

Oracle數據庫升級到19.28版本後,我們的監控就比較頻繁收到一類告警郵件,提示告警日誌中出現下面這類告警信息:
2025-11-26T15:56:10.135762+08:00
Warning: long redo log write elapsed times detected, the LG* process tracefiles have more details
而且出現這類告警的無一例外都是升級補丁的那一批服務器。當然頻率有多有少。我們從下面幾方面進行了分析:
- 首先,Oracle的告警日誌出現這類告警,官方文檔Doc ID 3102584.1中強調了這個是為了解決Bug 36383923,而新增的功能。logwr進程將redo信息寫入聯機日誌文件超過閾值的信息寫入到告警日誌和lgwr進程的trace文件. 它不是一個bug,也不是性能問題. 具體英文如下所示:
"The root cause of these warnings is not a bug or a performance issue, but rather new functionality added in version 19.28 via below Bug fix.
This functionality writes redo write threshold warnings to the alert log file, which was not previously reported."
官方文檔的詳細信息如下所示:
In this Document
Symptoms
Changes
Cause
Solution
Applies to:
Oracle Database - Enterprise Edition - Version 19.28.0.0.0 and later
Information in this document applies to any platform.
Symptoms
On : 19.28.0.0.0 version
The system is intermittently generating a warning message in the alert log after applying the 19.28 July RU patch.The exact error message is:
"Warning: long redo log write elapsed times detected, the LG* process tracefiles have more details"
Changes
Patched to 19.28DBRU
Cause
The root cause of these warnings is not a bug or a performance issue, but rather new functionality added in version 19.28 via below Bug fix. This functionality writes redo write threshold warnings to the alert log file, which was not previously reported.
Bug 36383923 - REPORT LOGWRITER ELAPSED TIME CRITICAL WARNING IN ATTENTION LOG
Solution
This is not a database issue, but rather an enhancement to report slow IO warnings for redo in the alert log file via Bug 36383923.
Previously, these warnings were only written to LGWR tracefiles, but with the 19.28 patch, they are now also included in the alert log.
No specific actions are required to address these warnings in alertlog file. However, you can review the LGWR tracefiles and alert log to understand the frequency and impact of these slow IO warnings on your system's performance.
- 分析了升級補丁前後lgwr進程的trace文件. 發現類似下面這類告警信息都是升級補丁後出現的. 而且分析了好幾個升級補丁的實例都是如此. 下面是其中一個實例的trace文件
*** 2025-11-26T14:31:51.635693+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 2930ms, size 0KB
*** 2025-11-26T14:34:09.008769+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 1489ms, size 0KB
*** 2025-11-26T15:19:36.438765+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 800ms, size 0KB
*** 2025-11-26T15:20:41.873096+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 1069ms, size 0KB
*** 2025-11-26T15:56:10.133693+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 856ms, size 0KB
*** 2025-11-26T16:00:16.141489+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 644ms, size 0KB
*** 2025-11-26T16:01:15.729286+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 554ms, size 0KB
*** 2025-11-26T16:02:17.331034+08:00 (CDB$ROOT(1))
Warning: log write elapsed time 998ms, size 0KB
- Zabbix監控服務器的IO性能指標正常.例如指標"Disk write request avg waiting time(w_await)"都在正常範圍內.沒有出現告警。但是查看指標"sdc: Disk write request avg waiting time(w_await)",通過對比分析,發現從2025-11-05開始,這些指標數據(Disk write request avg waiting time(w_await)和Disk write time(rate))就有明顯上升。而數據庫安裝補丁是在2025-11-04日升級的。確實是安裝完補丁後出現的。這個證據是確實無誤的。而且不是個例,如果是個例,可能還有業務增長等各種因素影響。如果不是個例,那麼可以排除這些可能性!
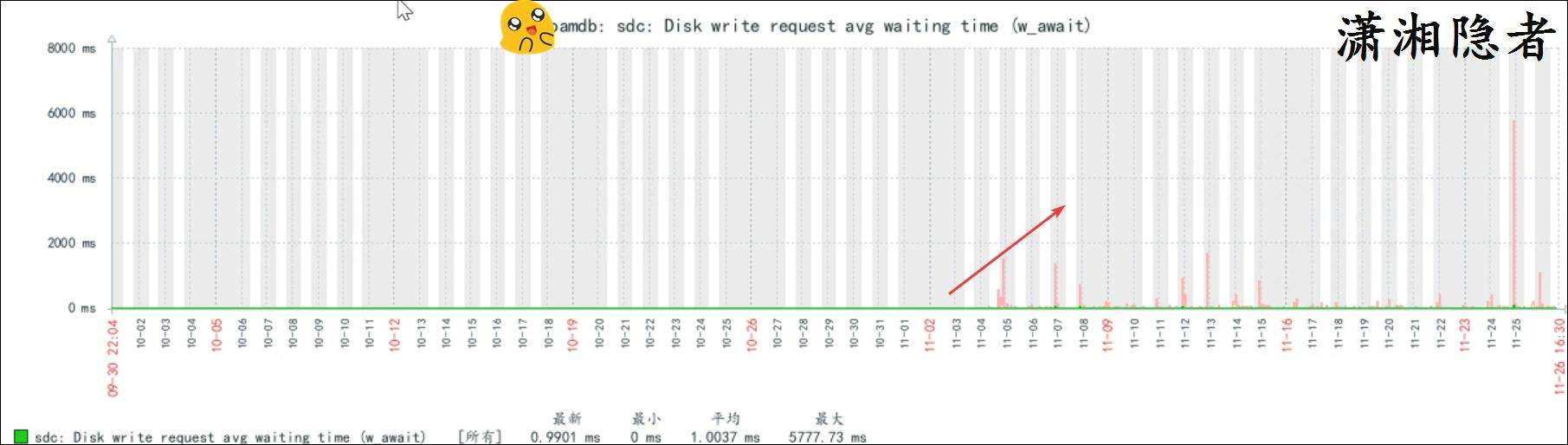
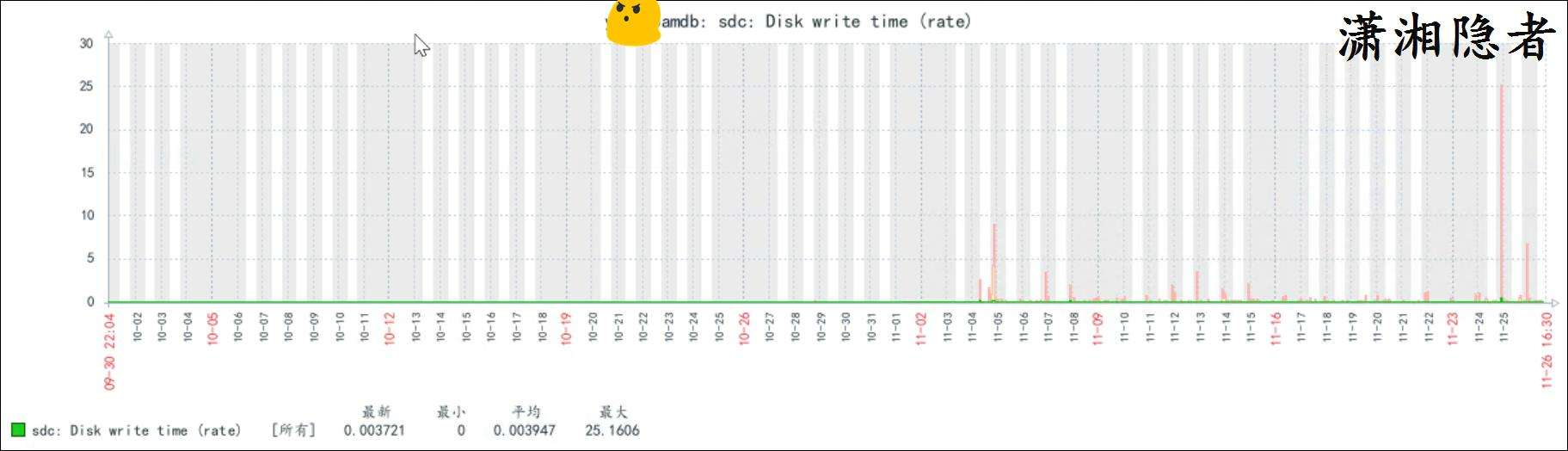
注意:這裏只看sdc設備,是因為redo log位於sdc設備上。
上面圖片可能由於時間範圍拉得太長,對比不是特別明顯,我們將時間範圍縮小,你就能看到磁盤寫的平均等待時間確實在打完補丁後上升了,如下截圖所示
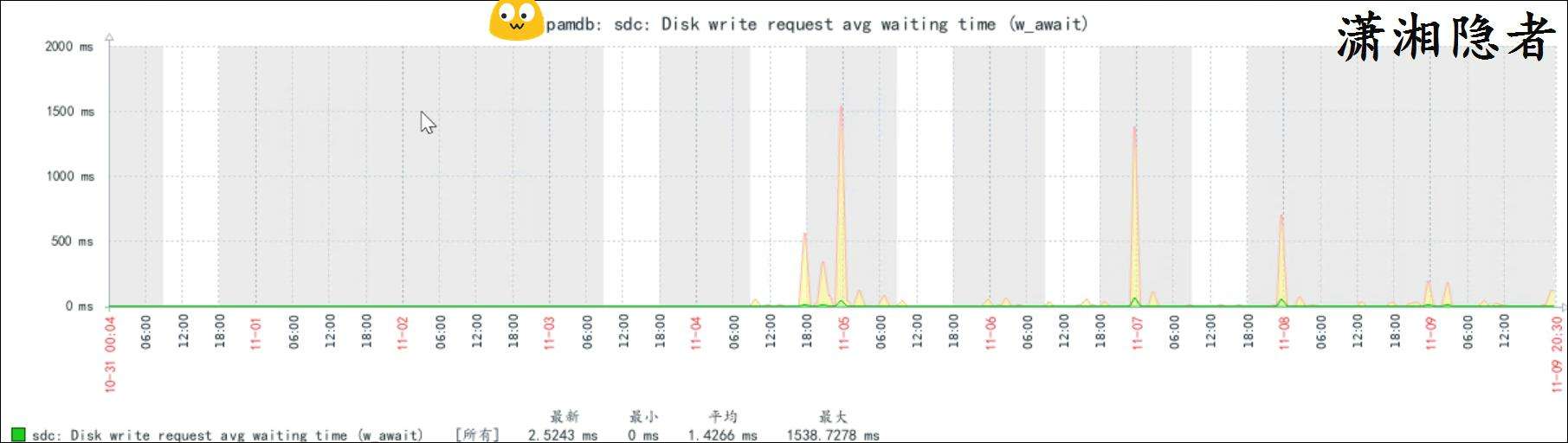
而且這些告警出現的時間基本上和Zabbix中指標"Disk write request avg waiting time(w_await)"數據飆升是一致的。當然也有幾個不一致,可能跟指標採樣頻率有關係。其實是分析了好多案例,基本吻合。 這裏就不一一列舉了,只貼了其中一個例子
那麼這種告警到底是正常還是不正常呢?或者説到底是IO性能問題還是不是呢?官方又説不是性能問題(The root cause of these warnings is not a bug or a performance issue。). 而沒有打補丁前,確實告警日誌和lgwr進程的trace文件幾乎沒有這類告警。但是打完補丁後出現了大量這類告警,你説它不是性能問題吧, 那麼指標"Disk write request avg waiting time(w_await)"數據確實對比打補丁之前有所增長。 而且不是個例, 於是我懷疑數據庫打了Oracle 19.28補丁後會出現性能下降, 但是官方文檔也沒有明確的例子説打了Oracle 19.28補丁會出現性能下降。 而且網上也沒有看到相關網友反饋這個問題。這裏面總有一個邏輯不自洽的問題在裏面,一時間讓我也有點沒有頭緒。雖然沒有找到root cause,但是現象不會説謊。 只是我沒有理清這團亂麻。
如果一眼難以看清真相,那麼我們就捋清線索,一條條自證與排除。
-
首先告警日誌中出現"Warning: long redo log write elapsed times detected, the LG* process tracefiles have more details ",這類告警,確實是打了Oracle 19.28補丁後出現的。確實也是為了解決Bug而新增的功能。這裏沒有什麼爭議與質疑。
那麼出現這個告警是否意味着IO性能下降呢? 官方文檔"The root cause of these warnings is not a bug or a performance issue, but rather new functionality added in version 19.28 via below Bug fix"這句話,一度讓我懷疑自己的英語水平。
它説出現這類告警不意味着性能問題。其實後面我自己認為這個可能要結合上下文語境來看,之前lgwr進程寫redo log可能也有這種時延,只是它不寫入告警日誌。寫入告警日誌不意味着真的就出現了性能下降。這樣理解就對了,如果真的出現IO性能下降,出現這類告警,怎麼不是性能下降呢? 英語畢竟不是母語,況且中文也會話裏有話,或者表達的話。不同人不同的理解,出現存在爭議的點。 -
為什麼打完補丁後,出現IO性能下降? 首先確認事實,打完補丁後,數據庫服務器IO性能確實出現性能下降(僅從指標"Disk write request avg waiting time(w_await)"來看),但是這個是補丁引起的嗎? 我並不能給出證據,或者説我不能給出無可辯駁的鐵證。雖然,打了補丁數據庫服務器有不少出現這類告警,但是也有一些數據庫服務器沒有出現這類告警。
-
綜上所述,這裏出現了一個邏輯不自洽。 雖然打補丁後出現性能下降,但是並不能説就是補丁引起的。那麼肯定還有我遺漏或忽略的線索。 後面下班路上,我腦瓜裏突然想起每次打補丁前,我們會找系統管理員做一個快照(VMware虛擬機),方便出現問題的時候,我們回滾操作。因為快照沒有及時刪除,會帶來IO性能問題。為了驗證猜想,第二天找系統管理員確認後,讓他刪除了快照。
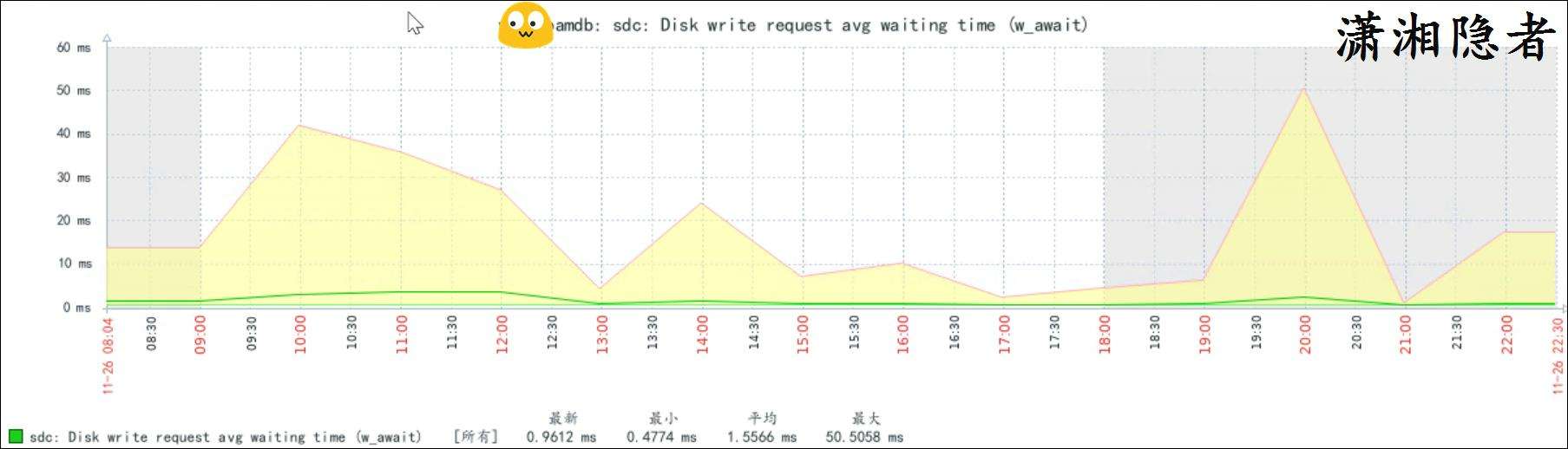
最後通過驗證發現,快照刪除後,lgwr進程的trace文件沒有了寫redo log寫超過閾值的warning信息了,Zabbix監控的也能印證這個。如下截圖所示:
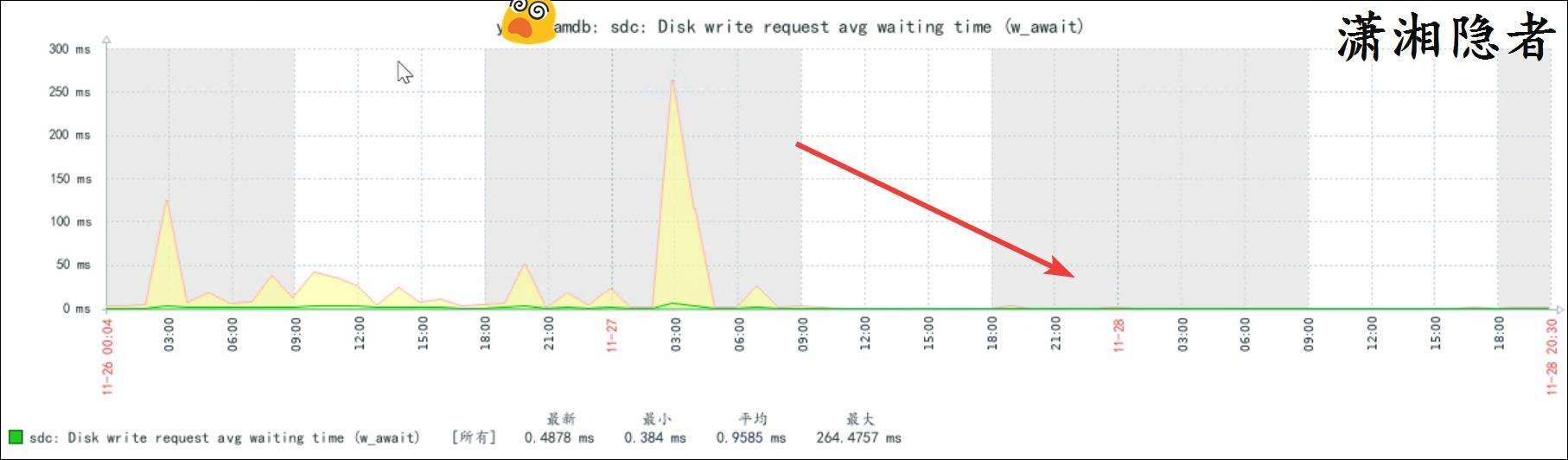
到此可以説真的找到root cause了。因為打補丁前, 我們做了VMware的快照,一般來説這些快照需要保留一段時間,而有時候系統管理員沒有及時刪除這些快照,就引起了IO性能問題,導致lgwr進程寫redo log時出現超過閾值的情況。而由於從Oracle 19.28開始,這些告警會寫入告警日誌,我們的監控程序捕獲並觸發告警。到此,這些推理與證據鏈完整邏輯自洽。
寫到此處,突然又想起了一個笑話:
為驗證蜘蛛的聽覺是否在腳上,科學家做了以下實驗:
先是把一隻蜘蛛放在實驗台上,然後衝蜘蛛大吼了一聲,蜘蛛嚇跑了!
然後割掉蜘蛛的腳,再對它大吼,蜘蛛一動不動;
於是得出結論:蜘蛛的聽覺在腳上
我們做Troubleshooting或分析的時候,也很容易鬧這個笑話。所以,很多時候分析、診斷,推理都必須邏輯嚴謹與邏輯自洽。否則可能會得到一個錯誤的結論。
參考資料
"Warning: long redo log write elapsed times detected" in Alertlog After applying 19.28 July RU Patch (Doc ID 3102584.1)