

工作中遇到芯片初次燒錄跑不起來的問題,遂讓回讀片內數據查看與燒錄文件一直不一致
(有大佬知道此方法不對的麻煩評論一下)
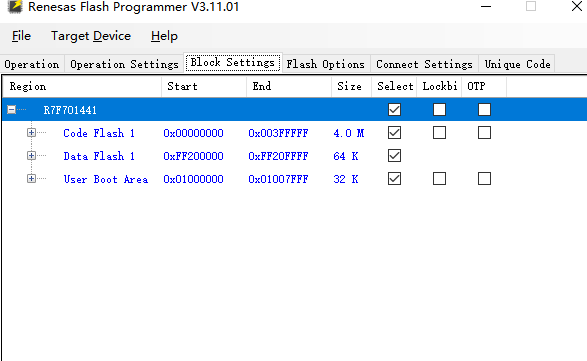
使用的是瑞薩的RH850系列r7f701411
使用Renesas Flash Programmer V3.11 搭配E1 進行回讀
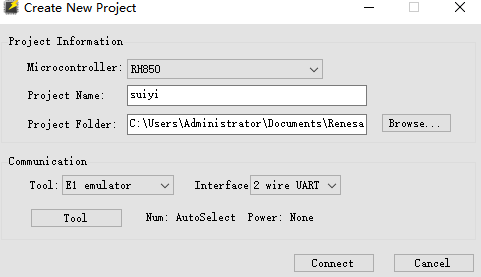
選擇對應的燒錄機器 其他默認則好 這裏選擇的E1
點擊 connect 出現選擇芯片晶振,這裏按自己的芯片來(注意必須物理連接上)
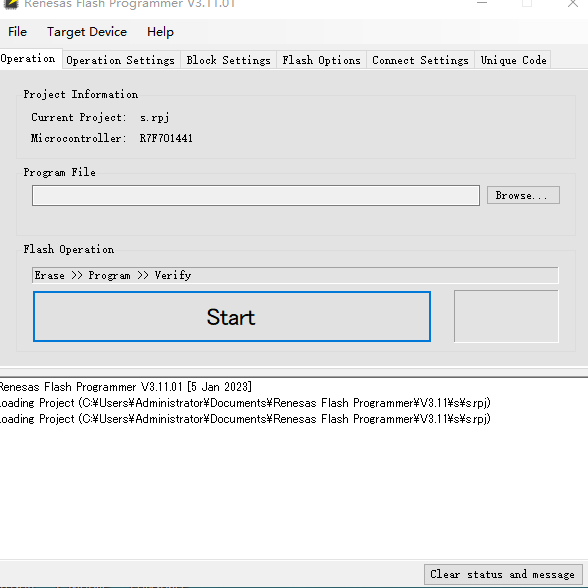
進入這個界面 大概介紹一下,我也認得不全
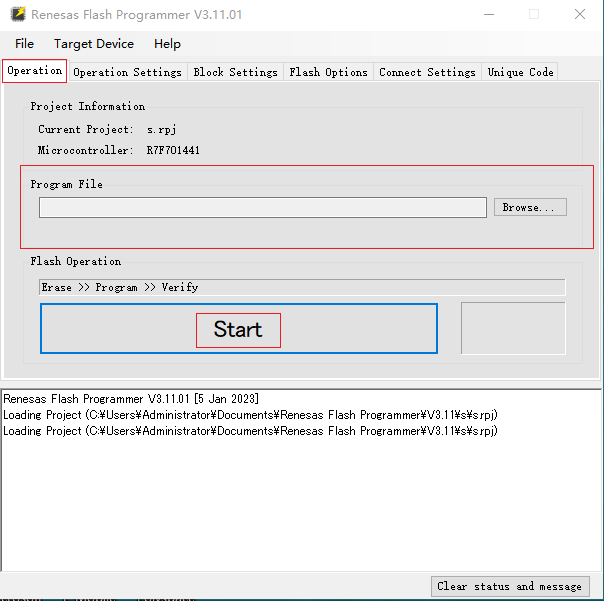
導入燒錄文件 start就可以燒錄
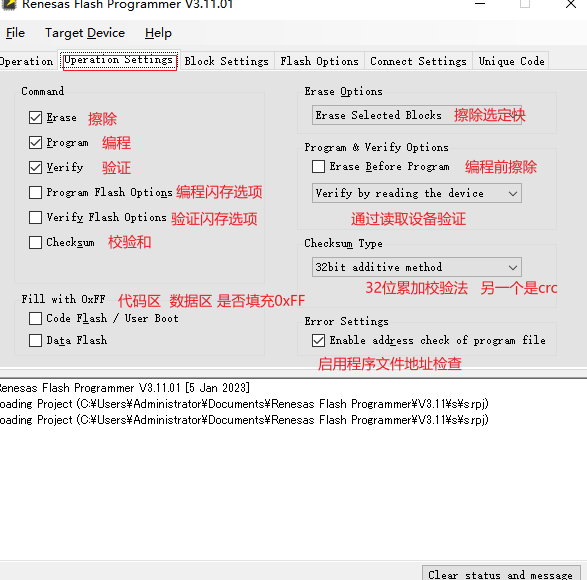
常規燒錄選前三個就可以
沒點過
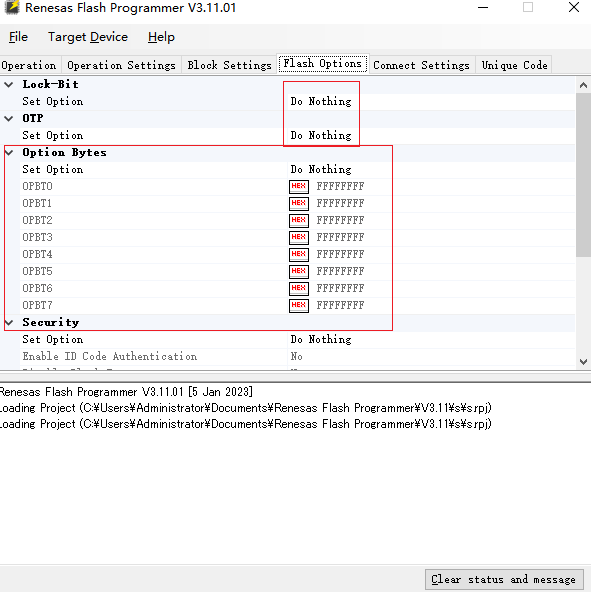
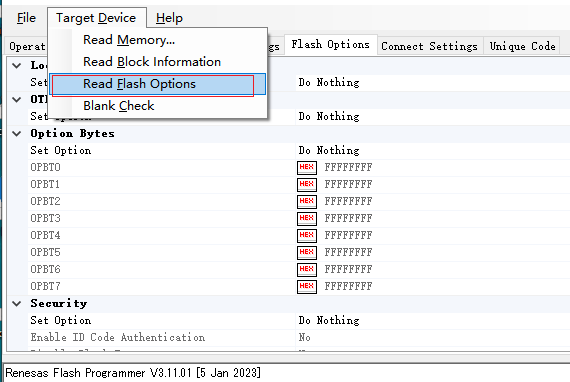
這裏的OPBT數據不對芯片啓動不起來,可以先讀取好的板子
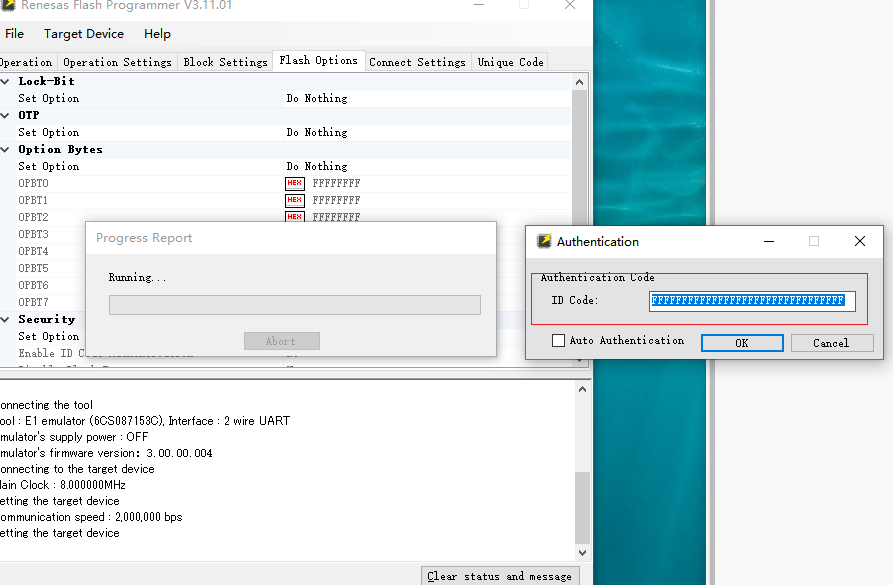
這個id也是可以改的
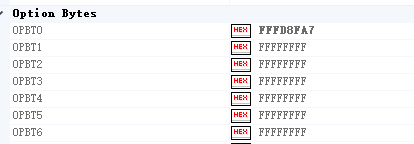
可以讀出好的板子這個(我讀新板子也有這個所以可以先讀一下)

勾選這個就可以填到我們的配置裏了
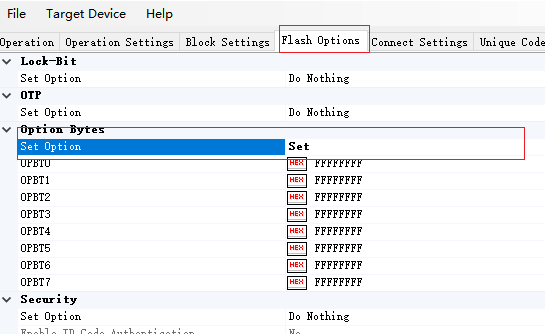
修改後可以寫道芯片裏

同樣 設置位set後可以修改id
這兩個地方沒改過
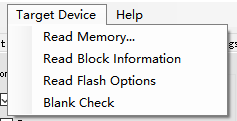
可以通過這裏讀取芯片某些信息
點擊第一個後會把設置的區域內代碼讀出
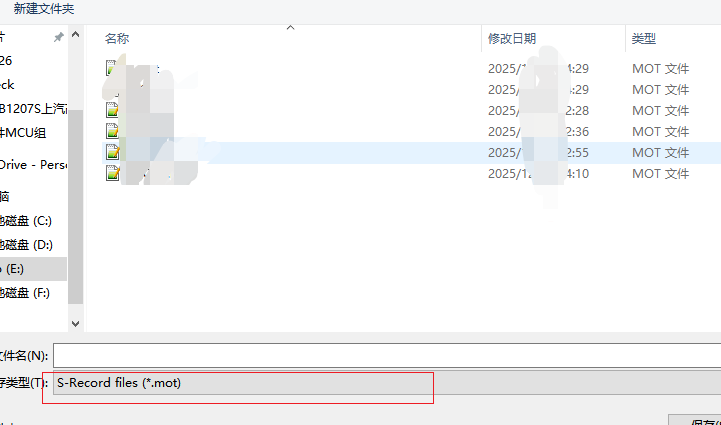
選擇一個保存地方
我這個版本支持.mot和.hex 選擇hex
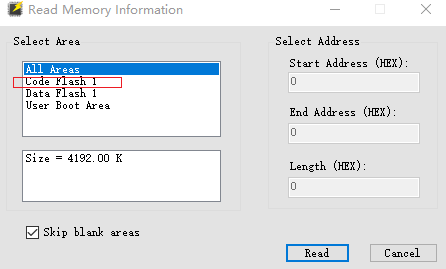
選擇讀取的區域
我選擇 code區 read就好了
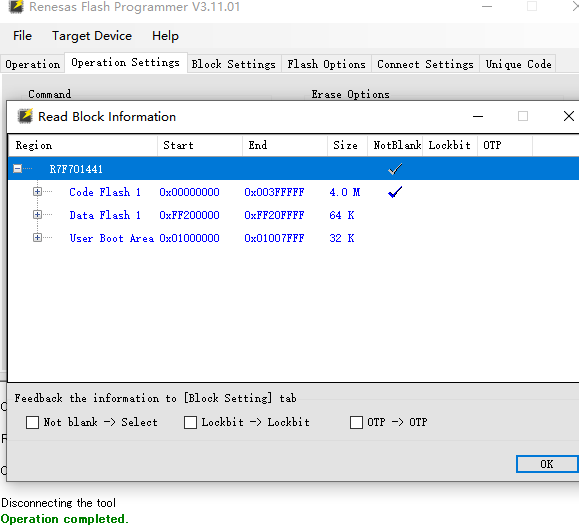
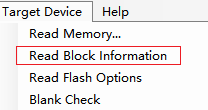
勾選 讀信息裏的第二個
可以看到那些區域上鎖沒 打鈎的
第四個檢查空白區
這裏進行題目的hex對比工作

直接讀出的數據
可以看到
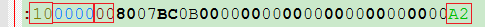
0x10 這段的數據有16字節
0000 地址
00 數據類型 00標準格式 04 擴展地址 (01 結束 05 開始地址等)
A2 這16的數據的校驗值

而我要燒寫的數據
0x20 32字節
所以要對這些數據進行掐頭去尾比較
import sys
def parse_hex_to_dict(filename):
"""
解析 HEX 文件,提取 {地址: 數據字節} 的映射。
處理記錄類型 00 (數據) 和 04 (擴展線性地址)。
"""
data_map = {}
extended_linear_address = 0
with open(filename, 'r') as f:
for line_num, line in enumerate(f, 1):
line = line.strip()
if not line.startswith(':'):
continue
try:
# 解析 HEX 行結構
byte_count = int(line[1:3], 16)
address = int(line[3:7], 16)
record_type = int(line[7:9], 16)
if record_type == 0x00: # 數據記錄
full_address = extended_linear_address + address
data_hex = line[9:9 + byte_count * 2]
# 將每一位數據存入字典
for i in range(byte_count):
byte_val = data_hex[i*2 : i*2+2].upper()
data_map[full_address + i] = byte_val
elif record_type == 0x04: # 擴展線性地址記錄
extended_linear_address = int(line[9:13], 16) << 16
# 其他類型 (01結束, 05開始地址等) 在對比純數據時通常可忽略
except ValueError:
print(f"警告: 無法解析文件 {filename} 第 {line_num} 行")
return data_map
def compare_hex_files(file1, file2):
print(f"正在讀取文件 1: {file1}")
data1 = parse_hex_to_dict(file1)
print(f"正在讀取文件 2: {file2}")
data2 = parse_hex_to_dict(file2)
# 獲取兩個文件的所有地址並集
all_addresses = sorted(list(set(data1.keys()) | set(data2.keys())))
if not all_addresses:
print("錯誤: 未在文件中找到有效數據。")
return
mismatches = []
only_in_file1 = []
only_in_file2 = []
for addr in all_addresses:
val1 = data1.get(addr)
val2 = data2.get(addr)
if val1 and val2:
if val1 != val2:
mismatches.append((addr, val1, val2))
elif val1:
only_in_file1.append(addr)
elif val2:
only_in_file2.append(addr)
# 輸出結果
print("\n" + "="*40)
print("比對結果彙報:")
print("="*40)
if not mismatches and not only_in_file1 and not only_in_file2:
print("恭喜!兩個文件的【數據內容】完全一致。")
print(f"有效數據總量: {len(all_addresses)} 字節")
else:
if mismatches:
print(f"發現 {len(mismatches)} 處數據不一致 (地址: 文件1 vs 文件2):")
# 僅顯示前 10 處差異
for addr, v1, v2 in mismatches[:10]:
print(f"地址 0x{addr:08X}: {v1} != {v2}")
if len(mismatches) > 10: print("... 剩餘差異已省略")
if only_in_file1:
print(f" 文件 1 獨有的地址數據量: {len(only_in_file1)} 字節")
if only_in_file2:
print(f"文件 2 獨有的地址數據量: {len(only_in_file2)} 字節")
print("="*40)
if __name__ == "__main__":
# 使用方法: python script.py file1.hex file2.hex
if len(sys.argv) < 3:
print("使用方法: python compare.py <燒錄文件.hex> <讀取文件.hex>")
else:
compare_hex_files(sys.argv[1], sys.argv[2])
運行時須在命令行執行 python compare.py Rj.hex du1.hex
例如
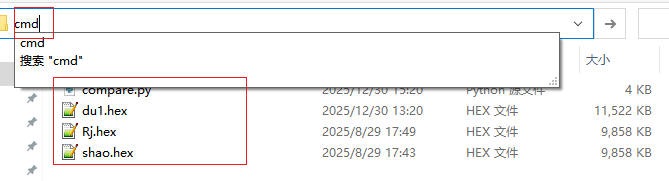
新建文件夾,將py文件名為compare.py 以及導入要對比的數據
在文件位置輸入cmd回車召除命令行
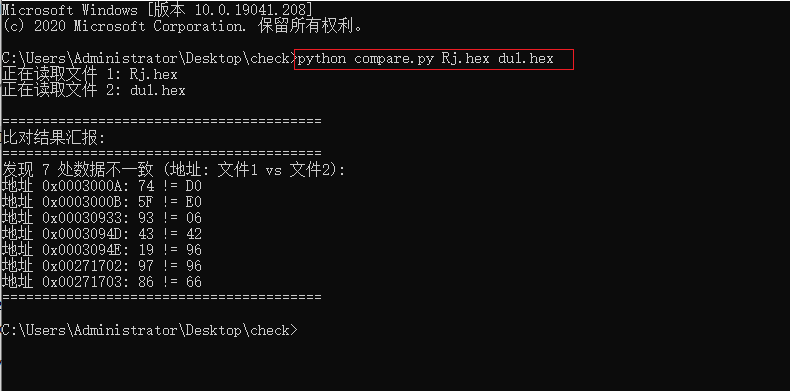
便可看到結果
現在記錄一下腳本內容

初始化變量
data_map = {} # 存儲最終結果:地址->數據字節
extended_linear_address = 0 # 高16位地址
逐行解析
跳過不以:開頭的行
使用enumerate(f, 1)跟蹤行號便於錯誤報告

解析關鍵字段
byte_count = int(line[1:3], 16) # 數據字節數
address = int(line[3:7], 16) # 低16位地址
record_type = int(line[7:9], 16) # 記錄類型
計算完整32位地址:高16位 + 低16位
full_address = extended_linear_address + address
提取數據部分:line[9:9 + byte_count * 2]
逐字節存入字典


地址合併排序
all_addresses = sorted(list(set(data1.keys()) | set(data2.keys())))
set(data1.keys()) | set(data2.keys()):取兩個地址集的並集
list():轉換為列表
sorted():排序,確保按地址順序比對
檢查地址有效性
if not all_addresses:
print("錯誤: 未在文件中找到有效數據。")
return
定義三種隊列
mismatches = [] # 地址相同但數據不同
only_in_file1 = [] # 只在文件1中出現的地址
only_in_file2 = [] # 只在文件2中出現的地址
比較邏輯
for addr in all_addresses:
val1 = data1.get(addr) # 使用get()避免KeyError
val2 = data2.get(addr)
if val1 and val2: # 兩個文件都有這個地址
if val1 != val2: # 但數據不同
mismatches.append((addr, val1, val2))
elif val1: # 只在文件1中
only_in_file1.append(addr)
elif val2: # 只在文件2中
only_in_file2.append(addr)
輸出結果
print("\n" + "="40)
print("比對結果彙報:")
print("="40)
一致的話
if not mismatches and not only_in_file1 and not only_in_file2:
print("恭喜!兩個文件的【數據內容】完全一致。")
print(f"有效數據總量: {len(all_addresses)} 字節")
不一致的話
else:
# 顯示數據不一致的地址
if mismatches:
print(f"發現 {len(mismatches)} 處數據不一致 (地址: 文件1 vs 文件2)😊
# 限制顯示前10處差異,避免輸出過多
for addr, v1, v2 in mismatches[:10]:
print(f"地址 0x{addr:08X}: {v1} != {v2}")
if len(mismatches) > 10:
print("... 剩餘差異已省略")
# 顯示獨有的地址數量
if only_in_file1:
print(f" 文件 1 獨有的地址數據量: {len(only_in_file1)} 字節")
if only_in_file2:
print(f"文件 2 獨有的地址數據量: {len(only_in_file2)} 字節")