於校準器具的尺寸標註,適合用於息肉檢測、深度估計與尺寸測量研究。
在線使用:
https://go.openbayes.com/a9iPA
4. Envision 多階段事件視覺生成數據集
Envision 數據集由 1,000 個完整事件序列與 4,000 條四階段文本提示組成,每個事件被拆分為多個時間階段,形成明確的階段遞進結構。數據覆蓋自然科學與人文歷史等六大領域,事件素材來源於教材與公開資料,並經過統一生成與潤色,強調因果關係與多階段演化,適合用於事件理解與多階段生成任務。
在線使用:
https://go.openbayes.com/PYeFr
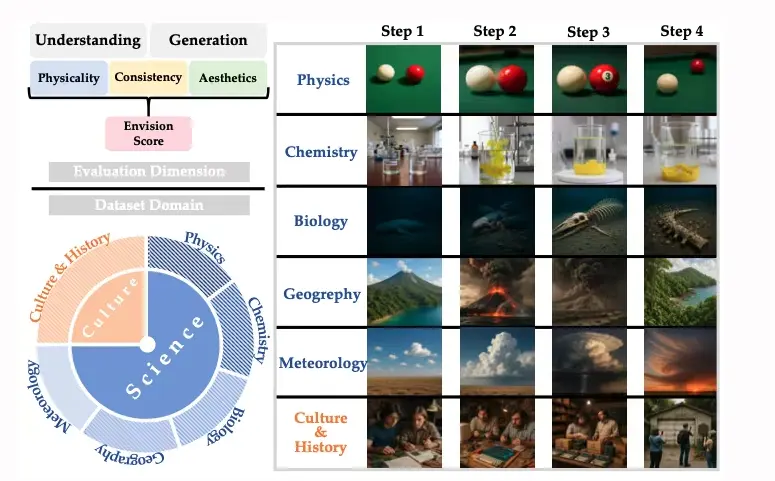
數據集示例
5. Care-PD 帕金森三維步態評估數據集
CARE-PD 包含 362 名受試者的步態數據,來源於 8 個臨牀機構、9 個獨立隊列,是目前公開規模較大的帕金森病三維步態數據集。所有原始視頻與動作捕捉數據均被統一轉換為匿名化的 SMPL 三維人體步態網格。數據集由 9 個子集構成,涵蓋不同藥物狀態、步態亞型與臨牀評分信息,適合用於步態建模、疾病評估與跨隊列分析研究。
在線使用:
https://go.openbayes.com/YrC2A
公共模型
1. SAM 3
發佈機構: Meta AI
SAM 3 是新一代通用視覺分割模型,引入「可提示概念分割」機制,可通過自然語言或示例圖像指定分割目標。模型能夠在圖像與視頻中自動檢測、分割並持續追蹤同一概念下的所有實例,並具備良好的零樣本泛化能力,同時擴展支持 3D 場景理解,在通用分割與複雜視覺理解任務中表現突出。
在線使用:https://go.openbayes.com/vpxfY
2. Z-Image-Turbo
發佈機構: 阿里通義實驗室
Z-Image-Turbo 總參數規模為 6B,基於單流擴散 Transformer(S3-DiT)架構,在極少採樣步數下實現高質量圖像生成。模型僅需約 8 步推理即可輸出接近印刷級質量的圖像,在推理速度與硬件成本方面具備顯著優勢,同時在中文提示詞理解與中英文字渲染方面表現突出。
在線使用:https://go.openbayes.com/HGdWh
3. Ovis-Image-7B
發佈機構: Ovis
Ovis-Image-7B 是一款參數規模為 7B 的文本生成圖像模型,針對文本渲染任務進行了專項優化。模型在文字密集、版式敏感的提示詞場景中具備穩定表現,能夠準確生成清晰可辨的文本內容,併兼顧整體視覺一致性,在較低資源條件下也具備良好的部署與推理效率。
在線使用:https://go.openbayes.com/cK8SC
4. Ministral-3-14B
發佈機構: Mistral AI
Ministral-3-14B 是一款 14B 參數規模的多模態對話模型,在保持輕量化體量的同時實現了較強的指令遵循與多輪對話能力。模型支持較長上下文窗口,並在推理效率與部署友好性方面表現平衡,適合本地 AI 應用開發、對話系統構建與二次研究。
在線使用:https://go.openbayes.com/iITIL
5. LongCat-Image
發佈機構: 美團 LongCat 團隊
LongCat-Image 是一款 6B 參數規模的圖像生成與編輯基礎模型,在中英文雙語文本理解與文字渲染方面具備明顯優勢。模型在保持較高生成效率的同時,實現了真實感較強的視覺輸出,並在多項生成與編輯任務中表現穩定,適合多語言內容生成與圖像編輯場景。
在線使用:https://go.openbayes.com/PjpLD
6. Open-AutoGLM
發佈機構:智譜 AI
Open-AutoGLM 是一款具備手機端操作能力的多模態智能體模型,能夠理解真實手機屏幕內容並自動執行點擊、滑動與輸入等操作。模型採用「感知–規劃–行動–反思」的執行框架,可穩定完成多步驟、跨應用的複雜任務,並支持敏感操作確認與人工接管,適用於移動端自動化與智能助理研究。
在線使用:https://go.openbayes.com/mn9Ot
7. VibeVoice-Realtime-0.5B
發佈機構: Microsoft
VibeVoice-Realtime-0.5B 參數規模為 0.5B,是一款專為超低延遲交互設計的實時文本轉語音模型。該模型支持流式推理,可在約 300 毫秒內完成語音生成,並支持長時間音頻輸出與多説話人自然對話,在極低計算開銷下實現高保真語音合成。
在線使用:https://go.openbayes.com/16kcX
8. Eigen-Banana-Qwen-Image-Edit
發佈機構: Eigen AI
Eigen-Banana-Qwen-Image-Edit 是基於 Qwen-Image-Edit 的圖像編輯 LoRA 權重,針對文本引導的高質量圖像編輯任務進行了優化。模型在較少推理步驟下即可完成物體操作、風格遷移等多類編輯任務,並保持良好的編輯一致性,適合快速、交互式的圖像編輯應用。
在線使用:https://go.openbayes.com/3xmgy
公共教程
1. RFdiffusion3:蛋白質設計模型
RFdiffusion3 是一款全原子級蛋白質生成模型,能夠在嚴格的空間與化學約束下直接建模分子間相互作用。模型支持精細到原子級的結構控制,可在設計階段同時考慮穩定性、功能性與結合位點構型,在複雜生物分子設計任務中具備較強的生成能力與靈活性,適用於高精度蛋白設計與結構研究。
在線運行:
https://go.openbayes.com/STGlr
2. Open-AutoGLM:手機端智能助理
Open-AutoGLM 通過多模態模型對手機屏幕進行感知,並結合規劃與執行機制實現端到端自動化操作。系統可在無需預定義腳本的情況下理解真實應用界面,並動態生成操作步驟,同時支持安全確認與人工介入,在複雜、多變的移動端場景中具備良好的泛化與可控性,適用於智能助理與自動化交互探索。
在線運行:
https://go.openbayes.com/3x4GU
3. MarkItDown 微軟開源的文檔轉換工具
MarkItDown 面向大模型應用場景設計,強調在文檔轉換過程中最大程度保留結構與語義信息。工具可穩定提取標題層級、列表關係、表格結構與鏈接引用,避免傳統純文本轉換造成的信息丟失,使複雜文檔更適合作為 LLM 的輸入格式,適用於文檔理解與知識處理流程。
在線運行:
https://go.openbayes.com/NuoO8
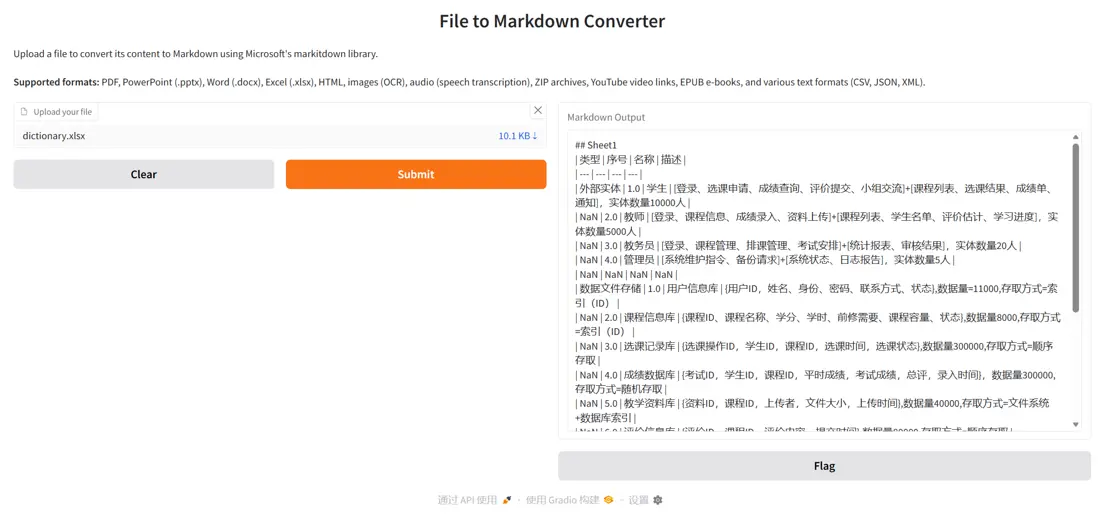
項目示例
4. LongCat-Image:雙語文本驅動圖像生成系統
LongCat-Image 是一款支持中英文雙語的圖像生成與編輯模型,在文本到圖像生成任務中兼顧生成質量與效率。模型在中文文本渲染準確性與覆蓋度方面表現突出,並在較小參數規模下實現高真實感的視覺輸出,適用於多語言內容生成與視覺創作場景。
在線運行:
https://go.openbayes.com/t4VCv

項目示例
5. LightOnOCR-1B-Interface:面向複雜文檔的高速 OCR 引擎
LightOnOCR-1B-Interface 基於端到端視覺–語言模型構建,可直接從高分辨率頁面中完成佈局感知文本解析。系統在表格、多欄排版與掃描文檔等複雜結構下保持穩定表現,併兼顧處理速度與解析精度,適用於大規模文檔解析與自動化 OCR 任務。
在線運行:
https://go.openbayes.com/MvFv5