

在Java代碼中我們常常會開啓異步線程去執行一些網絡請求,或是開啓子線程去讀寫文件,這些線程的開啓與執行在併發量較小的場景下可以正常運行,如果涉及併發量比較大、線程數量有限、響應速度要快的業務場景下,此時就不允許單獨創建線程去執行任務,而是基於線程池管理、分發線程機制去執行線程任務,從而降低資源消耗、提高響應速度,統一管理線程資源
線程池的創建與分類
Exectors類是concurrent包下的用於快速創建線程的工具類,該類中定義了一系列創建不同線程類型的靜態方法,實際還是調用ThreadPoolExecutor類的有參函數,下面看下對應的方法源碼
--- newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
--- 調用有參函數
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}-
newFixedThreadPool : 固定數量的線程池,可用於限制特定線程啓用數量的場景,調用ThreadPoolExecutor構造函數中的參數定義如下
- corePoolSize : 核心線程數量
- maximumPoolSize : 最大線程數量
- keepAliveTime : 當線程的數量大於核心線程時,空閒線程在終止之前等待新任務的最大時間
- unit : 參數keepAliveTime的時間單位
-
workQueue : 存放等待執行任務的阻塞隊列,常用的組賽隊列如下
- ArrayBlockingQueue : 基於數組的有界阻塞隊列,遵循FIFO(先進先出)原則,構造函數提供設置隊列大小參數,採用ReentrantLock(基於AQS實現)獲取重入鎖,如果向已滿的隊列插入則當前線程阻塞
- LinkedBlockingQueue : 基於鏈表的無界阻塞隊列,默認大小為Integer.MAX_VALUE,向該隊列插入數據時會封裝到Node<>節點所對應的鏈表中,隊列內部使用了putLock和takeLock標識添加、刪除鎖,二者可併發執行
- SynchronousQueue : 單向鏈表同步隊列,具體需查看源碼(知識盲區,未研究到該隊列)
- PriorityBlockingQueue : 具有優先級排序的無界阻塞隊列,默認以自然排序方式或者通過傳入可比較的Comparator比較器進行排序
- threadFactory : 默認線程創建工廠
-
defaultHandler : 拒絕策略,默認使用ThreadPoolExecutor.AbortPolicy,表示當隊列滿了並且工作線程大於線程池最大線程數量,此時直接拋出異常,
- CallerRunsPolicy : 用於被拒絕任務的處理程序,它直接在 execute 方法的調用線程中運行被拒絕的任務;如果執行程序已關閉,則會丟棄該任務
- DiscardOldestPolicy : 丟棄最老的一個請求,也就是即將被執行的一個任務,並嘗試再次提交當前任務
- DiscardPolicy : 默認丟棄被拒絕的任務
一般場景下默認使用ThreadPoolExecutor.AbortPolicy拒絕策略
<br/>
-
newSingleThreadExecutor : 單線程的線程池,只有一個核心線程在執行,可用於需要按照特定順序執行的場景
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }通過入參可以看到只使用一個線程,採用LinkedBlockingQueue無界隊列,keepAliveTime是0s,説明線程創建了不會超時終止,該線程順序執行所有任務
-
newCachedThreadPool : 核心線程為0,非核心線程數為int的最大值
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }keepAliveTime是60s,採用SynchronousQueue同步阻塞隊列,當有新的任務進來此時如果有空閒的線程則重複使用,否則就重新創建一個新的線程,線程空閒60s後會被回收,關於同步阻塞隊列可以看這篇文章SynchronousQueue
-
newScheduledThreadPool : 核心線程為傳入的固定數值,非核心線程數為int的最大值,可用於延時或定時任務的執行
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); } public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS, new DelayedWorkQueue()); }方法參數中的DelayedWorkQueue底層也是基於數組實現的最小堆的具有優先級的隊列,隊列中的任務按照執行時間升序排列,執行時間越靠近當前時間的任務排在最前面,此時也會最先執行該任務
<br/>
線程池內部執行機制
內部執行機制基本按照ThreadPoolExecutor構造函數傳入的參數來處理提交進來的任務
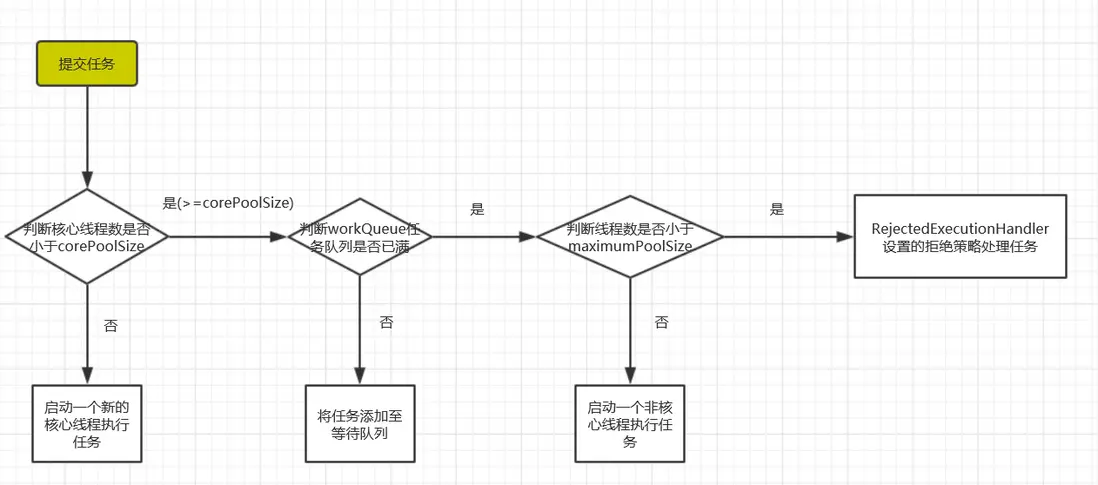
線程池ThreadPoolExecutor中的execute執行方法
先看下execute方法源碼
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}方法中的ctl是ThreadPoolExecutor中申明的提供原子操作的Integer對象,用於獲取當前線程池狀態
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
- 判斷當前線程數量是否小於核心線程數量corePoolSize,如果滿足條件調用addWorker()方法創建一個新的核心線程
- 如果大於corePoolSize,接着判斷當前線程池是否是運行狀態並且通過workQueue.offer()寫入阻塞隊列
- 此時再次檢查線程池狀態是否正在運行,否則從隊列中移除任務並執行拒絕策略;如果是運行狀態,調用workerCountOf()判斷當前線程池線程數,數量為0就新創建一個新的線程
- 如果首次判斷線程池狀態非運行狀態,調用addWorker()創建心線程如果失敗,執行拒絕策略
<br/>
ThreadPoolExecutor中提供了shutdown()、shutdownNow()方法用於關閉線程池,調用shutdown時不再接受新的任務,之前提交的任務等執行結束再關閉線程池,調用shutdownNow時會嘗試停止線程池中的任務然後再關閉,並且返回未處理完的List<> tasks任務列表
ForkJoinPool初探
ThreadPoolExecutor阻塞隊列中的任務都是單個線程去執行,如果此時需要進行密集型計算任務(比如大數組排序、遍歷系統文件夾並計算文件數量),就可能出現線程池中一個線程繁忙而其他線程空閒,導致CPU負載不均衡系統資源浪費,ForkJoinPool就是用於將單個密集型計算任務拆分成多個小任務,通過fork讓線程池其它線程來執行小任務,通過join合併線程執行任務結果,採用並行執行機制,提高CPU的使用率
ForkJoinPool構造函數
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler,boolean asyncMode) {
this(checkParallelism(parallelism),checkFactory(factory),handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}構造函數參數定義如下
- parallelism : 並行線程數,默認為Runtime.getRuntime().availableProcessors(),最小為1
- factory : 線程創建工廠,對象類型為ForkJoinWorkerThread
- handler : 線程執行時異常處理
- asyncMode : 為true表示處理任務的線程以隊列形式按照先進先出(FIFO)順序,此時不支持任務合併,false則是按照棧的形式後進先出(LIFO)順序,默認是false支持任務合併(join)
獲取ForkJoinPool對象可以直接使用commonPool()方法,
val pool = ForkJoinPool.commonPool()
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}而common對應的初始化放在靜態代碼塊中,且最終調用了ForkJoinPool的構造函數
static{
//...
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction<ForkJoinPool>() {
public ForkJoinPool run() { return makeCommonPool(); }});
//...
}
private static ForkJoinPool makeCommonPool() {
//...
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
}ForkJoinTask任務
ForkJoinTask抽象類實現了Future接口,同時提供了RecursiveAction和RecursiveTask兩個實現類,該實現類提供泛型類型申明,源碼如下
public abstract class RecursiveTask<V> extends ForkJoinTask<V> {
V result; //返回結果
protected abstract V compute(); //執行任務
public final V getRawResult() { //獲取result
return result;
}
protected final boolean exec() { //ForkJoinTask中的抽象方法
result = compute();
return true;
}
}RecursiveAction相對應RecursiveTask返回值為void,下面看下ForkJoinTask的三個核心方法
- fork : 在任務執行過程中將大任務拆分為多個小的子任務
- join : 調用子任務的join()方法等待任務返回結果,如果子任務執行異常,join()會拋出異常,quietlyJoin()方法不會拋出異常,需要調用getException()或getRawResult()手動處理異常和結果
- invoke : 在當前線程同步執行該任務,同join一樣,如果子任務執行異常,invoke()會拋出異常,quietlyInvoke()方法不會拋出異常,需要調用getException()或getRawResult()手動處理異常和結果
執行ForkJoinTask任務
使用ForkJoinPool時,可以通過以下三個方法執行ForkJoinTask任務,
public <T> T invoke(ForkJoinTask<T> task)
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
public void execute(ForkJoinTask<?> task)- invoke : 執行有返回值的任務,同步阻塞方法直到任務執行完畢
- submit : 執行沒有返回值的任務
- execute : 執行帶有ForkJoinTask對象返回的任務,非阻塞方法,調用後ForkJoinPool會立即執行並返回當前執行的task對象
invoke()、submit()是對ExecutorService接口的方法實現,同時ForkJoinPool 也定義了用來執行ForkJoinTask的execute方法
work-stealing模式
關於work-stealing模式描述可參見下面這篇博文,核心就是每個工作線程都有自己的任務隊列,當某個線程完成任務後會去"拿"別的隊列裏的任務去執行,work-stealing模式
ForkJoinPool 與 ThreadPoolExecutor 比較
ThreadPoolExecutor 與 ForkJoinPool 都實現了ExecutorService,不同之處在於前者只能執行 Runnable 和 Callable 任務,執行順序是按照其在阻塞隊列中的順序來執行;後者除了能執行前者的任務類型外還擴展處ForkJoinTask類型任務,從而滿足work-stealing這種算法模式,ForkJoinPool涉及的技術點還有很多,需要繼續深入探索,例如ForkJoinPool中的線程狀態、fork()、compute()、join()的調用順序、子任務拆分粒度等細節內容...


