









引言
繼上一篇BFF的文章後,我又去網上學習了一下DDD(領域驅動設計),發現一篇不錯的文章,參考並寫了一些自己的理解分享在這裏。
DDD
是什麼
領域驅動設計(Domain Driven Design) 是一種從系統分析到軟件建模的一套方法論。以領域為核心驅動力的設計體系。
為什麼使用
- 面向對象設計,數據行為綁定,告別貧血模型
- 優先考慮領域模型,而不是切割數據和行為
- 準確傳達業務規則
- 代碼即設計
以上是網上文章説的,但我在會議中理解的還是不變性,面向領域知識進行一系列的編程與設計,只要當前領域內的通用知識沒有發生變化,這些設計就不會進行變動。
戰略設計
首先戰略開始,不以戰略開始,戰術設計將無法有效實施。它強調的是業務戰略上的重點,如何按重要性分配工作,以及如何進行最佳整合。
首先用限界上下文的戰略設計模式來分離領域模型。然後在明確的限界上下文中發展一套領域模型的通用語言。進一步深入戰略設計中將會了解到用子域處理系統無邊界的複雜性。還會了解如何通過上下文映射來集成多個限界上下文。上下文映射圖同時定義了兩個進行集成的限界上下文之間的團隊間關係及技術實現方式。
限界上下文
限界上下文是一個顯式的語義和語境上的邊界,領域模型便存在於邊界之內。邊界內,通用語言中的所有術語和詞組都有特定的含義。
子域
代表單一的,有邏輯的領域模型。最佳情況,限界上下文於子域一一對應。
子域有三種類型:
- 核心域:業務的核心,核心競爭力。
- 支撐域:輔助核心域
- 通用域:被整個業務系統使用
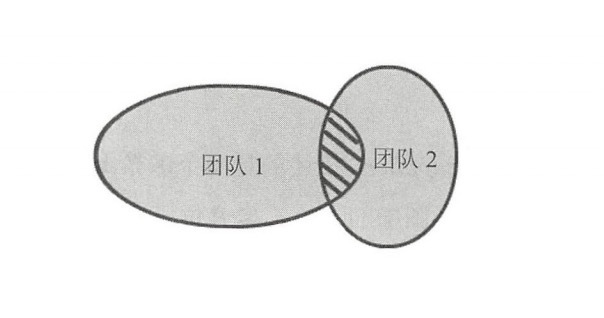
上下文映射圖
上下文映射圖就是表示兩個或多個限界上下文之間的映射關係。
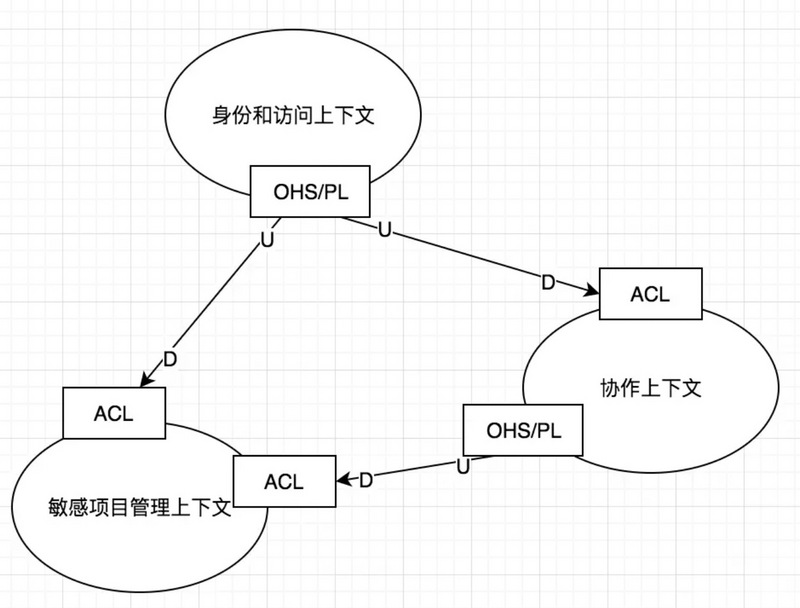
上下文組織和集成模式:
-
合作關係(Partnership):要麼一起成功,要麼一起失敗,此時他們需要建立起一種合作關係。他們需要一起協調開發計劃和集成管理。
-
共享內核(SharedKernel):模型和代碼的共享將產生一種緊密的依賴性。常見做法就是通過二進制依賴(jar)的方式共享給所有上下文使用。
-
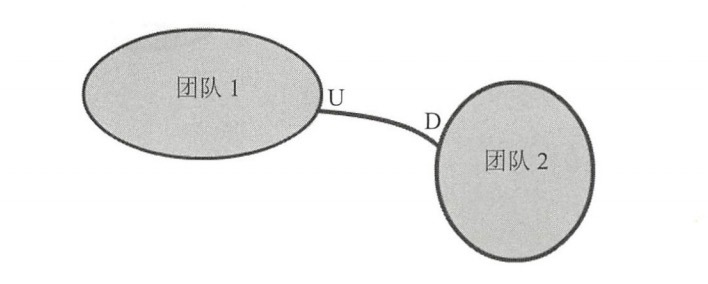
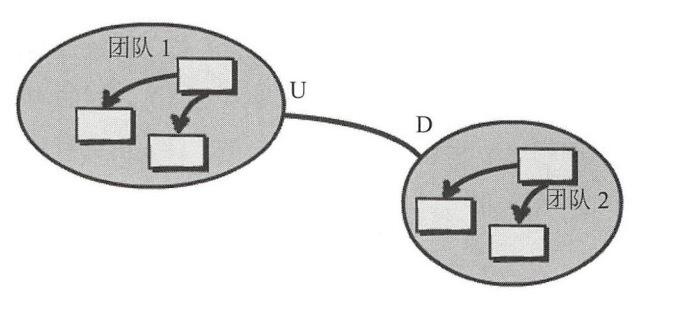
客户方-供應方開發(Customer-Supplier Development):客户方(D)提需求,供應方(U)配合做開發,現在用mq解耦的方式就非常類似這種。
-
尊奉者(Conformist):跟客户方-供應方開發類似,只是供應方沒有開發功力。下游只能盲目的使用上游的模型。
-
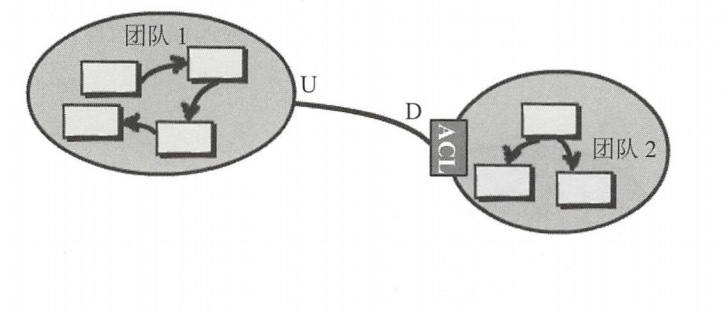
防腐層(Anticorruption Layer):簡稱ACL,在集成兩個上下文,如果兩邊都狀態良好,可以引入防腐層來作為兩邊的翻譯,並且可以隔離兩邊的領域模型。
-
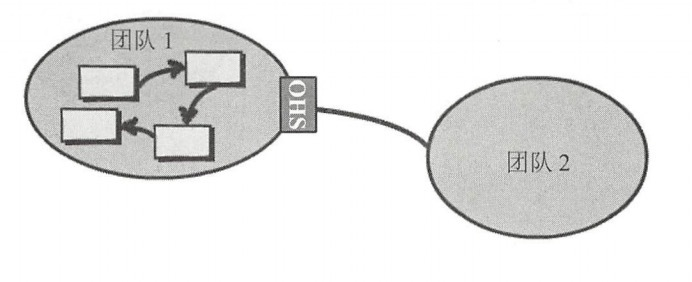
開放主機服務(Open Host Service):簡稱OHS,公開發布服務,公開的http服務,這是經常使用的
-
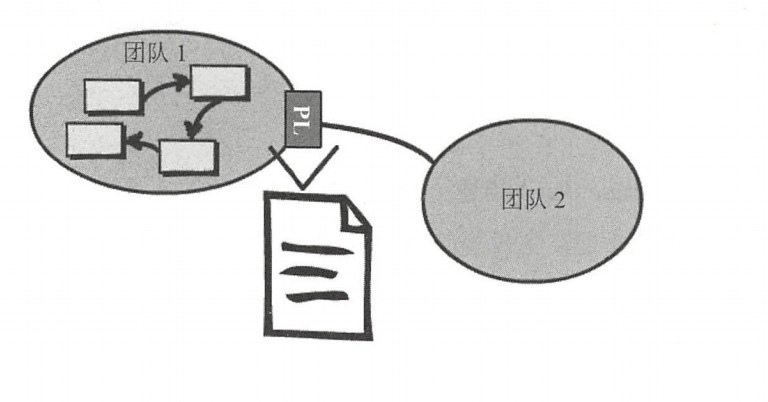
發佈語言(Published Language):簡稱PL,在兩個限界上下文之間翻譯模型需要一種公用的語言,發佈語言通常與開放主機服務一起使用。比如http服務,使用xml交互還是json做數據格式
-
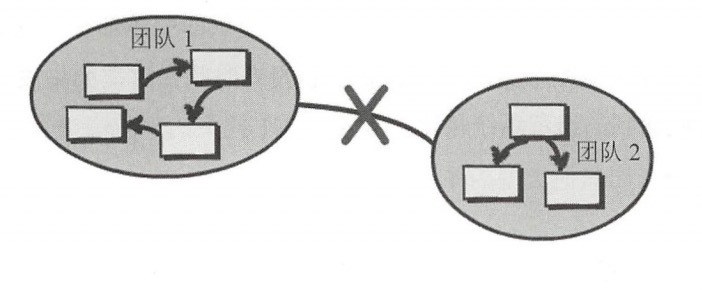
另謀他路(SeparateWay):聲明兩個限界上下文不存在任何關係,這也是一種很重的關係,完全獨立各自開發
-
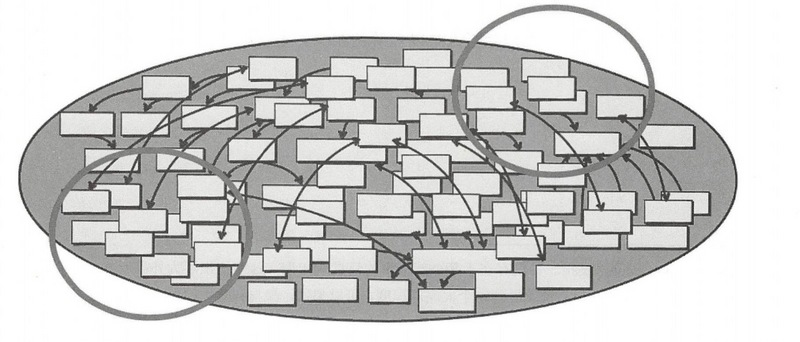
大泥球(Big Ball of Mud):對已有的一個大的混雜的系統,已經無法在內部梳理清楚了。你那怎麼辦呢?把這整個系統當成一個大泥球,對整個系統畫在一個邊界內,當成一個黑盒子,這樣只要接口可用就行,也防止了大泥球內部的混雜擴展到其它系統上。對歷史包袱的系統,可以採取這種做法。

示例
架構
分層
嚴格分層架構:某層只能與直接位於的下層發生耦合。
鬆散分層架構:允許上層與任意下層發生耦合
依賴倒置原則
高層模塊不應該依賴於底層模塊,兩者都應該依賴於抽象
抽象不應該依賴於實現細節,實現細節應該依賴於接口
簡單的説就是面向接口編程。
按照DIP的原則,領域層就可以不再依賴於基礎設施層,基礎設施層通過注入持久化的實現就完成了對領域層的解耦,採用依賴注入原則的新分層架構模型就變成如下所示:
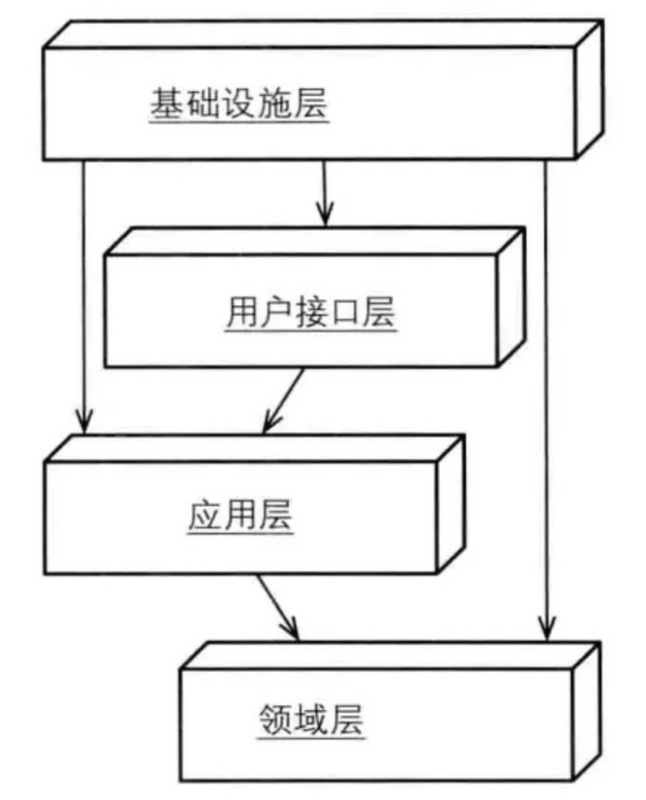
六邊形架構(端口與適配器)
對於每一種外界類型,都有一個適配器與之對應。外界接口通過應用層api與內部進行交互。
對於右側的端口與適配器,我們可以把資源庫看成持久化的適配器。
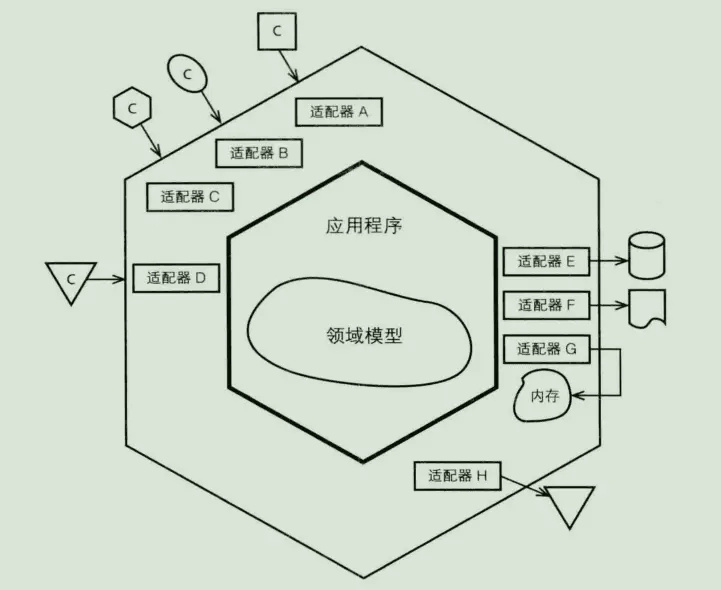
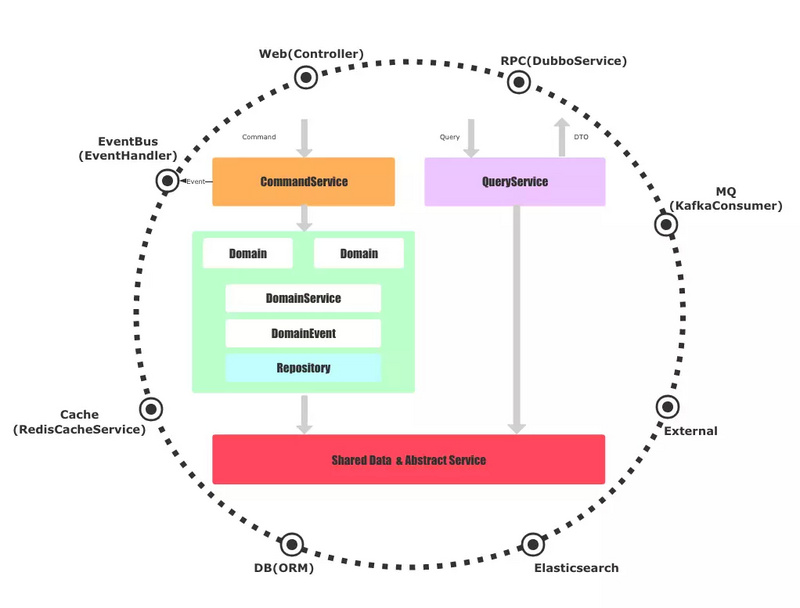
架構中,我們平等的看待Web、RPC、DB、MQ等外部服務,基礎實施依賴圓圈內部的抽象。
當一個命令Command請求過來時,會通過應用層的CommandService去協調領域層工作,而一個查詢Query請求過來時,則直接通過基礎實施的實現與數據庫或者外部服務交互。再次強調,我們所有的抽象都定義在圓圈內部,實現都在基礎設施。
命令和查詢職責分離--CQRS
-
一個對象的一個方法修改了對象的狀態,該方法便是一個命令(Command),它不應該返回數據,聲明為void。
-
一個對象的一個方法如果返回了數據,該方法便是一個查詢(Query),不應該通過直接或者間接的手段修改對象狀態。
-
聚合只有Command方法,沒有Query方法。
-
資源庫只有add/save/fromId方法。
-
領域模型一分為二,命令模型(寫模型)和查詢模型(讀模型)。
-
客户端和查詢處理器
客户端:web瀏覽器、桌面應用等
查詢處理器:一個只知道如何向數據庫執行基本查詢的簡單組件,查詢處理器不復雜,可以返回DTO或其它序列化的結果集,根據系統狀態自定
-
查詢模型:一種非規範化的數據模型,並不反映領域行為,只用於數據顯示
-
客户端和命令處理器
聚合就是命令模型
命令模型擁有設計良好的契約和行為,將命令匹配到相應的契約是很直接的事情
-
事件訂閲器更新查詢模型
-
處理具有最終一致性的查詢模型
事件驅動架構
- 事件驅動架構可以融入六邊型架構,融合的比較好,也可以融入傳統分層架構
- 管道和過濾器
- 長時處理過程
- 主動拉取狀態檢查:定時器和完成事件之間存在競態條件可能造成失敗
- 被動檢查,收到事件後檢查狀態記錄是否超時。問題:如果因為某種原因,一直收不到事件就一直不過期
- 事件源
- 對於聚合的每次命令操作,都至少一個領域事件發佈出去,表示操作的執行結果
- 每一個領域事件都將被保存到事件存儲中
- 從資源庫獲取聚合時,將根據發生在聚合上的事件來重建聚合,事件的重放順序與其產生順序相同
- 聚合快照:將聚合的某一事件發生時的狀態快照序列化存儲下來。以減少重放事件時的耗時
戰術設計
實體
DDD中要求實體是唯一的且可持續變化的。意思是説在實體的生命週期內,無論其如何變化,其仍舊是同一個實體。唯一性由唯一的身份標識來決定的。可變性也正反映了實體本身的狀態和行為。
實體 = 唯一身份標識 + 可變性【狀態(屬性) + 行為(方法或領域事件或領域服務)
為什麼使用實體
在使用DDD時,將數據模型轉換為實體模型
唯一標識
在設計實體時。我們首先考慮實體的本質特徵,特別是實體的唯一標識和對實體的查找,而不是一開始便關注實體的屬性和行為。
值對象可以存儲實體的唯一標識,與身份相關的行為可以封裝在值對象中,避免泄漏到模型的其他部份或客户端中。
創建策略
- 用户提供唯一標識
- 應用程序生成唯一標識
- 持久化機制生成唯一標識
- 另一個限界上下文提供唯一標識
標識生成時間
延遲生成方式
及早生成方式
委派標識
兩個標識,一個為領域所用,一個為ORM所用。委派標識沒有業務意義,迎合ORM而建。對外要隱藏,不是領域模型的一部分。
模式,層超類型,protected類型的委派標識字段。
標識穩定性,不應該修改實體的唯一標識。
發現實體及其本質特性
挖掘實體的行為:set方法不是完全要禁止,在其符合通用語言(有語義)的時候,或者完成客户端單個請求不用調用多個set時才有理由使用set方法。多個set方法使語義充潢歧義,使領域事件的發送也無法應對到單個命令上
創建實體:實體維護了一個或多個不變條件(整個生命週期中都必須保持事務一致性的狀態),聚合關注不變條件
跟蹤變化:使用領域事件跟蹤領域實體的狀態變化,將領域專家所關心的狀態改變建模成事件。
值對象
當你只關心某個對象的屬性時,該對象便可作為一個值對象。為其添加有意義的屬性,並賦予它相應的行為。我們需要將值對象看成不變對象,不要給它任何身份標識,還應該儘量避免像實體對象一樣的複雜性。
值對象=值+對象=將一個值用對象的方式進行表述,來表達一個具體的固定不變的概念。
為什麼使用值對象
使用不變的值對象使得我們做更少的職責假設
值對象的特性
- 它度量或者描述了領城中的一件東西
- 它可以作為不變量
- 它將不同的相關的屬性組合成一個概念整體
- 當度量和描述改變時,可以用另一個值對象予以替換
- 它可以和其他值對象進行相等性比較
- 它不會對協作對象造成副作用
實現
值對象有兩個構造
第一個:包含所有屬性的構造函數,對基本屬性的賦值調用私有的setter方法(自委派性)
第二個:複製作用的構造函數,用於將一個值對象複製為另一個新的值對象(淺複製即可,深複製太複雜,對於不變的值對象共享屬性不會出現什麼問題)
無副作用方法的名字很重要,不推薦使用java bean規範,除非其有通用語言的意義。推薦:String.endWith(),startWith(), indexOf()等。值對象的設計,方法不要遵循JavaBean規範。其setter更違背了值對象的不變性原則
持久化值對象
持久化機制不應該影響到值對象的建模;根據領域模型來設計數據模型,而不是根據數據模型來設計領域模型
ORM與單個值對象
實體和值對象一對一映射,值對象的屬性作為字段存在和實體同一張表中
多個值對象序列化到單個列中
實體引用了List和Set屬性的值對象集合
使用數據庫實體保存多個值對象
值對象單獨一個數據庫實體表存儲,並且帶有一個委派主鍵標識,這個標識不對客户端展示。領域模型依然是一個值對象。持久化相關的邏輯沒有泄漏到模型或客户端上去。
領域服務
當領域中的某個操作過程或轉換過程不是實體或值對象的職責時,我們便應該將該操作放在一個單獨的接口中,即領域服務。請確保該服務和通用語言時一致的。並且保證它是無狀態的。
概述
- 用於實現某個領域的任務,不適合放在聚合或值對象上時,就放在領域服務上
- 放在聚合根的靜態方法上有悖DDD
- 避免在聚合中調用資源庫
可以用領域服務的情況
- 執行一個顯著的業務操作
- 對領域對象進行轉換
- 以多個領域對象作為輸入參數進行計算,結果產生一個值對象
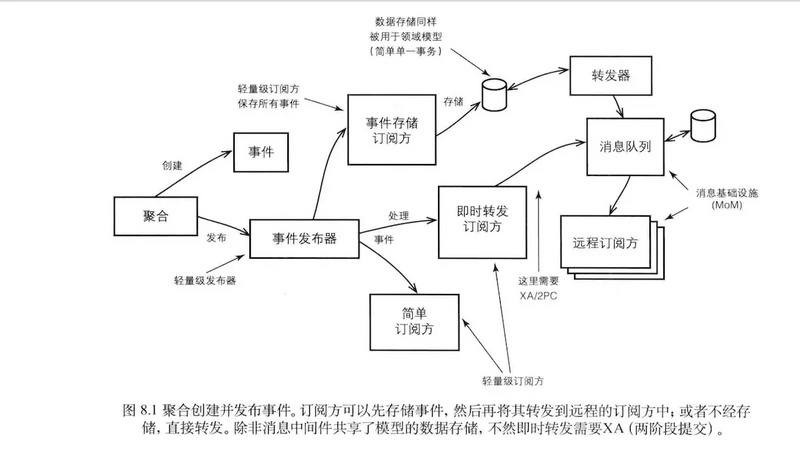
領域事件
領域事件是一個領域模型中極其重要的部分,用來表示領域中發生的事件。忽略不相關的領域活動,同時明確領域專家要跟蹤或希望被通知的事情,或與其他模型對象中的狀態更改相關聯
領域事件 = 事件發佈 + 事件存儲 + 事件分發 + 事件處理。
建模領域事件
- 根據限界上下文的通用語言來命名事件及其屬性
- 如果事件由聚合上的命令操作產生,則應該根據操作方法的名字來命名領域事件
- 事件的名字應該反映過去發生的事情
- 領域事件應該都有一個發生時間屬性,同時要包括另外的屬性:比哪些聚合跟此事件相關,繼承統一的DomainEvent接口
- 事件所帶的屬性能夠反映出該事件的來源。事件對象提供getter方法。事件屬性應該是隻讀的,沒有setter方法
- 是否有必要消除事件的重複提交
- 一個業務用例對應一個事務,一個事務對應一個聚合根,也即在一次事務中,只能對一個聚合根進行操作。當一個聚合依賴另一個聚合時,可以通過事件實現它們狀態的最終一致性
模塊
模塊的設計是基於領域模型的,要符合通用語言的表述。其次,模塊的設計要符合高內聚低耦合的設計思想。
領域模型命名規範
- 頂級模塊下一層模塊名定位了一個限界上下文(就是一個應用子域),如com.smudge.atum
- 示例:com.smudge.atum.domain.aggregate,該層定義模型中的聚合。
- 上述命名規範與傳統的分層架構和六邊形架構兼容
聚合
聚合是領域對象的顯式分組,旨在支持領域模型的行為和不變性,同時充當一致性和事務性邊界。一個聚合包含聚合根、實體和值對象。
聚合設計原則
-
在一致性邊界之內建模真正的不變條件
- 一致性。事務一致性、最終一致性。一個事務中只修改一個聚合,反之:不能在一個事務中同時修改多個聚合實例,真要這麼做的話要考慮最終一致性
- 不變條件。指的是一個業務規則,該規則應該總是保持一致的
-
設計小聚合。根實體(Root Entity)表示聚合,絕大多數根實體可以設計為聚合
-
通過唯一標識引用其它聚合
-
在邊界之外使用最終一致性
打破原則的理由
- 方便用户界面
- 一組聚合只有一個用户在處理它們,保證用户-聚合親和度使我們有理由在單個事務中修改多個聚合實例,因為這不會違背聚合不變條件
- 全局事務
- 查詢性能
實現
- 創建具有唯一標識的根實體(將實體建成聚合根)
- 優先使用值對象
- 使用迪米特法則
- “告訴而非詢問”原則
- Version實現樂觀併發
- 聚合中不應該注入資源庫或者領域服務
聚合根、實體、值對象
從標識角度:聚合根是實體,具有全局的唯一標識。而實體只有在聚合內部有唯一的本地標識,值對象沒有唯一標識,通過屬性判斷相等性,實現Equals方法。
從是否只讀的角度:聚合根除了唯一標識外,其他所有狀態信息都理論上可變。實體是可變的。值對象不可變,是隻讀的。
從生命週期角度:聚合根有獨立的生命週期,實體的生命週期從屬於其所屬的聚合,實體完全由其所屬的聚合根負責管理維護。值對象無生命週期可言,因為只是一個值。
聚合根、實體、值對象對象之間如何建立關聯
聚合根到聚合根:通過ID關聯;
聚合根到其內部的實體,直接對象引用;
聚合根到值對象,直接對象引用;
實體對其他對象的引用規則:
- 能引用其所屬聚合內的聚合根、實體、值對象。
- 能引用外部聚合根,但推薦以ID的方式關聯,另外也可以關聯某個外部聚合內的實體,但必須是ID關聯,否則就出現同一個實體的引用被兩個聚合根持有,這是不允許的,一個實體的引用只能被其所屬的聚合根持有。
值對象對其他對象的引用規則:只需確保值對象是隻讀的即可,推薦值對象的所有屬性都儘量是值對象。
工廠
領域模型中的工廠
- 將創建複雜對象和聚合的職責分配給一個單獨的對象,它並不承擔領域模型中的職責,但是領域設計的一部份
- 對於聚合來説,我們應該一次性的創建整個聚合,並且確保它的不變條件得到滿足
- 工廠只承擔創建模型的工作,不具有其它領域行為
- 一個含有工廠方法的聚合根的主要職責是完成它的聚合行為
- 在聚合上使用工廠方法能更好的表達通用語言,這是使用構造函數所不能表達的
聚合根中的工廠方法
- 聚合根中的工廠方法表現出了領域概念
- 工廠方法可以提供守衞措施
領域服務中的工廠
- 在集成限界上下文時,領域服務作為工廠
- 領域服務的接口放在領域模型內,實現放在基礎設施層
資源庫
是聚合的管理,倉儲介於領域模型和數據模型之間,主要用於聚合的持久化和檢索。它隔離了領域模型和數據模型,以便我們關注於領域模型而不需要考慮如何進行持久化。
只為聚合創建資源庫
聚合和資源庫存在一對一的關係
實現
- 第一步,定義資源庫接口,接口中有put或save類似的方法
- 與面向集合的資源庫的不同點:面向集合的資源庫只有在新增時調用add即可,面向持久化的無論是新增還是修改都要調用save
- 實現類放在基礎設施層,將領域的概念與持久化相關的概念相分離,依賴倒置原則。基礎設施層位與所有層之上,並且單向向下引用領域層
事務管理
- 事務的管理絕對不該放在領域模型和領域層中,事務放在應用層,然後為每個主要的用例創建一個門面,門面的方法是粗粒度的,每一個用例流對應一個業務方法。當用户界面層調用門面中的一個業務方法時,該方法都將開始一個事務。
- 警告:不要過度的在領域模型上使用事務,我們必須慎重的設計聚合以保證事確的一致性邊界。
資源庫VS數據訪問對象(DAO)
- DAO主要從數據庫表的角度看待問題,並且提供CRUD操作。Martin Fowler將DAO相關的設施與領域模型分離開來對待。他指出諸如“表模塊”,“表數據網關”和”活動記錄“這樣的模式應該用於事務腳本中。這些與DAO相關的模式只是對數據庫表的一層封裝。
- 資源庫和"數據映射器"則更偏向於對象,通常被應用於領域模型。
- DAO模式中所執行的CRUD操作都是可以放在聚合中實現的,要避免在領域模型領域模型中使用DAO模式
- 在設計資源庫時我們應該採用面向集合的方式,而不是面向數據訪問的方式,這有助於你將自己的領域當作模型來看待,而不是CRUD操作。
集成限界上下文
領域服務接口位於領域模型層(六邊形內部),實現位為基礎設施層(六邊形外部,即端口和適配器所在位置)。
應用服務
應用服務是用來表達用例和用户故事(User Story)的主要手段。
應用層通過應用服務接口來暴露系統的全部功能。在應用服務的實現中,它負責編排和轉發,它將要實現的功能委託給一個或多個領域對象來實現,它本身只負責處理業務用例的執行順序以及結果的拼裝。通過這樣一種方式,它隱藏了領域層的複雜性及其內部實現機制。
應用層相對來説是較“薄”的一層,除了定義應用服務之外,在該層我們可以進行安全認證,權限校驗,持久化事務控制,或者向其他系統發生基於事件的消息通知,另外還可以用於創建郵件以發送給客户等。
應用層作為展現層與領域層的橋樑。展現層使用VO(視圖模型)進行界面展示,與應用層通過DTO(數據傳輸對象)進行數據交互,從而達到展現層與DO(領域對象)解耦的目的。
總結
談談我對 DDD 的理解,我覺得 DDD 不像一門技術,我理解的技術比如高併發、緩存、消息隊列等,DDD 更像是一項軟技能,一種方法論,包含了很多設計理念。
這篇文章寫於去年,所以當時對 DDD 理解的其實還不夠深入,今年做過一些 DDD 的項目,所以現在對 DDD 的理解又加深了幾分。
大家不要認為,掌握了一些概念,以及 DDD 的基本思想,就掌握了 DDD,然後做項目時,照葫蘆畫瓢,這樣你會死的很慘!
只掌握 DDD 表面的東西,其實是不夠的,我覺得 DDD 最複雜的地方,其實是在它的領域設計部分,項目啓動前,你一定要設計各個領域對象,以及它們直接的交互關係。
比如我們之前做過一個項目,因為這塊沒有做好,大家一邊寫代碼,一邊還在思考,這個領域對象該如何構造,嚴重影響開發效率,最後又不得不回退到 MVC 的模式。
不要為了炫技,啥都要搞個 DDD,兩者如何選擇:
MVC:上來就可以開幹,短平快,前期用起來很香,整體開發效率也更高,所以對於緊急,或者不那麼重要的項目,我會直接用 MVC 懟,不好的地方就是,後面會越來越複雜,可能最後就是一坨屎山,但是很多時候,比如老闆進度催的緊,我哪想到那麼多以後呢?
DDD:前期需要花大量時間設計好領域模型,對於一些基礎組件,或者一些核心服務,如果對象模型非常複雜,建議採用 DDD,前期可能會稍微痛苦一些,但是後期維護起來會非常方便。
