
http HTTP面試題 - HTTP2 面試題

引言
根據網絡上的常見面試題進行收集,基本能應付大部分的場景,HTTP大部分是八股,所以直接開始背書即可。
關聯文章
關聯:HTTP - HTTP2 知識點
基礎問題
為什麼要修改 HTTP?
HTTP 1.X 自出現以來便統治整個互聯網15年以上,但是它的歷史包袱也漸漸變大,高效加載資源的需求日趨明顯,解決隊頭阻塞、頭部臃腫等問題也逐漸被擺上枱面。
HTTP1.X 的版本遺留了兩個比較嚴重的問題:
- 連接過多導致TCP堵塞的控制變得無效化,網絡擁塞造成不必要的帶寬佔用。
- 瀏覽器因為堵塞佔用本不屬於它的資源,同時會出現大量“重複”請求的資源數據。
業界曾經出現了大量方案嘗試解決這些問題,比如:
- spriting 圖片合併
- data: inlining 內聯數據
- Domain Sharding 域名分片
- Concatenation 文件合併
然而無論如何優化,HTTP1.X 協議本身造成的網絡擁塞是無法避免的,作為極客公司的Google為了推進自己的產品和業務需要更加高速的WEB互聯網環境,推進HTTP的改革勢在必行,Google本身也有足夠的用户量和技術實力推進。
推進HTTP/2
IETF的HTTP工作組是HTTP/2的實際推動者,這個工作組維護了HTTP協議,而組織的成員由HTTP實現者、用户、網絡運營商以及HTTP專家等組成。
除開IETF這個非盈利的神奇組織之外,還有各大主流瀏覽器的一些專家比如Firefox,Chrome,Twitter,Microsoft 的 HTTP stack,Curl 和 Akamai 等“大型”項目的工程師,以及諸如 Python、Ruby 和 NodeJS 之類的 HTTP 實現者。
注意HTTP協議是通過“郵件”溝通討論進行完善和制定的,所有的討論雖然構建在W3C的郵件服務商上,但是W3C本身對於HTTP推進沒多大的幫助。
我們可以這麼理解,IETF 是協議的真正推進者,也是協議標準的發佈者,但是具體的協議制定可能來自各種團隊和組織或者可以是個人,協議制定的日常工作是在郵件進行細節討論,當然郵件討論不能是聊閒話,每次郵件討論只有存在產出的才算是合格,於是HTTP2協議就這樣一步步完善並且最終完成。
服務器怎麼樣知道客户端需要 HTTP2 連接?
HTTP2和HTTP的請求協議都是http開頭,普通用户一般是不知道客户端是否支持HTTP的(或者連HTTP是啥都不知道),那麼客户端是如何在地址都是以Http開頭的情況下識別請求是一個HTTP2的連接的呢?
這個知識點考查的是 連接前言,這個前言是 設計如此,無需過多糾結。
“連接前言”是標準的 HTTP/1 請求報文,使用純文本的 ASCII 碼格式,請求方法是特別註冊的一個關鍵字“PRI”,全文只有 24 個字節。
In HTTP/2, each endpoint is required to send a connection preface as
a final confirmation of the protocol in use and to establish the
initial settings for the HTTP/2 connection. The client and server
each send a different connection preface.
The client connection preface starts with a sequence of 24 octets,
which in hex notation is:
0x505249202a20485454502f322e300d0a0d0a534d0d0a0d0a
That is, the connection preface starts with the string "PRI *
HTTP/2.0\r\n\r\nSM\r\n\r\n"). This sequence MUST be followed by a
SETTINGS frame ([Section 6.5](https://datatracker.ietf.org/doc/html/rfc7540#section-6.5)), which MAY be empty. The client sends
the client connection preface immediately upon receipt of a 101
(Switching Protocols) response (indicating a successful upgrade) or
as the first application data octets of a TLS connection. If
starting an HTTP/2 connection with prior knowledge of server support
for the protocol, the client connection preface is sent upon
connection establishment.上面一大段話其實都是圍繞 PRI * HTTP/2.0\r\n\r\nSM\r\n\r\n這一串作為核心,根據HTTP定義規則如果客户端發送了這一串字符,並且通過 SETTINGS 幀告知服務端自己期望HTTPS2 連接,服務端就知道客户端需要的是TLS的HTTP2連接。
在 Wireshark 裏,HTTP/2 的“連接前言”被稱為“Magic”,意思就是“不可知的魔法”。
為什麼叫HTTP2不叫HTTP2.0?
一句話就是就是為了規範化和消除歧義。工作組為了防止HTTP 1,HTTP1.1 這樣的容易誤解的協議名稱做的改進,從HTTP2開始,所有的升級不會出現小版本升級,只有存在巨大更新,才會出現大版本的改動。
為什麼要加入頭部壓縮?
具體可以看Patrick McManus對於頭部壓縮的性能提升的討論:# In Defense of Header Compresson
我們直接從數據可以看到壓縮過後的消息比沒有壓縮的要快出好幾倍。
Test 50ms 100ms 200ms 300ms
1 52 102 202 302
2 52 102 202 302
3 358 808 1401 2108
4 256 506 1006 1542
Test 1 is with the cookie and zlib compression
Test 2 is without the cookie but with zlib
Test 3 is with the cookie and no zlib
Test 3 is without cookie and no zlibHTTP/2 與 SPDY的關係
SPDY是谷歌為了對付HTTP1.X 的性能和網絡阻塞問題的試驗“玩具”,它用上億的用户量兜底一步步改進SPDY的協議,這項技術後來也受到了Mozilla和Nginx等實現者的關注,SPDY後來順水推舟成為了HTTP2的重要改進點。
後續IETF工作組經過討論最終採用了 SPDY/2 作為HTTP2的基礎,在IETF制定HTTP2的過程中,SPDY/2的核心開發團隊都有全程參與,在後續Goole看到SPDY已經被HTTP2完全容納了,於是在2015年直接刪除了SPDY2,全面面向使用HTTP2。
HTTP/2 和 HTTP/1.x 的主要區別是什麼?
在高版本的 HTTP/2 主要區別如下:
- 是二進制的,而不是文本的。
- 多路複用,實現應用層無隊頭阻塞。
- 一個連接可以進行並行處理。
- 使用HPACK算法壓縮頭部來減少開銷。
- 允許服務器主動將響應"推送"到客户端緩存中。
- 請求允許進行服務端推送,雙向併發傳輸。
為什麼選擇 HPACK?
第一個原因,SPDY2 建議無論請求還是回傳響應數據方都使用單獨的GZIP算法進行頭部壓縮(發現效率提升非常明顯)。但是從那時起,一個"重要"的攻擊方式 CRIME 誕生了,這種方式可以攻擊加密文件內部的所使用的壓縮流。
同樣的,TLS壓縮中也存在CRIME攻擊的手段,黑客利用CRIME可以對於壓縮TLS加密報文進行探測,並且可以解密恢復竊取密鑰等信息,同時可以利用JS截取對TLS加密的HTTP傳輸數據,獲取其中的Cookie信息和令牌竊取用户信息成為。
HPACK就是在在 GZIP 的安全性失效額基礎上出現的,SPDY設計了HPACK算法加強Header壓縮的安全性。
順帶一提,TLS 1.3 禁止壓縮加密報文傳輸並且直接廢棄壓縮加密傳輸。
HTTP2 必須加密麼?
雖然RFC文檔沒有明確要求HTTP2需要TLS加密,但是要知道主流瀏覽器大多都不支持不加密的HTTP2,所以HTTP2是理論上的自由選擇加密,實際上的“加密連接”。
HTTP/2 可以擴展新字段嗎?
HTTP/2 雖然在語法上做了很多改變,但是基本的報文結構是沒有變的,如果傳輸新的字段或者傳輸新的類型,那麼HTTP的前後兼容就會十分麻煩,這也是HTTP2沒有在結構上做根本性改變的原因。
為了讓使用者可以從HTTP1過渡到HTTP2,HTTP做了許多隱藏操作,比如連接前言,遵照HTTP協議請求頭。
現實情況是HTTP2出現之後至今這麼多年,本應該是8、90% 的普及率,實際只有50%的網站使用,可以看到一個升級協議除非足夠像是TLS1.2那樣足夠吸引人,否則推行起來並不是容易的事情。
此外積極推動HTTP2發展的締造者谷歌本身在宣傳上下的功夫並不是很多。
HTTP2的安全性如何?
HTTP2的本身安全性並不靠譜。具體細節可以看:https://www.rfc-editor.org/rfc/rfc8164,在這裏面簡單描述了一些基本的安全攻擊隱患,比如常見的降級攻擊,HTTP2會把對應的響應字段刪除,再比如服務器控制中使用“Alt-Svc”標頭字段描述整個源的策略,服務器不應該允許用户內容設置或修改此標頭的值等等。
此外廠商推行HTTP2 “要求”和TLS綁定上線的的另一個原因是TLS在當時的很多加密套件和加密方法才能在漏洞,橢圓曲線函數逐漸流行並且日漸成為網絡安全傳輸的必需品,個人看來HTTP2的TLS綁定側面反映了橢圓函數曲線加密的推行需求。
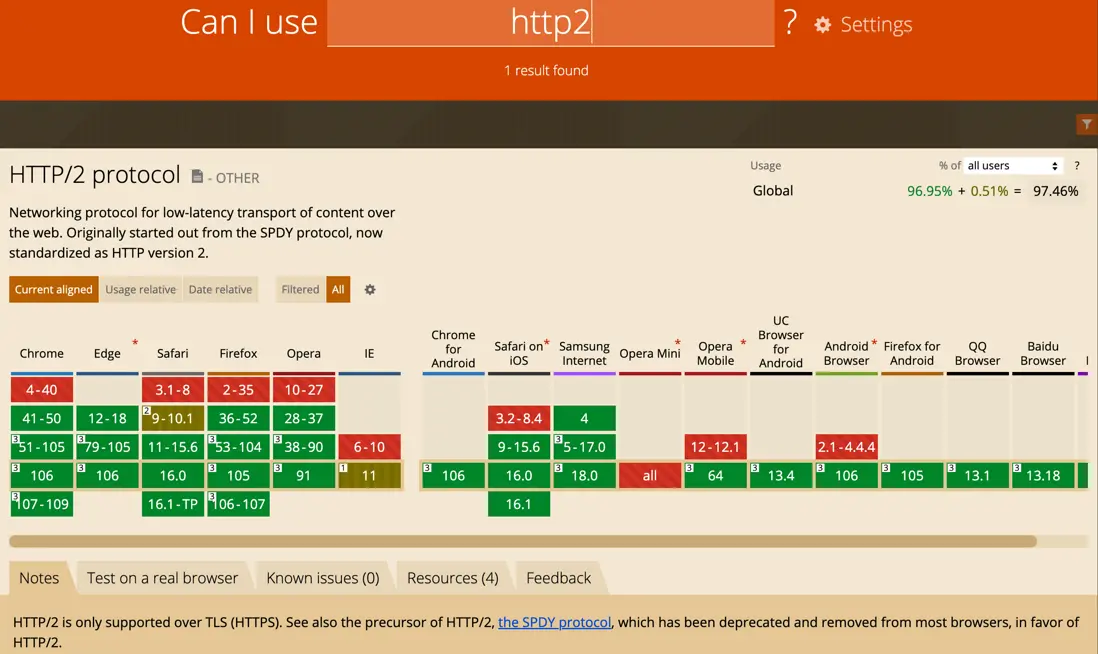
怎麼知道瀏覽器是否支持HTTP2?
下圖只列舉一些主流瀏覽器,可以查看下面這一個網站:https://caniuse.com/http2,HTTP 2 已經公佈很多年了,所以近幾年的主流瀏覽器基本都支持HTTP2。
HTTP/2 會取代 HTTP/1.x 嗎?
答案是不會,至少從HTTP2公佈了近8年之後依然只有50%的網站支持HTTP2,從這一份數據就可以看出HTTP2的普及率雖然不錯但是遠沒有想象中可觀,個人認為更多人在期待HTTP3的普及。
不會完全取代的根本原因是不同的代理服務器以及項目部署的方式不同,不能強制讓所有的服務器升級,HTTP1.X 依然會有很長的運行時間。
HTTP2 還有哪些缺陷?
HTTPS3 改進的都是HTTP2的缺陷,主要的問題如下:
1、沒有解決TCP隊頭阻塞問題,導致如果有丟包請求會等待重傳,阻塞後面的數據,有可能不如HTTP1.1的多個TCP連接 TCP 以及 TCP+TLS 建立連接的延時。
2、多路複用導致服務器壓力上升,沒有限制同時請求數。請求的平均數量與通常情況下相同,但很多服務器業務往往會有許多請求的短暫爆發導致瞬時 QPS 暴增。
3、HTTP2的多路複用容易產生大批量的請求Timeout,由於連接時內存在多個並行的流,而網絡帶寬和服務器資源有限,每個流的資源會被稀釋,也就是説表面上看上去是非常接近的時間實際發送可能超時。
能對比一下 HTTP/2 與 HTTP/1、HTTPS 的相同點和不同點嗎?
相同點:
- 下層都是都是基於TCP協議,HTTP/2雖然沒有規定必須加密,但是瀏覽器會進行要求加密HTTP2,所以我們看到的大部分HTTP2實現服務網站都是加密連接的。
- 基於請求-響應模型,schema還是http或https不會有http2。
不同點:h2使用二進制傳輸消息並且通過HPACK壓縮請求頭實現流多路複用,服務器推送等。
使用h2和h2c劃分加密和非加密請求有什麼區別?
h2使用二進制傳輸消息並且通過HPACK壓縮請求頭實現流多路複用,服務器推送等。h2c優點是性能,不需要TLS握手以及加解密。可以通過curl工具構造h2c請求;
應該怎樣理解 HTTP/2 裏的“流”?
h2的流我們可以看作是實際存在的,因為它是使用幀傳輸數據的,相同 StreamId 的幀組成了消息以及流;通過類比類似於我們把一個積木玩具按照一定的規則拆分為不同的零件,零件可以一起發送過來,組裝人員只需要知道組裝順序即可還原。也可以可以使用HTTP1的Chunked 的思路理解。
動態表維護、流狀態轉換很複雜,你認為 HTTP/2 還是“無狀態”的嗎?
個人認為HTTP2是存在狀態這個概念的。對上層應用來説,Headers頭部壓縮當中動態表維護、流狀態轉換這些操作對它不可見,應用的實現方也不需要為了實現HTTP2傳輸進行手動的狀態維護。頭部壓縮角度來看可以認為是“無狀態”的。
HTTP2引入的幀狀態是幀的進一步體現,具體可以看下面的流狀態流轉圖。
+--------+
send PP | | recv PP
,--------| idle |--------.
/ | | \
v +--------+ v
+----------+ | +----------+
| | | send H / | |
,------| reserved | | recv H | reserved |------.
| | (local) | | | (remote) | |
| +----------+ v +----------+ |
| | +--------+ | |
| | recv ES | | send ES | |
| send H | ,-------| open |-------. | recv H |
| | / | | \ | |
| v v +--------+ v v |
| +----------+ | +----------+ |
| | half | | | half | |
| | closed | | send R / | closed | |
| | (remote) | | recv R | (local) | |
| +----------+ | +----------+ |
| | | | |
| | send ES / | recv ES / | |
| | send R / v send R / | |
| | recv R +--------+ recv R | |
| send R / `----------->| |<-----------' send R / |
| recv R | closed | recv R |
`----------------------->| |<----------------------'
+--------+
send: endpoint sends this frame
recv: endpoint receives this frame
H: HEADERS frame (with implied CONTINUATIONs)
PP: PUSH_PROMISE frame (with implied CONTINUATIONs)
ES: END_STREAM flag
R: RST_STREAM frame
HTTP/2 的幀最大可以達到 16M,你覺得大幀好還是小幀好?
仁者見仁智者見智,認為大幀好的會覺得小幀需要很多額外的頭信息有數據冗餘。 而認為小幀比較好則覺得小幀符合大部分常見的業務,當然如果在某些特定場景裏比如下載大文件可以適當加大。
HTTP2頭字段有什麼特殊規定?
這個問題個人有些感觸,過去個人碰到過CONTENT-TYP、Content-Type、 content-type這樣的請求頭部,因為HTTP1.X對於頭字段寫法很隨意,HTTP2 為了避開這些問題所有設置所有的頭字段必須小寫。具體看下面的RFC文檔描述:
Just as in HTTP/1.x, header field names are strings of ASCII
characters that are compared in a case-insensitive fashion. However,
header field names MUST be converted to lowercase prior to their
encoding in HTTP/2
就像在 HTTP/1.x 中一樣,標頭字段名稱是 ASCII 字符串
以不區分大小寫的方式比較的字符。 然而,
標頭字段名稱必須在其之前轉換為小寫
HTTP/2 中的編碼隨着 http2 的發展,前端性能優化中的哪些傳統方案可以被替代
- 雪碧圖
- 資源文件合併
- 域名發散
- 資源內聯
http2 中 Stream 與 Frame 是什麼關係?
- Stream 為 Request/Response 報文的雙向通道,一個完整資源的請求與相應是一個 stream,特殊的 stream 作為 Settings、Window_Update 等 Frame 發送的通道
- Frame 為 http2 通信的最小單位,有 Data、Headers 等,一個 Stream 包含多個 Frame,如一條 http 請求包含 Header、Data Frame 等
實現細節問題
Http2 中 Server Push 與 WebSocket 有什麼區別?
- HTTP2 Server Push,一般用於服務器解析
index.html同時推送JPG/JS/CSS等資源,而避免了服務器發送多次請求。 - websocket,用於服務器與客户端手動編寫代碼去推送進行數據通信。
談談 HTTP/2 如何解決“隊頭阻塞”問題
先説一下結論:HTTP2 解決了應用層的的隊頭阻塞,但沒有解決TCP隊頭阻塞問題,我們可以認為HTTP2的隊頭阻塞很像是把管道化的概念實現的更好。
首先是HTTP1.X的隊頭阻塞問題,HTTP1在瀏覽器中的同一域名的併發連接數有限,如果連接數超過上限,排在後面的連接就需要等待前面的資源加載完成,有時候出現的瀏覽器空白並且一直“轉圈”也是如此。
各大服務網站的解決方式是使用資源分割的方式,配合多域名和主機進行多個IP避開瀏覽器單個域名的限制,同時結合CDN加速請求。但是這樣做需要分片多個TCP請求,TCP的連接請求的資源消耗比較大。
前面內容我們知道了,HTTP 2 通過改寫HTTP數據交互方式為二進制,使用二進制幀的結構實現了應用層的多路複用,所有的二進制幀可以組成流並行可以跑在一個TCP連接上面,每個Stream都有一個唯一的StreamId,通過每個幀上設置ID(流標識符)在雙方向上完成組裝來還原報文,接收方需要根據ID的順序拼接出完整的報文。
應用層上的隊頭阻塞是解決了,為什麼説沒有解決TCP隊頭阻塞?
我們需要明確HTTP本身是不具備數據傳輸能力的,雖然HTTP2識別數據和響應數據的方式變了,但是運載數據的還是TCP協議,而TCP協議實際上根本不認識什麼HTTP數據,也不知道什麼流,它只負責保證數據的安全傳輸。
在一個可靠的網絡中,併發傳輸和配合沒什麼問題,HTTP和TCP互相不認識對方也不打緊,但是問題就出在現代社會的網絡環境通常是頻繁切換的,網絡不暢事情時有發生。
在不穩定的網絡傳輸中很有可能出現TCP數據傳輸阻塞問題,假設A網站要給B用户一個CSS文件,HTTP知道要被拆分為三個獨立資源的包,按照ID連起來拼成完整的數據。此時如果數據包1和3都傳輸過去了,但2在傳輸過程突然出現丟包,此時接收方組裝的時候發現ID不連續,這時候是不能夠把1後面的數據包3傳出去的,TCP的處理方式是將數據包3保存在其接收緩衝區(receive buffer)中,直到它接收到數據包2的重傳副本,然後重新拼出完整的文件再返回給上層應用,HTTP拼接然後才能給瀏覽器(這至少需要往返服務器一次)。
在HTTP1.X中如果出現上面TCP隊頭阻塞情況,可以通過直接丟棄原有的TCP開新的TCP連接解決問題,雖然開銷很大但是至少可以確保傳輸在正常進行。
而HTTP2在這種情況下就開倒車了,因為HTTP2的理念是一個TCP連接,所以只能通過等待TCP連接重傳來解決丟包的問題,這種情況下整個TCP連接都要阻塞,如果是大文件傳輸,這種體驗會更加糟糕。
結論:
TCP 協議本身的缺陷加上HTTP2一個TCP連接設計,HTTP2的TCP層隊頭阻塞問題十分顯著。HTTP1.X在解決TCP隊頭阻塞雖然笨,但是實際體驗要比HTTP2好得多。
以上這就是TCP的隊頭阻塞問題。順帶提一句HTTP3 通過了QUIC協議替換掉TCP協議,徹底實現了無隊頭阻塞的HTTP連接。
簡單講解一下http2的多路複用
HTTP1.X不支持多路複用。同一個域名併發請求會因為瀏覽器限制在6-8左右,多餘連接會全部阻塞,過去的解決辦法是使用多域名和CDN以及緩存服務器加速HTTP1.X。
HTTP1.X的多路複用嘗試是管道化,但是它是非常失敗的嘗試,HTTP2.0 將它變得完善和可用。
2.0版本的多路複用指多個請求可以同時在一個TCP連接上併發,主要藉助二進制幀中的標識進行區分實現鏈路的複用;

流標識符號表示幀屬於哪一個流的,上限為2的31次方,接收方需要根據流標識的ID組裝還原報文,同一個Stream的消息必須是有序的。
總的來説HTTP2的多路複用就是:
- 同域名下所有通信都在單個連接上完成,消除了因多個 TCP 連接而帶來的延時和內存消耗。
- 單個連接上可以並行交錯的請求和響應,之間互不干擾(流標識符的存在)。
- 支持雙向推送,但是多路複用會造成帶寬壓力加大。
是否可以在不實現 TLS 的情況下實現 HTTP/2?
可以,但是我不建議這麼幹。在 HTTP2中,“h2”表示加密的 HTTP/2,“h2c”表示明文的 HTTP/2,這個c表示"clear text"。
原因如下:
- 只支持h2c的客户端:需要生成一個針對 OPTIONS 的請求。
- 只支持h2c 的服務器:可以使用一個固定的 101 響應來接收一個包含升級(Upgrade)消息頭字段的請求。在響應中可以對於不支持的版本進行明確的狀態碼拒絕(505狀態碼)。
- 不想要處理HTTP1.X的請求:立即用 REFUSED_STREAM 錯誤碼拒絕 stream,鼓勵客户端使用HTTP2 進行重試。
使用明文需要雙方向的兜底操作,並且服務實現方通常只能把控服務端這一塊,那麼還不如直接強制用TLS而直接用HTTPS請求來的直接,非TLS請求的提示在瀏覽器的體驗好很多。如果是希望用户儘可能使用HTTP2,則可以使用第三種方案。
簡單説一下HTTP/2
答案:[[HTTP - HTTP2 知識點]]
詳細內容這裏不做過多展開,因為HTTP2實現天翻地覆,展開講又是一篇長文,回答問題主要針對下面的知識點:
- 兼容HTTP1
- 應用層隊頭阻塞解決
- 併發傳輸
- 多路複用
- 二進制幀
- 服務器推送
- HPACK/頭部壓縮
- 請求優先級
關聯:[[HTTP - HTTP2 知識點]]
HTTP/2 連接需要 TCP_NODELAY 麼?
首先看一下TCP對於 TCP_NODELAY 的描述。
If set, disable the Nagle algorithm. This means that segments are always sent as soon as possible, even if there is only a small amount of data. When not set, data is buffered until there is a sufficient amount to send out, thereby avoiding the frequent sending of small packets, which results in poor utilization of the network. This option is overridden by TCP_CORK; however, setting this option forces an explicit flush of pending output, even if TCP_CORK is currently set.
這個參數實際上就是Nagle算法的開關,Nagle算法是在過去帶寬和網絡通信緩慢的情況下設計的優化手段。
Nagle算法是時代的產物,因為當時網絡帶寬有限,簡單理解它做的事情就是把接受到的網絡資源不會進行傳輸而是先放到緩衝區緩衝,等到到達一定的數量再一次性發出去,當然同時也會設置一個定時器,如果緩存區一直不滿,到了定時的時間同樣一併發出,這樣可以提高用户的使用體驗。
現代的網絡環境遠沒有以前那麼貧瘠和昂貴,目前TCP/IP協議棧的設置已經默認把TCP_NODELAY=1(關閉),但是並不是説這個算法完全派不上用場,有時候因為單個流的大數據量下載依然有可能派上用場,
避免保持 HPACK 狀態?
可以通過發送一個 SETTINGS 幀,將狀態(SETTINGS_HEADER_TABLE_SIZE)設置到 0,然後 RST 所有的流,直到一個帶有 ACT 設置位的 SETTINGS 幀被接收。
為什麼 HPACK 中有 EOS 符號?
HPACK用的是霍夫曼編碼,為了防止黑客利用字符空隙進行攻擊,同時出於CPU處理效率考慮,會通過填充字符串的方式對於字節進行對齊,所以任意字符都有可能會有0-7個位的填充操作。
HPACK 的設計允許按字節比較霍夫曼編碼的字符串,並且填充的時候要求使用EOS符號,同時根據霍夫曼編碼的定義字符串數據:字符串文字的編碼數據。如果 H 為“0”,則編碼數據是字符串文字的原始八位字節。如果H 為 '1',則編碼數據是字符串文字的 Huffman 編碼。
0 1 2 3 4 5 6 7
+---+---+---+---+---+---+---+---+
| H | String Length (7+) |
+---+---------------------------+
| String Data (Length octets) |
+-------------------------------+為了證實上面的論述,我們可以直接閲讀 https://datatracker.ietf.org/doc/rfc7541/ 這部分內容,裏面存在EOS和霍夫曼編碼的一些細節討論。
由於霍夫曼編碼的數據並不總是以八位字節邊界結束,在它之後插入一些填充,直到下一個八位字節邊界。至防止此填充被誤解為字符串的一部分文字,代碼的最高有效位對應於使用 EOS(字符串結尾)符號。
解碼時,編碼數據末尾的不完整代碼是被視為填充和丟棄。填充嚴格更長超過 7 位必須被視為解碼錯誤。填充不是對應於 EOS 代碼的最高有效位符號必須被視為解碼錯誤。霍夫曼編碼的字符串
包含 EOS 符號的文字必須被視為解碼
錯誤。
通過上面的討論以及論證,意思已經很明顯了,簡單理解就為了安全性和CPU效率考慮,霍夫曼編碼會,HPACK又是基於霍夫曼編碼進行頭部壓縮的,為了使規範統一要求EOS的符號進行填充EOS符號。
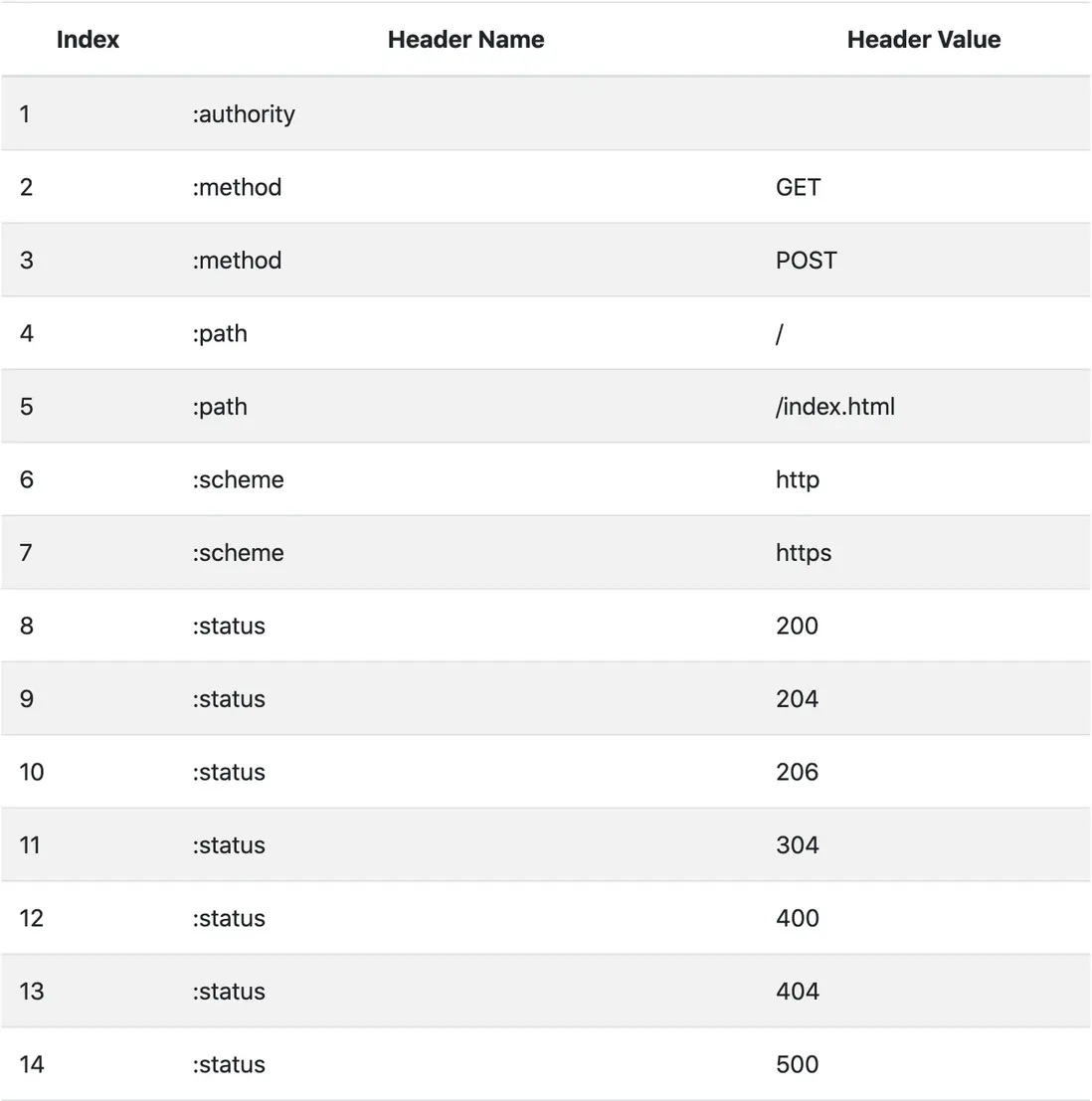
首部壓縮的實現原理是什麼?
主要是“兩表一碼”,動態表,靜態表,哈夫曼編碼。
靜態表負責存儲固定的1-61位索引的常見首部字段,動態表用於一些經常出現變動的請求頭部或者自定義請求頭部,動態表的索引從62開始。
部署問題
如果 HTTP/2 是加密的,我該如何調試?
簡單的方法是 NSS keylogging 與 知名的Wireshark 插件(包含在最新開發版本中)結合使用。這個方法對 Firefox 和 Chrome 均以及常見主流瀏覽器可適用。
如何使用 HTTP/2 服務器推送
服務器推送允許服務器無需等待客户端連接就可以向服務器推送數據,某些時候可以改善用户的使用體驗,比如大帶寬延遲的產品,為了儘可能減少網絡連接傳輸上花費的時間。
根據請求內容變化而變化請求資源是不明智的,通常會造成緩存失效,詳細情況可以查看 RFC 7234 的第 4 節
為了確保資源能夠被正確接收,最好的處理方式是使用內容協商機制,使用 accept-encoding 報頭字段的內容協商受到緩存的廣泛尊重,但是可能無法很好地支持其他頭字段。
更多面試題
通俗圖解HTTP面試題
http常見面試題總結 | 大廠面試題每日一題 (shanyue.tech)
