
1. 定義與本質
- 核心目標:解決 “模型訓練出來能用,但上線難、維護難、迭代慢” 的痛點(比如傳統 ML 流程中,數據科學家訓練的模型,運維人員難以部署,且上線後數據漂移、模型性能下降無法及時感知)。
- 與傳統運維的區別:傳統運維聚焦 “軟件 / 系統的穩定運行”,MLOps 聚焦 “模型的穩定運行 + 全流程工程化”,需額外關注數據、模型、實驗迭代的管理。
2. 核心價值(對企業 / 個人)
- 企業側:縮短模型上線週期(從月級→周級 / 日級)、降低模型運維成本、提升模型迭代效率(數據 / 算法變更後快速驗證)。
- 個人側:你的運維技能(K8s、Docker、CI/CD、監控告警)可直接複用,同時補充 ML 知識後,成為 “懂運維 + 懂 ML 工程” 的稀缺人才,職業天花板顯著提升(比如 MLOps 工程師、ML 平台架構師、AI 運維負責人)。
二、MLOps 核心知識體系:從 “運維視角” 切入,少走彎路
MLOps 的知識體系可拆解為 “流程框架 + 核心模塊 + 工具鏈”,建議先掌握流程,再針對性突破模塊和工具,避免孤立學習。
- MLOps 全流程框架(從開發到生產)
數據採集/預處理 → 模型實驗(訓練/調參) → 模型打包/版本管理 → 部署上線(推理服務) → 監控運維 → 迭代優化
- 關鍵特點:全流程自動化、可追溯、可觀測(比如數據變更後自動觸發模型重訓練,模型版本回滾可追溯,上線後性能下降自動告警)。
2. 核心模塊(重點突破,結合運維優勢)
(1)數據管理:MLOps 的 “基石”(運維需理解數據流程,而非深入數據科學)
- 核心需求:數據的 “可獲取、可治理、可複用”,避免因數據問題導致模型失效。
- 關鍵內容:
- 數據採集 / 存儲:瞭解結構化數據(MySQL、PostgreSQL)、非結構化數據(圖片、文本)的存儲方案(如 MinIO、HDFS),以及數據同步工具(Flink、Airflow 用於定時採集)。
- 數據預處理:無需精通算法,但要知道預處理流程(清洗、歸一化、特徵工程)的自動化實現(比如用 Feast 做特徵存儲,避免重複計算特徵)。
- 數據版本控制:核心!需掌握 DVC(Data Version Control)工具,實現數據版本管理(類似 Git 管理代碼),解決 “不同實驗用不同版本數據” 的問題。
(2)模型實驗與版本管理:連接 “實驗” 與 “生產” 的橋樑
- 核心需求:讓模型訓練過程 “可復現、可追溯”,方便數據科學家與運維協作。
- 關鍵內容:
- 實驗跟蹤:掌握 MLflow,用於記錄實驗參數(學習率、batch size)、指標(準確率、loss)、模型文件,支持多實驗對比(比如不同調參結果的可視化對比)。
- 模型版本管理:用 MLflow Model Registry 或 DVC 管理模型版本,明確 “哪個版本的模型對應哪個版本的數據 / 參數”,支持上線版本回滾。
- 調參自動化:瞭解 Hyperopt、Optuna 等工具,實現自動化調參(運維無需精通調參算法,但要會部署調參任務)。
(3)模型部署與 CI/CD:運維的 “核心優勢領域”(重點發力)
- 核心需求:將訓練好的模型快速、穩定地部署為 “推理服務”,並支持自動化迭代。
- 關鍵內容:
- 模型打包:將模型(如 PyTorch、TensorFlow 模型)打包為標準化格式(ONNX、TorchServe、TensorFlow Serving),確保跨環境可運行。
- 部署方式:
- 批量推理:適合離線任務(如每日用户畫像生成),用 Airflow 調度任務,部署在 K8s 集羣。
- 實時推理:適合低延遲場景(如推薦系統),用 K8s 部署推理服務(如用 Kubeflow Pipelines 管理部署流程),支持彈性擴縮容(結合你的 K8s 運維經驗)。
- Serverless 部署:瞭解 AWS Lambda、阿里雲函數計算等,適合流量波動大的場景(減少資源浪費)。
- ML CI/CD 流水線:複用你熟悉的 CI/CD 工具(Jenkins、GitLab CI、GitHub Actions),搭建自動化流水線:
代碼提交(Git)→ 自動測試(模型性能、代碼質量)→ 自動打包(模型+依賴)→ 自動部署(dev/test/prod環境)→ 自動驗證(線上性能檢測)(4)模型監控與運維:MLOps 的 “閉環關鍵”(運維主場)
- 核心需求:實時監控模型與數據狀態,及時發現問題並觸發優化,避免模型 “失效”(比如數據漂移導致預測準確率下降)。
- 關鍵監控指標(重點掌握):
- 數據監控:輸入數據分佈漂移(如用户年齡分佈突然變化)、數據質量(缺失值、異常值比例)。
- 模型監控:預測準確率、召回率等性能指標;推理延遲、吞吐量(服務可用性指標);預測分佈漂移(如分類模型預測結果集中在某一類)。
- 工具與實踐:
- 監控工具:Prometheus + Grafana(複用你的運維監控經驗)監控服務指標;Evidently AI、Alibi Detect 專門用於數據 / 模型漂移檢測。
- 告警與閉環:設置閾值(如準確率下降 10% 觸發告警),通過郵件 / 釘釘 / 企業微信推送;結合 CI/CD 實現 “告警→自動重訓練→自動部署新模型” 的閉環。
(5)ML 平台搭建:進階方向(體現組長的架構設計能力)
- 核心目標:搭建一站式 ML 平台,讓數據科學家無需關注工程細節,專注模型開發;運維人員統一管理資源、流程。
- 關鍵組件:數據存儲(MinIO)、特徵存儲(Feast)、實驗跟蹤(MLflow)、工作流調度(Airflow/Kubeflow)、模型部署(K8s)、監控(Prometheus+Evidently)。
- 開源方案參考:Kubeflow(Google 主導,基於 K8s 的端到端 ML 平台)、MLflow(輕量,聚焦實驗與部署)、BentoML(專注模型打包與部署)。
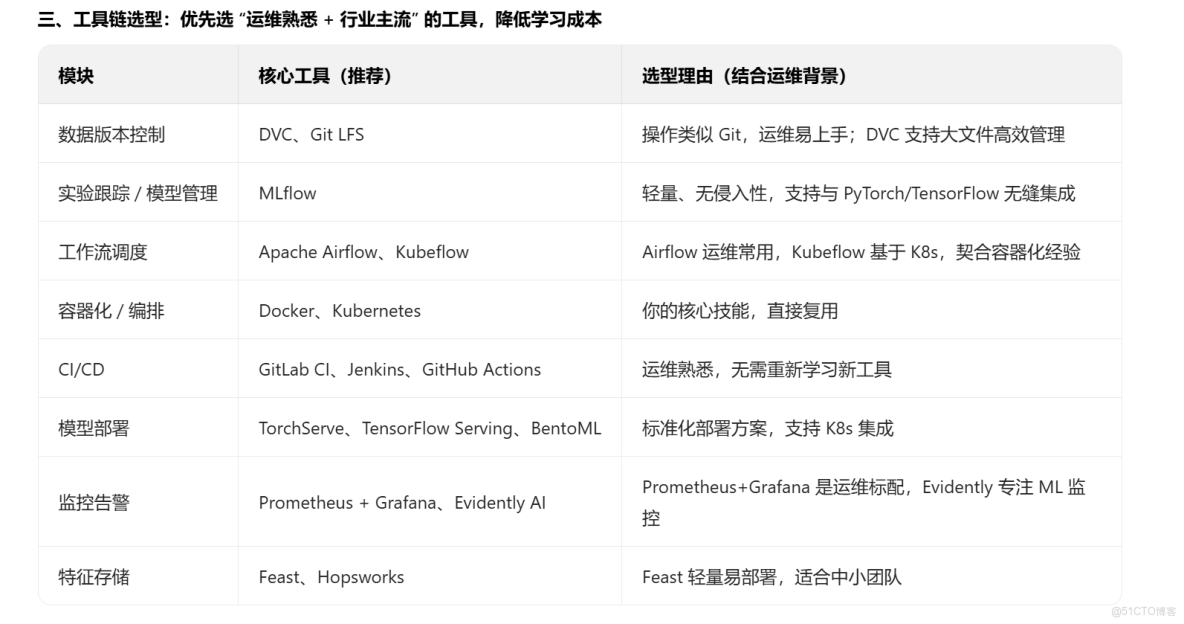
工具學習優先級:
四、實戰路徑:從 “小項目” 到 “平台搭建”,快速落地驗證
1. 入門實戰:搭建 “單模型自動化部署 + 監控” 流程(1-2 周)
2. 進階實戰:搭建輕量 MLOps 平台(1-2 個月)
- 數據層:MinIO(存儲原始數據)+ Feast(特徵存儲);
- 實驗層:MLflow(實驗跟蹤 + 模型註冊);
- 調度層:Airflow(定時觸發數據預處理、模型重訓練);
- 部署層:K8s(部署推理服務)+ GitLab CI(CI/CD 流水線);
- 監控層:Prometheus+Grafana(服務監控)+ Evidently AI(數據 / 模型監控)。實踐價值:可作為個人項目或公司內部試點,體現 “從 0 到 1 搭建 ML 工程體系” 的能力。
3. 生產級實踐(結合工作場景)
- 若公司已有 ML 團隊:推動 “模型部署標準化”(如制定模型打包規範、部署流程),搭建 CI/CD 流水線,落地監控告警;
- 若公司暫無 ML 場景:從 “AI 工具運維” 切入(如部署 Ollama 私有化大模型、Stable Diffusion 生成模型),再逐步搭建 MLOps 流程,成為公司 AI 工程化的核心推動者。
五、職業發展:MLOps 方向的 3 條進階路徑(匹配你的組長背景)
1. 技術專家路徑:MLOps 工程師 → ML 平台架構師 → 首席 AI 架構師
- 核心能力:深耕工具鏈與架構設計(如大規模 ML 平台的高可用、高併發設計),掌握雲原生(K8s、Serverless)、大數據(Flink、Spark)與 ML 的融合技術。
- 目標場景:大型科技公司、AI 創業公司,負責搭建企業級 ML 平台,支撐海量模型的落地。
2. 管理路徑:運維組長 → AI 運維負責人 → 技術總監(AI 方向)
- 核心能力:以 MLOps 為切入點,整合運維、ML 工程、數據團隊,推動跨團隊協作(數據科學家→ML 工程師→運維),制定 AI 工程化規範和流程。
- 優勢:你的 10 年運維經驗 + 團隊管理能力,能快速協調資源,推動 MLOps 落地,成為 “技術 + 管理” 雙能人才。
3. 交叉領域路徑:運維 → ML 工程師 → 業務 AI 專家
- 核心能力:在 MLOps 基礎上,補充業務場景的 ML 知識(如推薦系統、風控模型的業務邏輯),成為 “懂工程 + 懂業務 + 懂 ML” 的複合型人才。
- 目標場景:金融、電商、製造等行業,負責將 AI 技術落地到具體業務(如電商推薦系統的工程化落地、製造行業的質量檢測模型運維)。
六、學習資源:精準高效,避免信息過載
1. 入門書籍
- 《MLOps 實戰》:以案例為主,講解 MLOps 的核心流程與工具使用(適合零基礎入門);
- 《雲原生機器學習:MLOps 實戰指南》:結合 K8s、Docker,適合有運維 / 雲原生背景的學習者;
- 《MLflow 實戰》:聚焦 MLflow 的使用,快速掌握實驗與模型管理。
2. 在線課程
- Coursera《MLOps Engineering for Production (MLOps Zoomcamp)》:免費,由 DataTalks.Club 推出,實戰性強,涵蓋全流程工具鏈;
- 極客時間《MLOps 工程化實戰》:適合國內開發者,結合阿里雲、騰訊雲等雲服務,落地性強;
- B 站 “MLflow 官方教程”“Kubeflow 實戰”:免費視頻,適合快速上手工具。
3. 社區與文檔
- 官方文檔(優先看):MLflow Docs、Kubeflow Docs、Evidently AI Docs(權威、無過時信息);
- 社區:GitHub(MLOps 相關開源項目的 Issues / 討論)、知乎 “MLOps” 話題、DataTalks.Club 社區(國際 MLOps 交流);
- 公眾號:機器之心(MLOps 專欄)、雲原生實驗室(K8s+ML 融合)、DataFunTalk(MLOps 實戰案例)。
