

9 月 1 日,美團正式發佈並開源 LongCat-Flash-Chat,它採用了創新性混合專家模型(Mixture-of-Experts, MoE)架構,實現了計算效率與性能的雙重優化。
SGLang 團隊是業界專注於大模型推理系統優化的技術團隊,提供並維護大模型推理的開源框架 SGLang。近期,美團 M17 團隊與 SGLang 團隊一起合作,共同實現了 LongCat-Flash 模型在 SGLang 上的優化,併產出了一篇技術博客《LongCat-Flash: Deploying Meituan's Agentic Model with SGLang》,文章發表後,得到了很多技術同學的認可,因此我們將原文翻譯出來,並添加了一些背景知識,希望更多同學能夠從 LongCat-Flash 的系統優化中獲益。
1. 引言:美團開源 LongCat-Flash 智能體模型
LongCat-Flash——美團 LongCat 團隊開源的創新性混合專家模型(Mixture-of-Experts, MoE)現已在 Hugging Face 平台開源,我們總結了 LongCat-Flash 的一些特性:
- 總參數量達 5600 億
- 每 Token 激活參數 186 億-313 億(平均 270 億)
- 512 個前饋網絡專家 + 256 個零計算專家
- 採用 Shortcut-Connected MoE(ScMoE)實現計算-通信重疊
- 集成多頭潛在注意力機制(MLA)
基於多項基準測試,作為非思考型基礎模型,LongCat-Flash 僅通過少量參數激活即可達到與主流領先模型相當的性能表現,在智能體任務方面尤為突出。此外,得益於以推理效率為導向的設計理念和架構創新,LongCat-Flash 展現出顯著更快的推理速度,使其更適用於複雜且耗時的智能體應用場景。

更多內容可以參考我們的技術報告:《LongCat-Flash Technical Report》
2. 為什麼模型-系統協同設計很關鍵?
LongCat-Flash 在面向吞吐和延時的模型-系統的協同設計(Model-System Co-design)方面做了大量工作。這主要是因為我們更多希望 LongCat-Flash 能成為 Agent 場景下可以大規模使用的一個模型。正如我們在技術報告裏面所講,基於 ReACT 模式的智能體系統由於其多輪對話特性,對預填充(Prefill)和解碼(Decode)速度都提出了極高的要求,更快的響應速度,給用户端到端的體驗會更加明顯。為了解決 Prefill 和 Decode 的問題,我們分別設計了零專家機制和 Shortcut-connected MoE 結構來減少計算量和實現結構上的計算-通信重疊。
- Prefill:傳統大模型推理的預填充(Prefill)環節,主要受計算量和通信量影響,而具體到 MoE 模型的時候,通信量主要受平均選擇的專家數量影響。在 LongCat-Flash 的設計中,我們發現並非每個 Token 都需要同等規模的激活參數。基於這一觀察,我們設計了零專家機制(Zero Computation Experts),採用動態激活機制,針對一些不重要的 Token,採用更少的激活來完成計算,由此將每 Token 激活參數量控制在 186 億至 313 億之間(平均 270 億,激活 8 個 experts),這對於降低預填充計算量至關重要。
- Decode:對於解碼(Decode)階段,MoE 模型的高稀疏性(experts 總數和 per token 激活 experts 數的比值)需要更大的 batch 來提升 GEMM(矩陣乘法)的計算密度。比如,按照 Roofline 模型,H800 上的稠密(Dense)矩陣乘法運算,要達到計算約束(compute bound)區間,需要輸入規模達到 500 以上。但是如果是類似於 DeepSeekV3 這樣的 MoE 模型(256 個 expert,每個 token 激活 8 個 expert),則需要輸入規模達到 500*256/8 = 16000。由於 KV cache 的顯存開銷與輸入規模成正比,所以為了提高輸入的規模,部署上往往採用更大的併發度(也就是大規模專家並行部署),將參數分散到更多的 GPU 卡上,釋放出來更多的顯存給 KV Cache 存儲。但大規模部署時的多機通信會成為新的瓶頸。由此,計算/通信重疊成為提升推理性能的關鍵。DeepSeekV3/SGLang 提出的 TBO(Two Batch Overlap,雙批次重疊)通過不同 Batch 間的通信和計算做重疊降低了延遲,但在小批量或單請求場景下會失效。吞吐(大 Batch)和延遲(小 Batch)本質上是衝突的目標,在線業務往往需要在二者間做折衷。LongCat-Flash 為了解決這一衝突,採用 ScMoE 架構來實現吞吐與延遲的雙重優化。基於這套架構,我們可以採用 SBO(Single Batch Overlap),在小批量請求或者單請求場景依然能夠取得延時收益。此外,ScMoE 的另一優勢在於:Dense 分支的 FFN 上的節點內張量並行通信(通過 NVLink)可完全與節點間專家並行通信(通過 RDMA)重疊,實現 intra-node 通信和 inter-node 通信的 overlap,從而最大化網絡利用率。
模型-系統的協同設計使得我們可以突破吞吐和延時這一對衝突目標的限制,同時在兩個維度上取得顯著收益。
3. 我們的解決方案:SGLang + PD 分離 + SBO 調度 + 大規模 EP 部署
3.1 PD 分離
為實現預填充(Prefilling)與解碼(Decoding)階段的獨立優化,我們採用了 PD 分離(PD-Disaggregated)架構。基於 SGLang 的 PD 分離方案,我們開發了自己的創新解決方案,其核心特性是分層傳輸(Layer-wise Transmission),該設計在高 QPS 負載場景下顯著降低了首包時間(TTFT)。
3.2 SBO
SBO(Single Batch Overlap)是一種採用模塊級重疊(Module-Level)的四階段流水線執行架構,旨在充分釋放 LongCat-Flash 的性能潛力。與 TBO 不同的是,SBO 通過將通信開銷隱藏於單個批次內實現優化:
- 階段 1:獨立執行,因為多頭潛在注意力(MLA)的輸出是後續階段的輸入基礎。
- 階段 2:all-to-all 分發與密集 FFN 和 Attn 0(QKV 投影)並行執行。這種重疊至關重要,由於通信開銷過大,我們專門將注意力計算過程進行了拆分。
- 階段 3:獨立執行 MoE GEMM。該階段延遲將受益於寬專家並行(EP)的部署策略。
- 階段 4:Attn 1(核心注意力+輸出投影)和密集 FFN 與 all-to-all 合併操作重疊執行。
這種設計有效緩解了通信瓶頸:① 所有重疊操作在單批次內完成,實現吞吐量提升與延遲降低的雙重收益;② 通過計算/通信流水化,確保 LongCat-Flash 的高效推理。其核心價值在於突破傳統方案中吞吐量與延遲不可兼得的困境,特別適合實時性要求高的智能體應用場景。

3.3 大規模專家並行部署
為什麼要做大規模專家並行部署?一是因為前文所述,需要釋放更多顯存來給 KV cache 存儲;二是因為增大 EP 併發數,可以降低 MoE 環節的計算耗時。
- 降低 KV Cache:LongCat-Flash 採用了 MLA 結構來壓縮 KV Cache,單 Token 的 KV Cache 大小是:(512+64)*2*28*2 = 64.5KB。假設輸入的長度是 5K,則平均每條請求的 KV Cache 大小是:64.5KB * 5000 = 323MB,MoE 部分的參數大小是:541GB(FP8 存儲)。如果 H800-80GB 做 EP16 部署,則單卡的 MoE 參數是:33.8GB,參數佔了單卡存儲的 42.2%,考慮到 CudaGraph 的顯存開銷、通信的 buffer 開銷、Dense 分支的參數開銷,留給 KV Cache 的空間就不大,batch 就沒法打高。如果做 EP128 部署,則單卡的 MoE 參數是:541/128 = 4.2GB,只佔單卡顯存的 5.3%,更多的空間可以釋放給 KV cache。也可以看出來,在 EP128 基礎上,進一步增加 EP 數,顯存方面的收益已經不顯著了。
- 降低 MoE 環節的計算耗時:如技術報告和圖 2 所指出,在 SBO 中,單個 layer 的計算耗時由四個環節組成:attention 計算 + all-to-all dispatch 通信 + MoE 計算 + all-to-all combine 通信。其中 attention 計算和 all-to-all dispatch/combine 通信都無法通過增加分佈式節點來降低,只有 MoE 計算可以。所以,在達到 MoE 計算的算力瓶頸之前,擴大 EP 規模會減少 MoE 計算時間。
大規模專家並行部署,結合 SBO 調度,LongCat-Flash 在 EP128 的時候可以達到~10ms 的 TPOT,同時單卡~800 tokens/s 的吞吐。此外,與 SGLang 的實現類似,我們採用 DeepEP 實現大規模專家的分佈式通信,也在 DeepEP 基礎上實現了零專家無需通信的本地計算機制,顯著降低了通信開銷。
3.4 其他優化
- 多步重疊調度器:為提升 GPU 利用率,SGLang 採用單步重疊式調度器,將 CPU 的調度開銷隱藏在模型 Decode 的 GPU kernel 耗時中。然而,LongCat-Flash 前向傳播的耗時比較低,導致 GPU kernel 的耗時無法掩蓋 CPU 的調度開銷,為此我們實現多步重疊調度器,在單次調度迭代中啓動多個前向傳播 kernel,通過將 CPU 調度與同步操作隱藏於 GPU 計算過程,確保 GPU 一直處於 busy 狀態。

4. 性能表現
基於以上優化,LongCat-Flash 可以取得比同尺寸模型、甚至更小尺寸模型都顯著優異的性能表現,以公版 H800 每小時 14 元人民幣(2 美元)計算,在輸出速度達到 100 tokens/s(TPOT = 10ms)的 SLO 下,輸出成本價僅為每百萬 Token 5 元。
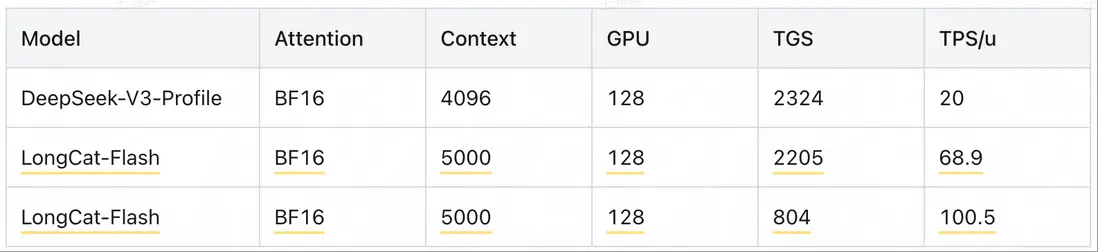
備註:不同的 SLO 有不同的成本。比如 68.9 tok/s 的生成速度,對應的吞吐是 2205 token/g/s;100.5 tok/s 的生成速度,對應的吞吐是 804 token/g/s。
5. 使用 SGLang 部署的方法
我們推薦使用 SGLang 部署 LongCat-Flash。通過與 SGLang 社區的深度協作,該模型在 SGLang 框架上實現首發即兼容。由於其 5600 億參數(560B)的規模,LongCat-Flash 在 FP8 格式下需要至少單節點 8xH20-141G GPU 來加載模型權重,BF16 權重則需要至少雙節點 16xH800-80G GPU。具體啓動配置如下所示。
安裝 SGLang
pip install --upgrade pip
pip install uv
uv pip install "sglang[all]>=0.5.1.post3"單機部署(8xH20-141G)
該模型可通過張量並行(Tensor Parallelism)與專家並行(Expert Parallelism)的組合方案在單節點上部署。
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat-FP8 \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 8多機部署(16xH800-80G)
在多節點部署方案中,當前採用張量並行(Tensor Parallelism)與專家並行(Expert Parallelism)的組合架構,未來將擴展其他並行策略。請將$NODE_RANK和$MASTER_IP替換為實際集羣環境對應的配置值。
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 16 \
--nnodes 2 \
--node-rank $NODE_RANK \
--dist-init-addr $MASTER_IP:5000使用 MTP 的方法
要啓用 SGLang 的多令牌預測(MTP)功能,需在啓動命令中添加以下參數
--speculative-draft-model-path meituan-longcat/LongCat-Flash-Chat \
--speculative-algorithm NEXTN \
--speculative-num-draft-tokens 2 \
--speculative-num-steps 1 \
--speculative-eagle-topk 16. 總結
通過結合 SGLang、PD 分離架構、大規模專家並行(EP)和 SBO 等關鍵技術,我們實現了 LongCat-Flash 的超低成本與極速生成能力。該模型的高效推理還得益於 SGLang 團隊、MoonCake 團隊、NVIDIA trt-llm 及其他開源社區的技術貢獻。未來我們將與 SGLang 團隊深度合作,逐步將基於 SGLang 的優化方案回饋至開源社區,共同推動生態發展。
註釋
[1] MagicDec:Sadhukhan, Ranajoy, et al. "Magicdec: Breaking the latency-throughput tradeoff for long context generation with speculative decoding." arXiv preprint arXiv: 2408.11049 (2024).
[2] C2T:Huo, Feiye, et al. "C2T: A Classifier-Based Tree Construction Method in Speculative Decoding." arXiv preprint arXiv: 2502.13652 (2025).
閲讀更多
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。