

我幹大數據這麼多年,見過太多人被數據傾斜折騰得沒脾氣——
- 明明數據量不算特別大,任務卻死活跑不完;
- 明明集羣資源還夠,節點卻接二連三OOM。
其實不是你技術不行,而是沒把數據傾斜的底層邏輯搞明白。
今天這篇文章,我不整那些虛的,就用最實在的話、最真實的踩坑經歷,帶你從現象到本質,把數據傾斜的解決辦法摸透。
一、數據傾斜的本質是什麼
很多人一遇到數據傾斜,就覺得是“數據太多了”,其實完全錯了。
實際上:
數據傾斜不是數據量的問題,而是數據分佈太不均衡,導致計算資源浪費又不夠用。
你想啊,分佈式計算的核心邏輯,就是把數據拆成小塊,分給不同節點一起算,這樣才快。
比如你有1000萬條用户行為數據:
本來計劃分給10個Reducer,每個處理100萬條,大家一起動手,效率最高。
但實際情況可能是:
800萬條數據的用户ID都是“VIP\_001”,剩下200萬條散在9999個其他ID裏。
結果呢?
處理“VIP\_001”的那個Reducer要扛800萬條,其他Reducer最多才處理22萬條——這就是數據傾斜。
這種情況一出現,連鎖反應馬上就來:
1.耗時翻倍
傾斜的節點處理時間可能是其他節點的幾十倍,本來10分鐘能跑完的任務,最後拖到2小時都算好的。
2.資源浪費
傾斜節點把CPU、內存、帶寬全佔了,其他節點明明有空,卻因為分佈式計算的規則幫不上忙,比如Shuffle時數據必須按Key歸到特定節點,這不就是浪費嗎?
3.任務崩了
嚴重的時候,傾斜節點直接內存溢出,任務重試好幾次都失敗,業務等着要數據,你説急不急?
這裏再跟你強調一句:數據傾斜的本質,就是計算邏輯和數據分佈沒對上。
比如:
你用GroupBy按某個Key聚合,或者用Join按Key匹配,只要這個Key對應的數據量遠超其他Key,傾斜就跑不了。
二、四類最常見的數據傾斜場景
數據傾斜不是憑空冒出來的,不同場景下的傾斜,原因和表現都不一樣。
我把這些年遇到的情況總結成四類,每類都給你講清楚觸發邏輯,再配個真實案例,你對照着就能對號入座。

場景1:GroupBy的時候,某個Key數據特別多
不管你用Hive、Spark還是Flink,只要做GroupBy聚合,就有可能遇到這個問題。
它的邏輯很簡單:
GroupBy會把相同Key的數據都分到同一個節點去算,比如統計用户訂單數,所有“user\_id=123”的數據都會去一個Reducer。
這樣一來:
如果某個Key的數據量佔了全量的5%以上(這是我踩了很多坑總結的經驗閾值),這個節點肯定會成為瓶頸。
你可能會問,為啥會這樣?
其實原理很簡單:
GroupBy是靠“哈希分區+本地聚合”實現的——哈希函數會把相同Key映射到同一個分區,然後這個分區的節點再做聚合。
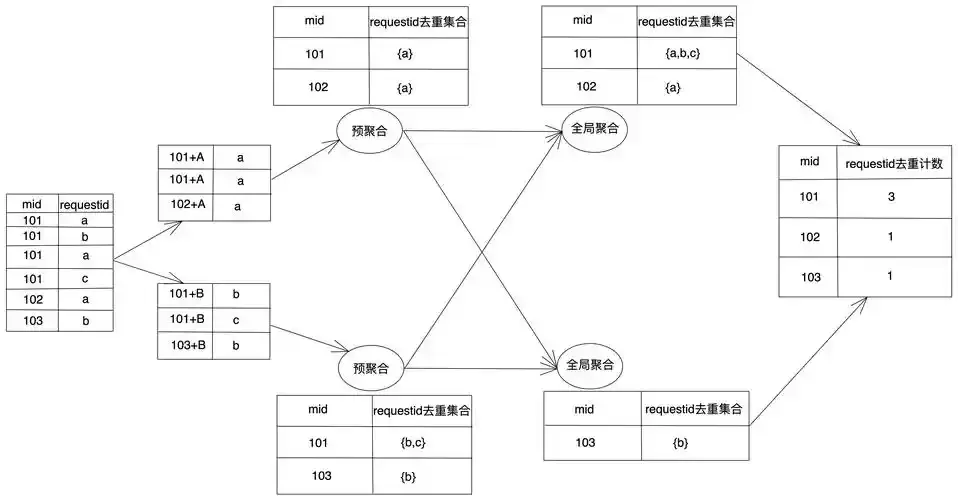
如果業務裏本來就有高頻Key,比如超級用户的日誌、爆款商品的ID,這些Key的數據一紮堆,傾斜就來了。所以説,不是代碼寫得有問題,是數據本身就長這樣。
場景2:Join的時候,遇到“大Key”直接崩
Join操作裏的傾斜更常見,尤其是大表和大表Join,或者大表和小表Join的時候。
它的觸發邏輯是這樣的:
Join要把兩個表裏相同Key的數據拉到一個節點匹配,比如用用户表和訂單表Join,“user\_id=123”的用户數據和訂單數據都會去一個節點。
如果某個Key:
在大表裏有100萬條,小表裏有1000條,那這個節點就要做100萬×1000=10億次匹配,計算量直接炸了。
這裏要跟你拆解下底層原因:
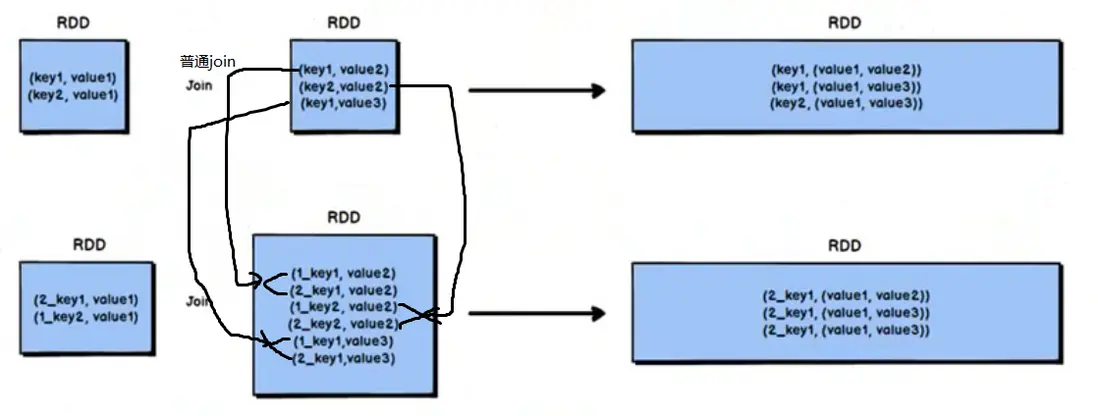
咱們常用的Shuffled Join,核心是“按Key分發數據”——
- Map端把數據按Key分區,
- 再傳到Reduce端匹配。
如果某個Key在兩個表裏的數量乘積超過1億次(這是個經驗值),節點的CPU和內存根本扛不住,不傾斜才怪。
場景3:Shuffle階段,某個分區數據太大
不管是Spark的Shuffle、還是Hive的MapReduce Shuffle,只要分區數據不均勻,就容易出問題。
Shuffle的過程是:
Map端把數據按Key分區,然後傳到Reduce端。
如果某個分區數據量太大,比如超過1GB,麻煩就來了:
- Map端要花大量時間寫磁盤,磁盤IO直接堵死;
- Reduce端拉數據的時候,會佔滿大部分網絡帶寬,其他節點根本搶不到帶寬,數據拉不下來;
- 更糟的是,Reduce端合併數據時內存不夠,頻繁GC不説,還容易OOM。
説白了,Shuffle能不能跑順,全看分區數據均不均勻:
如果單個分區的數據量超過節點能處理的上限(一般是500MB到1GB),整個Shuffle過程都會卡住,表現出來就是數據傾斜。
場景4:計算邏輯裏藏着“隱性傾斜”
這種傾斜最坑人,因為它不是數據分佈的問題,而是計算邏輯本身有“漏洞”。
常見的情況有三種:
- 一是UDF裏對特殊數據做複雜計算,比如用正則匹配超長字符串;
- 二是Window函數按時間分窗口,某個窗口數據突然暴增,比如雙11零點的訂單窗口;
- 三是Filter過濾後,剩下的數據全堆在少數分區,比如過濾掉99%無效數據,剩下1%集中在一個Key上。
這種隱性傾斜難就難:
你光看Key的分佈看不出問題,必須結合計算邏輯去分析。比如同樣是處理一條數據,普通設備指紋一秒能處理100條,異常的一條就要10秒,這不就傾斜了嗎?
三、四步法定位數據傾斜
遇到任務卡殼、失敗,很多人都是瞎調參數、試來試去,浪費時間還沒效果。用過來人的經驗告訴你,只要四步,就能精準定位數據傾斜,不用再摸黑找問題。
步驟1:先看監控,找“拖後腿”的節點
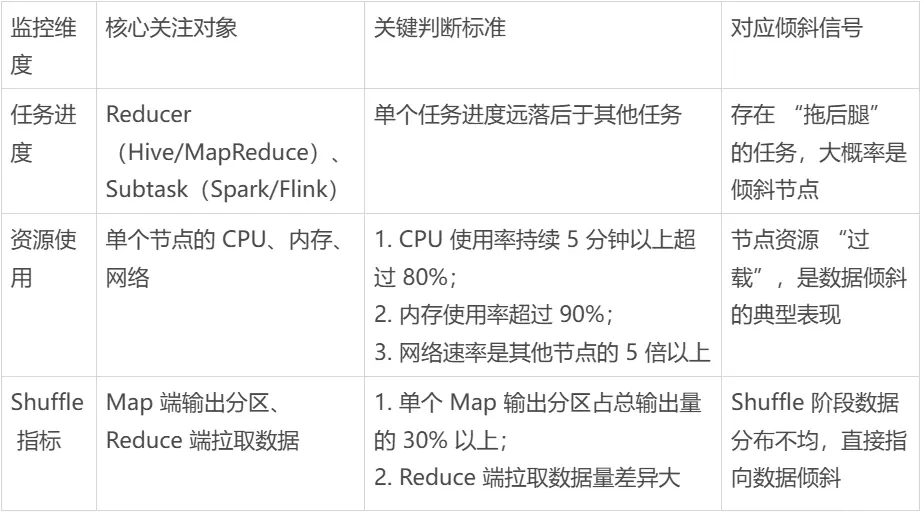
首先登集羣監控平台,比如YARN、Spark Web UI、Flink Dashboard,重點看三個地方:
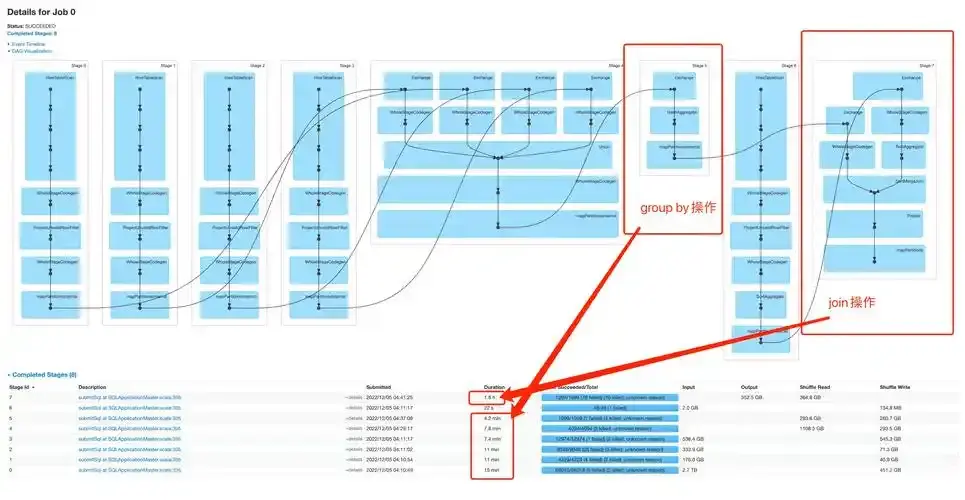
就拿Spark來説:
你打開Web UI的Stage頁面,能看到每個Task的運行時間和輸入數據量。如果某個Task輸入數據是其他Task的10倍,運行時間也翻了10倍,那不用想,就是它傾斜了。
步驟2:查日誌,找異常信息
數據傾斜在日誌裏肯定會留痕跡,不用大海撈針。
重點看三類信息:
- Reducer/TaskManager日誌:有沒有“Reducer X input size: XXXXX records”這種記錄?如果某個Reducer的輸入量遠超其他,那就是它的問題;
- OOM異常:如果日誌裏頻繁出現“Java heap space”,而且都集中在同一個節點,不是隨機崩的,那肯定是這個節點數據太多,內存扛不住了;
- Shuffle超時:有沒有“Fetch failed”“Shuffle read timed out”?這説明Reduce端拉數據太慢,大概率是目標分區數據太大。
我之前查Hive任務的時候:
看到日誌裏寫着“Reducer 5 input records: 1.8億,Reducer 6 input records: 150萬”,當時就確定是Reducer 5傾斜了,直接針對它處理就行,不用浪費時間查其他節點。
步驟3:採樣分析Key的分佈,找到問題所在
光看監控和日誌還不夠,得確認到底是哪個Key導致的傾斜。這時候就要採樣統計Key的頻次,步驟很簡單:

步驟4:復現驗證,排除干擾
找到可疑Key後,彆着急動手改,先驗證一下,避免誤判。
怎麼驗證?
- 單獨提取這個Key的數據,用和原任務一樣的邏輯跑一遍,看看耗時是不是和原任務裏的異常節點差不多;
- 對比這個Key和普通Key的計算邏輯,比如聚合函數、Join操作是不是一樣,有沒有哪裏不一樣導致耗時增加;
- 檢查這個Key對應的數據質量,有沒有髒數據、異常值,比如空字符串、格式錯誤,有時候數據有問題也會導致傾斜。
總結
數據傾斜的本質,是大數據計算中"分而治之"思想與"數據自然分佈"之間的矛盾。它不僅是一個技術問題,更是對數據特徵、業務邏輯、計算框架三者關係的深度考驗。
當你下次遇到數據傾斜時,不妨問自己三個問題:
1.我的Key分佈真的均勻嗎?
2.我的計算邏輯與數據特徵匹配嗎?
3.我的集羣資源足夠應對這種分佈嗎?
通過不斷追問和驗證,你會發現:數據傾斜可以反映你對數據的理解深度,對計算邏輯的掌控能力。
畢竟,真正的高手,不是從不遇到數據傾斜,而是能快速定位、精準破局,並從根本上預防它的發生。