

流處理(處理實時數據流)和批處理(處理歷史數據集),曾經是支撐我們實時監控和深度分析的兩大支柱。
但日子久了,問題也來了:它們數據不通、代碼不通、資源不通。
為了同時滿足“秒級響應”和“深度分析”,不得不同時維護兩套系統、寫兩套代碼、存兩份數據。成本高、效率低,還容易出錯。
如今,業務對數據的要求越來越高:
- 報表要從“T+1”變成“分鐘級”,
- 實時數據要立刻用於模型訓練,
- 離線規則要馬上生效於實時風控
這種分離的架構,越來越力不從心。於是,“流批一體”被推到了台前。
它喊出的口號是:告別重複勞動,一套代碼搞定實時和離線!
但它真能解決我們的痛點嗎?還是隻是聽起來很美?大數據架構真的到了必須擁抱流批一體的時候了嗎?看完這篇你就明白了!
一、流處理和批處理是什麼?
要回答「是否需要流批一體」,首先得弄清楚流處理和批處理分別是什麼。
它們是兩種完全不同的數據處理思路,很多企業最初選擇分開流批,是因為兩者的技術特性差異:
- 流處理擅長處理無界、實時的數據流,強調低延遲;
- 批處理則針對有界、靜態的歷史數據集,追求高吞吐。
這種「術業有專攻」的分工,在早期確實降低了技術複雜度。
1. 流處理:處理那些不停產生的實時數據
流處理的核心是:
處理那些源源不斷、沒有終點的數據,而且得快。
具體來説:
- 一是無界,數據來了就停不下來。
- 二是實時,數據剛產生,系統就得馬上處理,延遲通常在秒級甚至毫秒級。
舉個實際的例子:
外賣平台的騎手實時位置追蹤功能,每秒要接收幾千個騎手的GPS座標。
流處理系統要:
立刻算出每個騎手離用户多遠、大概多久能送到,然後把結果推到用户手機上。
這裏最關鍵的就是快——如果處理慢了,超過5秒,用户看到的位置可能就不準了,體驗肯定受影響。
流處理設計的時候就盯着這幾個目標:
- 低延遲
- 高併發
- 容錯性強
2. 批處理:處理那些固定時間段的歷史數據
批處理正好相反,它處理的是有明確範圍、相對靜態的數據集。
具體來説:
- 一是有界,數據有頭有尾,比如一天的所有訂單記錄、一個月的用户行為日誌;
- 二是靜態,系統可以對這些數據做深入、複雜的計算,不用擔心新數據一直進來打擾。

這種處理對時間要求不高:
延遲幾小時甚至一天都沒關係,只要能在次月1號上午前弄完就行。
但有一點必須保證:
結果絕對準確,不能漏算任何一筆訂單。
批處理設計目標很明確:
- 高吞吐
- 強一致性
- 計算精確
3. 傳統架構為什麼要分開
早期大數據架構選擇讓流處理和批處理分開,説白了就是讓合適的工具幹合適的事:
- 流處理擅長快速響應,適合監控、報警、實時推薦這些場景;
- 批處理擅長深入分析,適合做報表、訓練模型、覆盤歷史數據。
這樣一來:
在業務主要靠T+1分析的年代,這種分工效率很高,企業不用為了實時性花太多錢。
二、流批一體到底是什麼?
要説流批一體,得先説説流批割裂的問題。傳統架構裏,流處理和批處理是兩套完全獨立的系統:
- 數據在流處理這邊存在Kafka,在批處理那邊存在HDFS,兩邊都得存一份;
- 業務邏輯也得寫兩遍,流任務用Flink SQL,批任務用Hive SQL。
結果呢?
- 一個是增量累加,一個是全量掃描,經常因為計算方式不一樣而對不上;
- 運維也得分開,兩撥人各管一攤。
而流批一體,本質上是通過重構技術架構,讓流處理和批處理在邏輯、存儲、資源這三個層面實現統一。
最終目的是:
讓企業不用再糾結用流還是用批,而是根據業務場景選最合適的處理方式。
具體怎麼實現?
可以藉助ETL工具FineDataLink,它提供了簡單易用的交互界面,通過拖拽等方式輕鬆實現數據抽取、數據清洗、數據轉換、數據整合、數據加載等多個環節,大大提高了數據處理效率和準確性。
具體來説,流批一體有這麼三個關鍵統一:
1. 邏輯統一:一套代碼,既能處理實時數據也能處理歷史數據
流批一體最核心的是邏輯能複用。
傳統架構裏,算個GMV:
- 實時的得寫一套Flink SQL,基於增量消息一點點加;
- 離線的又得寫一套Hive SQL,掃全量表來算。
結果呢?
這兩套邏輯很容易因為過濾條件、關聯方式不一樣,導致結果差得遠。
但在流批一體架構裏:企業可以用同一套SQL或者代碼定義計算邏輯。
這樣一來:
- 不管是處理剛產生的實時數據(秒級延遲),
- 還是回溯過去的歷史數據(小時或天級延遲),
邏輯都是一樣的,結果自然也能對得上。
2. 存儲統一:一個數據湖或數據倉,同時滿足實時和離線需求
傳統架構裏:
- 流數據存在Kafka,雖然實時性好,但不好長期存,分析起來也麻煩;
- 批數據存在HDFS,雖然穩定,但更新起來不方便。
兩邊的數據要同步,還得靠ETL任務。這樣一來,數據的時效性和完整性很難同時保證。
流批一體架構一般會用湖倉一體的存儲方案:
- 實時數據會以增量日誌的形式寫到湖倉裏,批處理任務直接讀這些實時增量就行,不用再做傳統的ETL;
- 流處理任務想查歷史數據,也能直接從湖倉裏調,不用再依賴Kafka長期存數據。
這樣一來,存儲就統一了,數據流轉也更順暢。
3. 資源統一:彈性調度,讓計算資源跟着需求走
流批分離的時候:
- 得給實時任務預留固定的計算資源,怕延遲太高;
- 還得給批任務留些彈性資源,應對大促這種高峯期,結果就是資源浪費不少。
而流批一體架構靠的是統一計算引擎加彈性調度,打破這種資源分割。
就拿基於Flink的流批一體來説,同一個集羣裏既能跑流任務也能跑批任務:
- 大促高峯期,調度器自動把更多資源分給實時任務;
- 到了夜間低谷期,批處理任務就能用流任務空閒的資源,資源利用率一下子就提上來了。
三、流批一體的三個常見誤區
流批一體聽着是好,但別為了統一而統一。要是盲目推進,很容易掉坑裏。用過來人的經驗告訴你,落地的時候得避開這三個陷阱:
1. 誤區一:換個能同時支持流批的工具≠實現了流批一體
有些企業覺得,只要把技術棧換成Flink這種能同時跑流和批的工具,就算實現流批一體了。
但實際上:
這只是把流批任務從兩套工具搬到了一套工具上,根本沒解決邏輯不一致的問題。
真正的流批一體,得從三個層面融合:
- 數據模型層面,比如統一管理元數據;
- 計算邏輯層面,比如用同一套SQL或代碼;
- 運維體系層面,比如統一監控告警。
2. 誤區二:沒必要分實時優先還是批處理優先
流批一體不是説用流處理代替批處理,也不是反過來,而是看場景選最合適的:
- 比如實時風控,必須要毫秒級的延遲,那肯定得用流處理;
- 但年度財務審計,需要全量數據算得精準,這時候批處理的穩定性就更靠譜。
所以説:
別跟工具較勁,跟業務場景匹配才最重要。
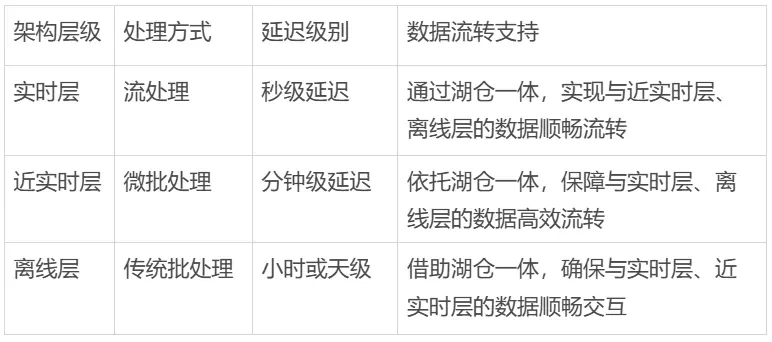
3. 誤區三:沒考慮數據時效性分層的需求
企業的數據,不是所有都得實時處理:
- 最近1小時的數據,可能對實時決策很關鍵,比如促銷活動裏的用户點擊;
- 最近7天的數據,可能更適合做趨勢分析,比如預測商品銷量;
- 超過30天的數據,可能更多用來做長期建模,比如分析用户生命週期。
流批一體架構得支持這種分層處理:
四、大數據架構真的需要流批一體嗎?
回到開頭的問題:大數據架構真的需要流批一體嗎?我的答案是,不僅需要,而且會是未來3-5年企業數據架構的核心發展方向。
為啥這麼説?
因為流批一體不是技術上的妥協,而是業務真的需要:
- 現在企業的業務,已經從過去的事後分析,轉向了實時決策;
- 數據也從原來的支撐工具,變成了核心生產要素。
這時候:
流批分離的架構就成了瓶頸,制約企業的競爭力。
流批一體的價值不在於用一套技術代替另一套,而在於:
通過邏輯、存儲、資源的統一,讓數據從產生、處理到應用的全鏈路裏,既能保持一致,又能高效流轉,最終把數據的價值充分發揮出來。
總結
對企業來説,落地流批一體別為了統一而統一,要選最合適的處理方式,讓技術真正服務於業務目標。
我一直覺得,技術的價值從來不是説用了多先進的工具,而是解決了多少實際問題。
流批一體的本質,就是通過技術融合,讓數據能更高效地驅動業務增長。這一點,相信正在做大數據的你,感受會越來越深。
