

對齊規則太 “苛刻”,PostgreSQL表變大的 3 個核心原因
相同的表結構和數據,在商業數據庫中存儲緊湊,到了PostgreSQL裏卻會明顯變大? 為什麼有些數據庫管理員(DBA)在將Oracle、SQL Server和DB2等商業數據庫遷移到PostgreSQL後表佔用的磁盤空間增加20%-40%?
本文將通過實際示例説明“對齊”與“填充”是如何造成這種差異的。
商業數據庫中的行存儲機制
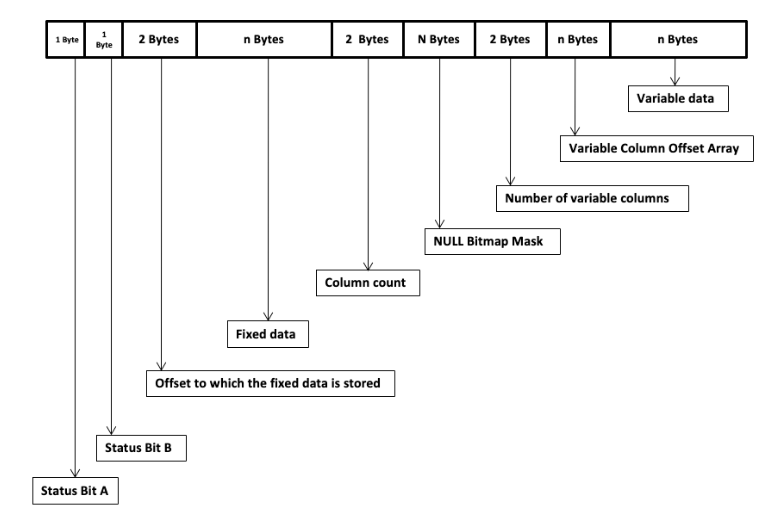
SQL Server作為商業數據庫,會將行數據存儲在8KB大小的頁(page)中,每一行的結構包含三部分:
- 一個小型行頭部(4字節,外加一個空值位圖);
- 按定義順序排列的所有固定長度列;
- 通過“偏移數組”(offset array)管理的可變長度列。
注意:SQL Server不對固定長度類型強制執行對齊規則。這意味着你可以在表中先定義一個BIT列、再定義一個BIGINT列、最後再定義一個BIT列,SQL Server會將這些字節緊密排列,不會產生空間浪費。
通過實際代碼來看具體效果:
-- SQL Server 代碼
CREATETABLE T_BadOrder
(
a BIT, -- 佔用1字節
b BIGINT, -- 佔用8字節
c BIT -- 佔用1字節
);
INSERTINTO T_BadOrder VALUES (1, 42, 0);
-- 計算數據佔用(payload)大小:結果為10字節
SELECTDATALENGTH(a) + DATALENGTH(b) + DATALENGTH(c) AS payload_bytes
FROM T_BadOrder;
-- 查看物理行的平均大小:結果為16字節(4字節行頭部 + 10字節數據載荷 + 2字節空值位圖掩碼的字段計數)
SELECT avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('T_BadOrder'), -1, NULL, 'DETAILED')
WHERE alloc_unit_type_desc = 'IN_ROW_DATA';可以看到,數據佔用總計10字節,加上行頭部和空值位圖後,總大小為16字節。這裏的重點是:字段a和字段b之間沒有插入任何填充字節。
PostgreSQL中的行存儲機制
PostgreSQL作為開源數據庫,表中的每一行的結構如下:
- 一個元組頭部(tuple header,固定23字節),包含MVCC(多版本併發控制)所需的元數據(如事務ID、可見性標記等);
- 一個空值位圖;(記錄哪些字段是空值,每字段佔 1 位,不足 1 字節則補滿 1 字節,表如果有8個字段就佔用1 字節)。
- 按定義順序排列的字段值。
與商業數據庫最大的不同是:PostgreSQL會強制要求數據類型對齊,具體規則如下:
- BOOLEAN類型需要1字節對齊;
- SMALLINT類型需要2字節對齊;
- INT類型需要4字節對齊;
- BIGINT、double precision(雙精度浮點數)、timestamp(時間戳)類型需要8字節對齊。
如果某一字段的起始位置不符合對應的對齊要求,PostgreSQL會自動插入“填充字節”(padding bytes),將該字段“推”到正確的對齊邊界上。我們用跟前文相同的表結構來測試:
-- PostgreSQL 代碼
CREATE TABLE t_bad
(
a boolean, -- 1字節(後續需補7字節填充)
b bigint, -- 8字節(需8字節對齊,因此前一列要補填充)
c boolean -- 1字節
);
INSERT INTO t_bad VALUES (true, 42, false);
-- 查看實際行大小:結果為41字節
SELECT pg_column_size(t) AS row_bytes
FROM t_bad t;在這個例子中,元組頭部(23 字節)+ 空值位圖(1 字節)= 前 24 字節,PostgreSQL先為字段a分配1字節,然後插入7字節填充,這樣字段b才能從8字節對齊邊界開始存儲;字段b之後是1字節的字段c。僅數據佔用的大小就已經超過了SQL Server,還沒算上PostgreSQL本身更大的元組頭部。
但如果我們根據“填充需求”調整字段的順序,存儲佔用會顯著減少:
-- PostgreSQL 代碼
CREATE TABLE t_good
(
b bigint, -- 8字節
a boolean, -- 1字節(無需填充!)
c boolean -- 1字節
);
INSERT INTO t_good VALUES (42, true, false);
-- 查看實際行大小:結果為34字節(減少了7字節,因為無需為任何列插入填充)
SELECT pg_column_size(t) AS row_bytes
FROM t_good t;調整後,行大小從41字節降至34字節,核心原因就是字段a不再需要填充字節,因為字段b(8字節)結束後,剛好滿足字段a(1字節)的對齊要求。
關鍵原則:字段的順序應從“佔用空間最大”到“佔用空間最小”排列!
8字節對齊規則:bigint類型(8字節)要求其起始位置必須是8的倍數(比如8、16、24、32...)。這是硬件層面的優化。
具體位置計算
我們按字段的定義順序(a → b → c)逐步計算每個字段的“起始位置”:
-
字段a(boolean)的位置:
前24字節是頭部和空值位圖,所以列a從第24字節開始存儲。
boolean佔1字節,因此字段a佔用第24字節,結束在第24字節(24→24,共1字節)。 -
字段b(bigint)的位置:
字段a結束後,下一個可用的起始位置是第25字節。
但bigint要求起始位置是8的倍數(8的倍數:8、16、24、32、40...)。 第25字節不是8的倍數(25÷8=3.125,餘數1),不符合要求。 因此需要填充字節,直到下一個8的倍數位置。最近的8的倍數是第32字節(8×4=32)。 從第25字節到第32字節,中間有32-25=7字節,這就是需要填充的7字節。所以字段b從第32字節開始,佔用8字節(32→39字節)。 -
字段c(boolean)的位置:
字段b結束在第39字節,下一個位置是第40字節。
boolean只需要1字節對齊(任何位置都可以),因此直接從第40字節開始,佔用1字節(40→40字節)。
總大小驗證
整個行的總大小=頭部(23)+ 空值位圖(1)+ 字段a(1)+ 填充(7)+ 字段b(8)+ 字段c(1)= 23+1+1+7+8+1=41字節。
調整順序後不需要填充
如果把bigint(b)放在第一個字段,情況就變了:
- 字段b從第24字節開始(頭部23+空值位圖1=24),24是8的倍數(24÷8=3),符合
bigint的對齊要求,無需填充。 - 字段b佔用24→31字節(8字節),之後字段a(boolean)從32字節開始(1字節對齊,無需填充),字段c從33字節開始,總大小減少7字節。
可變長度字段的影響
當表中包含可變長度字段時,情況更有意思。兩者的處理差異如下:
- 在SQL Server中,可變長度數據通過行末尾的“偏移數組”管理;
- 在PostgreSQL中,每一個可變長度值(如TEXT、VARCHAR、BYTEA、NUMERIC等)都自帶一個4字節的“變長頭部”(varlena header)。
我們通過下面兩個表的表結構對比來看看實際影響:
-- PostgreSQL 代碼:列順序不合理的表
CREATETABLE bad_order
(
a boolean,
b bigint,
c int,
d timestamp,
e smallint,
f varchar(20),
g numeric(18,2)
);
-- PostgreSQL 代碼:列順序合理的表
CREATETABLE good_order
(
b bigint,
d timestamp,
c int,
e smallint,
a boolean,
g numeric(18,2),
f varchar(20)
);
-- 插入100萬條測試數據
INSERTINTO bad_order (a,b,c,d,e,f,g)
SELECT
(i % 2 = 0), -- 布爾值:true/false交替
(random()*1e9)::bigint, -- 隨機大整數
(random()*1e5)::int, -- 隨機整數
to_timestamp(1420070400 + (random()*1e6)::int), -- 隨機時間戳
(random()*32000)::int::smallint, -- 隨機小整數
substr(md5(random()::text), 1, (random()*20)::int), -- 隨機長度字符串(1-20字符)
((random()*1e7)::bigint)::numeric / 100.0-- 隨機數值(保留2位小數)
FROM generate_series(1,1000000) i; -- 生成1-1000000的序列作為循環變量
-- 將bad_order的數據按合理列順序插入good_order
INSERTINTO good_order
SELECT b,d,c,e,a,g,f FROM bad_order;
-- 對比兩張表的平均行大小
SELECT'bad_order'AS tbl, avg(pg_column_size(t)) AS avg_row_bytes FROM bad_order t
UNIONALL
SELECT'good_order', avg(pg_column_size(t)) FROM good_order t;實際測試結果顯示:bad_order因列順序不合理和對齊問題,平均每行佔用77字節;而good_order將“寬字節固定長度字段”放在前面、“可變長度字段”放在最後,最大限度減少了填充,平均每行僅佔用66字節。
為什麼PostgreSQL的行存儲通常更大?
遷移後PostgreSQL行大小超過商業數據庫,主要源於三個核心差異:
- 元組頭部大小:PostgreSQL的行頭部包含約23字節的MVCC元數據,而SQL Server僅為4字節;
- 對齊填充:PostgreSQL會插入填充字節以保證固定長度類型的對齊,而商業數據庫則不會;
- 可變長度字段開銷:PostgreSQL中每個可變長度字段都自帶4字節的變長頭部,商業數據庫則無此開銷。
PostgreSQL優化存儲空間的核心邏輯包括下面幾個方面:
- 先放“寬字節固定長度列”(如BIGINT、timestamp);
- 再放“中等字節固定長度列”(如INT);
- 接着放“小字節固定長度列”(如SMALLINT、BOOLEAN);
- 最後放“可變長度列”(如VARCHAR、TEXT、NUMERIC)。
總結
從商業數據庫遷移到開源數據庫PostgreSQL後表體積變大是為了支撐PostgreSQL的核心特性(MVCC)和跨架構的性能穩定性。這也意味着,我們不能期望商業數據庫和開源數據庫兩者的存儲大小完完全全“一一對應”,而且開源數據庫跟商業數據庫相比起來還是有一定的差距。

本文版權歸作者所有,未經作者同意不得轉載。