

本文作者:張琪
Metrics是服務監控的重要部分,網易雲音樂中間件團隊基於VictoriaMetrics構建了服務端Metrics監控體系,旨在提供易用、高效的監控解決方案,本文介紹了建設中遇到的問題、方案與成果。
一、背景介紹
Trace、Metrics、Log是APM系統(Application Performance Management,應用性能管理)的三大支柱。過去雲音樂使用的Metric監控體系與APM分屬不同系統,使用時相互之間沒有聯動,導致Metric與Trace完全割裂,問題定位中將二者關聯起來時需要一定成本;另外不同系統的數據視角不同,使用風格也有較大區別,導致總體問題分析能力較弱。
為此,雲音樂中間件團隊規劃建設了新版應用服務端監控體系(Pylon APM),重新實現了Metric體系,選型了作為雲原生監控標準的Prometheus作為Metric監控基礎。而云音樂龐大的服務規模,多樣的監控需求也對Metric時序存儲的可靠性、可用性及性能帶來了很大挑戰。我們最終形成了圍繞VictoriaMetrics(以下簡稱VM)體系的Metric架構,旨在解決以下問題:
- 應用層Metric可觀測性弱:過去音樂內部Metric監控以機器層面的Metric監控為主,雖也提供了常用框架的監控插件,但無論是性能還是可視化效果都有一定改進空間,問題排查效率低;
- Metric關聯到Trace的問題:Metric是發現問題最直觀的方式,比如“接口錯誤數10”,但還需要Trace協同工作才能定位到發生錯誤的根因;
- 性能與成本問題:舊版Metric監控數據存儲成本較高;而社區版Prometheus單體應用,無法支撐音樂如此大的數量級。需要一套高可用而低成本的數據採集、數據存儲方案;
- 數據維度大,聚合查詢吃力:監控數據時常應對聚合查詢,應用層數據的採集維度很大,若直接查詢原始數據往往需要數秒甚至數十秒,嚴重影響問題排查;
- 可視化能力弱,缺乏靈活的數據對比:監控數據時常需要同環比、多實例比較等手段來幫助定位問題,Prometheus UI和可視化工具Grafana都沒有支持這項功能。
為解決以上問題,我們對圍繞VM時序採集、聚合、Grafana可視化做了深度擴展,最終達成以下目標:
- Metric關聯到Trace的問題排查:解決信息孤島,從Metric入手可下鑽到Trace、Log排查問題;
- 高效的Metric監控可視化與圖表分析能力:我們設計了豐富、直觀、多維度的Dashboard,使用户能夠在第一時間觀測到Metric存在的問題,還改造Grafana提供了圖表分析能力,大大提升問題分析效果;
- 高性能、低成本的採集存儲方案:我們採用VM作為Prometheus的替代存儲方案,以較低的成本支撐了音樂Metric監控;
- 毫秒級的聚合數據查詢:為了解決數據聚合、查詢效率低的問題,我們實現了時序數據預聚合Recording Rules服務和查詢代理Proxy服務。受益於此,常用的大維度數據聚合查詢得以在毫秒級完成。
二、項目思路和方案
2.1 選型與架構
Prometheus定義了雲原生監控體系,但由於社區版性能較差且對數據持久化、高可用的支持較弱,衍生了很多數據遠程存儲方案,用以支持高可用、超大量級的數據。目前主流方案有VictoriaMetrics、M3DB、InfluxDB等。
其中VM以其極高的性能、對Prometheus生態的完整替代、其重新實現的PromQL進化版-MetricQL等優秀的特性,得到了業界的高度認可和廣泛使用,故我們選型了基於VM來實現我們的Metric監控方案,關於VM與其他TSDB的性能對比可以參考VM作者的文章。
基於VictoriaMetrics的Metric方案整體架構如下:
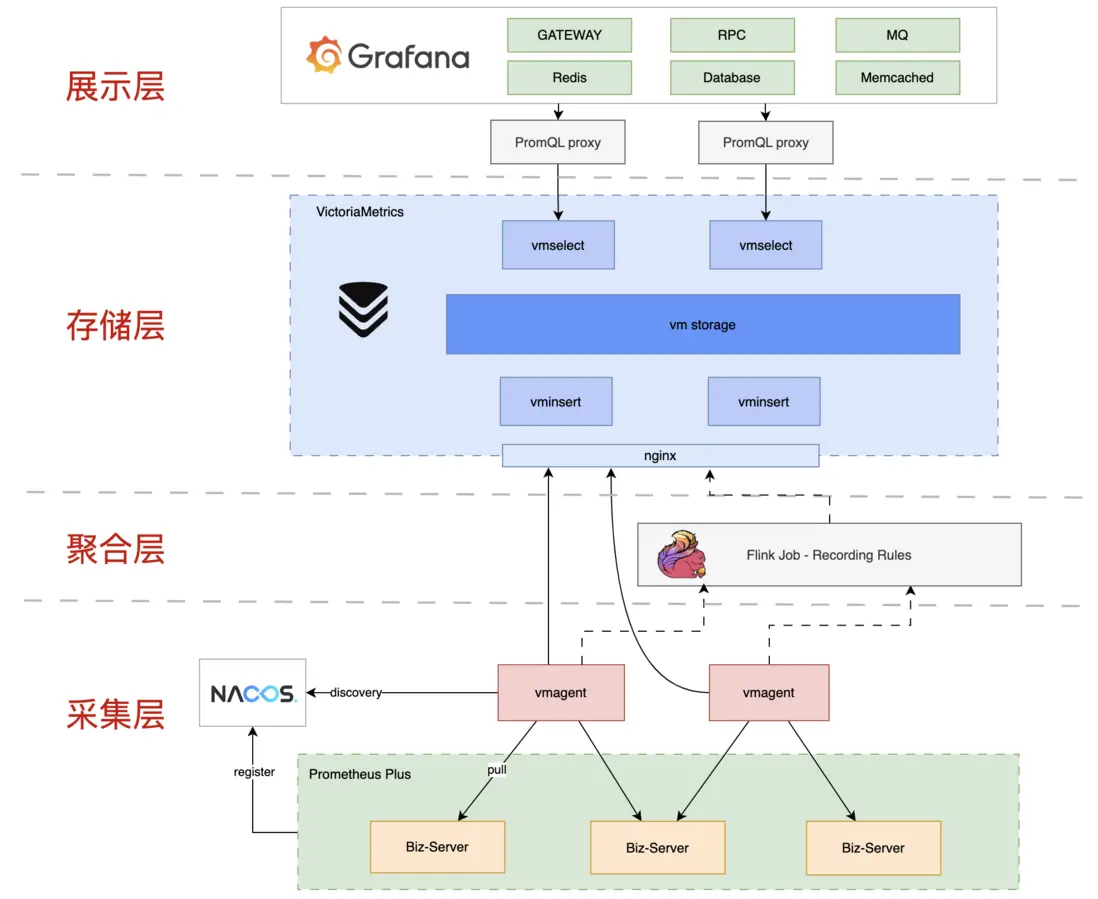
架構可分為採集鏈路、查詢鏈路:
-
採集鏈路負責將Metric數據分片收集、預聚合後存儲到vmstorage(VM的存儲引擎)中,由以下組件組成:
- Exporter:內嵌在業務服務中的Prometheus SDK,暴露數據採集端口;
- vmagent:負責數據採集;
- Nacos:註冊中心,負責vmagent和Exporter之間的服務發現。監控數據採集的服務發現節點量級較大,對一致性的要求沒有可用性和性能的要求高,故我們選型Nacos,並對其做了兼容Prometheus服務發現的補充;
- Recording Rules:自研的Flink任務,負責Metric數據的流式預聚合;
- vminsert:VM集羣模式的組件之一,負責數據寫入;
-
查詢鏈路負責優化數據查詢語句,查詢存儲引擎,由以下組件組成:
- Grafana:數據可視化,我們將其二次開發支持了數據同環比、多實例比較;
- proxy:自研的查詢代理,負責解析並優化PromQL;
- vmselect:VM集羣模式的組件之一,負責數據查詢。
2.2 監控數據採集、預聚合和查詢方案
問題背景
一條完整的Metric數據結構如下:

在此結構下應用層Metric監控數據label-value鍵值對取值情況多,其組合數量是乘積的關係。遇到大維度聚合查詢,對存儲層的查詢壓力很大,延遲較高,嚴重影響問題排查的效率。
比如我們監控一個API網關服務,集羣中有200台實例,註冊有10000個API,平均每個API有10種返回code,則按集羣查詢總的code分佈情況時,存儲層需要聚合的時序量有:
200 10000 10 = 20000000 條。

我們嘗試了社區開源的後置聚合方案Recording Rules,發現後置聚合對存儲層的壓力並未緩解,整體性能並不高,並不能達到優化整體查詢性能的目的。
解決方案
由於時序數據不斷增長的特點,數據預處理提高查詢時效率較好的解決方案。經過測試,開源方案後置聚合(數據存入存儲引擎後,再查詢出來聚合)的方式不能滿足我們的性能要求,故我們基於Flink設計實現了預聚合的Recording Rules服務,另外為了讓用户更方便地使用聚合數據,我們設計了查詢代理Proxy。
- 預聚合的Recording Rules
預聚合服務負責將用户經常需要使用的大維度聚合查詢提前的聚合,提高查詢效率。
Prometheus體系下的Metric數據是時間連續的,每隔一個interval都會有一組數據上報,非常符合流式數據窗口聚合處理的特點,故我們選型大數據領域廣泛使用的Flink來實現數據預聚合Recording Rules。
整體架構為:vmagent將採集上來的原始數據雙寫,一份直接寫出到存儲層,另一份寫出Kafka中,由Recording Rules消費,經過滾動窗口聚合後,寫出到vmstorage中。方案如下圖:
經預聚合,大維度查詢RT從數秒降低到毫秒級。
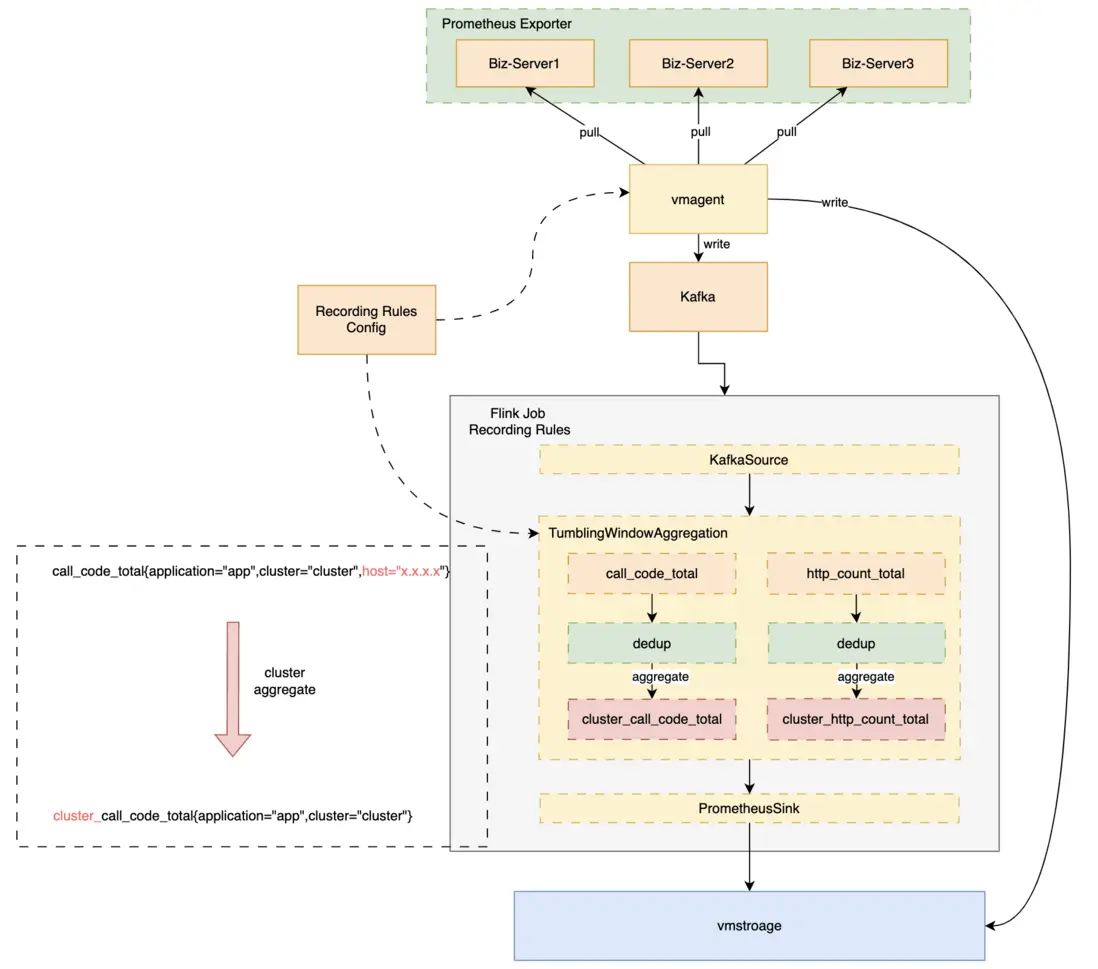
- 查詢代理Proxy
經過數據預聚合的數據需要與原始數據隔離,metric名稱、label都會發生變化。
比如我們有聚合前原始數據gateway_call_code_total{application="app1",cluster="cluster1",host="host1",env="online"},按集羣聚合。
按集羣聚合後host這個label即丟掉,且為了隔離,表名添加前綴後變化為cluster_gateway_call_code_total{application="app1",cluster="cluster1",env="online"}。
用户若要在查詢時使用聚合數據需感知聚合規則,比較不便。為解決這個問題,我們自研了查詢代理Proxy,與聚合配置聯動,為用户提供統一的數據查詢接口,查詢請求經過查詢代理時直接優化修改用户的PromQL,將原始數據查詢轉為聚合數據查詢、檢測聚合數據正確性等。
Flink聚合任務數據穩定性建設
在設計我們的Flink任務Recording Rules過程中,也引入了一些新的問題,以下是一些重點問題的解決方案。
任務發佈、Failover的處理
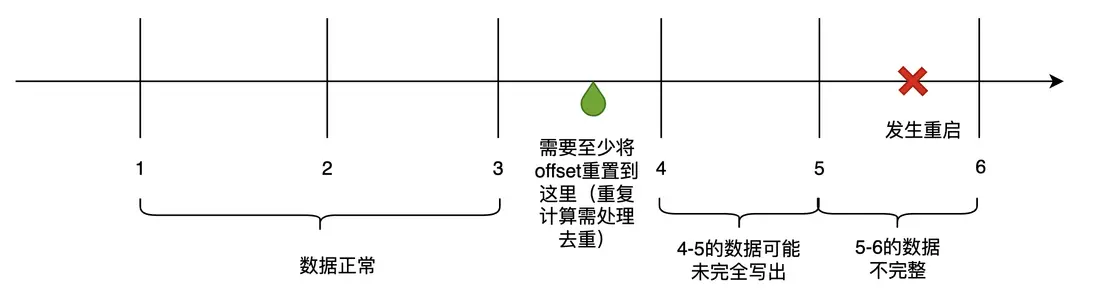
當Flink任務有需求變更、或底層資源導致的Failover,會發生任務重啓,導致聚合停止。重新拉起服務時,從Kafka當前位點繼續消費,無法完整拿到當前這分鐘的完整數據,上一分鐘的數據也可能未完全寫出,故會造成數據丟失和錯誤。
時序監控數據的丟失、錯誤會直接影響到告警、問題排查,需要儘量避免。考慮到時序數據量級大,Checkpoint存儲成本高、效率低,我們採用記錄Kafka位點,重啓時將位點向前重置、重新計算的方式。在數據處理時,定期將當前處理到的kafka timestamp offset記錄下來,重啓時向前推至少2個聚合間隔。offset前推引入的數據重複問題,我們藉助vmstorage自帶數據去重處理。
Flink任務內部序列化優化
我們的聚合數據量極大,超過了250萬+QPS,且對實時性要求高,若通過簡單擴容去支撐該量級,需要的IT資源過高,故需要提高任務效率。通過火焰圖抓取可以發現,我們的任務花費了大量開銷在Function之間的序列化上,我們的數據是JavaBean,其中包含泛型的HashMap,會劣化為性能最低的Kyro序列化。我們重新抽象了數據結構,將其設計為Flink原生的Tuple類型,其中只用基本數據類型。在同樣的數據源和運行環境下對比,序列化開銷從54%降低為15%(下火焰圖中紫色部分為序列化),在物理資源不變的基礎上,任務支撐處理的輸入QPS擴大數十倍。
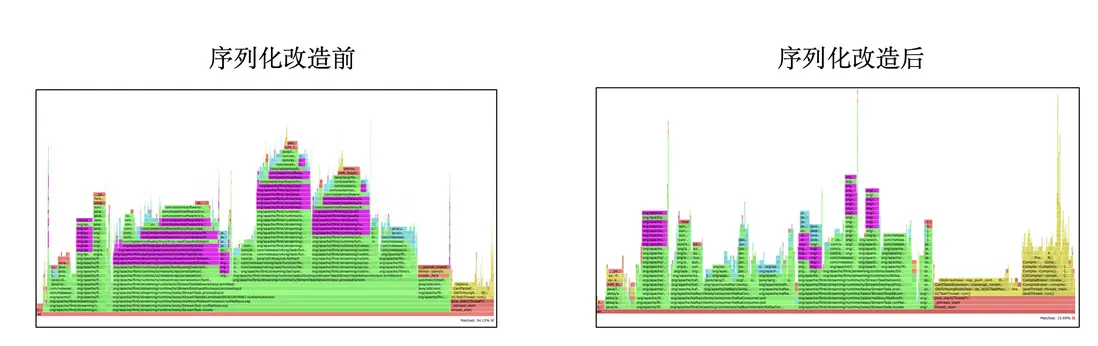
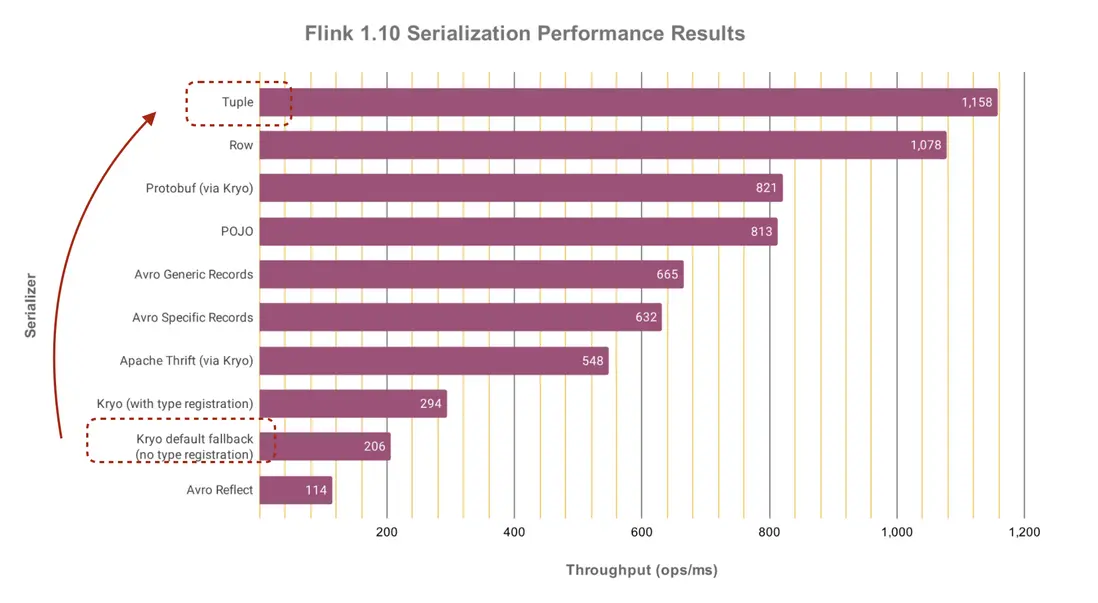
以下是Flink官方提供的各序列化的效率對比,可知Tuple序列化對比Kryo有巨大提升。
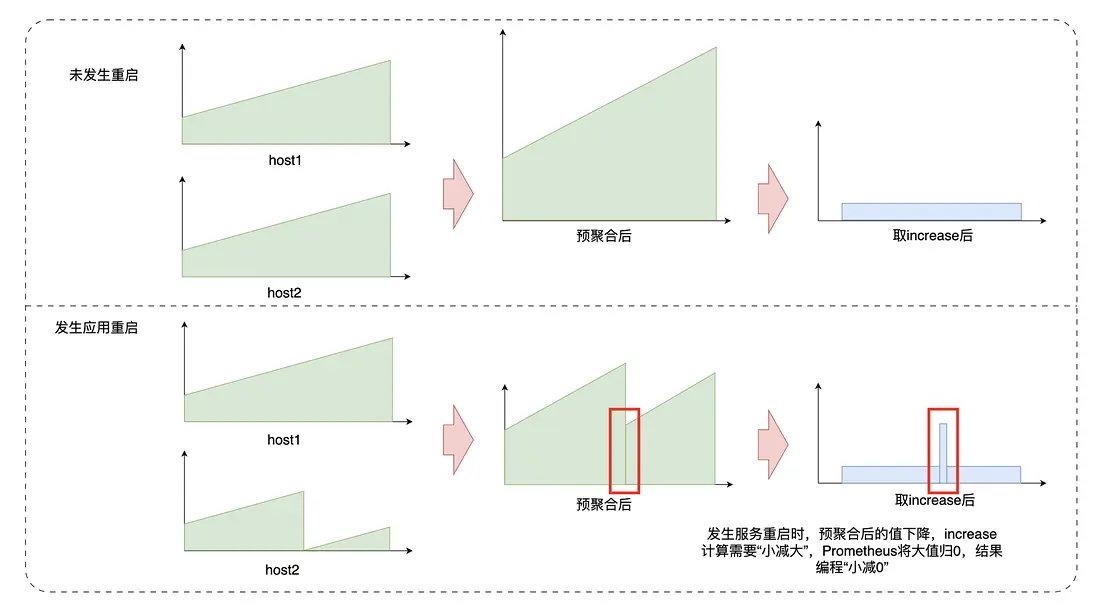
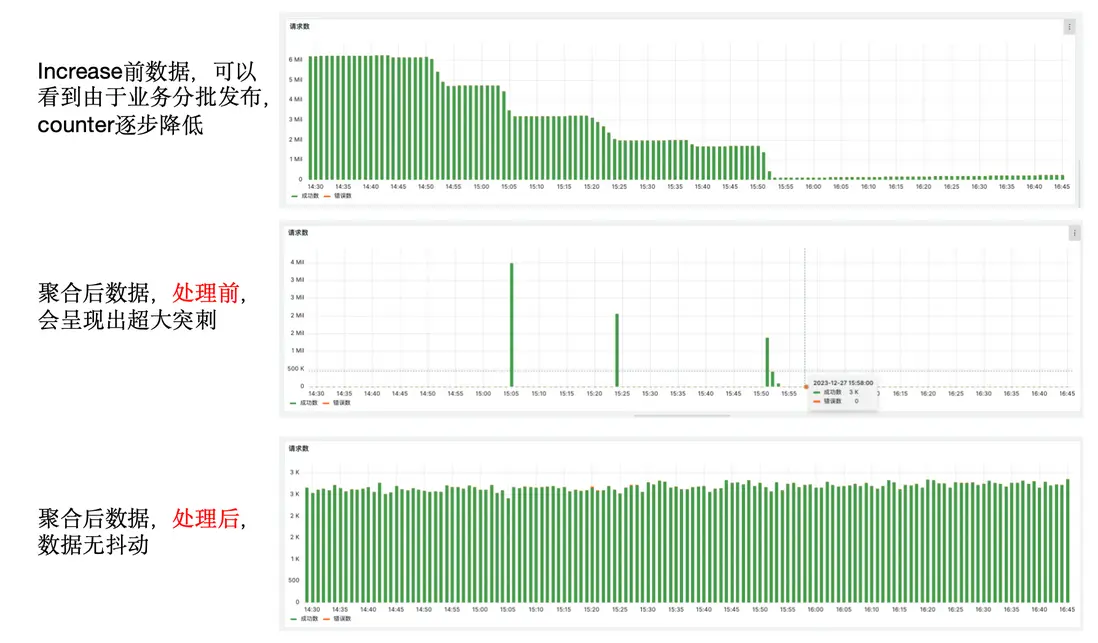
踩坑解決:Counter數據預聚合值下降導致Increase值突刺
問題背景
採用預聚合的方案會遇到以下問題:目前我們的數據聚合主要是針對Counter做求和聚合,Counter的特點是在同一數據源上是累增的,若要獲取一段時間內的值,需要用區間末尾減掉區間開始。
我們若按照集羣聚合,第n分鐘該集羣發佈,則會有服務的Counter被重置為0,導致整個集羣的聚合值下降。若此時我們用PromQL的rate或increase函數查詢發佈這一分鐘的值,存儲層會用n分鐘的值減n-1分鐘的值,但此時n分鐘的值大於n-1分鐘的值,即小值減大值。此時存儲層會認為該Counter被重置,基數應當為0,則變成n分鐘的值減0,得到n分鐘的值。由於集羣發佈前大概率已經累計了很長時間的Counter,此時n分鐘的值可能非常大,會導致這一分鐘的increase結果非常大,展示在圖表上為一個超大的突刺。
若要在預聚合中像查詢時聚合一樣,在rate時對每條被聚合的原始數據一一檢測counter重置,那麼則需要存儲每條原始數據的前值並一一檢測,如此存儲成本和計算成本都很高,所以我們需要其他方法來規避掉這個問題。
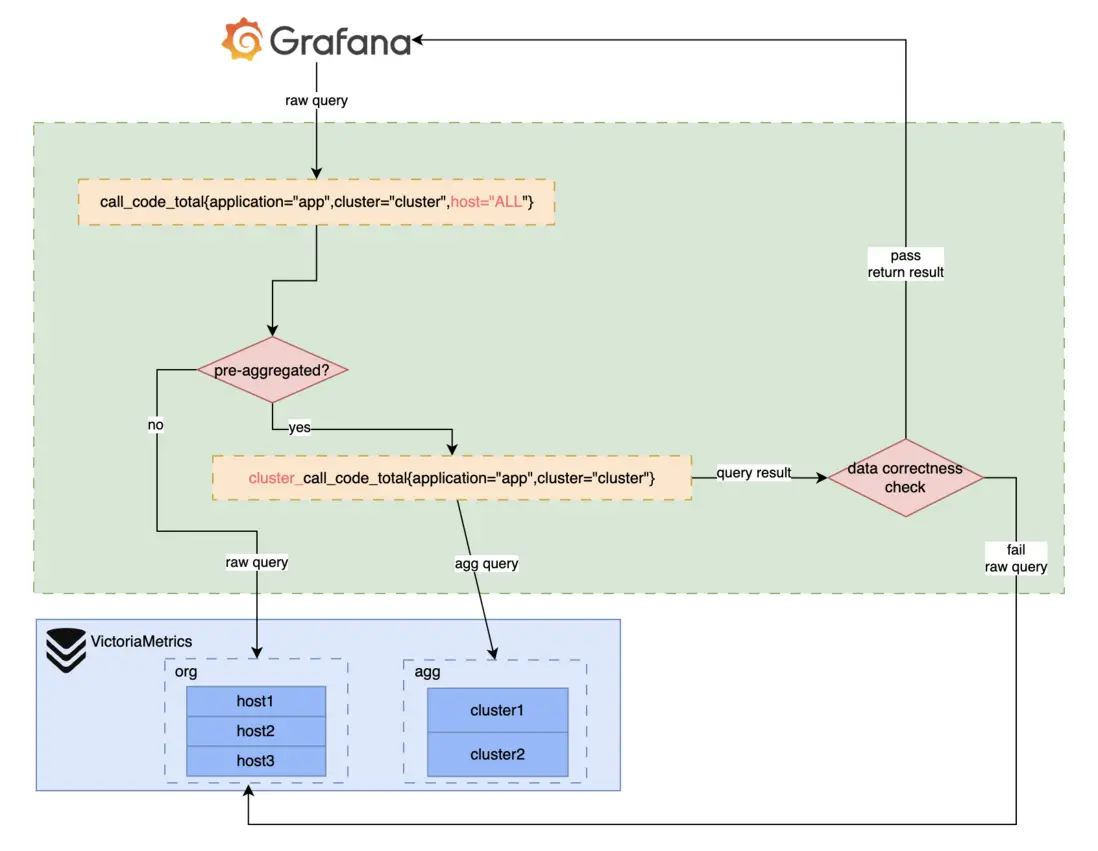
解決方案:通過查詢代理Proxy實現聚合數據正確性檢測
前文的問題背景介紹中已經介紹過,Counter的聚合數據在遇到increase查詢時會發生超大的突刺,我們想到在查詢時檢測和屏蔽這種情況。我們自研的Proxy查詢代理,本身的功能是自動解析修改業務的PromQL,將普通查詢轉為原始查詢,我們設計在這個轉換過程中檢測數據正確性。
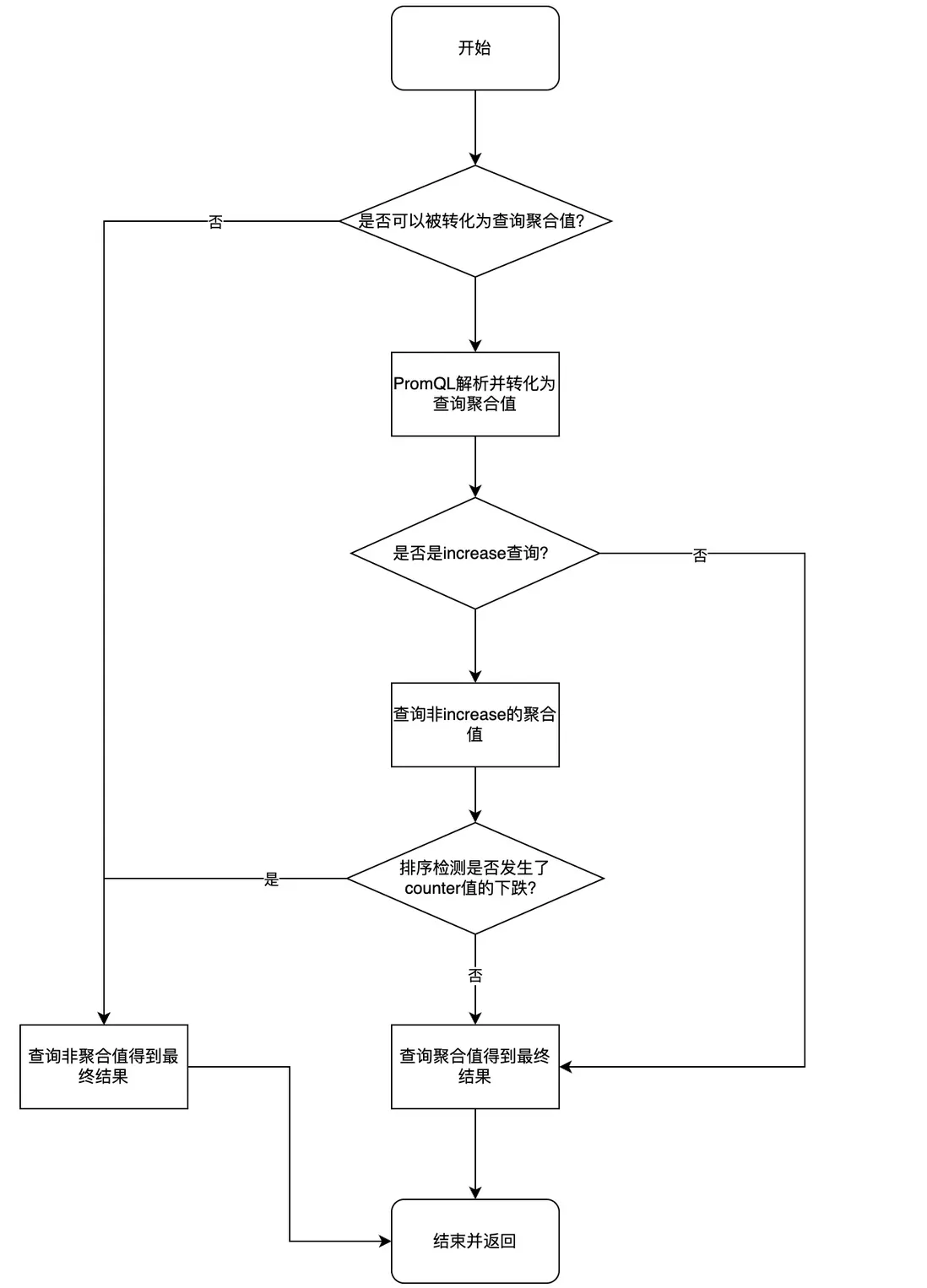
通過此方案,我們解決了該問題。
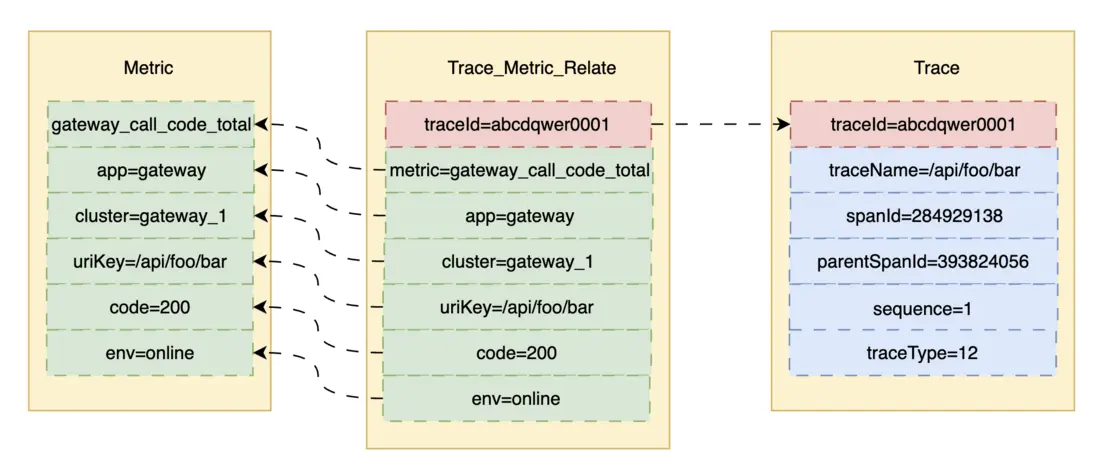
2.3 Metric與Trace關聯分析
為關聯Metric和Trace,我們設計了關聯表,單獨上報存儲。我們從Metric關聯到Trace時,先通過Metric的label、value、時間範圍查出TraceId列表,隨後查出對應的Trace詳細信息。
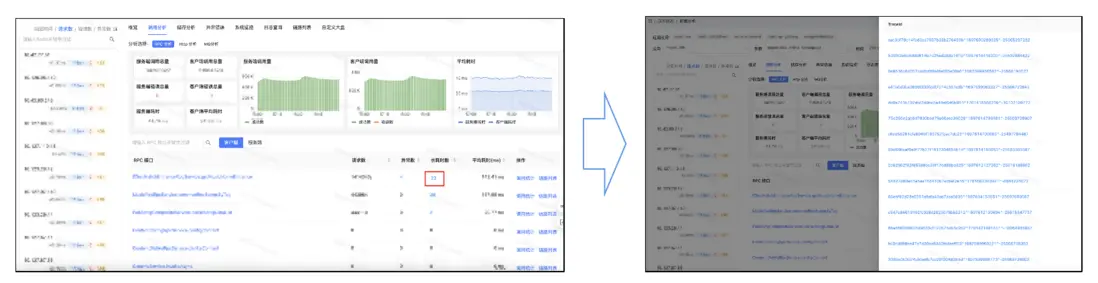
在APM平台設計上,我們將Metric數值做成了可點擊的按鈕,用户點擊即查詢出關聯到的TraceId列表,進一步點擊可看到詳細內容。
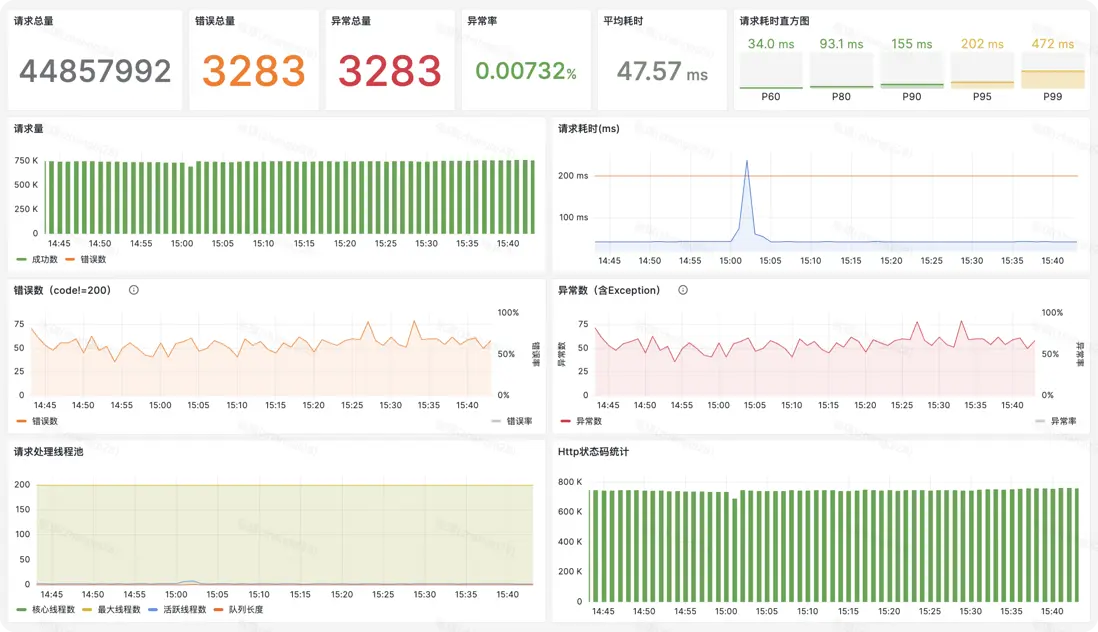
2.4 高效的Metric監控可視化與圖表分析能力
- Metric可視化:我們使用Grafana來可視化Metric數據,設計了大量直觀的Dashboard,維度包括應用總覽,各組件如HTTP、RPC、Redis、數據庫、MQ等的總覽、異常、錯誤、請求執行的圖表。如以下為某服務的請求總覽Dashboard,用户可直觀看到總量、P99、異常率、平均耗時、錯誤碼、線程池等信息,非常方便。
-
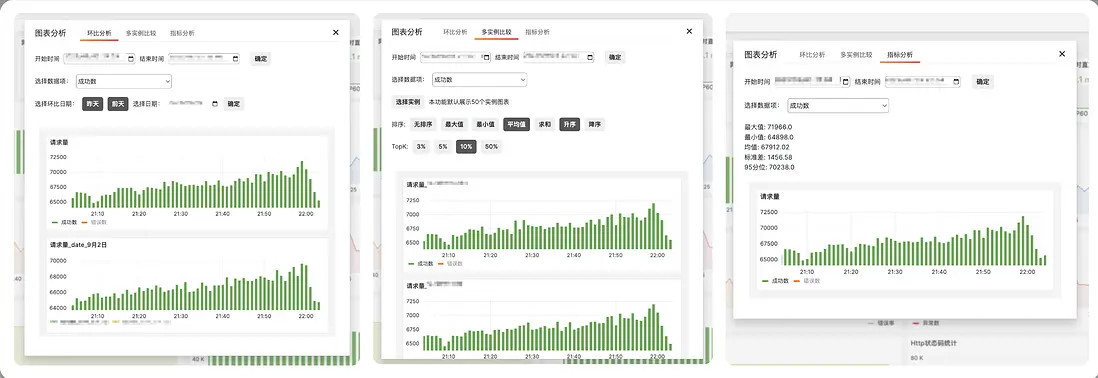
圖表分析能力:在日常故障排查中,經常需要進行時間跨度和實例之間的比較分析。我們選型的Grafana雖然對時序數據的可視化支持很好,但對圖表比較分析的支持較弱。因此我們對Grafana做了二次開發,支持了以下功能:
- 環比分析:支持用户對監控項跨時間段比較;
- 多實例比較:支持用户同集羣內的同監控項跨實例比較,還支持按照不同的數據指標排序、查看TopK的實例等;
- 指標分析:幫助研發一鍵計算曲線的數據指標,方便數據統計方面的需求。
三、總結
基於VictoriaMetrics的Metric監控目前已經在雲音樂各業務線全面推廣,目前支撐活躍時序近7億。其帶來的優勢如下:
- Metric與Trace關聯排障,打破信息孤島;
- 應用層監控能力提升:補足應用層各維度Metric監控數據可視化,應用觀測能力明顯提升,可直接產出P99等指標,問題定位能力強;
- 大規模業務低成本Grafana可視化:利用Grafana的低代碼配置,省去大量開發成本;
- 低成本解決大規模時序數據存儲:基於VictoriaMetrics的存儲方案成本低、性能高,經對比所佔用資源僅需如M3DB等方案約三分之一。
在未來我們將持續拓展監控能力,在智能分析、智能告警等方向持續深挖,為業務發展保駕護航。
最後

更多崗位,可進入網易招聘官網查看 https://hr.163.com/