

本文介紹了美團技術團隊在國際頂會ACL 2025中發表的8篇論文,研究方向覆蓋了生成式檢索算法、多目標偏好對齊訓練、富文本圖像理解、搜索詞推薦、跨語言遷移能力、多模態數學推理、第三人稱任務等技術領域,希望相關研究能給同學們帶來一些幫助或啓發。
ACL是計算語言學和自然語言處理領域最重要的頂級國際會議,由國際計算語言學協會組織,每年舉辦一次。據谷歌學術計算語言學刊物指標顯示,ACL影響力位列第一,是CCF-A類推薦會議。ACL成立於1962年,是世界上影響力最大、最具活力的國際學術組織之一,它每年夏天都會召開大會,供學者發佈論文,分享最新成果,它的會員來自全球60多個國家和地區,是NLP領域最高級別的國際學術組織,代表了國際計算語言學的最高水平。
01 Multi-level Relevance Document Identifier Learning for Generative Retrieval
論文類型:Long Paper(ACL 2025 Main)
論文下載:PDF
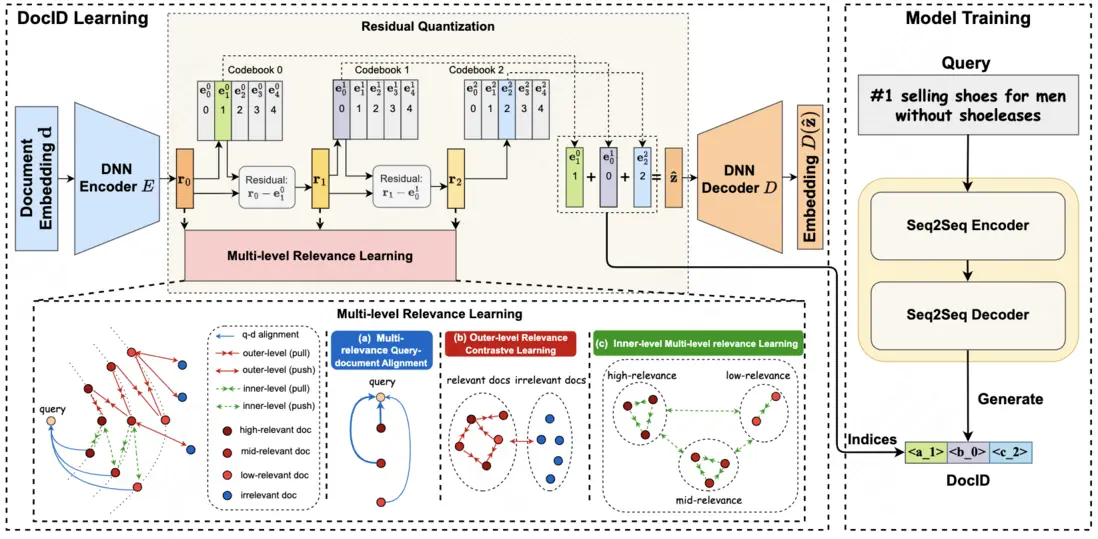
論文簡介:本文提出一種基於多級相關性的生成式檢索文檔標識符學習方法(MERGE),旨在解決生成式檢索範式中的關鍵挑戰。針對現有方法僅依賴文檔文本生成離散標識符(DocIDs)導致語義關聯不足的問題,本方法引入查詢作為關聯橋樑,構建多級文檔相關性學習框架。該方法通過三個核心模塊實現:多相關性查詢-文檔對齊模塊建立文檔表徵與相關查詢的有效映射,外層對比學習模塊捕捉二元相關性特徵,內層多級相關性學習模塊實現細粒度文檔區分。該方法在保持文檔標識符唯一性的同時,編碼了豐富的層次化語義信息。在公開的多語言電商搜索數據集的實驗表明,MERGE在檢索性能上顯著優於現有基準方法,驗證了其通過多級相關性建模提升文檔標識符語義表徵能力的有效性。
02 HierGR: Hierarchical Semantic Representation Enhancement for Generative Retrieval in Food Delivery Search
論文類型:Industry Oral
論文下載:PDF

論文簡介:本文針對生成式檢索(Generative Retrieval, GR)在外賣搜索場景中的實際應用挑戰展開研究,提出基於層次化語義表徵增強的生成式檢索方法(HierGR)。針對在線部署面臨的商品規模大、大模型推理延遲高及地理位置服務(LBS)限制嚴格等核心問題,本文提出了離線訓練與在線部署協同優化方法:首先設計改進殘差量化過程的層次化語義標識符生成方法,構建具有空間層級特徵的語義ID體系;其次採用查詢緩存機制降低延遲,並通過與在線稠密檢索模型的聯合部署滿足實時搜索需求。實驗結果表明,在美團外賣搜索場景下,複雜意圖Query的搜索效果提升顯著,千人成單+0.68%,驗證了生成式檢索技術在外賣搜索領域落地的可行性。
03 AMoPO: Adaptive Multi-objective Preference Optimization without Reward Models and Reference Models
論文類型:Long Paper
論文下載:PDF
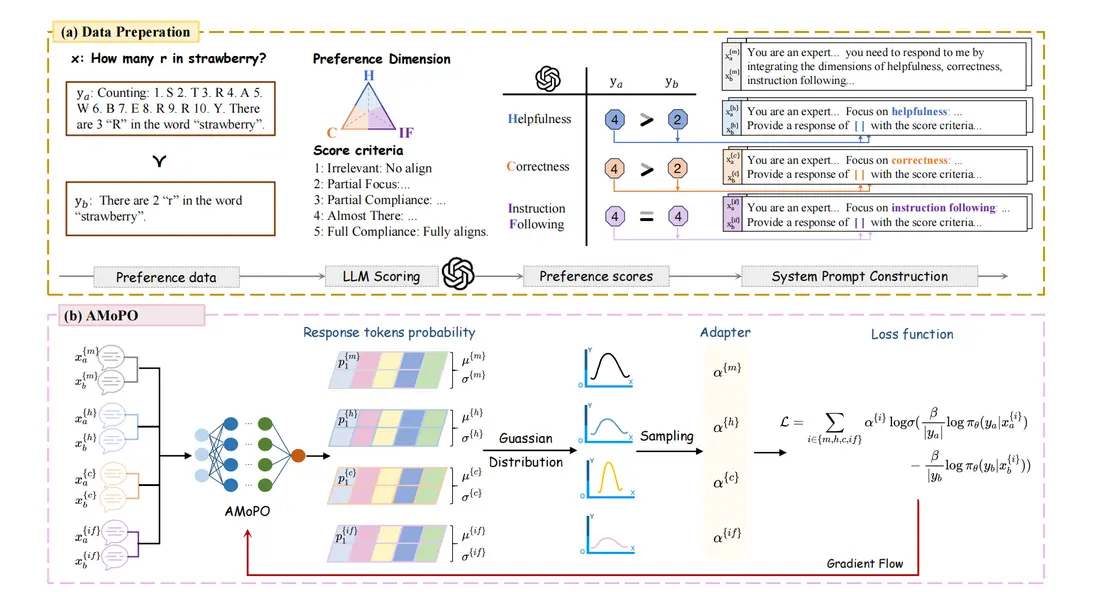
論文簡介:本文提出了一種自適應參考模型自由的多目標偏好優化算法AMoPO(Adaptive Reference-free Multi-objective Preference Optimization),以解決現有多目標偏好優化方法在訓練複雜度和計算資源消耗上的突出問題。傳統方法如DPO、SimPO和MODPO在多目標優化時需要多輪訓練或多個獎勵模型,導致效率低下、資源消耗大。而在實際業務中,對一個回覆的評估常常涉及多個維度(如擬人性、指令遵循性等),單一維度的優化難以滿足需求。為此,本論文提出了AMoPO算法無需依賴參考模型和獎勵模型,通過自適應採樣策略動態調整各維度權重,在單次優化過程中即可高效實現多目標偏好優化。該方法顯著降低了計算資源消耗,同時實現了多維度偏好的自適應優化。在公開數據集上以及業務上的實驗結果表明,AMoPO在有效性、效率和多維度自適應優化能力方面均具有顯著優勢。
04 Multimodal Large Language Models for Text-rich Image Understanding: A Comprehensive Review
論文類型:Findings
論文下載:PDF
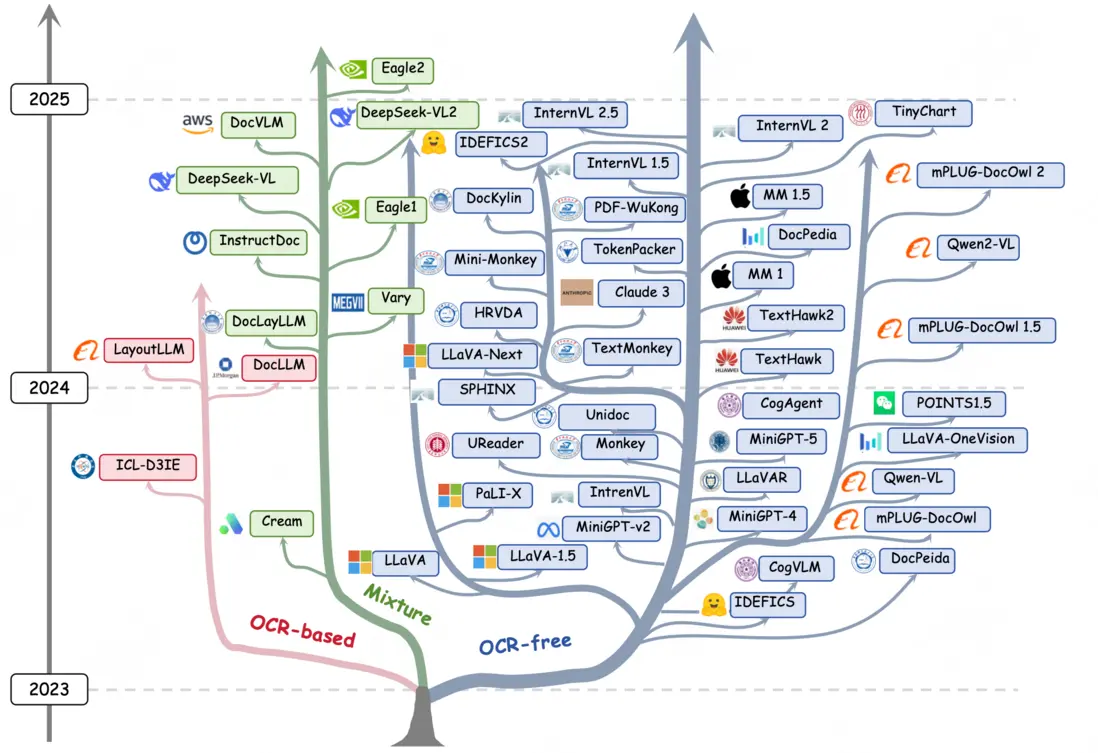
論文簡介:近年來,多模態大型語言模型(MLLM)的興起為富文本圖像理解(TIU)領域引入了一個新的維度,這些模型展現出令人印象深刻的性能。然而,它們的快速發展和廣泛應用使得研究者們跟上最新進展變得越來越具有挑戰性。為了解決這個問題,我們提出了一項系統而全面的綜述,以促進對 TIU MLLM 的進一步研究。首先,我們概述了幾乎所有 TIU MLLM 的時間線、架構和流程。然後,我們回顧了所選模型在主流基準測試中的表現。最後,我們探討了該領域的發展方向、挑戰和侷限性。
05 Consistency-Aware Online Multi-Objective Alignment for Related Search Query Generation
論文類型:Industry Track
論文下載:PDF
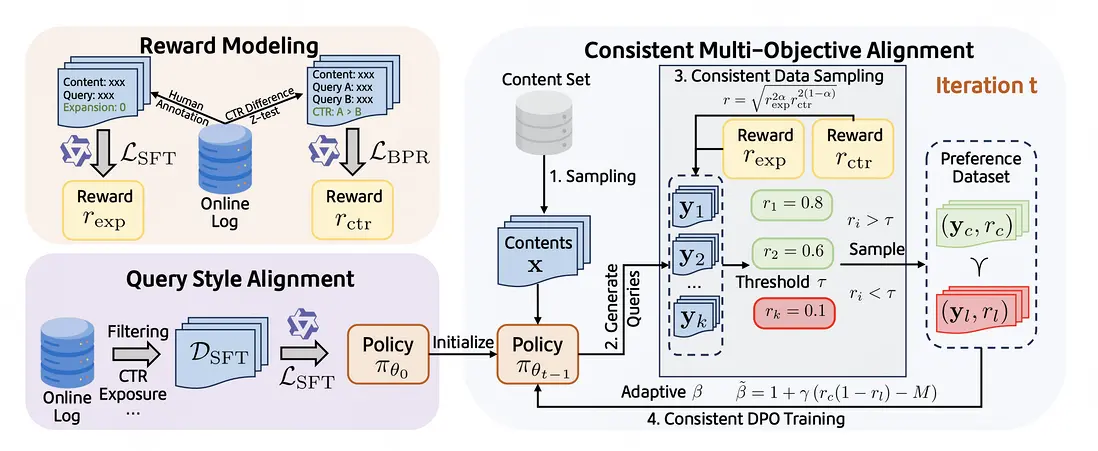
論文簡介:在現代數字平台中,相關搜索場景下的搜索詞推薦對於提升用户參與度和內容發現至關重要。然而,現有方法往往難以在優化點擊率(CTR)和促進主題延展性這兩個核心目標之間取得平衡,尤其是在利用大型語言模型(LLM)進行查詢生成時,多目標對齊的挑戰尤為突出。這主要面臨三大挑戰:1)如何精確量化並建模不同的優化目標(如CTR和主題延展性);2)如何確保生成搜索詞的格式和風格與平台保持一致;3)如何有效協調可能衝突的多目標以實現共同提升,避免顧此失彼。針對這些挑戰,本文提出了CMAQ(Consistency-aware Multi-objective Aligned Query generation),一個面向相關搜索詞生成的在線多目標對齊框架。CMAQ包含三個關鍵組成部分:1)精確的獎勵建模,針對兩個目標的區別,為CTR和主題擴展分別使用不同策略訓練獎勵模型;2)搜索詞風格對齊,通過監督微調(SFT)使LLM適應平台搜索詞風格;3)一致性感知的多目標優化,迭代式直接偏好優化(DPO)策略。該策略通過幾何平均獎勵進行一致性數據採樣,並引入樣本級別自適應的β調整DPO損失,從而在優化過程中提升樣本層面和損失層面兩個目標的一致性,緩解目標衝突。離線實驗結果顯示,CMAQ在以CTR獎勵和延展性獎勵為維度的帕累託前沿上顯著優於基線方法。同時,在大型工業級生活服務平台大眾點評上進行的在線A/B測試表明,CMAQ實現了顯著的在線CTR提升(+2.3%)。此外,人工評估也證實了CMAQ生成的查詢質量更高。這些結果共同證明了CMAQ不僅能有效提升查詢生成質量和用户參與度,也為多目標LLM對齊提供了新的思路,有助於維護平台生態健康。
06 Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training
論文類型:Findings
論文下載:PDF
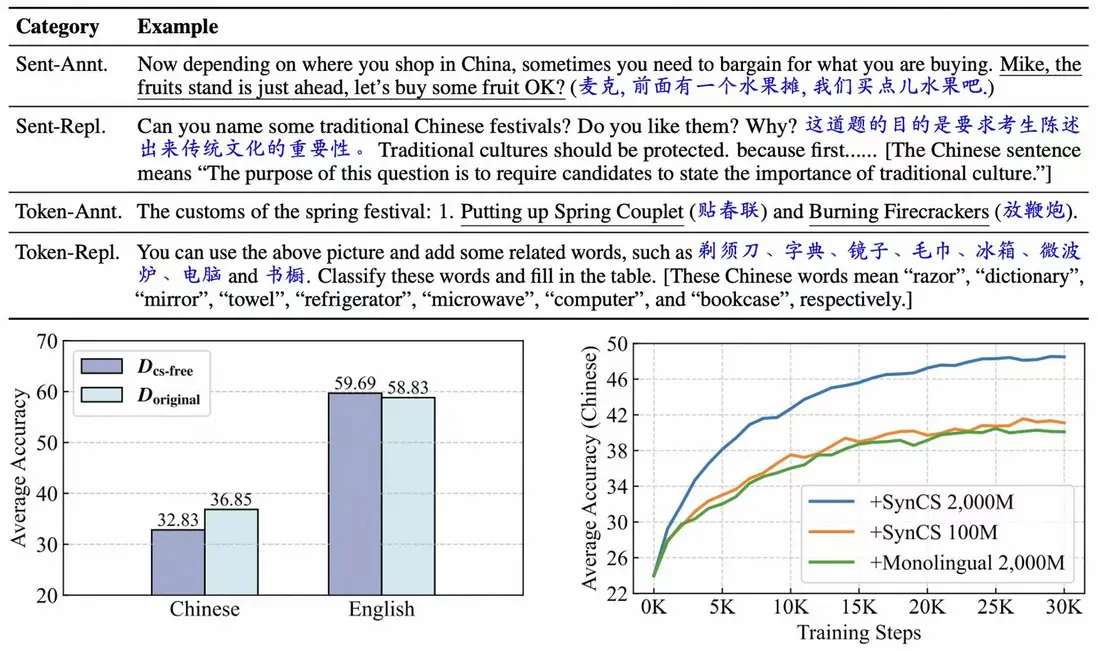
論文簡介:在本文中,我們聚焦於當前大語言模型的自發跨語言遷移能力:儘管大多數開源大模型在其預訓練語料中僅包含少量多語言數據(例如 LLaMA-3 的多語言數據佔比僅為8%,平均到每種非英語語言則比例極低),這些模型卻仍展現出較強的多語言理解與生成能力。我們認為,這種現象源於模型在預訓練過程中發生了自發的跨語言遷移 ,即模型能夠從主要訓練語言(如英語)中學習到的能力自動遷移到其他語言上。然而,目前關於這一現象的研究尚缺乏對其數據層面成因的系統解釋 ,這在一定程度上限制了多語言大模型的發展與優化。針對該現象,本文開展了深入研究,我們發現,即使在大模型的預訓練語料中 Code-Switching 數據的比例非常低,它們仍然是引發大模型自發跨語言遷移的關鍵因素,其中 Code-Switching 指的是在同一個上下文中混合使用多種語言的現象。在此基礎上,我們進而提出了一種低成本、高效率的 Code-Switching 數據合成方法 SynCS(Synthetic Code-Switching)。我們系統比較了不同類型的 Code-Switching 數據在擴大規模時對模型跨語言遷移能力的影響差異,最終形成了一套通過合成 Code-Switching 數據來增強大模型多語言能力的有效策略 。
07 The Role of Visual Modality in Multimodal Mathematical Reasoning: Challenges and Insights
論文類型:ACL 2025 Main(Oral)
論文下載:PDF
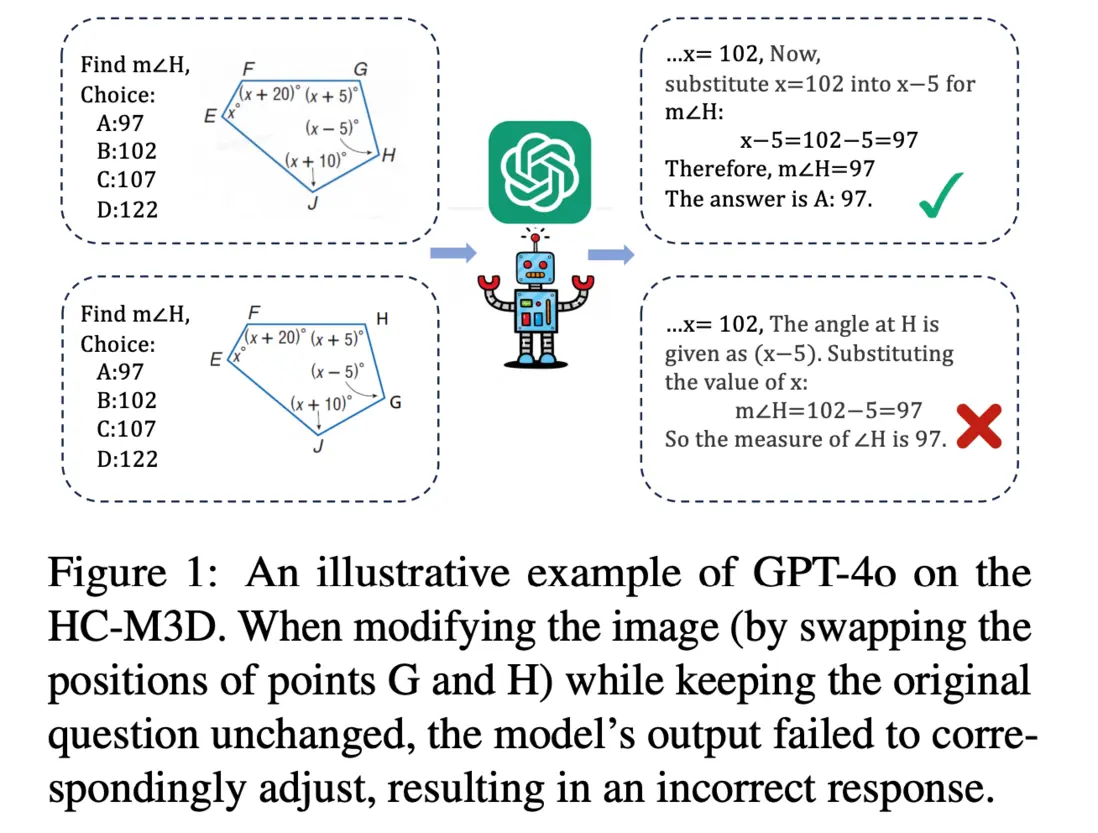
論文簡介:隨着大型視覺-語言模型(LVLMs)的迅猛發展,多模態數學推理成為了AI研究中的熱門領域。然而,視覺信息在模型推理中真正發揮了多少作用?在本研究中,我們揭示了現有模型可能過於依賴文本而忽略了視覺信息的潛在價值。我們設計了一項視覺模態擾動實驗,在訓練過程中隨機打亂圖像與文本之間的對應關係或完全移除圖像,訓練完成後與正常訓練的模型對比性能差異。結果顯示,即使在這些干擾下,當前主流模型的推理性能也僅出現了輕微下降。這表明,模型的推理過程主要受文本信息的引導,視覺信息的作用遠未被充分利用。與之對照的是,通用領域中,對視覺模態的擾動會大幅度降低性能。進一步分析發現,現有的評測基準中存在兩個明顯的問題:很大一部分數據由文本模型即可正確回答以及模型可以根據選項來猜測答案。基於上述的觀察,我們認為現有的評測數據集無法準確反映視覺模態在推理過程中的重要性,因此提出了HC-M3D數據集。該數據集包含1,851條人工標註的數據,其中429個問題包含對照組,對照組為對圖片做出關鍵修改來確保答案變化。實驗發現即便是最先進的模型在面對這些細微變化時也頻頻「失明」,超過一半的情況下堅持原本的預測,未能根據視覺變化進行修正。這一系列發現凸顯了現有多模態數學推理模型對視覺信息利用不足的深層問題,也為未來的研究指明瞭明確方向。我們建議,構建更具視覺挑戰性的數據集、設計更精細的圖像編碼器以及開發更有效的視覺依賴增強機制,將是未來研究的重要突破口。
08 From Observation to Understanding: Front-Door Adjustments with Uncertainty Calibration for Enhancing Egocentric Reasoning in LVLMs
論文類型:Findings
論文下載:PDF
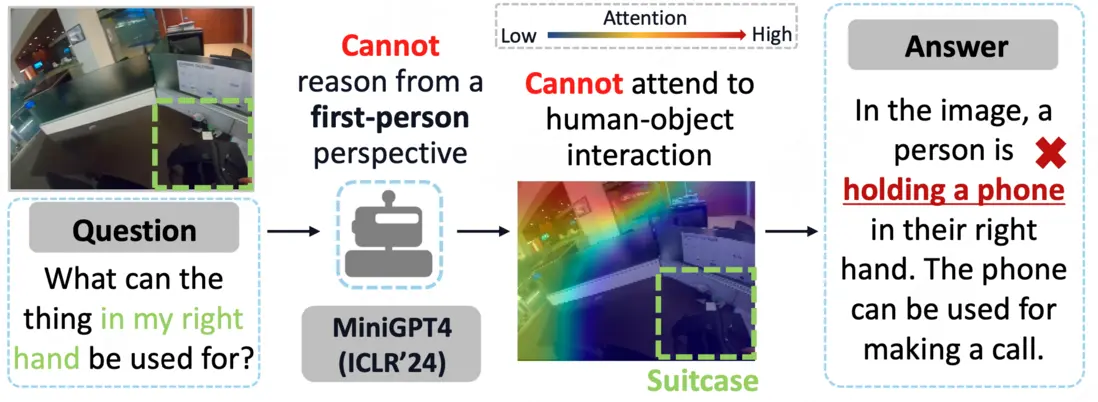
論文簡介:近年來,大型視覺語言模型(LVLMs)在第三人稱任務中展現出巨大潛力。現有方法在將LVLMs應用於第一人稱任務時,往往忽視了關鍵的主體與環境的交互信息,限制了其自我中心推理能力。例如下圖中MiniGPT4未能準確聚焦右下角人物與物體的交互區域,根據經驗誤判右手握持的物體為手機。
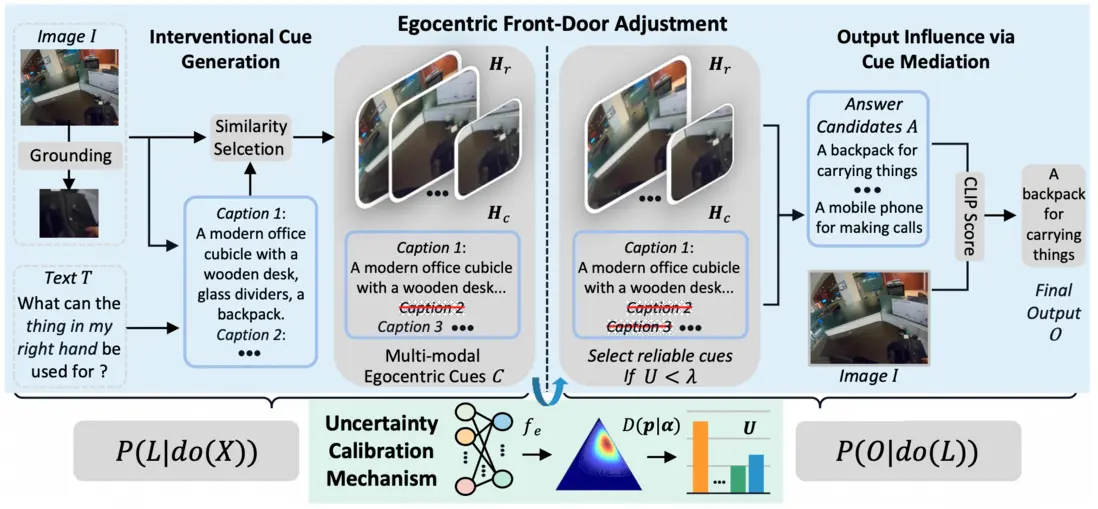
本論文提出了基於不確定性校準的前門調整方法(Front-Door Adjustments with Uncertainty Calibration,FRUIT),通過結構因果模型增強大型視覺語言模型(LVLMs)的自我中心推理能力。該方法分觀察與理解兩階段:首先定位交互區域並構建層次化的視覺-文本線索,然後通過不確定性過濾線索中的噪聲信息,最終將優化的觀察結果整合到提示模板中,指導模型進行第一人稱視角的語義理解。
閲讀更多
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。
| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明 “內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。