
調整和管理自定義 Handler
在 KServe 中,自定義 Handler 的概念通常體現在 Transformer 組件上。Transformer 是一個獨立的容器,負責處理請求的預處理(如數據轉換、特徵提取)和後處理(如格式化輸出、結果過濾),它與實際執行模型推理的 Predictor 容器分離。
- 關注點分離:模型推理和數據處理邏輯解耦。
- 靈活性:可以獨立更新
Transformer或Predictor。 - 可重用性:同一個
Transformer可以被多個模型服務複用。
調整自定義 Handler(即 Transformer)的流程如下:
核心概念:KServe Transformer
一個 Transformer 本質上是一個 HTTP 服務,它接收原始請求,進行處理後,將處理後的數據發送給 Predictor,然後接收 Predictor 的原始響應,再次處理後返回給客户端。
KServe 提供了一個 kserve.Model 基類,你可以通過繼承它來實現自己的 Transformer。
步驟一:實現自定義 Transformer
和部署模型一樣,你需要將這個 Transformer 代碼打包成一個 Docker 鏡像。
Dockerfile.transformer:
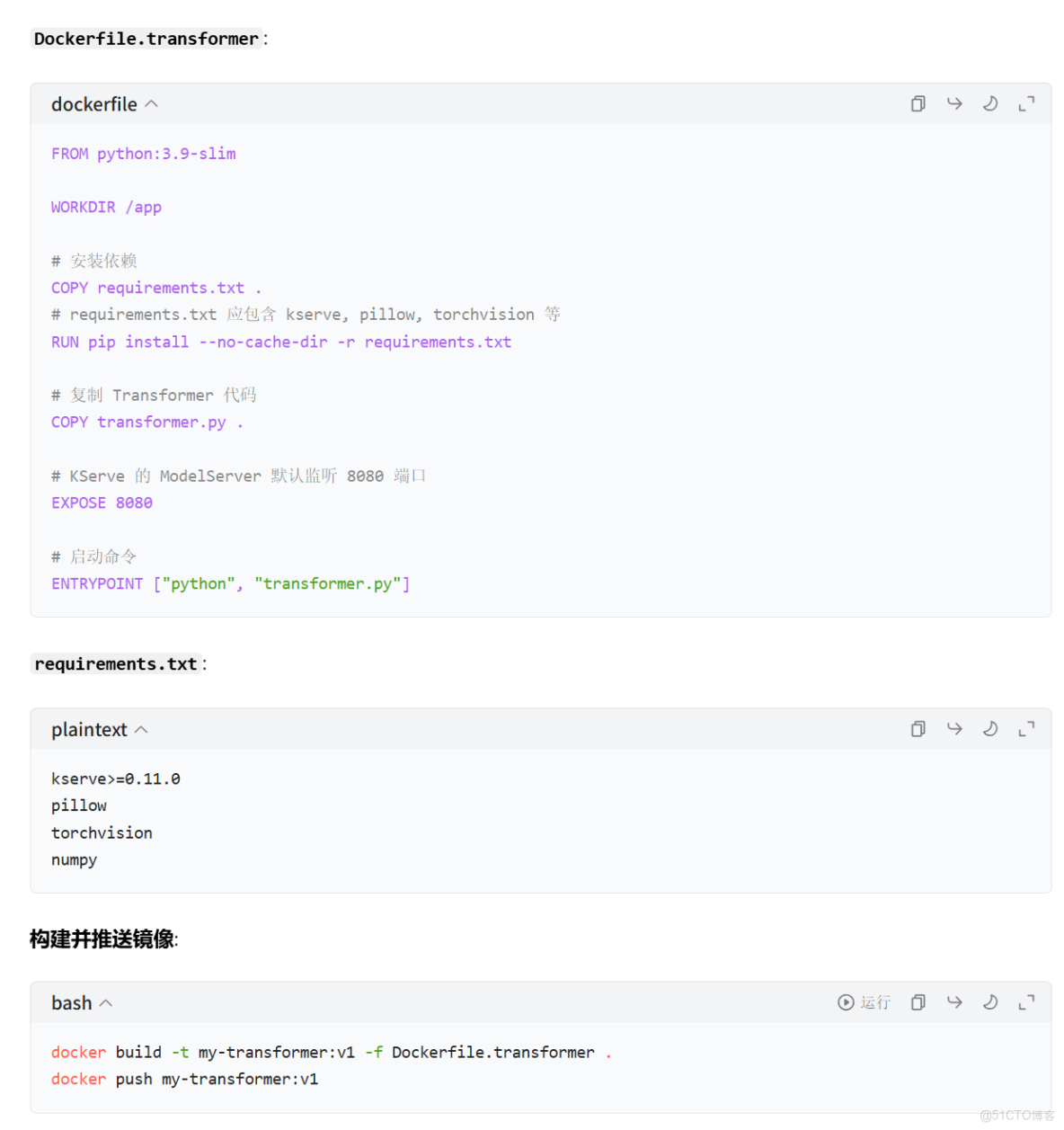
步驟三:在 KServe InferenceService 中配置 Transformer
現在,你需要更新你的 InferenceService YAML 文件,將這個 Transformer 配置進去。
inference_service.yaml:
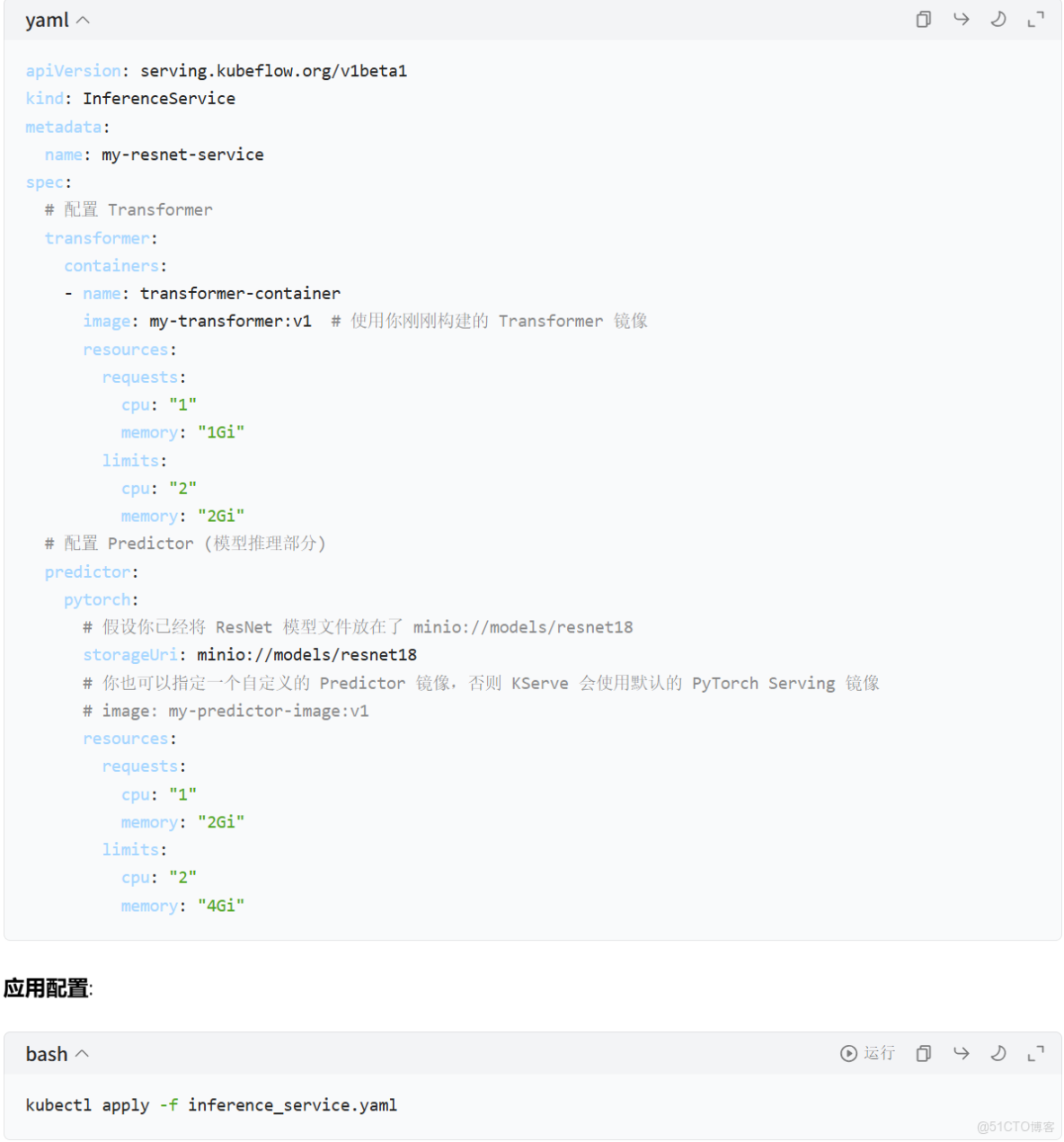
如何調整和更新自定義 Handler (Transformer)
當你需要修改預處理或後處理邏輯時,只需重複以下步驟:
1. 修改代碼:更新 transformer.py 中的 preprocess 或 postprocess 方法。
- 重新構建鏡像:
docker build -t my-transformer:v2 -f Dockerfile.transformer .
docker push my-transformer:v2
3.更新 InferenceService:
◦ 方法 A (推薦):編輯 inference_service.yaml 文件,將 transformer.containers.image 的版本從 v1 改為 v2,然後執行 kubectl apply -f inference_service.yaml。KServe 會自動觸發一個滾動更新,創建新的 transformer Pod 並逐步切換流量。
◦ 方法 B (使用 kubectl edit):
kubectl edit inferenceservice my-resnet-service
在打開的編輯器中找到 transformer 部分,修改 image 字段,保存並退出。
總結
在 Kubeflow (KServe) 中,自定義 Handler 的角色由 Transformer 組件承擔。調整自定義 Handler 意味着:
1. 更新 transformer.py:修改預處理 / 後處理邏輯。
2. 構建新鏡像:將更新後的代碼打包成新的 Docker 鏡像。
3. 滾動更新:修改 InferenceService 的 YAML 配置,指向新的鏡像版本,KServe 會自動完成更新,過程對用户無感知(或僅有短暫的流量切換)。
這種方式充分利用了 Kubernetes 的滾動更新能力,確保了服務的高可用性和零停機部署,是生產環境中管理自定義邏輯的最佳實踐。
在 KServe 中,transformer 和 predictor 是作為兩個獨立的 Deployment 部署的,而不是在同一個 Pod 裏。
1. 整體架構
- 一個
InferenceService自定義資源:作為整個服務的 “控制面板”,定義了期望狀態。 - 兩個
Deployment:
- 一個對應
transformer組件。 - 一個對應
predictor組件。
- 兩個
Service:
- 一個
Service暴露transformerDeployment。 - 一個
Service暴露predictorDeployment。
- 一個 “聚合”
Service:
- KServe 會創建一個與
InferenceService同名的Service,它充當 “入口網關”,將外部流量先路由到transformer,再由transformer轉發到predictor。
2. 工作流程
3. 為什麼這樣設計?
- 獨立擴縮容:
transformer和predictor的計算需求可能不同。例如,predictor可能是 GPU 密集型,而transformer是 CPU 密集型。通過獨立的 Deployment,你可以為它們配置不同的資源和 HPA(Horizontal Pod Autoscaler)策略。 - 獨立更新:你可以單獨更新
transformer或predictor的鏡像,而不會影響另一個組件。這在迭代自定義處理邏輯或模型版本時非常有用。 - 故障隔離:如果
transformer出現問題,predictor仍然可以正常運行(反之亦然),提高了整體服務的可用性。 - 資源優化:可以根據每個組件的實際負載精細調整資源分配,避免浪費。
4. 查看部署的資源
#查看 InferenceService
kubectl get inferenceservices
#查看所有相關的 Deployments
kubectl get deployments
#查看所有相關的 Services
kubectl get services
你會看到類似以下的資源:
my-resnet-service-transformerDeploymentmy-resnet-service-predictorDeploymentmy-resnet-serviceService (入口)my-resnet-service-transformerServicemy-resnet-service-predictorService
總結
transformer和predictor是分開部署的,各自擁有自己的 Deployment 和 Service。- 這種設計提供了更好的靈活性、可擴展性和 fault isolation。
- KServe 通過一個統一的入口 Service 來串聯它們,對客户端屏蔽了內部的複雜性。

