

語音大語言模型(Speech LLM)想落地,繞不開一個死結:既要快速理解語音裏的語義,又要説出自然的音色,還得實時響應。比如智能音箱 “聽不懂” 語音,車載助手 “説” 得像機器人,實時翻譯延遲卡半秒 ——深究根源,全在 “語音 Token 化”:作為拆分語音為 Speech LLM “離散單元” 的關鍵步驟,傳統方案始終沒平衡好 —— 要麼缺語義、要麼丟聲學、要麼延遲高,剛好卡了 Speech LLM 落地的 “死結”。
針對 Speech LLM 落地中的音頻處理難題,美團 LongCat 團隊正式開源專用語音編解碼方案 LongCat-Audio-Codec。它提供了一套一站式的 Token 生成器(Tokenizer)與 Token 還原器(DeTokenizer)工具鏈,其核心功能是將原始音頻信號映射為語義與聲學並行的 Token 序列,實現高效離散化,再通過解碼模塊重構高質量音頻,為 Speech LLM 提供從信號輸入到輸出的全鏈路音頻處理支持。通過創新的架構設計與訓練策略,LongCat-Audio-Codec 在語義建模、聲學重建、流式合成三大維度實現突破。

一、技術亮點
LongCat-Audio-Codec 的核心競爭力源於三大創新設計。
設計一: 語義 - 聲學雙 Token 並行提取機制:兼顧理解與生成
為解決語義空間干擾聲學空間導致的重構質量不佳的問題,LongCat-Audio-Codec 採用 “級聯訓練 - 並行推理” 的創新設計:
- 語義 Token:首先基於雙向 Transformer 架構,聚焦語音內容的核心信息,基於 CTC 微調後的 ASR 模型提取純粹的語義信息,為 Speech LLM 的語義理解提供支撐;
- 聲學 Token:隨後基於已有語義信息,結合改進的量化技術,在大碼本空間下補充韻律、音色等副語言特徵的聲學 Token,解決非語義信息覆蓋不足的問題。
同時,該方案支持聲學碼本的動態配置,可以在保證語義能力一致的情況下,根據下游任務調整碼本層數。如下游任務是少音色場景,則可以選擇單個聲學碼本來減少 Speech LLM 的學習壓力;如果下游任務是多音色場景,則可以選擇全部聲學碼本來提供豐富的説話人支持。
設計二: 低延遲流式解碼器:兼顧實時與質量
低延時流式處理能力是 Speech LLM 實時交互場景(如車載語音助手、實時翻譯)的核心需求,其關鍵指標為端到端延遲(End-to-End Latency)。傳統解碼架構沒有專為流式場景設計,易導致實時交互延遲高(如實時翻譯卡半秒),LongCat-Audio-Codec 通過低延遲流式解碼器解決這一問題。其解碼器採用幀級增量處理模式,通過控制對未來語音 Token 的依賴,將解碼延遲控制在百毫秒級。該架構顯著提升了 Speech LLM 的交互實時性,滿足工業級實時響應標準。
設計三:超低比特率高保真與集成超分辨率設計:兼顧壓縮效率與音質
為解決 “低比特率音質劣化”和“超分辨率需額外模型” 問題,LongCat-Audio-Codec 採用協同優化設計:
- 超低比特率:比特率是衡量音頻壓縮效率的核心指標,依託模型優化與三階段訓練機制,通過降低信息量,從而在保證 Speech LLM 能夠從海量數據中學習到語音的本質同時,降低 Speech LLM 的訓練難度,也為 Speech LLM 的規模化落地提供了支撐。
- 集成超分辨率:LongCat-Audio-Codec 將超分辨率思想嵌入解碼器,通過神經網絡對重建音頻進行頻域補全。該集成設計不僅進一步提高了核心內容的壓縮率,更通過提升輸出音頻的採樣率,增強了語音的自然度與細節表現力。
二、性能評估
1. 低比特率下的可懂性與音質優勢
在測試中,LongCat-Audio-Codec 在低比特率區間(0.43-0.87kbps)關鍵指標優於同類方案:對比其他攜帶語義的編解碼器,LongCat-Audio-Codec 在各比特率區間均表現最優。
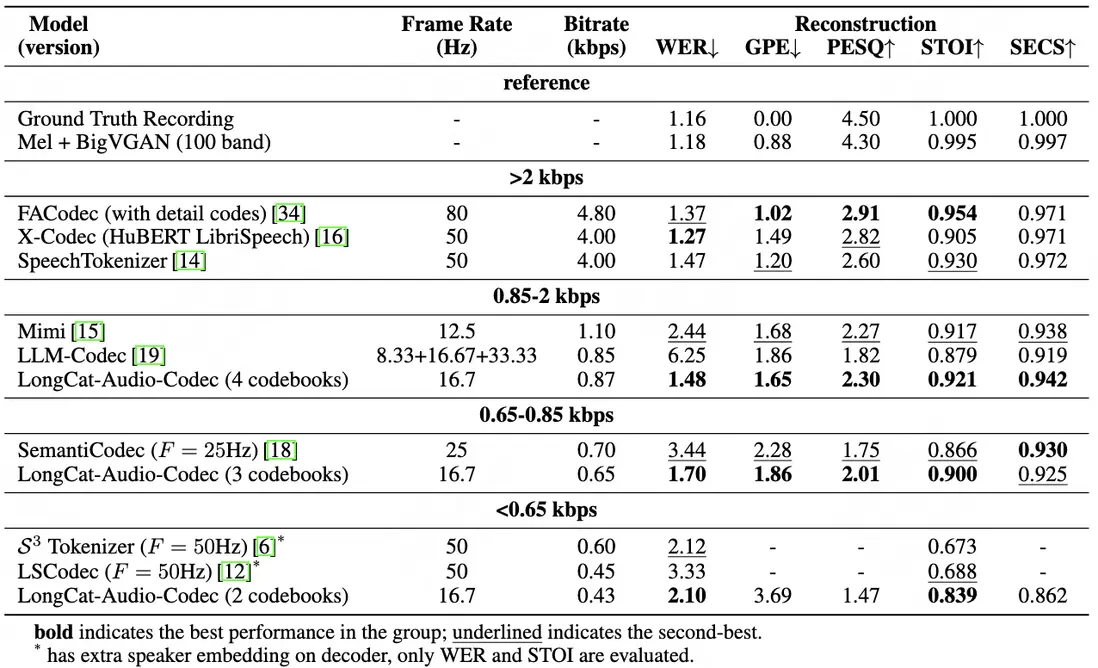
- 0.85-2kbps 區間(4 個碼本,0.87kbps):詞錯誤率(WER,越低表示語音可懂性越高)僅 1.48,語音質量感知評估(PESQ,越高表示主觀音質越好)達 2.30,短時客觀可懂性(STOI,越高表示語音信息保留越完整)達 0.921,説話人相似度(SECS)0.942,兼顧可懂性與音色一致性;
- 0.65-0.85kbps 區間(3 個碼本,0.65kbps):WER 1.70,STOI 0.900,優於同類低比特率方案;
- <0.65kbps 區間(2 個碼本,0.43kbps):WER 2.10,STOI 0.839,在極端低比特率下仍保持高可懂性,適合資源受限場景。
2. 比特率與性能的靈活適配
當前架構支持在保證語義理解能力的情況下靈活調整碼本數量(2-4 個),LongCat-Audio-Codec 可以實現比特率從 0.43kbps 到 0.87kbps 的漸進式優化,且指標同步提升:
- WER 從 2.10 降至 1.48,STOI 從 0.839 升至 0.921,語音可懂度顯著提高;
- 總基音誤差(GPE)從 3.69 降至 1.65,PESQ 從 1.47 升至 2.30,説話人相似度從 0.862 升至 0.942,語音重構相似度進一步提高。
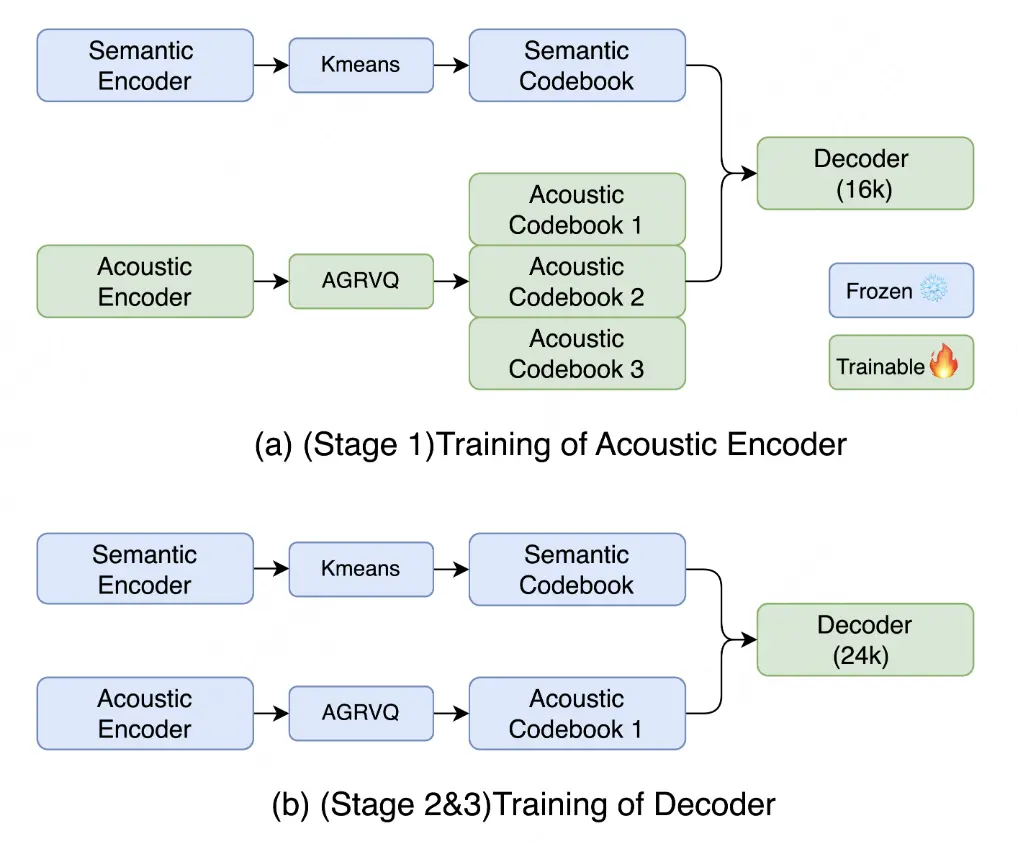
3. 多階段訓練策略適配多樣化場景
LongCat-Audio-Codec 設計了多階段的訓練策略,來兼容壓縮率和音質的需求。其中 Stage1 用於滿足高壓縮率下的重構需求,Stage2 用於滿足高音質合成需求,Stage3 用於滿足個性化定製需求:
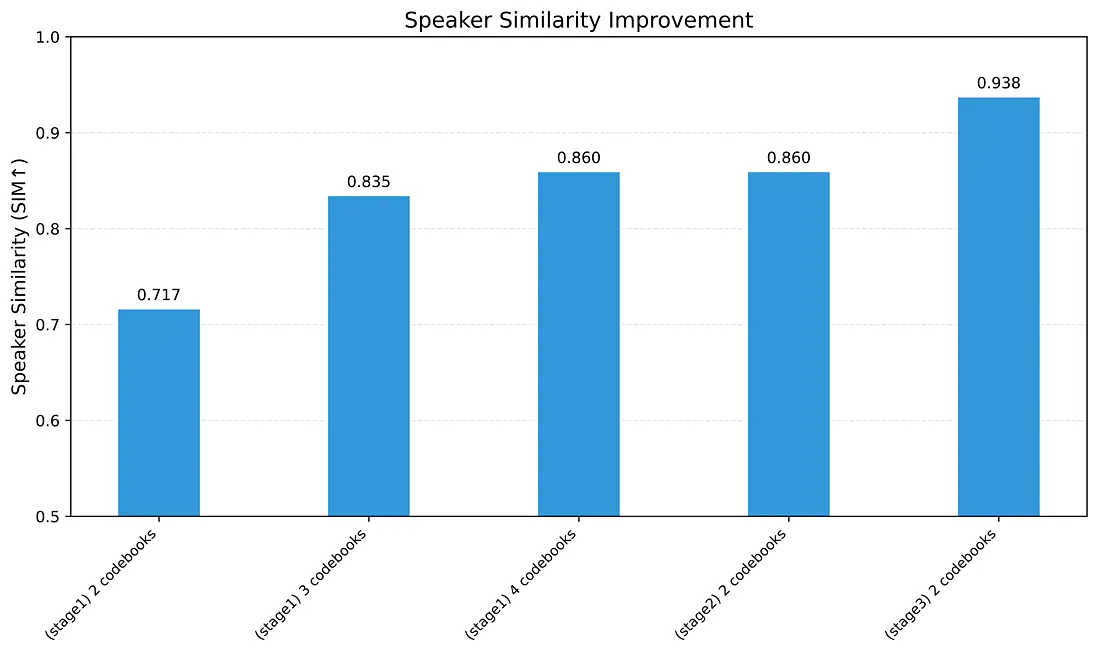
經過 Stage 2 優化後,LongCat-Audio-Codec 在音質上表現突出,無參考音質指標 SIGMOS 3.35,NISQA 4.33,甚至超過 LibriTTS clean 數據集(SIGMOS 3.24、NISQA 4.09)錄音水平:

經過 Stage 3 優化後,有限集説話人相似度(SIM)從 0.717 升至 0.938,證明在當前架構下,使用最低碼率(0.43kbps)下也可滿足説話人定製需求。
三、總結
作為工業級語音大模型(Speech LLM)的專用語音 Token 解決方案,LongCat-Audio-Codec 以三大核心創新打破了語音大模型落地的關鍵瓶頸:通過 “語義 - 聲學雙 Token 並行提取” 破解 “懂卻説不清” 的平衡難題,以 “低延遲流式解碼” 解決 “説得清卻不實時” 的交互痛點,靠 “超低比特率高保真 + 集成超分辨率” 兼顧壓縮效率與音質細節,真正讓語音大模型既 “聽懂” 語義,又能夠“説清” 。
LongCat-Audio-Codec 的開源發佈,給語音大模型領域帶來三重關鍵價值:
- 其一,降低技術門檻 —— 為缺乏專用語音處理模塊的研究團隊提供一站式 Token 生成器(Tokenizer)與 Token 還原器(DeTokenizer)工具鏈,緩解語音大模型領域架構碎片化、上手難度高的問題,開發者可基於開源代碼快速開發自己的語音大模型;
- 其二,豐富應用場景 —— 具備靈活碼本、輕量化、低延遲解碼方案,適用更多的應用場景;
- 其三,完善技術生態 —— 與美團此前發佈的 LongCat 系列模型形成協同,從語音Token處理到語音大模型全鏈路能力,為構建全棧式語音智能系統奠定基礎。
作為開源的語音大模型專用語音編解碼器,LongCat-Audio-Codec 的技術路線不僅為當前語音大模型落地提供了高效適配的解決方案,更給語音 - 語言跨模態研究提供了新的參考範式。未來,LongCat 團隊還將在多語言語音處理、長音頻建模等方向持續優化,期待為行業帶來更多突破,也歡迎更多開發者關注與參與共建。
Github地址:https://github.com/meituan-longcat/LongCat-Audio-Codec
| 關注「美團技術團隊」微信公眾號,在公眾號菜單欄對話框回覆【2024年貨】、【2023年貨】、【2022年貨】、【2021年貨】、【2020年貨】、【2019年貨】、【2018年貨】、【2017年貨】等關鍵詞,可查看美團技術團隊歷年技術文章合集。

| 本文系美團技術團隊出品,著作權歸屬美團。歡迎出於分享和交流等非商業目的轉載或使用本文內容,敬請註明“內容轉載自美團技術團隊”。本文未經許可,不得進行商業性轉載或者使用。任何商用行為,請發送郵件至 tech@meituan.com 申請授權。