

一文讀懂MOE:大模型背後的"專家分工"智慧
本文基於綜述論文:A Comprehensive Survey of Mixture-of-Experts Algorithms, Theory, and Applications(Siyuan Mu and Sen Lin)。如需深入瞭解,建議閲讀原文。
重點內容
- MoE(混合專家模型) 是當前大模型擴展的核心技術之一,DeepSeek、Mixtral、GPT-4 等明星模型都在用
- 核心思想:不是所有參數都參與每次計算,而是動態選擇最相關的"專家"子網絡來處理輸入,省算力、提性能
- 關鍵組件包括:門控函數(Router)、專家網絡(Experts)、路由策略(Routing)、訓練策略和系統設計
- MoE 已滲透到持續學習、元學習、多任務學習、強化學習、聯邦學習等多個範式
- 在計算機視覺(分類/檢測/分割/生成)和自然語言處理(理解/生成/翻譯/多模態)中均有廣泛應用
- 本文基於 Siyuan Mu & Sen Lin 的最新綜述,帶你係統梳理 MoE 的全貌
開篇:為什麼你需要關注 MoE?
想象一下,你經營一家醫院。面對不同的病人,你不會讓所有醫生同時出診——而是根據病情,把病人分配給最合適的專科醫生。心臟問題找心內科,骨折找骨科,各司其職,效率最高。
MoE(Mixture-of-Experts,混合專家模型)的思路如出一轍。
當今 AI 大模型面臨兩大核心挑戰:
- 算力爆炸:模型越來越大,訓練和部署成本飆升
- 數據異質性:現實數據極其複雜多樣,單一模型難以"面面俱到"
MoE 的解法很優雅——不激活所有參數,只讓最相關的"專家"子網絡工作。這樣既能擁有超大模型的容量,又能控制實際計算開銷。
DeepSeek-V3、Mixtral 8×7B、GPT-4(據傳)……這些刷屏的模型背後,都有 MoE 的身影。
本文基於一篇最新的全面綜述論文,帶你從零開始理解 MoE 的設計、算法、理論與應用。
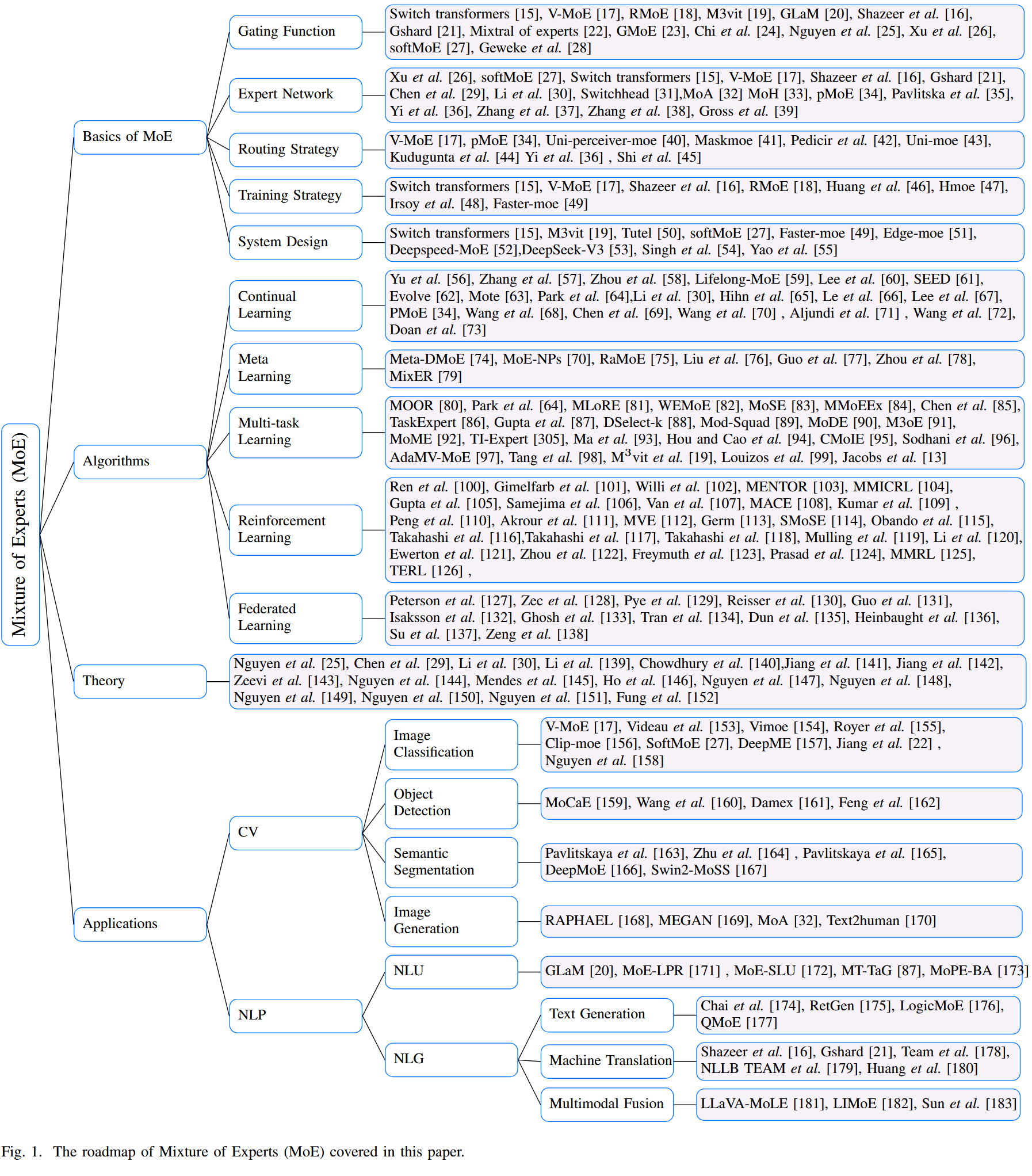
一、MoE 基礎架構:四大核心組件
一個標準的 MoE 層由以下部分組成:門控函數(Router/Gating) 決定"誰來幹活",專家網絡(Experts) 負責"幹活",路由策略 決定"在哪個粒度上分配",訓練策略 確保"大家都有活幹"。
1.1 門控函數(Gating Function):誰來接診?
門控函數是 MoE 的"調度中心",決定每個輸入應該交給哪些專家處理。
最常用的方案:線性門控 + Softmax + TopK
公式很直觀:先用一個線性層給每個專家打分,再通過 TopK 選出得分最高的 K 個專家,最後用 Softmax 歸一化權重。
設計門控函數時有兩個關鍵原則:
- 準確性:能識別輸入特徵,把相似的數據分給同一個專家
- 均衡性:數據要儘量均勻分配,避免某些專家"累死"、其他專家"閒死"
除了線性門控,還有一些變體值得關注:
- Expert Choice 門控:反轉視角,讓專家主動選擇要處理的 token(見綜述 Section II-A)
- Soft MoE:不再做離散的 token 分配,而是對所有 token 做加權平均生成輸入,避免了 token 丟棄問題
- 基於 Cosine 相似度的門控:用餘弦相似度替代線性打分,對輸入尺度更魯棒
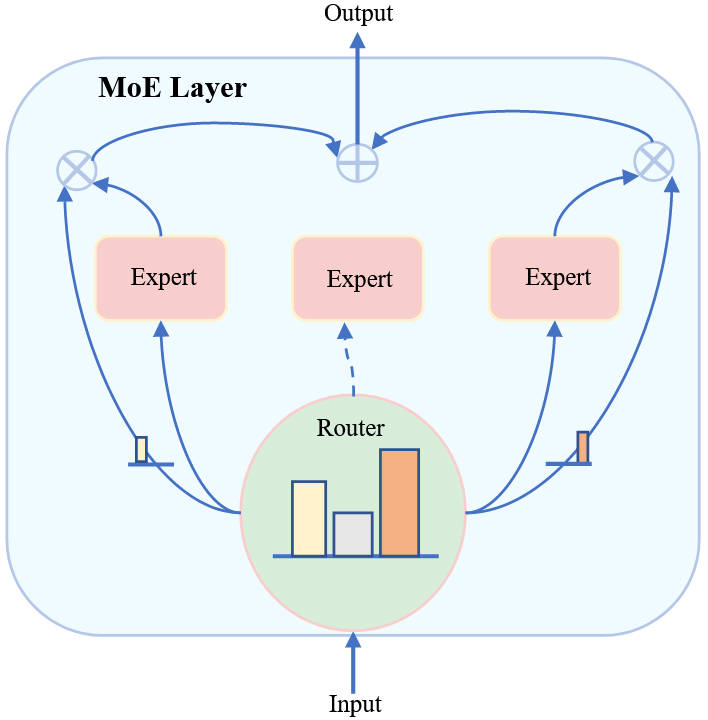
1.2 專家網絡(Expert Networks):各有所長
專家網絡是 MoE 的"幹活主力"。實踐中,MoE 層通常嵌入到已有網絡結構中,替換特定層。主流方案有三種:
方案一:替換 Transformer 的 FFN 層(最主流)
這是目前最廣泛的做法。Transformer 中的 FFN 層天然具有較高的稀疏性和領域特異性,非常適合用 MoE 替換。Switch Transformer、Mixtral、DeepSeek 系列都採用了這種設計。
方案二:替換注意力層(MoA / MoH)
Mixture-of-Head Attention(MoH)將多頭注意力中的每個頭視為一個"專家",通過路由機制動態選擇激活哪些頭,減少冗餘計算。
方案三:應用於 CNN 層
在計算機視覺中,CNN 專家可以利用卷積的局部特徵提取優勢,實現更精細的任務分配。
1.3 路由策略(Routing Strategy):在哪個粒度上分工?
路由策略決定了"在什麼層級上做專家分配",這直接影響模型的靈活性和效率。
| 路由級別 | 説明 | 適用場景 |
|---|---|---|
| Token 級別 | 每個 token 獨立路由,最細粒度 | LLM、通用場景(最常用) |
| 模態級別 | 按輸入模態(文本/圖像/音頻)路由 | 多模態模型 |
| 任務級別 | 按任務類型路由,推理時只加載相關專家 | 多任務學習,節省內存 |
| 其他級別 | 上下文級別、屬性級別等 | 複雜多任務場景 |
Token 級別路由是目前最主流的選擇,因為它粒度最細、靈活性最高。但任務級別路由在推理時有明顯優勢——只需加載當前任務相關的專家,大幅降低通信和內存開銷。
1.4 訓練策略:讓每個專家都"有活幹"
MoE 訓練中最頭疼的問題是 專家坍塌(Expert Collapse)——少數專家被頻繁選中,其餘專家幾乎不被使用,導致模型退化為一個小模型。
核心解法:輔助損失函數(Auxiliary Loss)
- 負載均衡損失(Load Balancing Loss):懲罰不均勻的專家分配,鼓勵所有專家被均勻使用
- 重要性損失(Importance Loss):確保每個專家獲得的總權重大致相等
- Z-loss:約束 Router 的 logits 不要過大,防止訓練不穩定(Switch Transformer 提出)
其他訓練技巧:
- Token 丟棄與容量因子:為每個專家設置容量上限,超出的 token 直接跳過該專家(見綜述 Section II-D)
- Dropout 正則化:在層級化 MoE(HMoE)中隨機丟棄不同分支的專家,提升泛化能力
- BPR(Batch Prioritized Routing):優先處理重要樣本,實現稀疏性複用
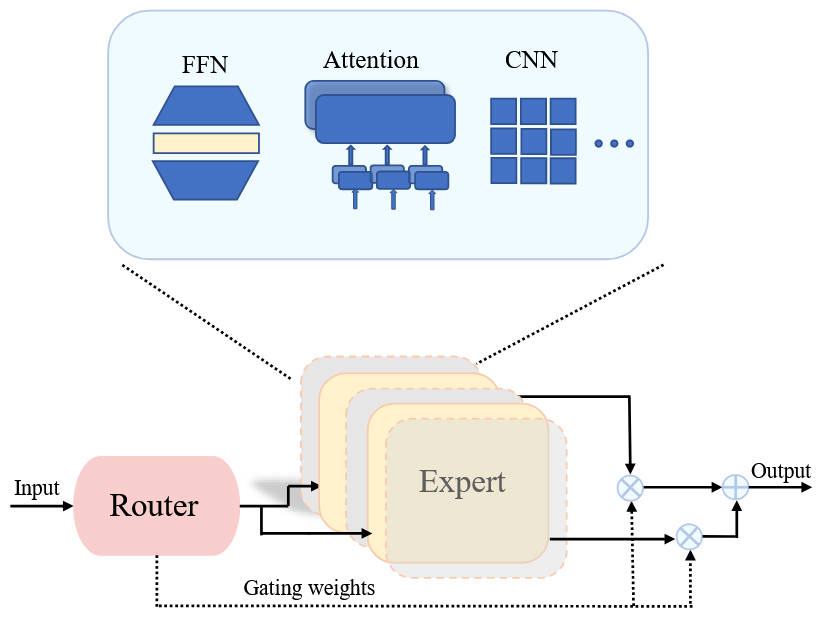
二、系統設計:MoE 的工程挑戰
MoE 不只是算法問題,更是系統工程問題。綜述的 Section II-E 專門討論了三大系統挑戰:
2.1 通信開銷
MoE 的 All-to-All 通信模式是性能瓶頸。每個設備上的 token 需要發送到持有對應專家的設備上,處理完再發回來。
優化方案:
- TUTEL、FasterMoE 等系統通過通信-計算重疊來隱藏延遲
- EdgeMoE、M3ViT 利用硬件特性設計更高效的通信模式
2.2 並行策略
- 專家並行(Expert Parallelism):不同專家分佈在不同設備上
- 數據並行 + 模型並行 + 張量並行:可靈活組合
- 實際部署中通常採用混合並行策略
2.3 內存管理
MoE 模型參數量巨大(專家多),可能超出單設備內存。
- Switch Transformer 提出跨設備參數遷移策略
- DeepSpeed-MoE 採用分層存儲管理(高速緩存 + 遠程存儲)
三、MoE 在各學習範式中的應用
MoE 不僅僅是大語言模型的專屬技術。綜述的第三章系統梳理了 MoE 在五大學習範式中的應用。
3.1 持續學習(Continual Learning)
核心問題:模型學習新任務時,如何不遺忘舊知識?
MoE 天然適合持續學習——可以為新任務添加新專家,同時保留舊專家的知識。
代表性工作:
- Lifelong-MoE:為新數據分佈引入新專家,同時用正則化策略保留舊知識
- PMoE:淺層處理通用知識,深層逐步添加新專家處理新知識
- MoE-Adapters:基於 CLIP 模型,用 Adapter 作為專家,配合任務特定路由器
💡 關鍵洞察:MoE 的模塊化特性使其成為"抗遺忘"的天然選擇——新知識加新專家,舊知識不受影響。
3.2 元學習(Meta-Learning)
核心問題:如何從少量數據快速學習新任務?
元學習假設所有任務來自同一分佈,但現實中任務差異可能很大。MoE 通過多個專家捕捉不同任務分佈,突破了這一限制。
代表性工作:
- MixER:用 Top-1 MoE 增強上下文元學習,每個專家對應一個元模型
- Meta-DMoE:用 MoE 處理多源域適應問題,通過度量學習捕捉源域與目標域的相似性
3.3 多任務學習(Multi-task Learning)
核心問題:多個任務共享模型時,如何避免任務間的負遷移?
MoE 的"專家分工"機制天然適合多任務場景——不同專家可以專注於不同任務。
代表性工作:
- MMoE(Multi-gate MoE):為每個任務設置獨立的門控網絡,共享專家池
- MoME(Mixture-of-Masked-Experts):從過參數化的基礎網絡中提取專家子網絡,而非訓練獨立子網絡
- MOOR:引入 Gram-Schmidt 正交化,強制專家生成互相正交的特徵,避免冗餘
在推薦系統中,多任務學習 + MoE 的組合尤其受歡迎,因為推薦系統天然需要同時優化多個目標(點擊率、轉化率、停留時長等)。
3.4 強化學習(Reinforcement Learning)
核心問題:高維狀態空間和複雜動態環境下,如何提升策略的靈活性?
MoE 通過動態選擇專家來應對不同環境狀態,增強了 RL 智能體的適應能力。
代表性工作:
- 模塊化 RL(Modular RL):將複雜 RL 問題分解為多個模塊,每個模塊處理特定子任務。早期工作 MMRL 就採用了多模塊架構,每個模塊包含動力學模型和控制器
- Soft MoE + Deep RL:研究發現,在深度 RL 中用 Soft MoE 替換倒數第二層,可以顯著提升多種 RL 算法的性能
- MENTOR:用 MoE 架構替換視覺 RL 中的 MLP 層,讓機器人從視覺輸入中學習技能
- SMOSE:基於 Top-1 MoE 的連續控制方法,每個專家學習不同的基礎技能
💡 關鍵洞察:MoE 在 RL 中的優勢在於處理非平穩性——環境不斷變化時,不同專家可以適應不同的環境狀態。
3.5 聯邦學習(Federated Learning)
核心問題:分佈式客户端數據異質性大,如何訓練統一模型?
聯邦學習中,不同客户端的數據分佈可能差異巨大(Non-IID)。MoE 可以為不同數據分佈分配不同專家。
代表性工作:
- 將客户端標識信息納入門控決策,讓路由器感知數據來源
- 先訓練通用模型,每個客户端只微調淺層參數
- 動態確定 Top-K 專家數量,根據客户端資源條件靈活調整
- 設計退出機制,保護敏感數據客户端的隱私
聯邦學習中的另一大挑戰是通信開銷。MoE 的稀疏激活特性有助於減少每輪通信的數據量。
四、理論視角:MoE 的數學基礎
綜述的第四章梳理了 MoE 的理論研究,主要圍繞以下問題:
4.1 收斂性與參數估計
- Softmax 門控的收斂速率:當部分專家參數趨近於零("消失")時,標準 Softmax 門控的參數估計速度會顯著下降
- 改進方案:使用修改後的 Softmax 門控函數(如有界變換函數 M(X)),消除門控參數與專家參數之間的耦合,提升收斂速度
4.2 深度學習中的 MoE 理論
這是一個相對新的方向。代表性工作包括:
- 證明了在特定二分類任務上,非線性 MoE 模型優於單專家模型和線性 MoE 模型
- 路由器可以自動學習數據的聚類結構,將數據動態路由到最合適的專家
- 對 patch 級別路由(pMoE)的理論分析,揭示了 MoE 在視覺任務中的工作機制
💡 理論研究的核心啓示:MoE 的優勢不僅僅是"大",而是路由器能夠自動發現數據結構,實現比單一模型更精細的分工。
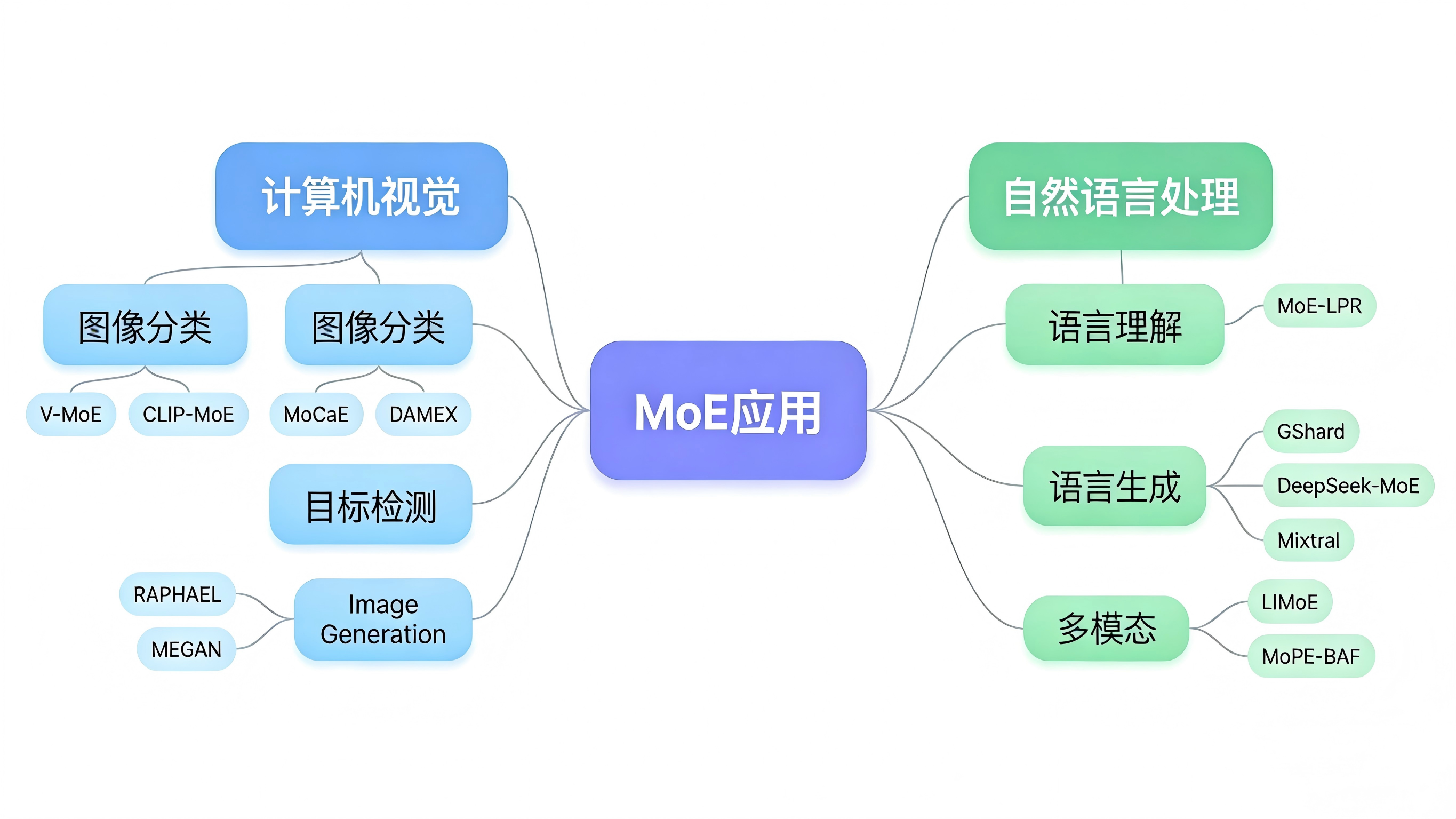
五、應用實戰:CV 與 NLP 中的 MoE
5.1 計算機視覺
MoE 在 CV 領域的應用覆蓋了四大基礎任務:
圖像分類
- V-MoE:將 Vision Transformer 中的 MLP 層替換為稀疏 MoE 層,模型擴展到 150 億參數,在圖像分類上展現了顯著的效率提升
- CLIP-MoE:將 CLIP 模型與 MoE 結合,通過多樣化的專家提升視覺-語言對齊能力
目標檢測
- MoCaE:發現簡單地將不同檢測器組合為 MoE 反而會降低性能(因為不公平競爭),提出了 Early/Late Calibration 來校準不同檢測器的置信度
- DAMEX:數據感知的 MoE 架構,不同專家學習不同數據源的特徵,增強泛化能力
圖像分割
- 將 MoE 應用於語義分割,通過多專家處理不同類別或區域的分割任務
- 在醫學圖像分割中,低秩 MoE(Low-rank MoE)用於持續學習場景
圖像生成
- RAPHAEL:引入空間 MoE 和時間 MoE 兩種專家層。空間 MoE 負責在不同圖像區域描繪不同文本概念,時間 MoE 在擴散過程的不同時間步處理不同程度的噪聲。數十億條擴散路徑,每條路徑就像一位"畫家"
- MEGAN:多生成器 MoE 架構,每個生成器專注於學習數據集中特定模態的分佈
5.2 自然語言處理
自然語言理解(NLU)
- MoE-LPR:解決多語言理解中的"語言遺忘"問題,通過語言先驗路由機制在學習新語言時保持原有語言的性能
- MT-TaG:任務感知門控的稀疏 MoE,在多任務 NLU 中表現優異,尤其在低資源任務遷移上
自然語言生成(NLG)與機器翻譯
- GShard:Google 的里程碑工作,將 MoE 應用於大規模多語言翻譯,在相同硬件條件下顯著提升翻譯質量和訓練效率
- DeepSeek-MoE / DeepSeek-V2:通過細粒度專家分割和共享專家隔離,實現了極致的專家特化
- Mixtral 8×7B:8 個專家、每次激活 2 個,以 12.9B 激活參數達到了接近 70B 密集模型的性能
多模態融合
- LIMoE:首個大規模多模態 MoE 模型,動態調整不同模態的重要性權重
- MoPE-BAF:設計文本提示專家、圖像提示專家和統一提示專家,通過塊感知融合機制實現跨模態交互
六、未來方向:MoE 的下一步在哪裏?
綜述在 Section VI 中指出了六大未來方向:
1. 訓練穩定性與負載均衡
- 當前的輔助損失函數仍然是"打補丁"式的解法,需要更根本的理論指導
- 如何在不犧牲模型性能的前提下實現真正均衡的專家利用率?
2. 訓練與系統效率
- All-to-All 通信仍是瓶頸,需要更高效的通信協議
- 推理階段的專家緩存和調度策略有待優化
3. 架構設計
- 超越 FFN 替換:探索在注意力層、嵌入層等更多位置引入 MoE
- 自適應專家數量:根據輸入複雜度動態調整激活的專家數
4. 理論發展
- 當前理論主要集中在淺層 MoE,深度 MoE 的理論分析仍然匱乏
- 需要更好地理解路由器的學習動態和專家特化機制
5. 定製化算法設計
- 針對特定學習範式(持續學習、聯邦學習等)設計專用的 MoE 變體
- 探索 MoE 與其他技術(如 LoRA、Prompt Tuning)的深度融合
6. 新應用領域
- 科學計算、藥物發現、自動駕駛等領域的 MoE 應用尚待探索
- 多模態大模型中 MoE 的潛力遠未被充分挖掘
Key Takeaways(核心要點)
- MoE 的本質是"條件計算":不是所有參數都參與每次推理,而是根據輸入動態選擇子集。這是擴展模型規模同時控制計算成本的關鍵
- 門控函數是靈魂:Router 的設計直接決定了 MoE 的性能上限。線性 + TopK 是基線,但 Expert Choice、Soft MoE 等新範式正在崛起
- 負載均衡是永恆的挑戰:專家坍塌問題至今沒有完美解法,輔助損失 + 容量因子是當前的"最佳實踐"
- MoE 不只屬於 LLM:從 CV 到 RL,從聯邦學習到持續學習,MoE 的"專家分工"思想具有普適性
- 系統工程同樣關鍵:通信、並行、內存管理——MoE 的落地需要算法和系統的協同優化
- 理論仍在追趕實踐:深度 MoE 的理論基礎薄弱,這既是挑戰也是研究機會
Beginner Roadmap(入門路線圖)
如果你剛接觸 MoE,建議按以下路徑學習:
第一步:理解基礎概念(1-2 天)
- 閲讀本綜述的 Section I 和 Section II,建立對 MoE 架構的整體認知
- 重點理解:門控函數、TopK 路由、負載均衡損失
第二步:動手實現一個簡單 MoE(2-3 天)
- 用 PyTorch 實現一個最簡單的 MoE 層(線性門控 + 2-4 個 FFN 專家)
- 推薦參考 HuggingFace 的
transformers庫中 Mixtral 的實現 - 或者從
fairseq的 MoE 模塊入手
第三步:閲讀經典論文(1 周)
- 必讀:Switch Transformer(Google, 2021)——奠定了現代稀疏 MoE 的基礎
- 必讀:Mixtral 8×7B(Mistral AI, 2024)——當前最成功的開源 MoE 模型之一
- 推薦:DeepSeek-MoE / DeepSeek-V2——細粒度專家設計的代表
- 推薦:GShard——大規模分佈式 MoE 的先驅
第四步:深入特定方向(按興趣選擇)
- 對 CV 感興趣 → 閲讀 V-MoE、RAPHAEL
- 對系統優化感興趣 → 閲讀 TUTEL、DeepSpeed-MoE
- 對理論感興趣 → 閲讀綜述 Section IV 引用的論文
- 對多任務/推薦系統感興趣 → 閲讀 MMoE、PLE
第五步:跟蹤前沿(持續)
- 關注 arXiv 上 MoE 相關的新論文
- 關注 DeepSeek、Mistral、Google 等團隊的最新發布
工程踩坑指南(Common Pitfalls & Engineering Notes)
⚠️ 坑 1:專家坍塌比你想象的更容易發生
即使加了負載均衡損失,如果超參數沒調好(比如輔助損失的權重太小),模型仍然可能退化為只用 1-2 個專家。建議:訓練時監控每個專家的利用率,發現不均衡立即調整。
⚠️ 坑 2:Token 丟棄會影響訓練質量
容量因子(Capacity Factor)設太小會導致大量 token 被丟棄,影響模型學習。設太大又浪費計算資源。經驗值:從 1.25 開始調,根據實際負載情況微調。
⚠️ 坑 3:All-to-All 通信可能吃掉你的加速收益
MoE 理論上減少了計算量,但如果通信沒優化好,實際訓練速度可能反而更慢。建議:先在單機多卡上驗證,再擴展到多機。使用 NCCL 的 All-to-All 原語,並嘗試通信-計算重疊。
⚠️ 坑 4:推理時的內存問題
MoE 模型的總參數量遠大於激活參數量。推理時如果把所有專家都加載到 GPU 顯存中,可能會 OOM。解決方案:專家卸載(offloading)、動態加載、或使用任務級路由只加載相關專家。
⚠️ 坑 5:不要盲目增加專家數量
更多專家 ≠ 更好性能。專家數量增加到一定程度後,收益遞減,而系統複雜度和通信開銷持續增長。找到"甜蜜點"需要實驗。
結語
MoE 不是一個全新的概念——它的思想可以追溯到 1991 年 Jacobs 等人的開創性工作。但在大模型時代,MoE 煥發了全新的生命力。
從 Switch Transformer 到 DeepSeek-V3,從圖像生成到多語言翻譯,MoE 正在成為 AI 基礎設施的核心組件。它的魅力在於一個樸素的道理:讓合適的專家做合適的事。
如果你正在研究或開發大模型,MoE 是一個繞不開的話題。希望這篇文章能幫你建立起對 MoE 的系統認知,也歡迎在評論區交流你的實踐經驗。
更多資源獲取歡迎關注我的公眾號:「木子吉星」
