


圖片來自:https://getboulder.com/boulde...
引
話説,在很長一段時間,程序員依賴了摩爾定律。而在它到頭之前,程序員找到了另一個救命稻草:並行/併發/最終一致。而到了今天,不是 Cloud Native / Micro Service 都不好意思打招呼了。多線程,更是 by default 的了。而在計算機性能工程界,也有一個詞: Mechanical Sympathy,直譯就是 機器同情心。而要“同情”的前提是,得了解。生活中,很多人瞭解和追求work life balance。但你的線程,是否 balance 你要不要同情一下? 一條累到要過載線程,看到其它同伴在吃下午茶,又是什麼一種同情呢? 如何才能讓多線程達到最大吞吐?
開始
項目一直很關注服務響應時間。而 Istio 的引入明顯加大了服務延遲,如何儘量減少延遲一直是性能調優的重點。
測試環境
Istio: v10.0 / Envoy v1.18
Linux Kernel: 5.3
調用拓撲:
(Client Pod) --> (Server Pod)其中 Client Pod 結構:
Cient(40 併發連接) --> Envoy(默認 2 worker thread)其中 Server Pod 結構:
Envoy(默認 2 worker thread) --> ServerClient/Serve 均為 Fortio(一個 Istio 性能測試工具)。協議使用 HTTP/1.1 keepalive 。
問題
壓測時,發現TPS壓不上去,Client/Server/envoy 的整體 CPU 利用率不高。
首先,我關注的是 sidecar 上是不是有瓶頸。
Envoy Worker 負載不均
觀察 envoy worker 線程利用率
由於 Envoy 是 CPU 敏感型應用。同時,核心架構是事件驅動、非阻塞線程組。所以觀察線程的情況通常可以發現重要線索:
$ top -p `pgrep envoy` -H -b
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
41 istio-p+ 20 0 0.274t 221108 43012 R 35.81 0.228 49:33.37 wrk:worker_0
42 istio-p+ 20 0 0.274t 221108 43012 R 60.47 0.228 174:48.28 wrk:worker_1
18 istio-p+ 20 0 0.274t 221108 43012 S 0.332 0.228 2:22.48 envoy根據 Envoy 線程模型(https://blog.envoyproxy.io/en...)。連接綁定在線程上,連接上的所有請求均由綁定的線程處理。這種綁定是在連接建立時確定的,並且不會改變,直到連接關閉。所以,忙的線程很大可能綁定的連接數相對大。
🤔 為何要綁定連接到線程?
在 Envoy 內部,連接是有狀態數據的,特別是對於 HTTP 的連接。為減少線程間共享數據的鎖爭用,同時也為提高 CPU cache 的命中率,Envoy 採用了這種綁定的設計。
觀察 envoy worker 連接分佈
Envoy 提供了大量的監控統計(https://www.envoyproxy.io/doc...)。首先,用 Istio 的方法打開它:
apiVersion: v1
kind: Pod
metadata:
name: fortio-sb
annotations:
sidecar.istio.io/inject: "true"
proxy.istio.io/config: |-
proxyStatsMatcher:
inclusionRegexps:
- ".*_cx_.*"
...視察 envoy stats :
$ kubectl exec -c istio-proxy $POD -- curl -s http://localhost:15000/stats | grep '_cx_active'
listener.0.0.0.0_8080.worker_0.downstream_cx_active: 8
listener.0.0.0.0_8080.worker_1.downstream_cx_active: 32可見,連接的分配相當不均。其實, Envoy 在 Github 上,早有怨言:
- Investigate worker connection accept balance (https://github.com/envoyproxy...)
- Allow REUSEPORT for listener sockets https://github.com/envoyproxy...
同時,也給出瞭解決方案: SO_REUSEPORT。
解決之道
什麼是 SO_REUSEPORT
一個比較原始和權威的介紹:https://lwn.net/Articles/542629/
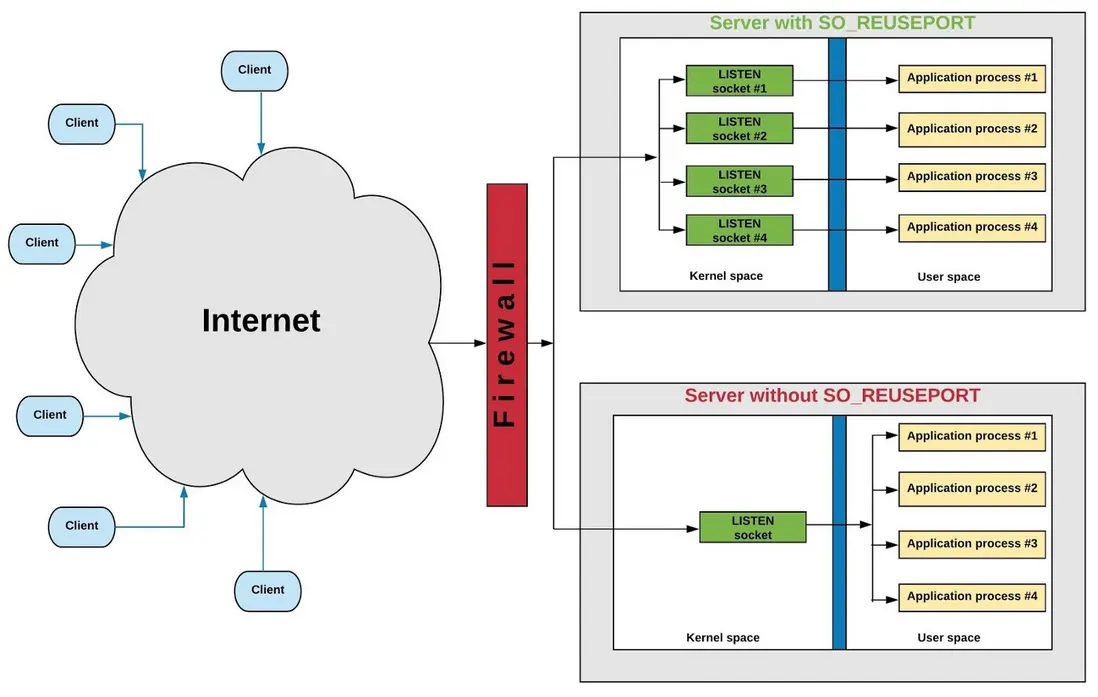
圖片來自:https://tech.flipkart.com/lin...
簡單來説,就是多個 server socket 監聽相同的端口。每個 server socket 對應一個監聽線程。內核 TCP 棧接收到客户端建立連接請求(SYN)時,按 TCP 4 元組(srcIP,srcPort,destIP,destPort) hash 算法,選擇一個監聽線程,喚醒之。新連接綁定到被喚醒的線程。所以相對於非 SO_REUSEPORT, 連接更為平均地分佈到線程中(hash 算法不是絕對平均)。
Envoy Listner SO_REUSEPORT 配置
Envoy 把監聽和接收連接的組件命名為 Listener。作為 sidecar 的 envoy 有兩種 Listener:
-
virtual-Listener,名字帶'virtual',但,這才是實際上監聽 socket 的 Listener。🤣
- virtual-outbound-Listener:出站流量。監聽 15001 端口。由 sidecar 所在的 POD 的應用發出的對外請求,均被 iptable redirect 到這個 listener,再由 envoy 轉發。
- virtual-inbound-Listener:入站流量。監聽 15006 端口。接收由其它 POD 發過來的流量。
- non-virtual-outbound-Listener,每個 k8s service 的端口號均對應一個名字為 0.0.0.0_$PORT 的
non-virtual-outbound-Listener。這種 Listener 不監聽端口。
詳見:https://zhaohuabing.com/post/...
回到本文的重點,只關心實際上監聽 socket 的 Listener,即 virtual-Listener。目標是讓其使用 SO_REUSEPORT,以讓新連接較平均分配到線程。
在 Envoy v1.18 中,有一個 Listener 參數: reuse_port:
https://www.envoyproxy.io/doc...
reuse_port (bool) When this flag is set to true, listeners set the SO_REUSEPORT socket option and create one socket for each worker thread. This makes inbound connections distribute among worker threads roughly evenly in cases where there are a high number of connections. When this flag is set to false, all worker threads share one socket. Before Linux v4.19-rc1, new TCP connections may be rejected during hot restart (see 3rd paragraph in ‘soreuseport’ commit message). This issue was fixed by tcp: Avoid TCP syncookie rejected by SO_REUSEPORT socket.
在我使用的 Envoy v1.18 中默認為關閉。而在最新版本中(寫本文時未發佈的 v1.20.0)這個開關有了變化,默認為打開:
https://www.envoyproxy.io/doc...
reuse_port (bool) Deprecated. Use enable_reuse_port instead. enable_reuse_port (BoolValue) When this flag is set to true, listeners set the SO_REUSEPORT socket option and create one socket for each worker thread. This makes inbound connections distribute among worker threads roughly evenly in cases where there are a high number of connections. When this flag is set to false, all worker threads share one socket. This field defaults to true. On Linux, reuse_port is respected for both TCP and UDP listeners. It also works correctly with hot restart.
✨ 題外話:如果你需要絕對平均分配連接,可以試試 Listener 的配置 connection_balance_config: exact_balance,我沒試過,不過由於有鎖,對高頻新連接應該有一定的性能損耗。
好,剩下的問題是如何打開 reuse_port 了。下面,以 virtualOutbound 為例:
kubectl apply -f - <<"EOF"
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: my_reuse_port_envoyfilter
spec:
workloadSelector:
labels:
my.app: my.app
configPatches:
- applyTo: LISTENER
match:
context: SIDECAR_OUTBOUND
listener:
portNumber: 15001
name: "virtualOutbound"
patch:
operation: MERGE
value:
reuse_port: true
EOF是的,需要重啓 POD。
我一直覺得 Cloud Native 一個最大問題是,你修改了一個配置,很難知道是否真正應用了。面向目標狀態配置的設計原則當然很好,但現實是可視察性跟不上。所以,還是 double check 吧:
kubectl exec -c istio-proxy $POD -- curl 'http://localhost:15000/config_dump?include_eds' | grep -C 50 reuse_port很幸運,生效了 (現實是,因環境問題,我為這個生效折騰了一天🤦):
{
"name": "virtualOutbound",
"active_state": {
"version_info": "2021-08-31T22:00:22Z/52",
"listener": {
"@type": "type.googleapis.com/envoy.config.listener.v3.Listener",
"name": "virtualOutbound",
"address": {
"socket_address": {
"address": "0.0.0.0",
"port_value": 15001
}
},
"reuse_port": true如果你和我一樣,是個強迫症患者,那麼還是看看有幾個 listen 的 socket 吧:
$ sudo ss -lpn | grep envoy | grep 15001
tcp LISTEN 0 128 0.0.0.0:15001 0.0.0.0:* users:(("envoy",pid=36530,fd=409),("envoy",pid=36530,fd=363),("envoy",pid=36530,fd=155))
tcp LISTEN 0 129 0.0.0.0:15001 0.0.0.0:* users:(("envoy",pid=36530,fd=410),("envoy",pid=36530,fd=364),("envoy",pid=36530,fd=156))是的,兩個 socket 在監聽同一個端口。 Linux 再次打破我們的模式化思維,再次證明它是個怪獸企鵝。
調優結果
醜婦還需見家翁,我們看看結果吧。
線程的負載比較平均了:
$ top -p `pgrep envoy` -H -b
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
41 istio-p+ 20 0 0.274t 221108 43012 R 65.81 0.228 50:33.37 wrk:worker_0
42 istio-p+ 20 0 0.274t 221108 43012 R 60.43 0.228 184:48.28 wrk:worker_1
18 istio-p+ 20 0 0.274t 221108 43012 S 0.332 0.228 2:22.48 envoy連接比較平均地分配到兩個線程了:
$ kubectl exec -c istio-proxy $POD -- curl -s http://localhost:15000/stats | grep '_cx_active'
listener.0.0.0.0_8080.worker_0.downstream_cx_active: 23
listener.0.0.0.0_8080.worker_1.downstream_cx_active: 17服務的 TPS 也有一定提高。
體會
我不太喜歡寫總結,我覺得體會可能更有意義。Open Source / Cloud Native 發展到今天,我覺得自己離寫程序編碼越來越遠,更像一個 search/stackoverflow/github/yaml 工程師了。因為幾乎所有需求,均有組件可拿來主義,解決一個簡單的問題大概只需要:
- 清楚找到問題的 keyword
- search keyword,憑經驗過濾自己認為重要的信息
- 瀏覽相關的 Blog/Issue/文檔/Source code
- 思考過濾信息
- 應用和實驗
- Goto 1
- 如以上步驟均不行,提 Github Issue。 當然,自己 fix 做 contributor 就完美了。
我不知道,這是件好事,還是個壞事。search/stackoverflow/github 讓人覺得搜到就是學到,最後知識就變成了碎片化的機械記憶,缺少了體系的、經自己深度消化和考證過的認知,更不用談思考與創新了。
關於續集
下一 Part,我打算看看 NUMA 硬件架構下 ,如何用 CPU 綁定, 內存綁定, HugePages,優化 Istio/Envoy。當然,也是基於 Kubernetes 的 Topology Management 和 CPU / MemoryManager。到現在為止,暫時效果不大,也不太順利。網上有大量的用 eBPF 優化 Envoy 協議棧成本的信息,但我覺得技術上,還不太成熟,也沒看到理想的成本效果。
參考
Istio:
https://zhaohuabing.com/post/...
SO_REUSEPROT:
https://lwn.net/Articles/542629/
https://tech.flipkart.com/lin...
https://www.nginx.com/blog/so...
https://domsch.com/linux/lpc2...
https://blog.cloudflare.com/p...
https://lwn.net/Articles/853637/