

DORA 2025 報告指出:AI 採用率上升可能伴隨吞吐與穩定波動,根因在於交付基本功與治理護欄沒跟上。本文用 DORA×SPACE 給 PMO 一套 AI 研發效能度量路線圖:先對齊口徑,再做可對照試點,最後規模化治理,並説明如何把 AI 放進研發管理流程、跑成持續改進閉環。
閲讀本文你將獲得:
- 一套可複用的 AI 研發效能度量指標體系:DORA(結果)× SPACE(機制)
- 一條從 0 到規模化的 PMO 路線圖(含試點實驗與護欄)
- 一張“症狀—機制—指標”映射思路,避免只談使用率與工時
- 一個“把 AI 放進流程”的落地方式:以 ONES Copilot 為例(不綁定工具,可替換)
AI 研發效能度量、DORA、SPACE 到底是什麼
1. AI 研發效能度量是什麼?
一句話:用可驗證的數據衡量“AI 是否讓交付更快更穩、更可持續”,並據此驅動改進。它不等於“AI 使用次數”,也不等於“節省工時”,而是把 AI 放進端到端交付系統,衡量系統結果與系統機制。
2. DORA 四項指標(軟件交付性能)
DORA 給出衡量軟件交付結果的“四項關鍵指標(Four Keys)”。
- 部署頻率(Deployment Frequency)
- 變更前置時間(Lead Time for Changes)
- 變更失敗率(Change Failure Rate)
- 故障恢復時間(Time to Restore Service)
3. SPACE 五維(開發者生產力)
SPACE 強調:生產力不能用單一指標定義,需要從五個維度組合觀測:滿意度與幸福感、績效、活動、溝通協作、效率與心流。
總結一下,從治理語言翻譯:DORA 看“交付結果”,SPACE 解釋“為什麼結果變成這樣”。
方法論:PMO 的 DORA×SPACE 路線圖(從0到規模化)
我在不少企業的覆盤會上聽過類似對話:研發説“寫得更快了”,測試説“迴歸更重了”,運維説“變更更頻繁但故障沒少”,而 PMO 最難回答的是:“領導問 ROI,我們只剩使用次數。”
很多時候,問題不在 AI,而在落地方式——把 AI 當成 IDE 插件,只能優化局部;PMO 關心的是端到端交付系統。更有效的做法,是把 AI 放進研發管理流程裏:讓它落在“工作項、文檔、動態總結、項目數據洞察”這些可治理、可追溯的對象上。比如 ONES Copilot,就是圍繞這些對象提供智能創建工作項、文檔生成、總結動態、篩選查找與數據洞察等能力,並強調透明、負責、可控的原則。
路線圖總覽(一屏版)
- 對齊目標與邊界
- 建立指標字典(DORA×SPACE×AI三層)
- 試點做成實驗(基線/對照/護欄/停機條件)
- 規模化治理(權限、透明追溯、質量門禁)
- 變成持續改進引擎(洞察→決策→行動閉環)
第 1 階段:對齊目標與邊界(2–4 周)
AI 不是“買工具項目”,而是“交付系統再設計項目”。PMO 先把三件事寫清楚:
北極星目標(建議一條就夠):例如,在不提高變更失敗率的前提下,將核心服務 Lead Time 縮短 30%。
- 度量對象邊界:按服務/產品線拆分,避免大盤混算。
- AI 治理邊界(先立護欄):把“責任歸屬、權限控制、透明追溯”寫進章程。
ONES Copilot 的原則表述(透明優先、負責、可控、人類監督與審查)很適合直接轉譯成 PMO 的治理條款:關鍵輸出必須經人類評審,權限遵從所有者設定,動作通過日誌可追蹤。
這一步看似慢,但它決定後面你能不能把數據説清、把風險控住。
第 2 階段:建立指標字典(4–6 周)
AI 研發效能度量最怕“指標很全、口徑在吵”。建議分三層建字典:
2.1 結果層:DORA 四項(速度×穩定)
先把 DORA 四項跑起來,並統一口徑:
- Lead Time 起點/終點:提交→合入→發佈?
- 部署頻率:只算生產成功發佈還是包含灰度?
- 失敗定義:回滾算不算、事故等級如何映射?
DORA 官方對“四項指標”的定義與定位非常清楚,適合作為口徑基準。
2.2 機制層:SPACE 五維(解釋原因)
用 SPACE 解釋 DORA 的變化,優先選“低摩擦、可持續”的採集方式:
- S:雙月脈搏問卷(工具摩擦、認知負荷、信任與焦慮)
- A:PR 週期、評審等待、變更批次
- C:評審往返輪次、跨團隊依賴、返工原因
- E:WIP、等待佔比、被打斷次數
- P:與產品結果/OKR掛鈎,但避免落到個人產出考核
SPACE 的五維定義與“不要用單指標衡量生產力”的主張,是這層的理論底座。
2.3 AI 層:從“使用率”升級為“貢獻率”
把 AI 指標拆成三類,避免“熱鬧但無用”:
- Leading(採用與熟練度):覆蓋哪些工作類型(需求/文檔/排障/測試/編碼)、有效採納率
- Guardrail(風險護欄):AI 相關缺陷佔比、安全告警趨勢、團隊信任度
- Lagging(交付影響):最終回扣 DORA 四項趨勢
如果你的 AI 能把動作留痕,PMO 的口徑工作會輕很多。以 ONES Copilot 為例,它強調所有生成結果可通過日誌與標記追蹤,動作被詳細記錄,並要求關鍵輸出經人類評審才進入協作流程——這類機制能顯著降低“AI 到底改了什麼”的爭議,讓覆盤更像治理而不是辯論。
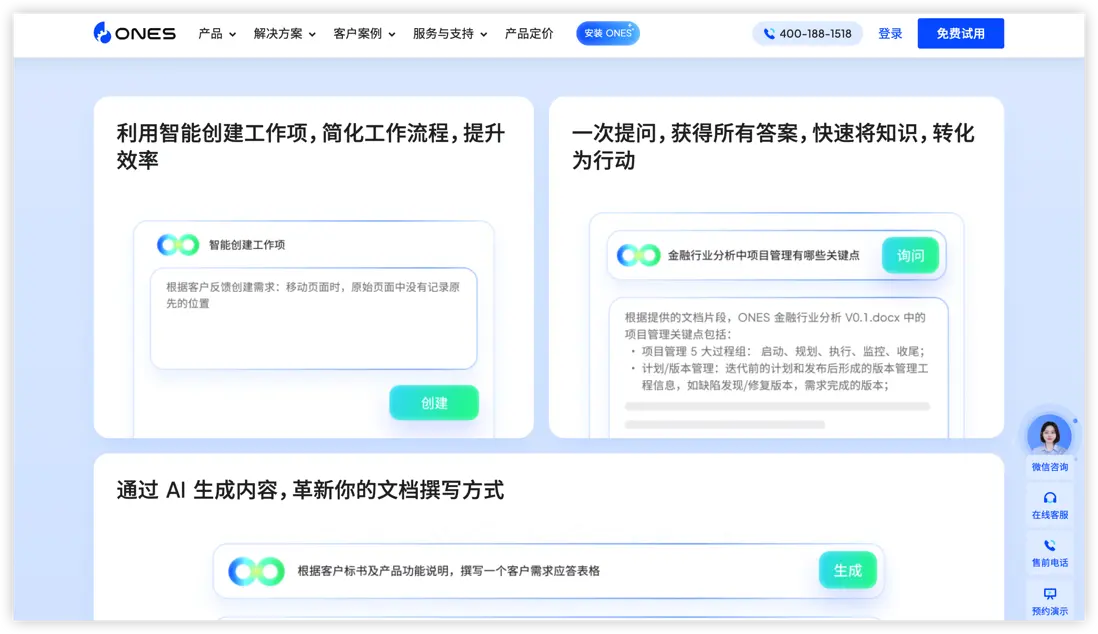
第 3 階段:試點與實驗設計(6–12 周)
- 試點要像實驗:有基線、有對照、有護欄、有停機條件。推薦從“管理鏈路低風險閉環”先贏一仗
- 智能創建工作項:把原始反饋/會議紀要轉成結構化工作項
- 文檔生成與優化:減少知識沉沒,提高可複用性
- 總結動態與相似工單:讓評審與決策基於事實
- 自然語言篩選與查找:降低檢索成本,把信息流做順
這些能力與對象(工作項、文檔、動態、數據洞察)天然更利於 PMO 度量與治理。
試點章程建議包含 5 個硬要素
- 基線期:2–4 周先跑通數據,識別自然波動
- 成功標準:Lead Time ↓,且 CFR 不上升(或可控下降)
- 護欄指標:評審等待不許失控;迴歸缺陷不許飆升
- 停機條件:穩定性連續惡化且無法解釋時,立即收斂範圍
- 覆盤節奏:每兩週一次(DORA 看結果 + SPACE 找原因 + 行動項閉環)
記住:試點不是證明“AI 很強”,而是證明“系統交付更好”。
第 4 階段:規模化與治理(3–6 個月)
規模化的關鍵,不是“全員開通”,而是“護欄前置”。PMO 建議制度化三件事:
- 權限與可控:不同角色能用 AI 寫入哪些字段?哪些輸出必須二次確認?
- 透明與追溯:AI 參與過的內容要能回溯來源與改動
- 質量門禁:自動化測試、評審清單、灰度與回滾預案
DORA 2025 的提醒非常現實:如果沒有小批量與健壯測試機制,改進開發過程不一定帶來交付改善;規模化時更要把這些基本功變成制度,而不是寄希望於“工具自帶魔法”。
第 5 階段:把路線圖做成“持續改進引擎”(長期)
到這一階段,AI 不再是一個項目,而是一種能力:組織學會在不確定性中持續改進。
建議沉澱三張“管理可讀”的圖:
- DORA 結果看板:速度與穩定趨勢
- SPACE 機制看板:摩擦點與瓶頸
- AI 影響圖譜:哪些場景值得加碼,哪些要收斂或加護欄
你會發現,PMO 的工作開始從“追數字”升級為“給洞察、推行動”:用數據把討論從“感覺更忙”拉回到“系統哪裏卡住了、下一步改什麼”。
FAQ:
Q1:AI 研發效能度量最小可行版本(MVM)是什麼?
A:先跑通 DORA 四項趨勢,再用 SPACE 選 3–5 個低摩擦指標解釋波動;AI 指標只做“採用、護欄、交付影響”三層即可。
Q2:DORA 與 SPACE 是競爭關係嗎?
A:不是。DORA 是交付結果,SPACE 是機制解釋;對 PMO 來説是“結果+因果”的組合拳。
Q3:PMO 如何回答“AI 的 ROI”?
A:用“護欄下的交付改善”回答:Lead Time 是否縮短、CFR 是否可控、恢復是否更快;同時用 SPACE 證明摩擦點是否減少,而不是用使用次數。
Q4:怎樣避免 AI 讓穩定性變差?
A:堅持小批量、強測試、質量門禁與可追溯審查;把 AI 輸出納入流程治理,而不是隻在個人側加速產出。
Q5:ONES Copilot 在這套體系裏扮演什麼角色?
A:它是一種“把 AI 放進可治理對象”的落地方式:圍繞工作項、文檔、動態總結與數據洞察,讓 PMO 更容易做口徑對齊、留痕追溯與閉環覆盤;同樣的治理邏輯也可遷移到其他平台。
結尾:讓 AI 成為“可度量的改進資產”
AI 時代,PMO 的價值不是做更漂亮的週報,而是讓組織具備一種能力:用 DORA 看結果,用 SPACE 找原因,用試點實驗驗證槓桿,用治理護欄放大收益。
如果你的組織已在使用 ONES 研發管理平台,那麼 ONES Copilot 圍繞工作項、文檔、動態總結、查找篩選與數據洞察的能力,可以成為你把 AI 研發效能度量跑成閉環的“天然載體”;如果你使用的是其他平台,也同樣可以借鑑這套思路:工具會變,治理邏輯不變——把 AI 放進流程、納入度量、接受審查,才能真正把它變成組織的交付能力。