

(一)前言

在當今數據驅動的時代,小紅書作為中國領先的社交電商平台,積累了大量的用户生成內容,這些數據對於市場分析和內容創作具有重要價值。為了合法合規地利用這些數據,我開發了一款名為“爬小紅書圖片軟件”的工具,它不僅能夠抓取紅薯圖片,還能採集筆記和評論數據,助力企業和創作者深入瞭解用户喜好和趨勢。
小紅書是一個高活躍度的社區平台,用户在這裏分享購物經驗、生活方式和產品評價。通過這款軟件,我們可以在尊重用户隱私和遵守平台規則的前提下,對小紅書的筆記、評論和圖片數據進行高效採集和分析。這有助於企業洞察市場動態,創作者優化內容策略。
(二)軟件功能概覽
多系統支持:軟件支持Windows和Mac操作系統。 配置簡便:用户需要在配置文件中輸入小紅書的cookie值,以確保長期穩定使用。 搜索和篩選:支持關鍵詞搜索,可選擇筆記類型(綜合、圖文、視頻)和排序方式(綜合、最新、最熱)。數據下載:可選擇是否下載圖片和採集評論,評論採集不包括二級評論。 數據保存:爬取的數據會自動保存為csv格式,每爬取一條數據即保存一次,防止數據丟失。 日誌記錄:軟件運行過程中會詳細記錄日誌,方便追蹤和解決問題。
軟件界面:(目前已升級至v3.3版本)
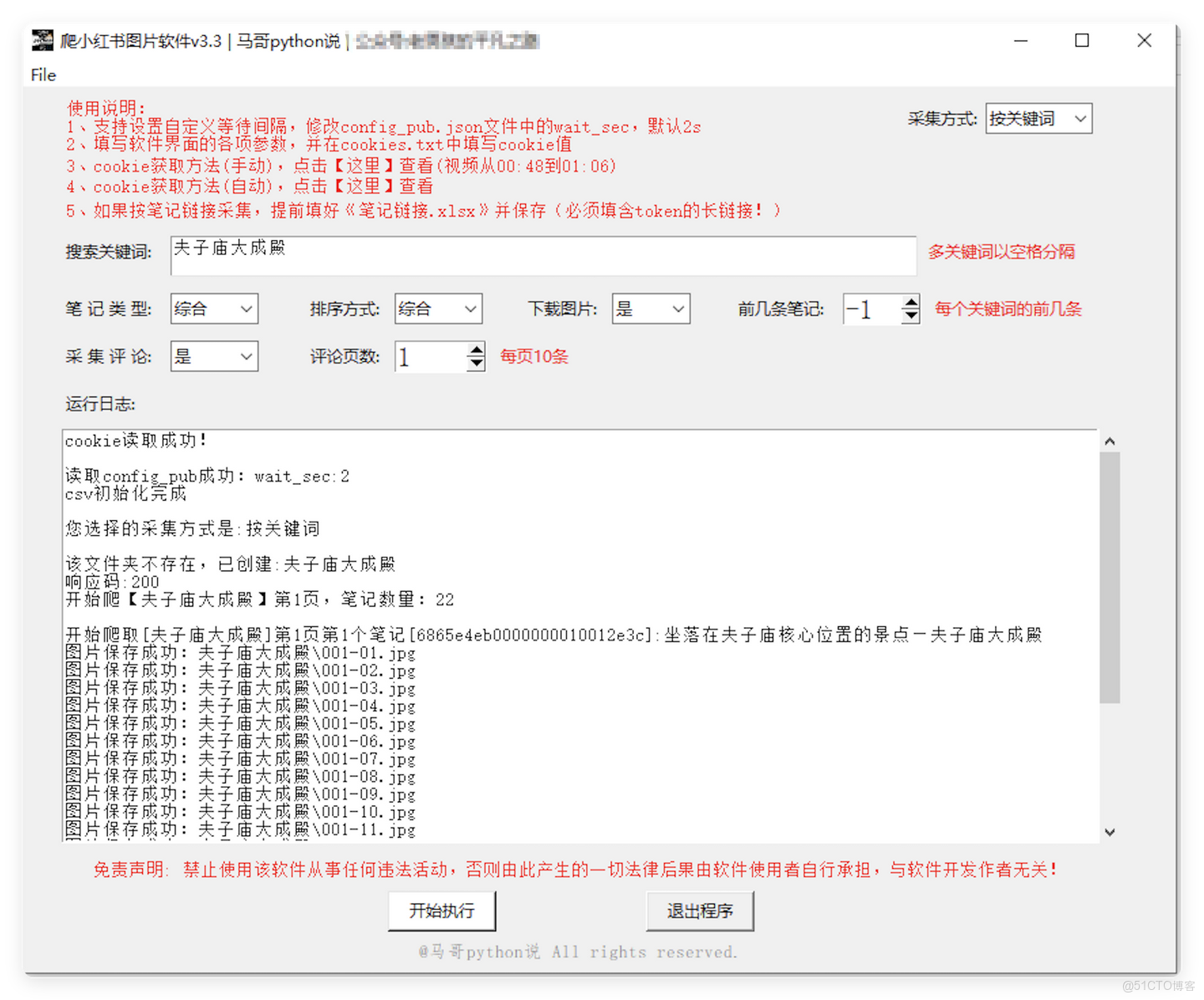
(三)數據導出和圖片保存
數據導出: 軟件運行過程中,會自動將爬取的數據保存為以時間戳命名的csv文件,方便用户查找和管理。軟件運行結果保存為csv文件,包含關鍵詞、序號、筆記ID、筆記鏈接、筆記標題、發佈時間、點贊數等20多個關鍵字段。

圖片保存: 圖片按照爬取順序保存,文件名與csv文件中的序號一一對應。所有圖片保存在以關鍵詞命名的文件夾中,便於管理和查找對應筆記的圖片。

(四)代碼實現
爬蟲模塊: 由於代碼複雜且涉及知識產權保護,爬蟲核心代碼未在文檔中展示。
# 發送請求
r = requests.get(url, headers=h1, params=params)
# 接收響應數據
json_data = r.json()
界面模塊: 使用Python的Tkinter庫創建用户界面,提供直觀的操作體驗。 界面部分:
# 創建主窗口
root = tk.Tk()
root.title('爬小紅書圖片軟件v1.0 | 馬哥python説')
# 設置窗口大小
root.minsize(width=850, height=650)
按鈕控件:
# 搜索關鍵詞
tk.Label(root, justify='left', text='搜索關鍵詞:').place(x=30, y=100)
entry_kw = tk.Text(root, bg='#ffffff', width=78, height=2, )
entry_kw.place(x=110, y=100, anchor='nw') # 擺放位置
tk.Label(root, justify='left', text='多關鍵詞以空格分隔', fg='red').place(x=665, y=100)
日誌模塊: 日誌功能詳細記錄軟件運行過程,幫助快速定位和修復問題。
日誌部分:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日誌格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日誌級別
self.logger.setLevel(logging.DEBUG)
# 控制枱日誌
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日誌文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 將其保存到特定目錄
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
(五)軟件演示
為了幫助用户更好地理解和使用這款軟件,提供了操作演示視頻,詳細展示了軟件的使用方法和功能,請見原文。
(六)作者聲明
本工具為原創開發,如需瞭解更多技術細節或進行專業交流,可通過正規渠道聯繫開發者(公眾號:老男孩的平凡之路)。工具使用需嚴格遵守相關法律法規和平台規定。