
優化 Kubeflow 部署,配置多 Master、共享存儲,使用 PyTorchJob/TFJob 配合 checkpoint 策略,保留 MLOps 全流程能力
這些優化的核心目標是:
1. 提高可用性 (HA):通過多 Master 消除單點故障。
2. 提升效率:通過共享存儲和合理的 Checkpoint 策略,加速訓練、方便模型複用和故障恢復。
3. 優化資源利用:確保昂貴的計算資源(如 GPU)得到高效利用。

一、配置多 Master (High Availability)
默認情況下,Kubeflow 的核心組件(如 kubeflow-controller-manager, training-operator)是單副本部署的,這構成了單點故障風險。
優化方案:
- 為核心組件配置多副本:你需要修改 Kubeflow 部署時使用的 kfctl 配置文件(通常是 kfctl_istio_dex.v1.2.0.yaml 或類似的),將關鍵組件的 replicaCount 設置為大於 1。
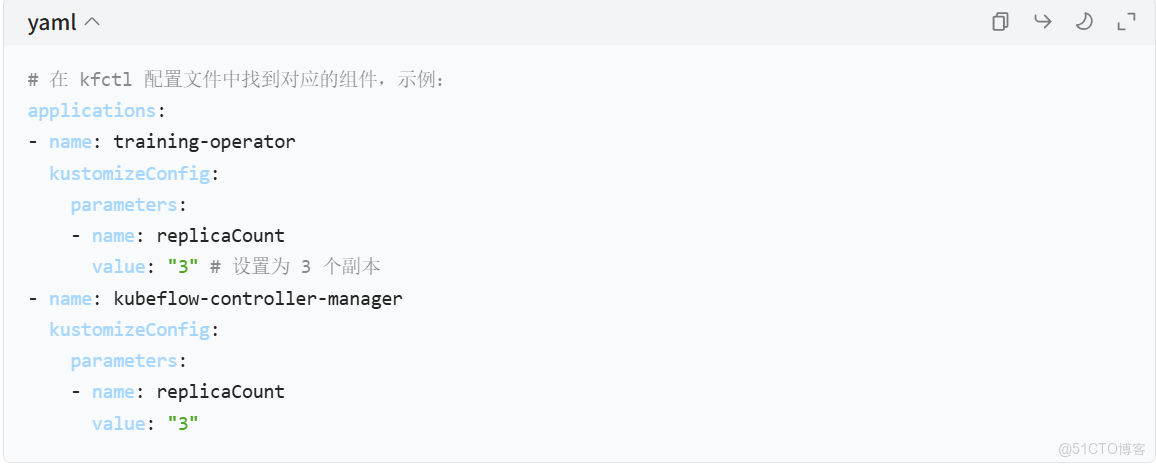
◦ 關鍵組件:至少包括 training-operator (負責訓練任務)、kubeflow-controller-manager (負責 Pipeline)、istio-ingressgateway (負責入口流量)。
◦ 原理:Kubernetes 的 Deployment 會確保指定數量的 Pod 副本運行,並通過 Service 實現負載均衡和故障轉移。
2. 使用外部數據庫和消息隊列:Kubeflow 的某些組件(如 Metadata Store, Katib)默認使用內置的、單節點的數據庫(如 SQLite)或消息隊列。為了實現 HA,應將它們替換為外部的、高可用的服務。
◦ 數據庫:可以使用 MySQL 或 PostgreSQL 的集羣版。
◦ 消息隊列:可以使用 Kafka 或 RabbitMQ 的集羣版。
◦ 這通常涉及更復雜的配置,需要修改 Kubeflow 組件的 kustomize 配置以指向外部服務。
優勢:
• 消除單點故障:即使一個 Master 組件的 Pod 失敗,其他副本會立即接管,訓練任務和 MLOps 流程不會中斷。
• 提升系統穩定性:增強了整個 Kubeflow 平台抵禦組件級故障的能力。
二、配置共享存儲
在分佈式訓練中,多個 Worker 節點需要訪問同一份訓練數據,並且訓練過程中產生的 Checkpoint 文件也需要被所有節點訪問(尤其是在故障恢復時)。
優化方案:
1. 選擇合適的存儲解決方案:
◦ 雲原生選項:在 AWS 上使用 EFS 或 S3;在 GCP 上使用 GCS;在 Azure 上使用 Azure Files 或 Blob Storage。
◦ 開源選項:在自建 K8s 集羣中,可以使用 MinIO (兼容 S3 API) 或 Ceph 作為共享存儲。
2. 在 K8s 中配置存儲:
◦ 創建 PersistentVolume (PV) 和 PersistentVolumeClaim (PVC):
將你的共享存儲(如 MinIO 的一個 bucket)掛載為 K8s 的 PV。然後,在你的訓練任務(PyTorchJob/TFJob)的 YAML 中,通過 PVC 來聲明使用這個存儲。
示例:在 PyTorchJob 中掛載 PVC
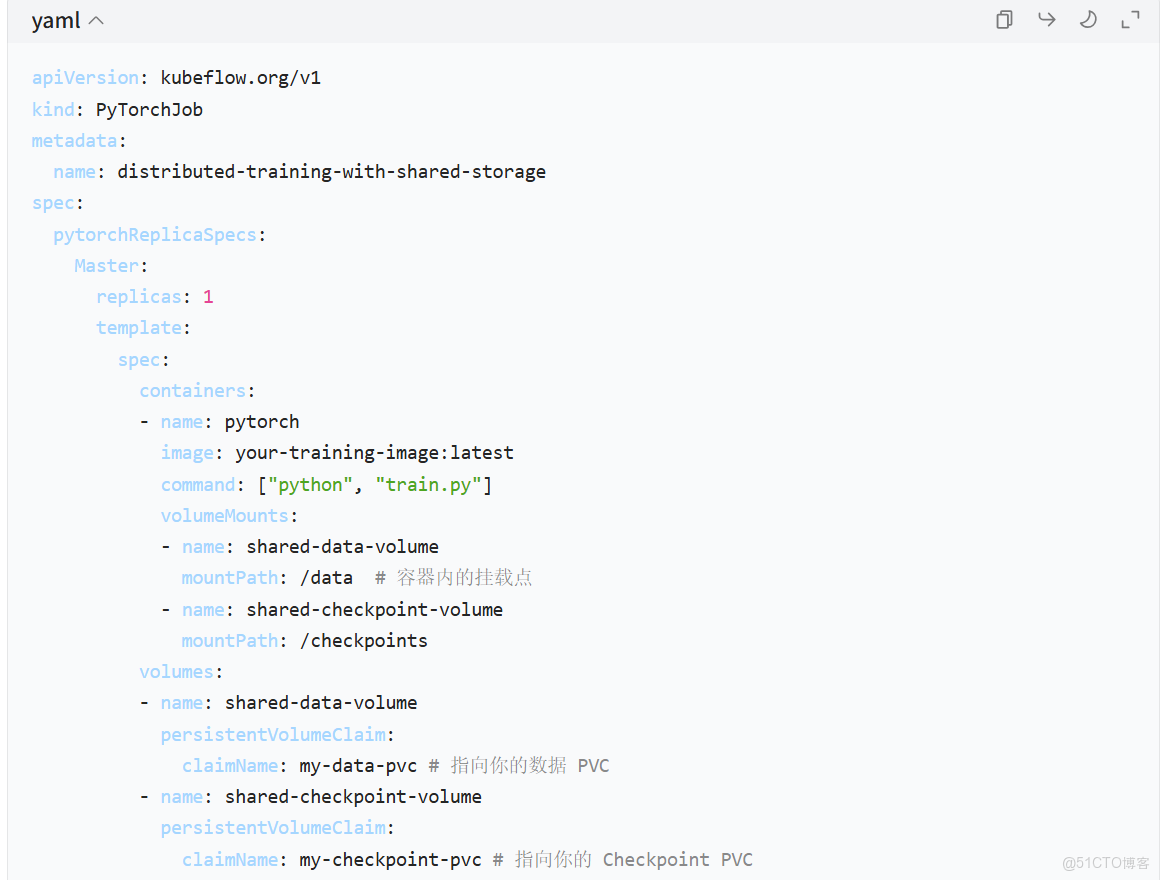
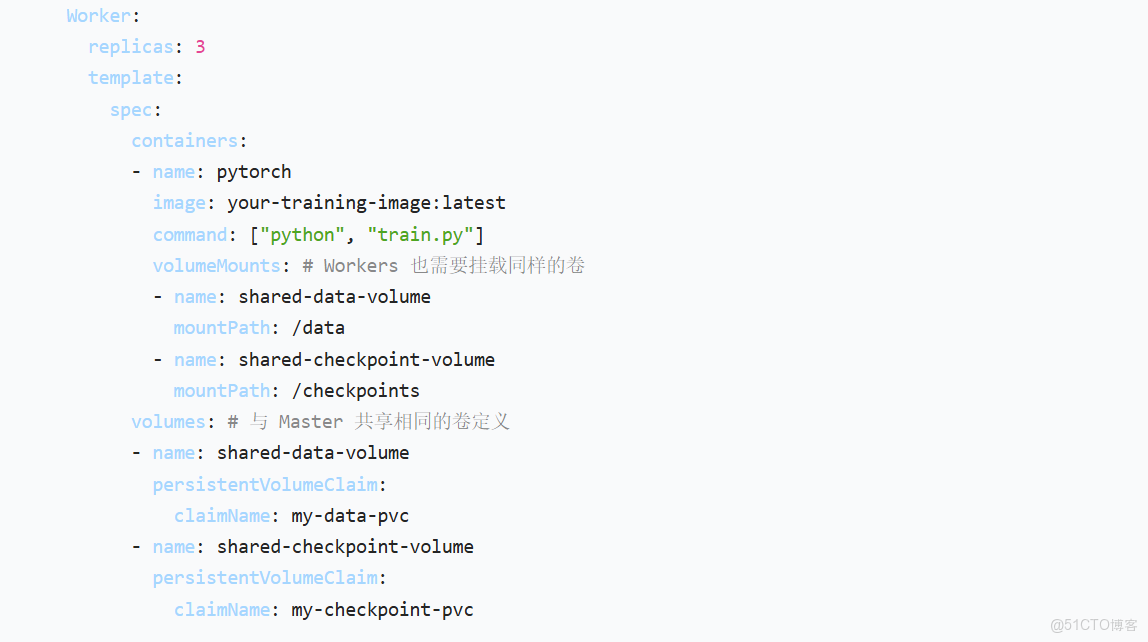
優勢:
• 數據一致性:所有訓練節點都能訪問到同一份最新的數據和 Checkpoint。
• 資源高效:避免了在每個節點上都複製一份大型數據集,節省了存儲空間和網絡帶寬。
• 便捷的故障恢復:當某個 Worker 或整個 Job 失敗時,可以從共享存儲上的最近一個 Checkpoint 快速恢復訓練,而不是從頭開始。
三、優化 Checkpoint 策略
Checkpoint 是訓練過程中保存的模型狀態(權重、優化器狀態等)的快照。一個好的 Checkpoint 策略對於提高訓練效率和可靠性至關重要。
優化方案:
1. 合理設置 Checkpoint 保存頻率:
◦ 不要太頻繁:每次保存 Checkpoint 都會消耗 I/O 和計算資源,過於頻繁會拖慢訓練速度。
◦ 不要太稀疏:如果保存間隔太長,一旦發生故障,需要重新訓練的步數就會很多,浪費資源。
◦ 建議:可以結合步數 (steps) 和輪次 (epochs) 來設置。例如,每訓練 1000 步或每完成 1 個 epoch 保存一次。同時,可以設置只保留最近的 N 個 Checkpoint,以防止共享存儲被佔滿。
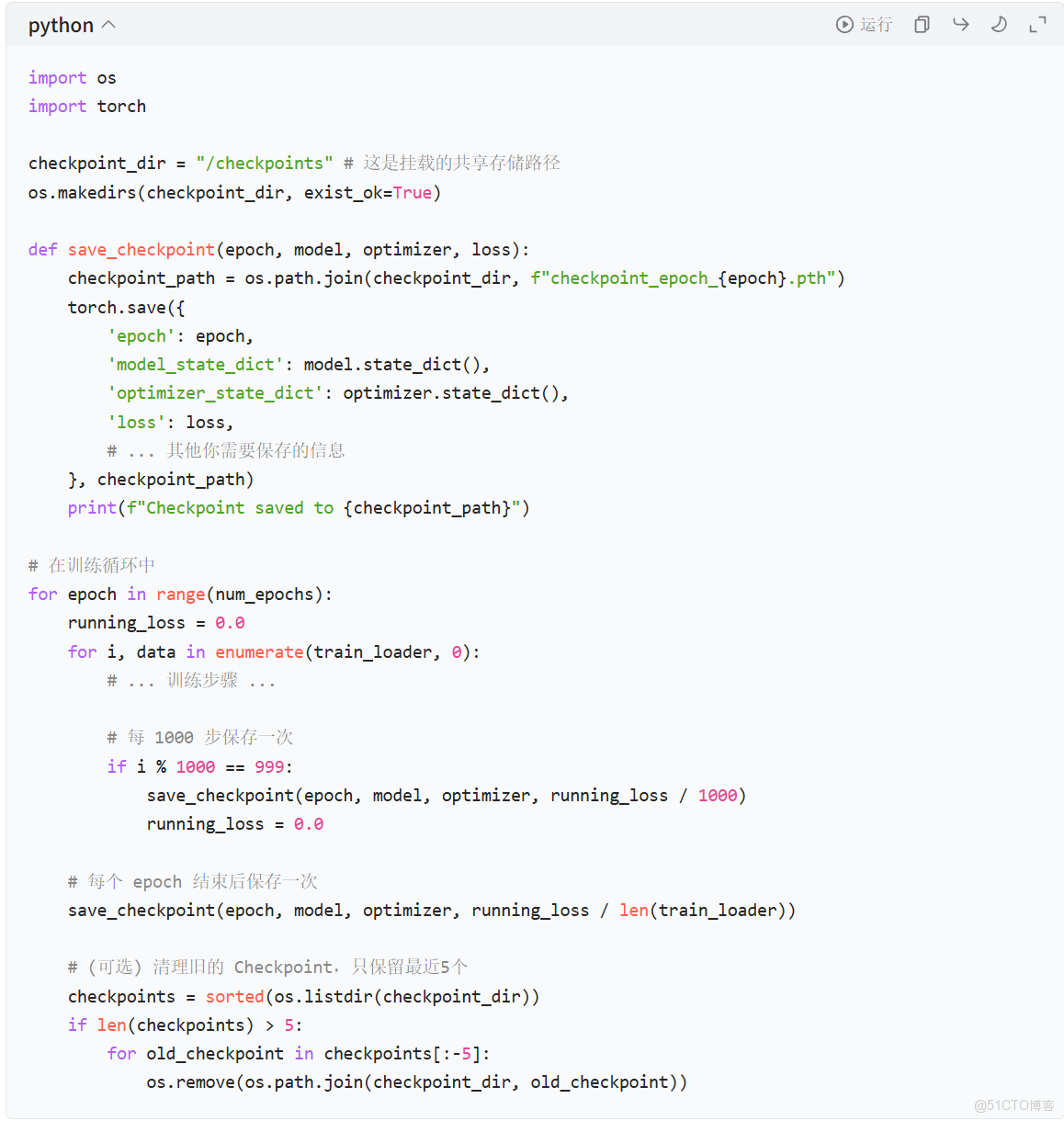
2. 實現 Checkpoint 回調:在你的訓練代碼中,使用框架提供的回調函數來自動管理 Checkpoint。
◦ PyTorch:使用 torch.save() 手動保存,或結合 torch.utils.tensorboard 的 ModelCheckpoint 回調。
◦ TensorFlow/Keras:使用 tf.keras.callbacks.ModelCheckpoint。
PyTorch 示例代碼片段
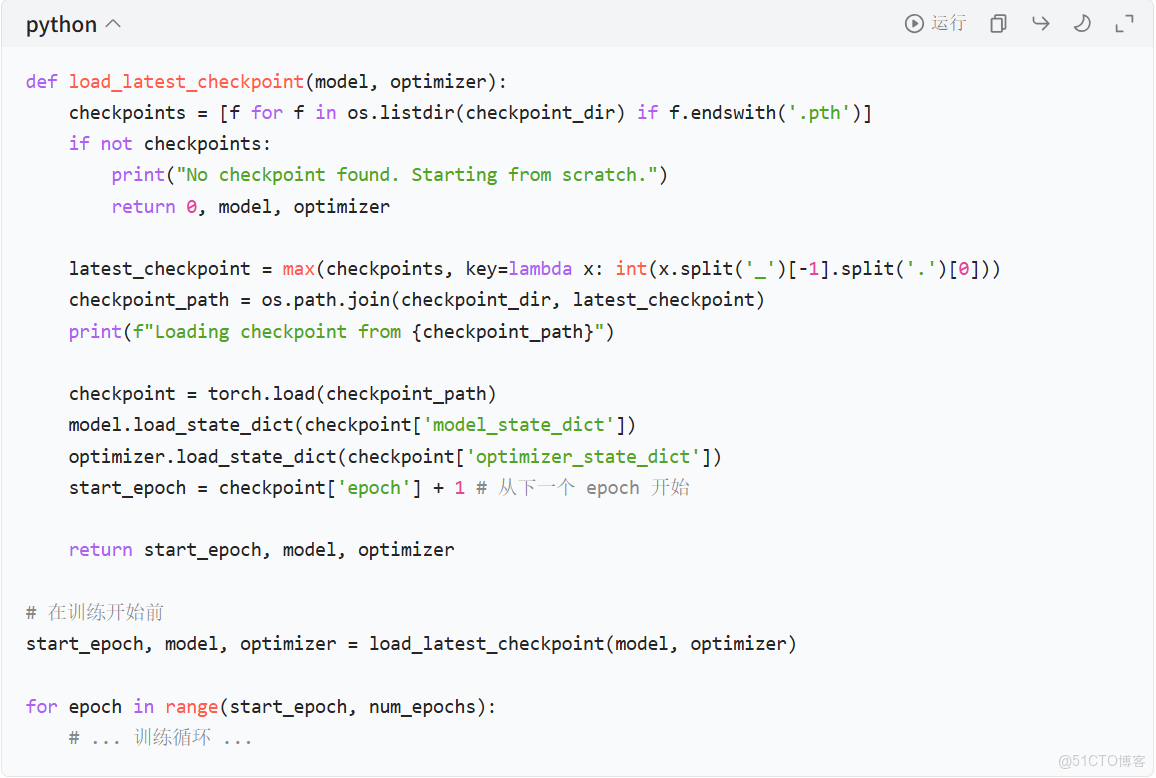
實現從 Checkpoint 恢復的邏輯:你的訓練腳本應該能夠檢測並加載最近的 Checkpoint,以便在中斷後繼續訓練。
恢復邏輯示例
優勢:
• 高效故障恢復:最大限度地減少因硬件故障、軟件錯誤或人為中斷導致的訓練進度損失。
• 資源節省:避免了重複計算,節省了寶貴的 GPU 時間。
• 支持彈性訓練:可以在訓練過程中動態調整 Worker 數量(如果框架支持),並從 Checkpoint 恢復。
總結
通過以上三個方面的優化,你的 Kubeflow 部署將變得更加健壯、高效和易於管理:
1. 多 Master 配置 確保了平台級的高可用性,為所有 MLOps 流程(如 Pipeline、實驗跟蹤)提供穩定的基礎。
2. 共享存儲 是實現分佈式訓練和高效數據管理的基石,讓數據和模型資產在整個集羣中無縫流轉。
3. 優化的 Checkpoint 策略 則直接提升了訓練任務的可靠性和資源利用效率,是大規模訓練中不可或缺的一環。
這些優化措施相互配合,共同構建了一個生產級的、能夠穩定支撐大規模機器學習任務的 Kubeflow 平台。
