

美團業務研發搜推平台部算法團隊創新提出可驗證過程獎勵機制(VSRM),針對大模型推理中的冗餘回覆與過度思考問題,精準獎勵有效推理步驟,顯著縮減輸出長度並提升推理效率。VSRM通過步驟級正確率增益評估,有效抑制無效步驟,兼容主流強化學習算法,助力高效、可靠的複雜推理任務。
1 背景
以 DeepSeek-R1 為代表的大規模推理模型,通過簡單有效的強化學習後訓練方法,培養了強大的推理能力,但卻導致模型傾向於生成冗餘的回覆。這使得模型在為每個輸入請求生成響應時,需要花費更多的時間以及計算資源,最終消磨用户的耐心。
針對這一缺陷,來自業務研發搜推平台部的算法團隊提出可驗證的過程獎勵機制(VSRM),鼓勵 CoT 中的“有效步驟”,懲戒“無效步驟”,最大限度保持性能的同時,實現高效推理。
論文下載地址:PDF
通過在數學任務上的實驗顯示,在多個常用 Benchmark 上,VSRM 加持的後訓練使得不同尺度的模型實現了輸出長度的大幅縮減,甚至在部分情況下提升了模型表現。
2 過度思考問題的本質
此前的工作將過度思考問題的現象總結為:對於一個問題,模型傾向於給出多種不同的解答,特別簡單的問題。在這一認識的基礎上,團隊更進一步,對現有 LRM 在 MATH-500 上做出的回覆進行了深入的 Case Study。

如圖所示,在這個例子中,模型為解決一個非常簡單的子問題([-500,0] 中有多少個小於 0 的整數)進行了反覆的思考,在正確和錯誤之間反覆橫跳,最終得出了一個不正確的中間結論,進而導致了最終結論的錯誤。這些無效步驟不但不能指引推理路徑的發展,反而會導致中間過程出錯。
這樣的案例並不孤立,甚至頻繁出現。基於上述觀察,我們團隊提出:大量無效的中間步驟是導致模型過度思考的根本原因。因此,抑制這些無效步驟,鼓勵有效步驟,是後訓練的核心優化目標。
3 設計可驗證的逐步驟獎勵
現有 RLVR 的機制,通過獎勵函數以可驗證的二元結果獎勵促進模型探索能夠獲得正確答案的解法。但是 結果獎勵無法精確地獎懲不同的步驟,也因此無法達到所期望的目標。
過程獎勵機制雖然能滿足這一要求,但 過程獎勵模型(PRM)往往難以訓練且預測結果的可靠性有限,針對數學問題/代碼編程等推理任務更是 嚴重欠缺可解釋性。
搜推技術團隊將可驗證獎勵與步驟級獎勵結合在一起,創造性地提出 VSRM,為推理過程中的每個中間步驟分配獎勵信號,從而實現對不同步驟的鼓勵和抑制,天然地契合推理任務分步作答的特點。
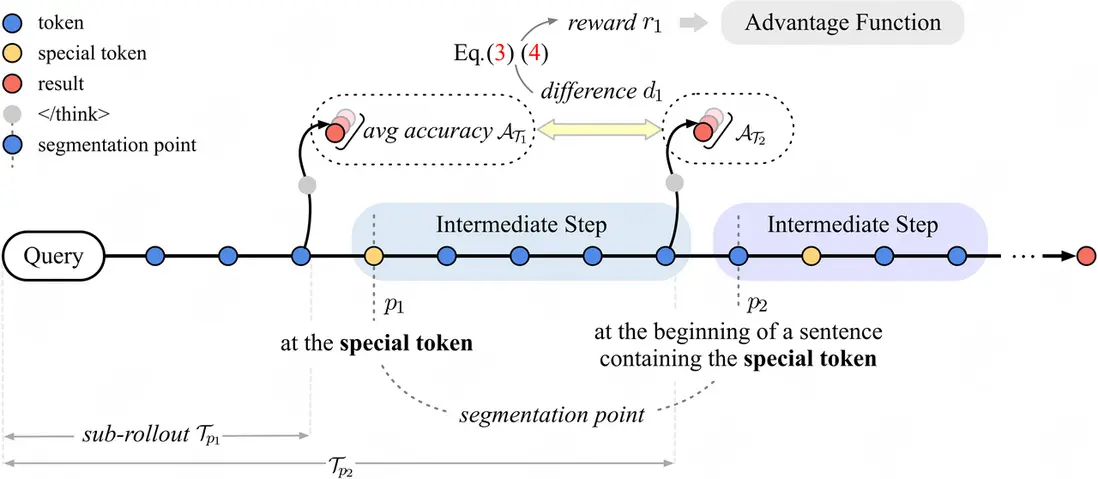
3.1 步驟劃分
引入步驟級獎勵的第一步是定位所有的步驟。
在 CoT 中,一些特殊的 Token,比如“However”、“Therefore”、“So”、“But”、“Wait”等往往表示模型已經完成了一個推理步驟,即將進行下一步推理(遞進或是轉折)。這些特殊 token 的存在將整個軌跡劃分成了多箇中間步驟。
為了保證劃分後內容的可讀性,我們額外設計了三條規則:1. 跳過最初的若干 token,這部分內容往往是對問題進行重述。2. 相鄰劃分點之間必須至少間隔一定距離,避免過度分割。3. 若特殊 token 位於句子內部,將劃分點放在該句句首。
3.2 獎勵分配
為了評估中間步驟有效與否,最直接的方式就是評估該步驟完成前後帶來的正確率增益。而正確率是完全可以通過可驗證的方式得到的。
只需要在每個劃分點的位置前,加上一個 </think> token,這樣,從 query 開始,到該處的 </think>,就構成了一條子軌跡。
以每個子軌跡為 prompt,模型能夠產生多個候選答案,平均正確率體現了當前步驟得到正確答案的概率。
$$\mathcal{A}_{\mathcal{T}_{i}}=\frac{1}{N} \sum_{j=i}^{N} I\left(\operatorname{IsCorrect}\left(\operatorname{LRM}\left(\mathcal{T}_{i}\right)_{j}\right)\right)$$
相鄰子軌跡的正確率差值,即為完成當前步驟後獲得的正確率增益。
$$d_{i-1}=\mathcal{A}_{i}-\mathcal{A}_{i-1}, \quad \text { for } i \in[1, \ldots, k]$$
直接將增益作為步驟級獎勵就能夠指導模型區分有效與無效步驟。但考慮到,往往若干個步驟才能夠導致解題過程的實質性推進,因此,多個連續步驟的平均正確率很可能保持不變,進而導致稀疏的獎勵信號,不利於優化。
$$r_{i-1}=\operatorname{sgn}\left(d_{i+q-1}\right) \cdot\left|d_{i+q-1}\right| \cdot \gamma^{q}$$
為了避免這種情況,引入前瞻窗口機制,將未來的正確率變化通過折扣因子傳播給當前步,從而確保獎勵信號儘量密集。
通過這種機制,VSRM 機制實現了為每個步驟分配可驗證的,步驟級獎勵信號,從而鼓勵模型減少無效步驟的輸出。
與直接施加長度懲罰不同,VSRM 直接從源頭上給予模型最清晰明瞭的獎勵信號,引導模型更多選擇對提升最終正確率有幫助的步驟,在緩解過度思考問題的同時,最大限度地保留模型性能。
$$R_{\mathcal{T}}=\left[\ldots, r_{1}, \ldots, r_{t}, \ldots, r_{k}, \ldots, r_{\mathcal{T}}^{\text {result }}+r_{\mathcal{T}}^{\text {format }}\right]$$
VSRM 機制本身與 強化學習算法解耦,能夠天然地適配支持過程獎勵的方法,只需將逐步獎勵添加到最終的 Reward Tensor 即可,搭配常用的結果二元結果獎勵和格式獎勵,即可無縫實現高效推理。
4 實驗
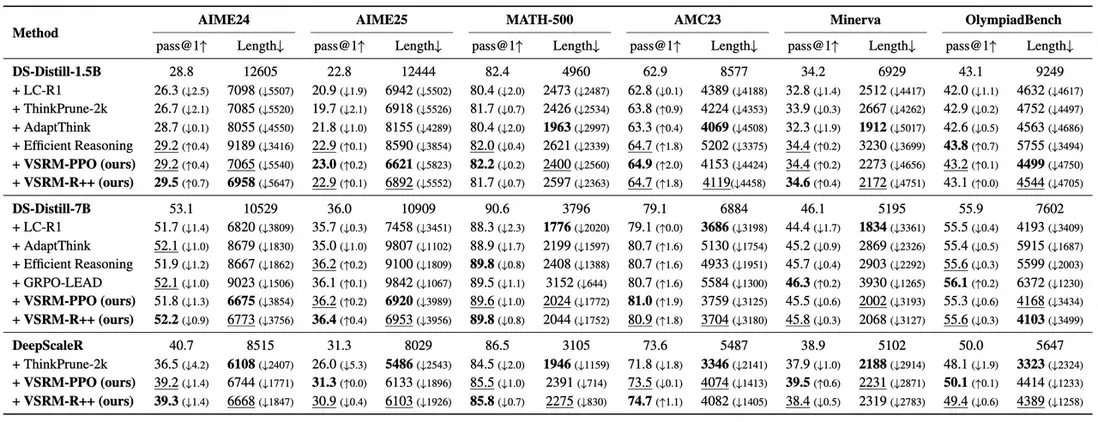
在數學問題最常用的 Benchmark 上,使用三個不同 Base Model,兩種 RL 算法,將 VSRM 與多種最新的相關工作進行對比,實驗結果展現出 VSRM 在降低輸出長度的同時,能夠最大限度地保持性能,取得很好的均衡。

消融實驗的結果顯示了 VSRM 中,前瞻窗口機制的有效性,以及,額外的顯式長度懲罰對於 VSRM 機制並無幫助。
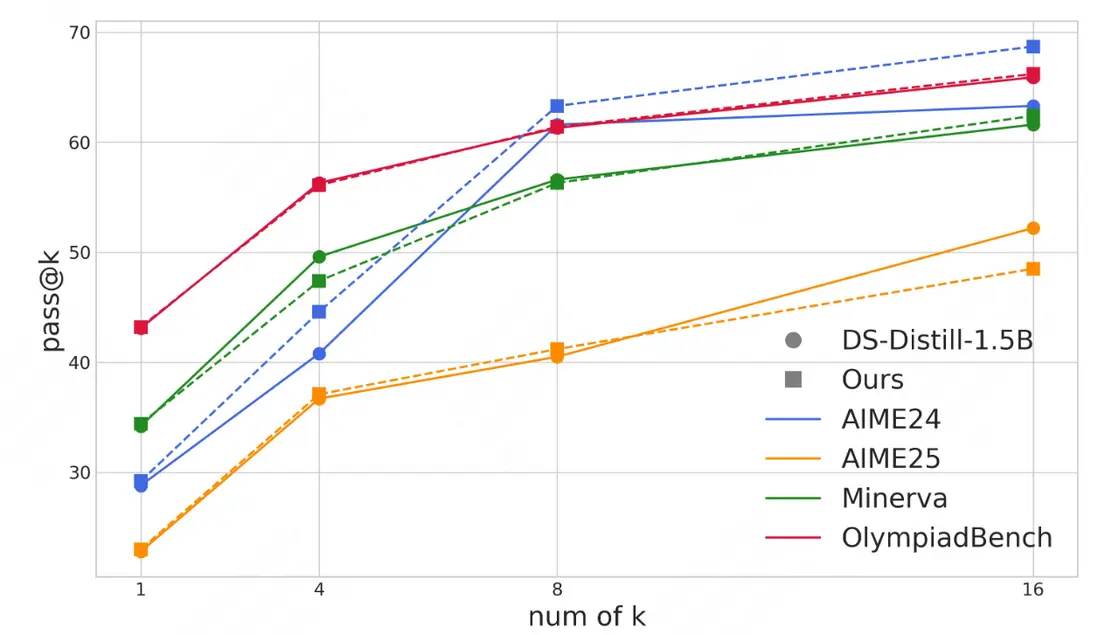
在困難 Benchmark 上,隨着 k 的增加,Pass@k 指標的提升趨勢能夠反饋模型探索更多可行解的能力。可以看到 VSRM-PPO 訓練後的模型,體現了與原本模型一致的趨勢,説明模型並沒有因為輸出長度的壓縮而失去了最重要的探索能力。
5 總結
通過廣泛的對比實驗,我們證明了可驗證的過程獎勵在不同 RL 算法,不同 Base Model 的設置下,均能實現保持性能的同時,極大緩解過度思考問題。消融實驗以及進一步的實證分析也展示出,可驗證的過程獎勵,真正起到了抑制無效步驟,鼓勵有效步驟的作用,是從根本上解決過度思考問題,保持模型良好推理行為的有效途徑。
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。