

本文作者:伍佰(周斯航)
雲音樂曲庫緩存經過多年的實踐和改善,形成了一套自有的緩存使用體系,並取得了很好的效果。本文將以實戰為主,介紹曲庫緩存設計的動機和思路,幫助讀者瞭解背後的原因,並在其他場景中借鑑相似的思路。
背景知識
緩存基礎介紹
緩存是系統設計中,用於提升底層系統訪問能力的一種技術手段,它同樣作用於雲音樂的各個系統中,一種常用的緩存使用調用鏈路如下:
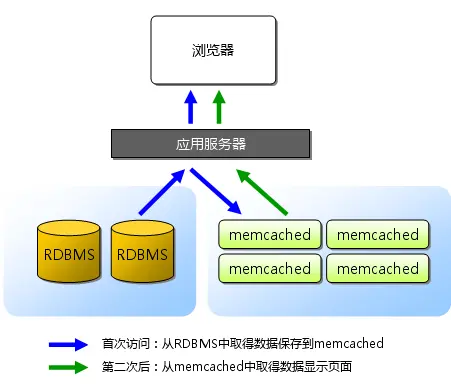
轉化為時序圖,如下圖所示:
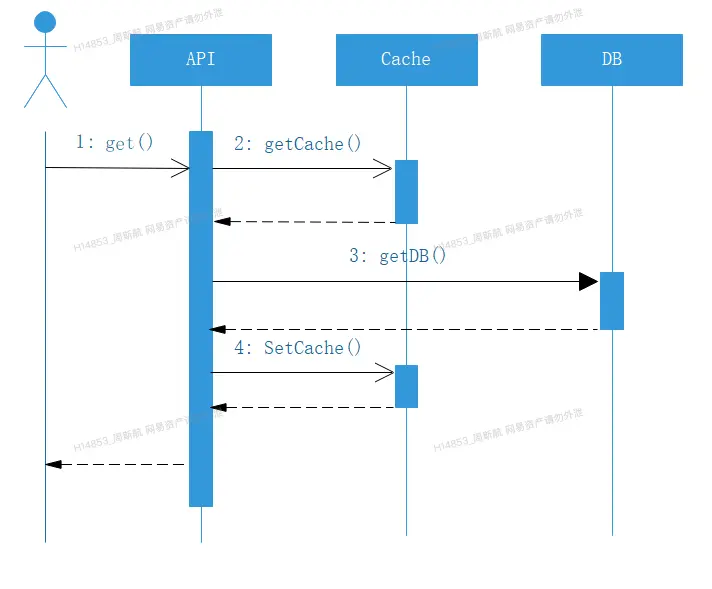
整個緩存的數據放入,是採用懶加載的方式,先取緩存,取到則返回,取不到則透過到下一層,拿到後會回寫當前層的緩存,這是整個雲音樂緩存使用的整體思路。
在正式進入實戰之前,介紹一些概念數據:
- 一次簡單的DB操作,耗時在 0.5~0.6ms
- 一次簡單緩存操作(非本機),耗時在 0.5~0.6ms
- 一次簡單的本機緩存操作,耗時在 0.2~0.3 ms
雲音樂曲庫讀是整個雲音樂服務中接口調用量最高的幾個之一,曲庫讀整體服務的rpc峯值調用qps能夠達到 50w+ (雙機房累加),通過多種緩存使用的嘗試及調優,並最終從以下角度進行考慮並實踐,得到較好的效果。
曲庫數據的特點
很多中間件、組件等設計,在考慮設計時,都會朝通用化方式去實現,而契合業務場景的特點,則更能將性能做到極致,曲庫的緩存實現,是與曲庫數據特性有着深度的聯繫,具體如下:
- 讀多寫少
- 可以讀寫分離
- 數據變化秒級延遲用户不敏感
- 熱點數據集中
- 通過List(列表)獲取數據的場景很多,有大量 MultiGet 操作
有上述特點的業務場景,都可以參考曲庫的緩存使用姿勢。
實戰場景講解
實戰場景1:緩存的高併發保障
日常對曲庫讀服務的高併發保障中,主要會遇到以下兩個問題:
- 歌曲(尤其是熱門歌曲)發佈時,短時間內會出現大量熱點請求,此時由於數據冷啓動,緩存沒有存儲對應數據,會有大量請求直接訪問數據庫,引起數據庫壓力瞬間增大。
- 針對預售但暫未入庫的歌曲,上游有持續不斷的請求,此時由於數據庫和緩存都沒有數據,導致請求都進入數據庫查詢,給數據庫帶來極大的壓力。
以下是曲庫讀緩存服務針對這兩個問題進行優化的策略。
場景1:保障熱點數據的獲取
曲庫將緩存服務分兩級進行部署:在最靠近數據庫層部署了一套分佈式Memcache作為中心緩存,用於緩存歌曲數據;在曲庫讀服務的主機側部署本地Memcache緩存,用於緩存最熱門的歌曲數據。為了防止發佈瞬間出現的緩存擊穿現象,曲庫採用了緩存穿刺的做法,具體做法如下:
對於緩存中的 Key-Value ,將每個Value變成這樣一個對象:
public static class HoleWrapper<T> implements Serializable {
private long expire; // 對象的過期時間
private T target; // 對象本身
}即每個在緩存中的對象,都帶上自身的過期時間,這樣在獲取對象的時候,就知道緩存是否快過期了,如果能得到這個信息,結合業務特點 對於秒級延遲不敏感、熱點數據集中,則可以這麼進行設置,在曲庫,我們稱之為 穿刺 :
- 通過 key 獲取 HoleWrapper
- 查看 HoleWrapper中的 expire 是否 快過期(快過期:可以定義5min、1h)
- 如果是,當前線程將獲取到的 HoleWrapper 的 expire 時間延長,並放入緩存(此操作耗時較少)
- 當前線程向下穿透到下一層取數據,並將最新數據進行更新
時序圖如下:
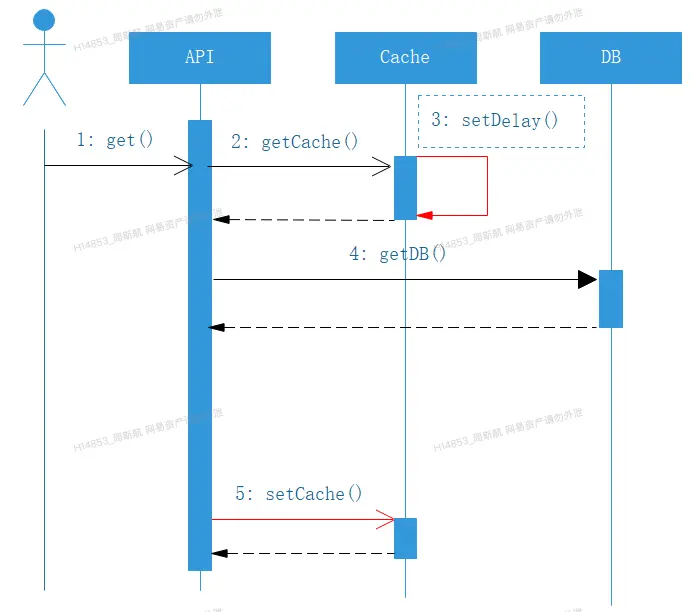
穿刺 體現在步驟3中,此處不能完全杜絕擊穿的風險,但由於緩存操作遠遠快於DB操作,這樣產生擊穿的概率就下降了極多;有了穿刺,對於熱點數據就能很好的做好防護,並且qps越高、越熱點,越能體現優勢。
場景2:數據庫不存在的數據請求的保障
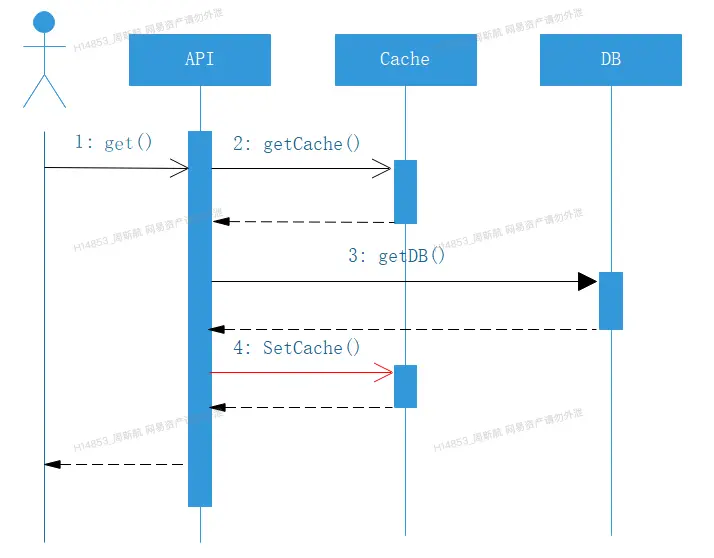
如何保障數據庫不存在的數據請求,是緩存優化中比較經典的“防穿透”問題,又一個簡單而通用的思路:
從緩存取不到的數據,在數據庫中也沒有取到,這時也可以在緩存中寫入一個特殊值進行標記,緩存時間的設置可以視情況確定(如果主動清理可以設置長一點、否則短一點)由於這種做法比較通用,故而在曲庫封裝的緩存代碼中,將其通用化封裝,即對於下面時序圖,第四步進行設置:
實戰場景2:緩存擴縮容
場景1:緩存容量夠,但性能不夠時,如何進行擴容
在熱門歌曲或大型活動期間,此時緩存的容量足夠存儲需要緩存的數據,但緩存本身的性能可能會出現瓶頸(例如緩存上限qps是20w,此時系統壓力達到30w),此時會新增多個緩存集羣,每個集羣緩存同樣的數據內容,以提升緩存的性能,本方法也被稱為 橫向擴容(Scale Out) 。
橫向擴容需要考慮以下兩個問題:
- 如何保障多組緩存數據是一樣的?
- 新擴展的緩存集羣冷啓動,如何防止大量請求打到db的問題?
為了解決這兩個問題,曲庫的最佳實踐是設計了一個緩存代理,所有的緩存操作均通過代理進行執行,代理對於緩存命令的執行形式為:隨機讀、順序寫
-
讀
-
寫

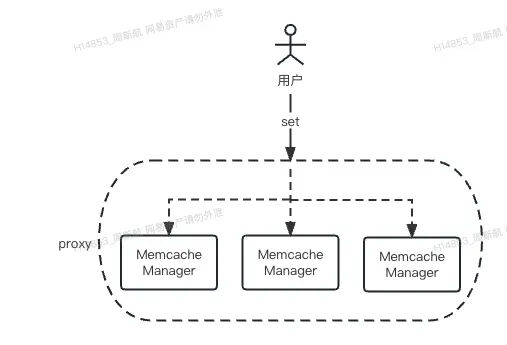
通過這種方式,可以保障在一定的時間範圍內,多個緩存集羣緩存的數據能夠基本一致。
在解決了一致性問題後,還需要保障擴容階段的系統穩定性。此時我們通過配置緩存訪問權重的方式實現緩存預熱,短時間內只有很少的讀請求能夠進入新集羣,由於代理順序寫的邏輯,在一段時間後,新集羣會緩存足夠多的數據,此時再通過修改代理配置,使新緩存能夠提供讀請求。
注:曲庫提供的這套橫向擴容的緩存方案比較適合“讀多寫少”的場景,在頻繁寫的場景下,由於需要頻繁的更新緩存,本套方案的性能可能會降低。
場景2:緩存性能夠,容量不夠時,如何進行擴容
隨着曲庫數據量的逐步變大,緩存的佔用量也越來越高,擴容緩存一個簡單的做法,就是在單個緩存集羣上增加更多資源,以提升緩存的容量。這種辦法被稱為縱向擴容(Scale Up)。
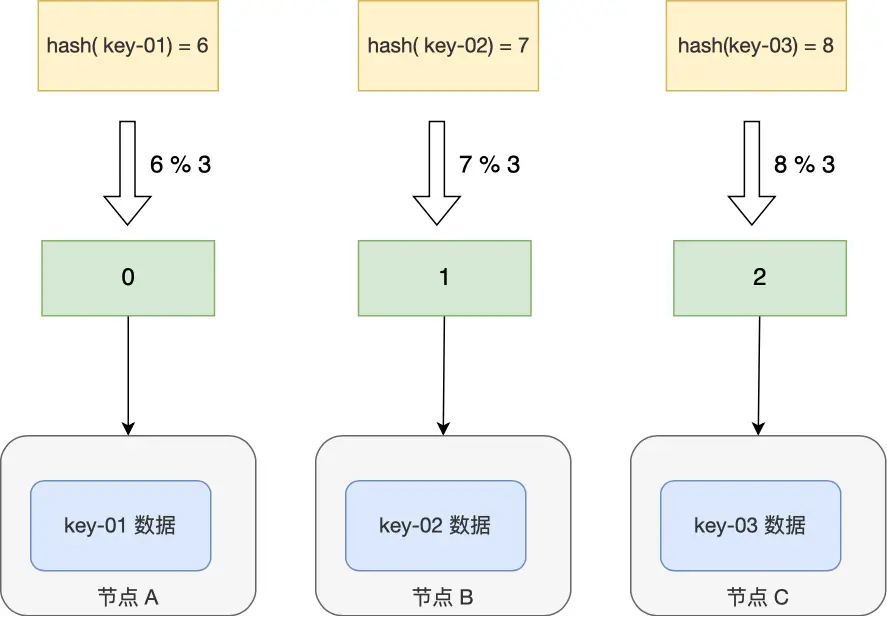
縱向擴容最可能出現的問題是由於節點增多,如果使用普通哈希算法存儲緩存,如果只有一組緩存(大部分場景都夠用),可能會導致擴容後緩存全部失效,此時會導致極高的系統風險。下圖對風險進行了詳細介紹:
-
擴容前:
-
擴容後:
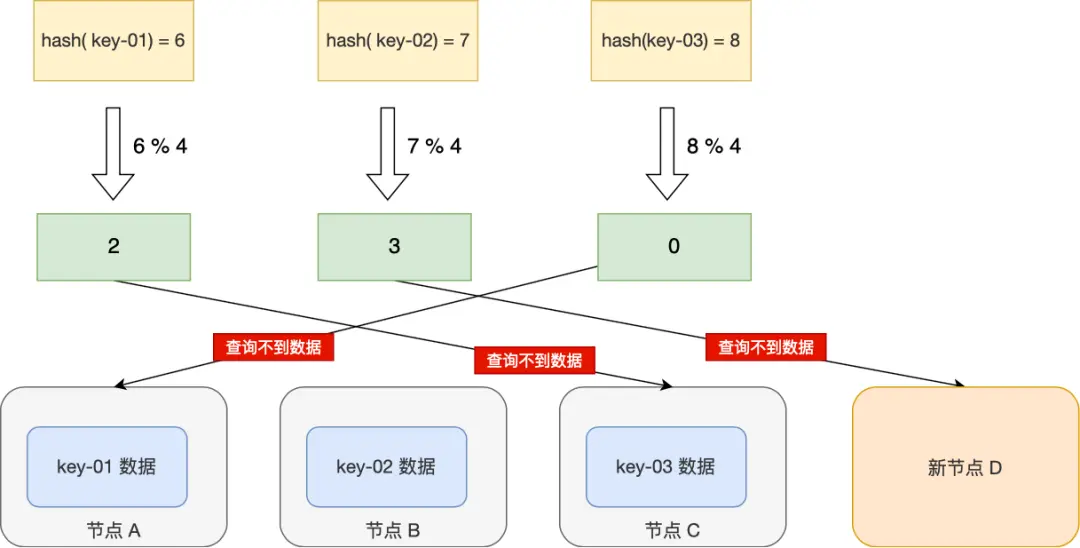
為了解決這個問題,我們採用了一致性哈希算法來進行緩存的存儲,通過這種方法,可以降低緩存集羣內節點擴縮容帶來的系統風險。本文不過度贅述一致性哈希算法的原理,感興趣的讀者可以參考5分鐘理解一致性哈希算法。
實戰場景3:緩存清理
曲庫數據的特點是讀多寫少,且可以接受數據變更後秒級的延遲。基於這種特點,我們設計了異步緩存清理的方案。其中在設計緩存key-value時需要遵循這樣的原則:
- 所有的緩存清理,由於曲庫數據支持秒級延遲的特點,可以進行異步清理
- 所有的緩存清理,由數據庫變更(binlog消息)消息觸發
- 所有關聯的Key,可以由單條binlog生成
只要遵循這樣的設計,曲庫緩存的清理就可以變得比較輕巧,可以採用監聽數據庫binlog的形式進行異步清理。
場景1:緩存數據出現變化時,如何保障一致性
場景1是比較基礎的緩存清理場景,在此不做過多描述,需要注意的是如果是多級緩存,需要從緩存的部署形式分析,按離數據庫從近到遠的形式進行清理。(例如監聽數據庫binlog後,先清理中心緩存,再清理本地緩存。)
曲庫的最佳實踐是隻有清理中心緩存的服務直接監聽binlog消息,在清理完中心緩存後再將消息轉發到另一個消息隊列,清理本地緩存的服務監聽新的消息隊列,這樣就能實現有序清理緩存的目的。在清理本地緩存時,我們提供了一個清理sdk插件,嵌入曲庫讀服務,每個服務在啓動時會實例化一個獨立的消費者,這樣雖然對業務有部分侵入,但由於每個消費者只需要清理本地緩存,曲庫讀服務的擴縮容會變得異常簡便,也更適用於當前容器化部署的形式。具體流程圖如下:
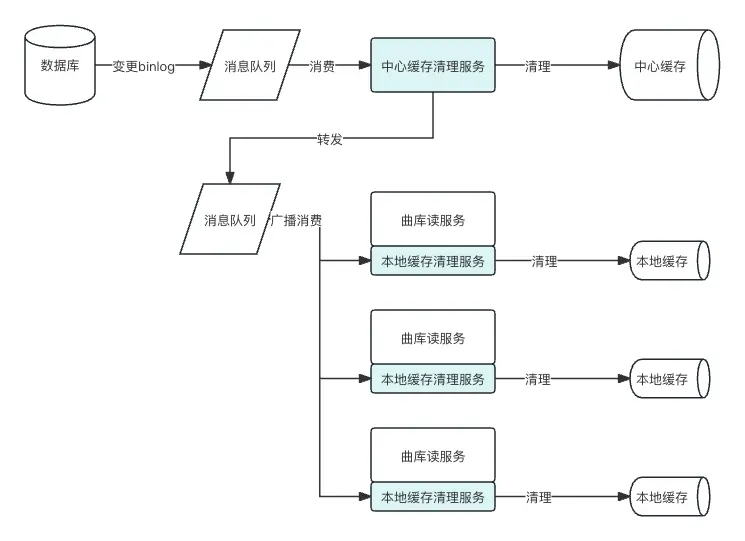
場景2:緩存數據結構出現變化時,如何保障一致性
如果某個緩存對象的數據結構發生了變化(例如新加了一個字段),此時需要把該類型對應已緩存的對象全部清理。
在這裏,我們採用了一個簡單做法:不去主動清理已存在的緩存,而是想辦法把這部分緩存“失效”掉(線上服務訪問不到)。主要的做法是利用了構建緩存key的生成器,在生成緩存key的時候添加一個“緩存版本”。後續如果遇到需要清理所有緩存的時候,只需要把緩存版本進行升級,就可以達到訪問不到老緩存,重新從數據庫獲取數據的效果。
注:通過升級版本號的方案其實是無法精確清理所有緩存對象的情況下的trade off,升級版本號後,在發佈服務時需要注意緩慢灰度發佈,否則可能會造成大規模的緩存雪崩現象。
總結
以上,是曲庫緩存使用的實踐歷程,涉及的細節較多,不同業務場景可以參考不同的考慮方式進行部分借鑑。
後續曲庫緩存的發展方向,是將元數據中額MetaData數據與狀態數據分開,並將MetaData數據進行純靜態化處理,結合業務數據變化的特點,將狀態部分數據的降級等引入考慮,進行更深度的緩存使用。
最後

更多崗位,可進入網易招聘官網查看 https://hr.163.com/