

本文作者:huangleilei02
業務背景
投放廣告買量,不管是拉新還是促活場景,都是互聯網用户增長的重要手段。RTA(Real Time API),是廣告投放領域非常重要的一種投放方式,用於滿足廣告主實時個性化的投放需求。顧名思義,RTA指的是API接口實時調用,將直投的廣告主的流量選擇權交給廣告主,媒體傳入設備號調用RTA問詢接口,進行用户投放的篩選,讓廣告主在廣告曝光前進行投放策略的判斷,滿足拉新、促活等個性化需求,同時也能做到媒體和廣告主數據隔離。
雲音樂在對外買量時,作為廣告主,也建設了一套從RTA人羣圈選、到媒體響應、再到站內承接的完整系統。雲音樂在過去一段時間裏,不斷從業務及技術等多個角度,對該系統進行建設和完善。
而在2023H2,RTA業務以RTA專項的方式進行實踐,專項目標包含RTA接入多個媒體、投放量級增長、縮短人羣圈選流程等。本文將以RTA專項建設過程中的解決方案為主,結合H2前的一些建設,來介紹雲音樂RTA投放與承接系統建設中的一些思路。
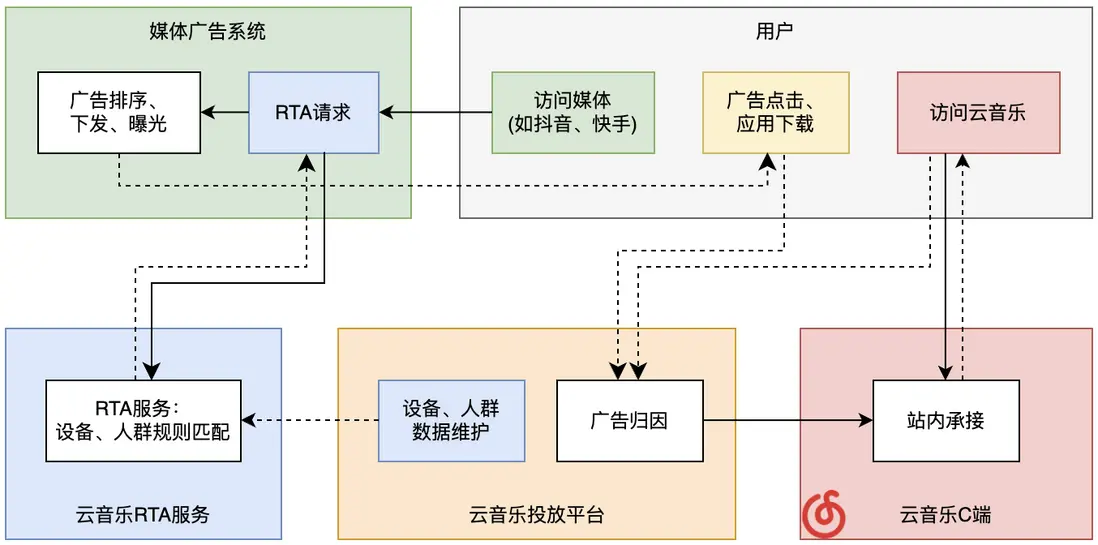
RTA投放側架構
RTA投放方式的顯著特點是請求量大、實時性要求高。雲音樂對接多個廣告媒體,單媒體的請求QPS在數萬-數十萬不等,單次請求從媒體測請求發起到收到響應的超時時間一般僅約五六十毫秒,對於服務來説有着不小的挑戰。
因此,雲音樂RTA投放側(即不包含站內承接的業務領域)的技術架構有以下特點:
- 獨立Nginx集羣及專線,和主站隔離
- 分層解耦。請求適配層+投放策略層+設備映射層+設備寫入層
- 異步模式,高性能、高吞吐量、低延遲。使用Netty處理請求、使用Lettuce作為redis客户端
- 針對海量請求,通過時間輪實現超時處理,大幅提升性能
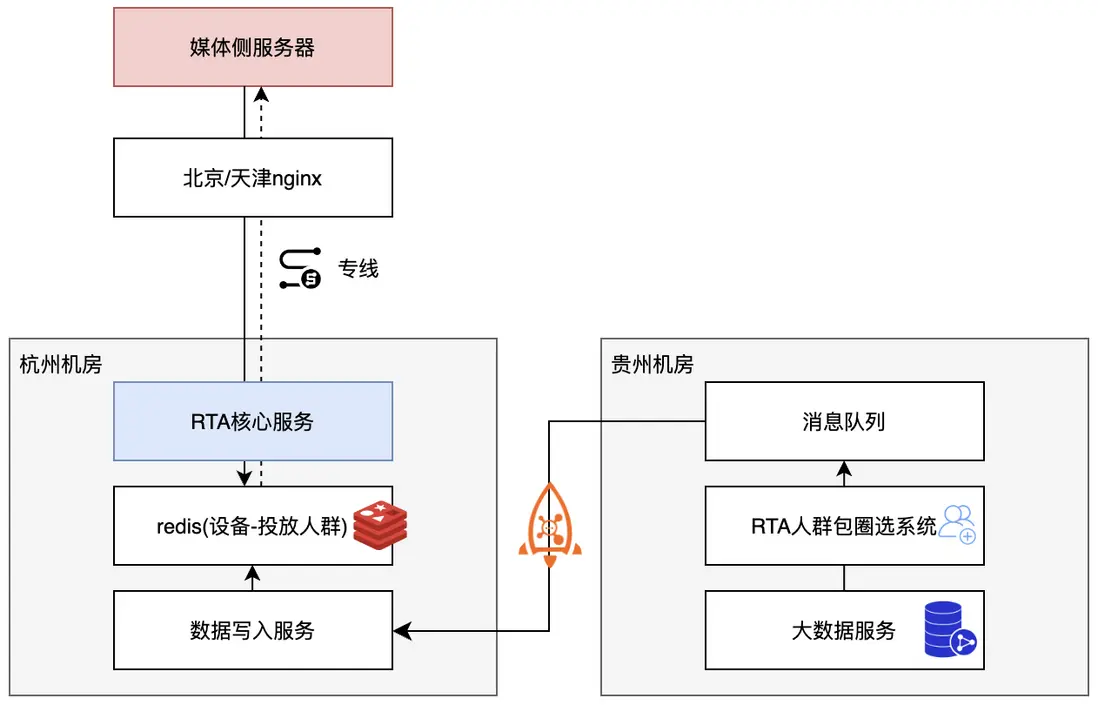
RTA自動化圈選人羣
RTA投放的核心部分,就是圈選出一定規則的以設備號為主體的人羣,針對不同媒體的不同投放賬户,投放不同的人羣。
由於用户增長領域廣告投放複雜度高,以及當前互聯網存量時代對精細化運營有更高訴求,業務對RTA投放人羣包圈選的自動化和靈活性有一定訴求。雲音樂RTA投放系統建設了自動化圈選後台,結合雲音樂人羣圈選平台“魔鏡”,做到設備維度的RTA投放人羣包的靈活圈選和快速設備同步。
其整體鏈路如下:
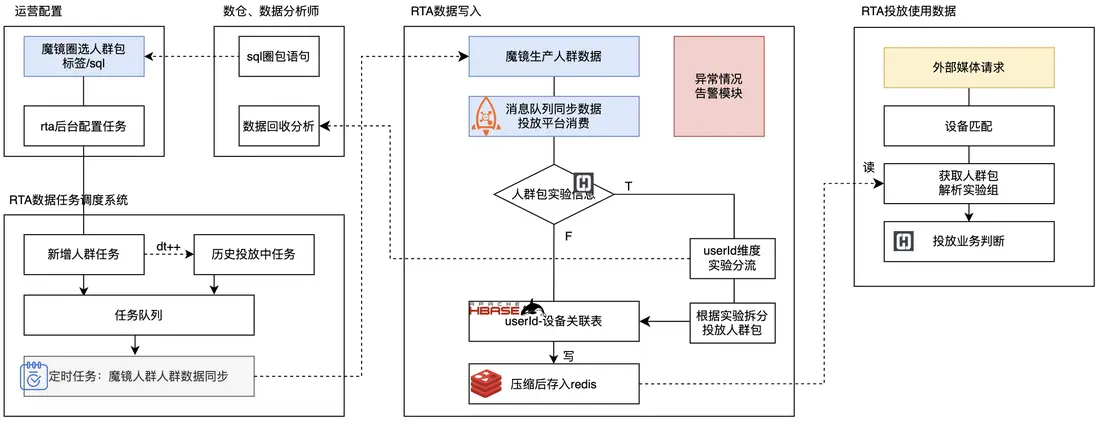
在圈包自動化能力的基礎上,RTA投放平台做了一些擴展性工作,從而做到系統穩定性提升、數據問題快速響應、圈包流程縮短提效,上線後對業務的圈包投放動作提效60%以上,也為後續的自動化、精細化運營打下基礎。
圈包後台可以通過以下幾點概括:
- 打通魔鏡人羣圈選平台、雲音樂設備數據,使得能夠通過簡單的標籤圈選或者自定義圈選條件SQL,完成投放設備的定向圈選,成本低、響應快速;
- 打通AB實驗能力,能夠靈活圈包並驗證投放策略;
- 整個數據準備流程由運營操作,平台自動化進行校驗;
- 能夠應對單日數億至十億級別總數人羣包數據寫入;
- 數據同步結果通知,調度過程記錄;
- 數據鏈路多類異常告警通知,做到快速定位問題並響應解決。
RTA存儲痛點優化
業內對於RTA設備數據的存儲方式大同小異,因為設備數據和人羣信息的關係以kv為主,所以redis是比較多的一種選擇,雲音樂也使用獨立集羣的redis cluster作為RTA數據存儲的數據庫。在業務初期,採用的是redis的String結構進行存儲,例如將設備Oaid的MD5值作為key,對於人羣包列表及其他相關信息的Json作為value,但該方式在存儲成本上有着很大問題。
目前投放數據,會針對Oaid、Imei、Idfa為主的幾種設備信息的MD5值進行存儲,此外,在與字節抖音合作時,應對數據安全規範,還需要進行Prl加密存儲,因此,一個手機會產生多條設備記錄。rta投放人羣設備數據非常龐大,用户數量數億甚至十數億左右量級,結合上述多種設備及多種加密方式,整體數十億量級記錄。在初期,投放平台使用redis的String類型存儲數據,隨着新加密方式的接入和設備數的增多,對存儲造成了壓力,如不做改造,將佔用數百GB甚至1000GB的存儲空間。
投放平台通過以下幾個方式的組合,完成了超過80%的存儲空間優化:key改造、value改造(分為人羣包名改造、過期時間改造、序列化壓縮)、存儲結構改造。我們先從更直觀的key、value本身對壓縮開始介紹。
key改造:此處的key指的是redis存儲的key,其內容為設備號相關信息,由設備號類型、加密信息以及設備號加密結果(如MD5或者其他方式加密結果)組裝而成的String,在39-86字節不等。使用MurmurHash2的64位hash算法對原本對長字符串進行哈希,此時衝突率非常低,對業務幾乎無影響。並將其作為字節數組轉為String,轉為String時採用的編碼字符集為ISO_8859_1,相比默認的UTF-8存儲更少。當然,如果讀寫均選擇合適的redis客户端,也可以直接用字節數組。
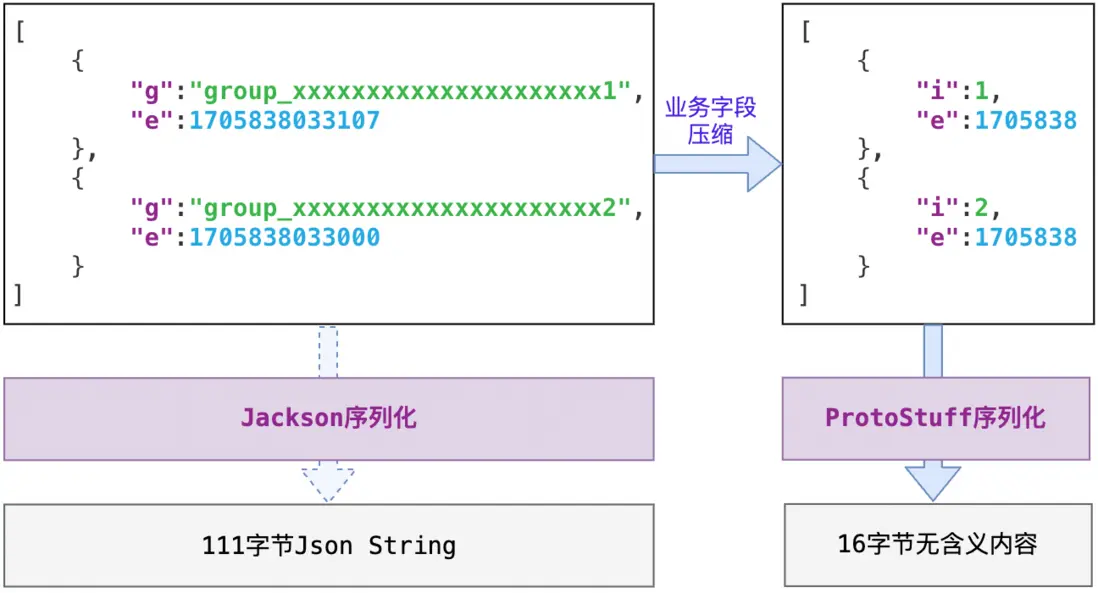
value改造:原本的value信息相對冗餘,經過以下三組改造的結合,可以將50-100+字節的Json壓縮為8-16字節。
- 人羣包名改造:原本的value為人羣包信息列表,包含了冗長的人羣包名、毫秒級別的業務過期時間以及其他相關信息。改造時將人羣包名字序號化,將string轉為int。
- 業務過期時間改造:將毫秒級過期時間減去6未有效數字,粗化到十幾分鍾級別,在對業務影響很小的前提下有效減少了存儲空間。
- 序列化壓縮:將原本JSON序列化結果轉為Protostuff(Google ProtoBuf的改進版)序列化,雖然犧牲了可讀性,但大幅壓縮了存儲空間。關於Protostuff序列化方式的壓縮原理,各位可以自行檢索研究,本文中就不再贅述了。
數據結構改造:除了業務數據的壓縮,本身在redis中的存儲結構也大有可為。為了更好介紹該項改造,我們不妨來看一個case,當我們使用redis的String類型存儲單條數據{"wyyyykey":"wyyyyval"},該數據的key大小為8字節,value大小為8字節,那麼這條鍵值對佔用了多少內存呢?
set wyyyykey wyyyyval
memory usage wyyyykey
--7272字節比鍵值對本身的16字節大了不少,那麼多出來的這部分內存用在哪裏了呢?這就得提到redis中字符串的實現方式了。redis首先會為每個鍵和每個值創建一個redisObject(以下簡稱robj),帶有一些對象頭信息;而我們都知道,redis的字符串對象的類型為簡單動態字符串(Simple Dynamic String,SDS),其中有部分空間用於記錄實際內容存儲情況和存儲時的預留空間;在維護全局哈希表的dictEntry時,需要維護指向key、value、和下一個節點的指針,這些都會造成額外的存儲。
下圖為一個字符串類型的鍵值對存儲結構,關於該key和value的SDS實現結構為sdshdr5還是sdshdr8對於整體存儲邏輯和量級影響很小,因此此處不做過多討論,讀者可自行閲讀源碼,此處參考引文2。需要注意的是,Redis的內存管理和優化策略是複雜的,並且在不同的版本和配置下可能會有所不同。因此,在具體情況下,實際的內存佔用可能會有所變化。
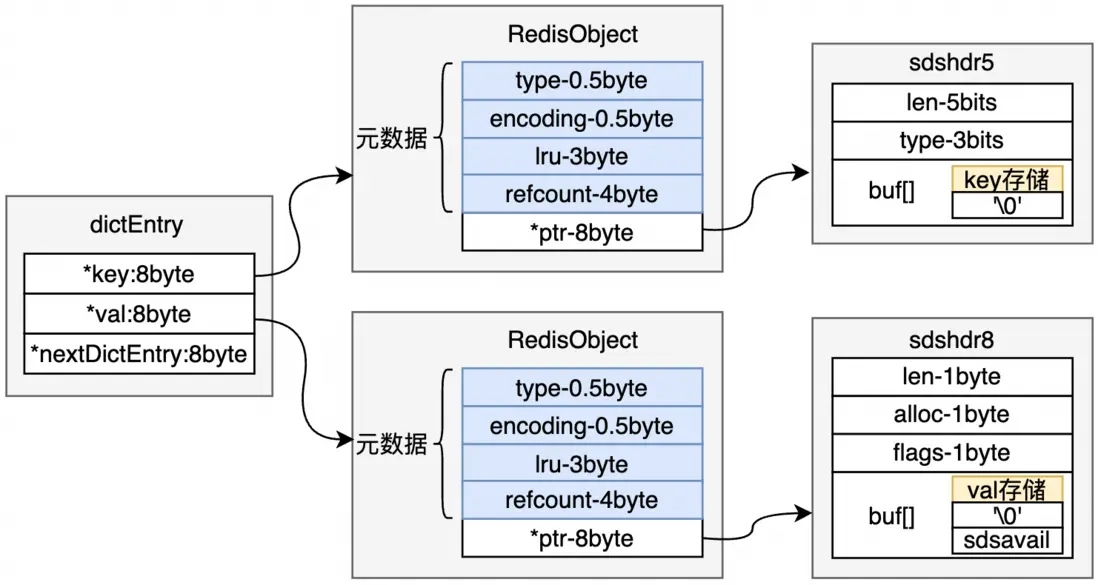
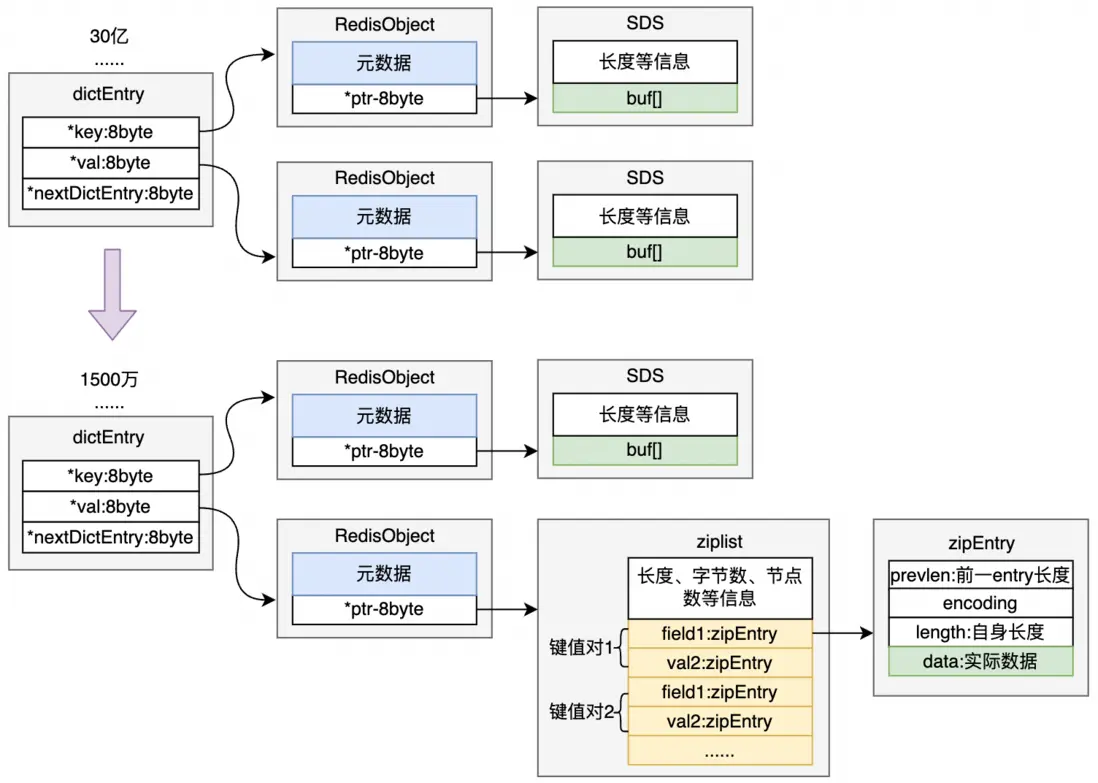
而想要優化掉大量的robj元數據、dictEntry、sds信息,redis的Hash結構是一個很好的方案。在默認設置下,當哈希對象可以同時滿足以下兩個條件時,哈希對象使用壓縮列表(ziplist)編碼:哈希對象保存的所有鍵值對的鍵和值的字符串長度都小於64;哈希對象保存的鍵值對數量小於512。ziplist非常節省內存,是由一系列特殊編碼的連續內存塊組成的順序性數據結構,一個ziplist可以包含多個節點,每個鍵值均為一個節點,每個節點緊挨着,能夠大幅減少內存。
不妨假設原本有30億個key需要存儲,將這30億個key通過hash打散成1500萬個redis的hash對象,可以大幅減少robj元數據、dictEntry、sds信息等佔用的內存。而雖然查詢的時間複雜度由O(1)變為了O(n),但由於此處n為ziplist的entry數量大約為200,對整體的時間影響非常小。
實時站內承接
為了提高使買量用户的留存(是讓錢花的更值),雲音樂建設了投放用户實時站內內容承接,能夠覆蓋新客和召回用户等多種用户類型。當然,廣告投放方式往往要多組合才能得到更好的效果,本節介紹的雲音樂站內承接建設,並不只覆蓋RTA鏈路投放到廣告用户,也能夠對其他方式的投放用户進行承接。
本節主要以雲音樂首頁模塊及內容的投放用户承接作為例子進行介紹,除此之外,站內落地頁直達、資源自動訂閲、搜索底紋詞等都是可以承接的手段,而用户的投放歸因信息也可以輔助算法進行決策。
用户來源實時歸因
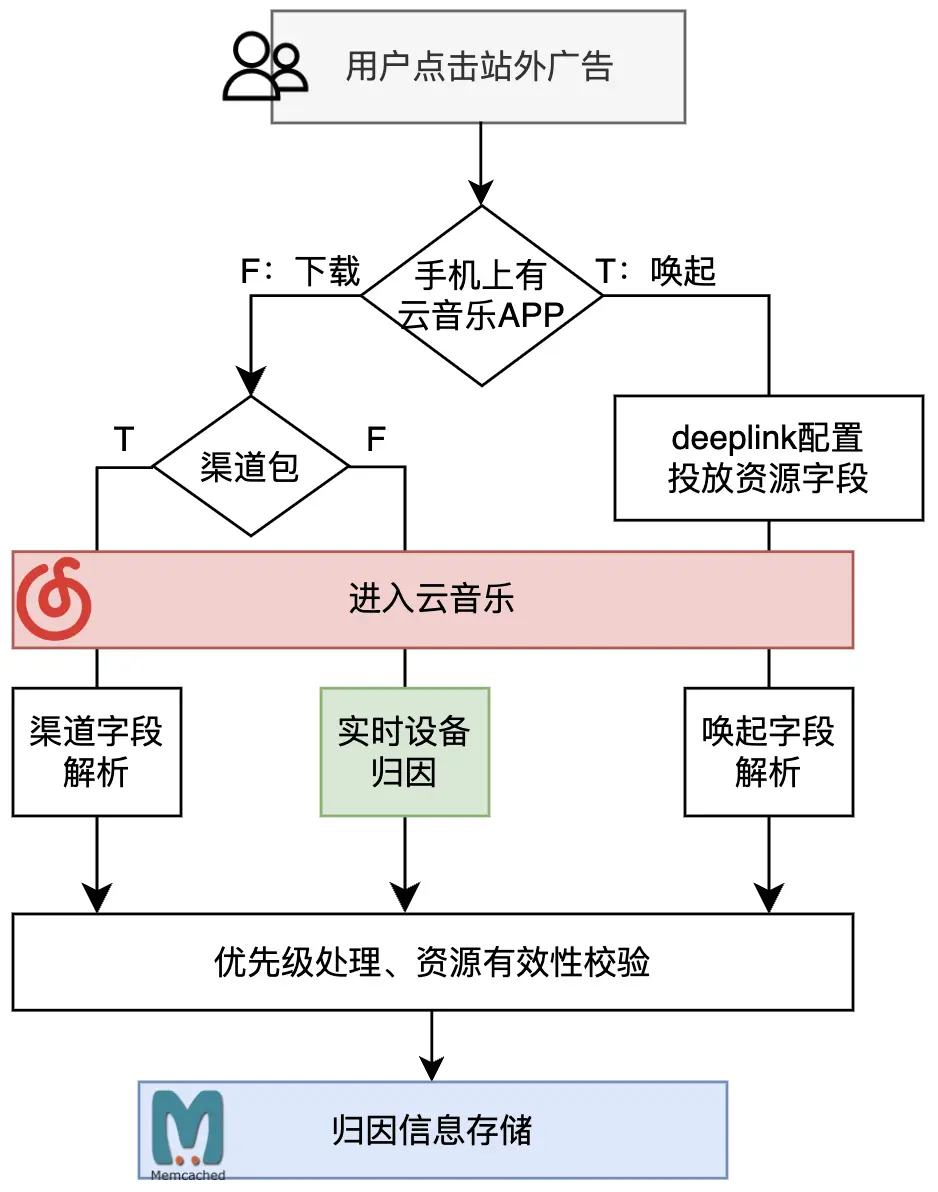
假如雲音樂在各媒體同時投了某首單曲和某個歌單,需要知曉用户成為新客或者回流APP來源於哪個廣告資源,才能進行承接,這個步驟就是歸因。廣告的投放方式是多種多樣的,例如A用户是點擊廣告後初次下載雲音樂APP進站;B用户是雲音樂老用户但已經卸載,也是點擊廣告後下載APP;而C用户則是老用户但手機上已經安裝雲音樂APP,直接通過廣告所帶的deeplink鏈接喚端;此外,還有渠道包等其他投放的方式。針對上述多種情況,需要聚合建立用户來源實時歸因能力。
針對直接通過廣告所帶的deeplink鏈接喚端的用户,通過在deeplink上拼接業務字段,客户端在打開APP時進行解析並傳給服務端,即可完成用户本次的歸因,該方式非常直接且準確。針對下載APP的用户,則相對曲折一些。在用户初次激活APP時,將雲音樂deviceId和歷史數據進行比較,來判斷該設備是新設備或者是迴流設備,將新設備、迴流設備數據和廣告點擊數據根據一定策略進行業務歸因,從而定位到該次激活是否投放用户以及具體是哪個投放資源帶來的用户。
首頁模塊承接
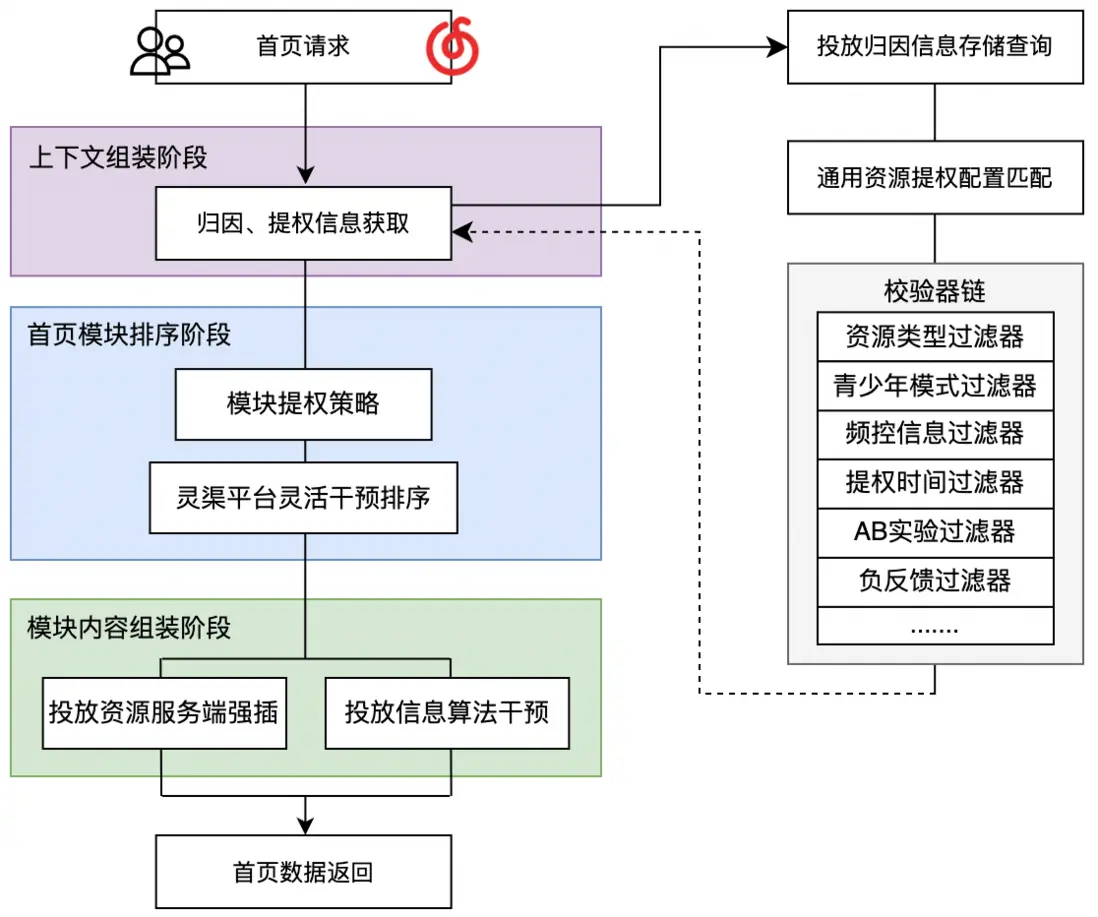
在首頁場景下,上下文組裝階段進行投放歸因信息和部分提權策略信息的組裝,該信息將用於後續模塊排序和各模塊資源的組裝過程中。在模塊排序階段,利用靈渠投放平台(感興趣的讀者可閲讀參考第3篇)進行靈活可配的模塊排序干預;在模塊內容組裝階段,通過服務端強插干預或者算法策略干預的方式,將對應的投放資源按照一定業務策略進行提權。模塊+資源的組裝方式有效提高了投放用户的站內留存。
針對多模塊多種資源的首頁模塊及資源承接策略,設計了一套通過json字段匹配方式靈活更改承接內容的解析規則,能夠實現從廣告媒體到廣告計劃到廣告投放資源等多級可變的規則匹配。同時,針對業務透出規則及投放資源特性,採用過濾器鏈模式實現提權與否的校驗。該承接能力涵蓋多種用户類型(新用户、流失用户等)、涵蓋多種首頁類型(老首頁、首頁新框架等)、多種客户端(android投放、IOS投放)。
總結與展望
本文從整體架構、投放數據、站內承接等多個角度介紹了雲音樂RTA投放與承接系統建設中的一些要點;從業務、技術兩個角度結合,為廣告投放業務提供了一些思路。
同時,從業務專項角度,較好地完成了專項目標,提高RTA渠道接入數量和業務量級,通過自動化圈選人羣能力的建設縮短投放圈包配置週期60%,通過站內承接系統有效提高了投放用户的留存。
展望未來,處於成本和價值的考量,RTA投放及承接的精細化將是非常重要的一個方向。在有完善用户價值體系的基礎上,RTA人羣圈選及投放需要和個性化出價策略結合得更加緊密,而不同用户在站內的不同承接策略也需要更加精細和深入,形成相對完整的生態。
參考鏈接
- https://github.com/protostuff/protostuff
- https://cloud.tencent.com/developer/article/1837860
- https://juejin.cn/post/7290741484364562432
最後

更多崗位,可進入網易招聘官網查看 https://hr.163.com/