

本文是翻譯Brent Ozar的這篇文章Updating Statistics Causes Parameter Sniffing, 譯文地址https://www.cnblogs.com/kerrycode/p/19542136。
在我的免費課程如何像引擎一樣思考中,我解釋了SQL Server是如何基於統計信息來生成執行計劃的。表中的數據內容會決定它使用哪些索引、採用索引查找還是全表掃描、分配多少CPU核心、授予多少內存,以及諸多其它執行策略。
當對象的統計信息發生變化時,SQL Server 會認為 “下次有查詢引用這個對象時,我最好生成一個新執行計劃,因為舊執行計劃可能不再適合新的數據分佈”。
這通常是好事,因為我們都希望有一個準確的執行計劃。但這同時也讓你面臨/陷入風險。
每當你更新某張表或某個索引的統計信息時,其實也是在告訴 SQL Server,所有涉及該表的執行計劃都需要根據接下來傳入的參數生成一個全新的執行計劃。正如我在Fundamentals of Parameter Sniffing課程中所討論的,這意味着你更新統計信息次數越頻繁,承擔的風險就越大:你是在刻意釋放執行計劃緩存的一部分,通常是很大一部分,並且對接下來傳入的參數抱有很大的不確定性。
更新統計信息可以生成更優的查詢計劃.
在理想情況下,你應該只有在查詢計劃能從新的統計信息中獲益時,才應該更新統計信息.
為了讓大家理解這一點,我們以Stack Overflow數據庫中的 Users 表為例,並思考一下每一列的內容會以何種方式發生變化,才會對查詢計劃產生影響。
頻繁更新統計數據至關重要的經典場景是使用日期列來記錄當前活動.在數據倉庫中,這意味着加載昨天的新銷售數據。在Stack Overflow的Users表中,類似的是LastAccessDate 列:用户整天都在登錄。假設我們在 LastAccessDate 上有一個索引,並且有一個存儲過程通過該日期範圍來查詢用户信息:
CREATE INDEX LastAccessDate ON dbo.Users(LastAccessDate);
GO
CREATE OR ALTER PROC dbo.usp_SearchUsersByDate
@LastAccessDateStart DATETIME,
@LastAccessDateEnd DATETIME
AS
SELECT *
FROM dbo.Users
WHERE LastAccessDate >= @LastAccessDateStart
AND LastAccessDate <= @LastAccessDateEnd
ORDER BY DisplayName;
GO
當這個查詢運行時,SQL Server 必須決定是否使用該索引,以及為DisplayName列的排序操作授予多少內存。如果我們在前一晚更新了統計信息後,今天有 1% 的用户在白天登錄,
然後我們嘗試運行這個搜索查詢:
-- 假設今天有 1% 的用户登錄
UPDATE dbo.Users
SET LastAccessDate = GETDATE()
WHERE Id % 100 = 1;
GO
EXEC usp_SearchUsersByDate '2020-05-26', '2020-05-27';
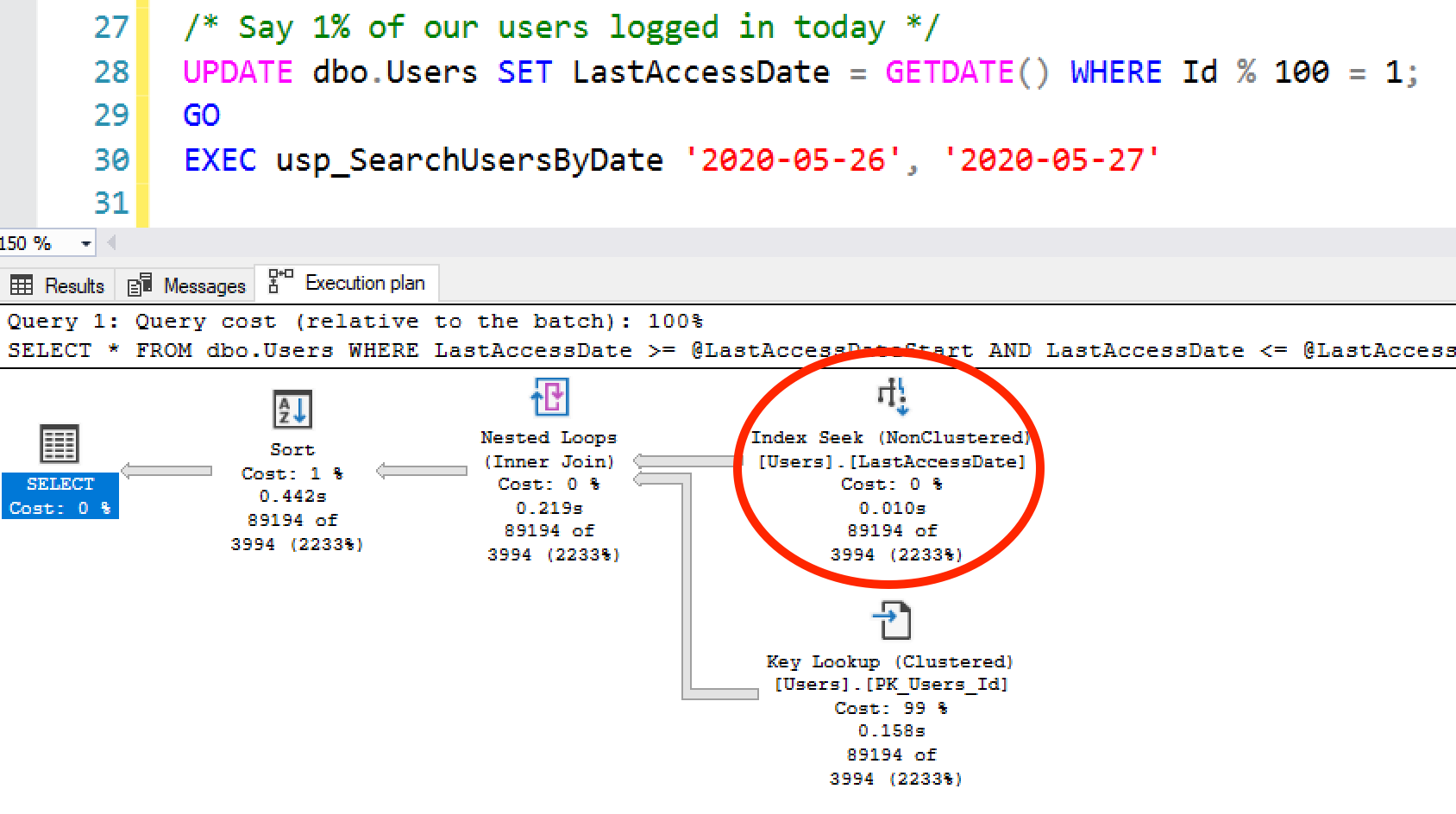
那麼SQL Server很可能無法精準預估查詢的返回行數,因為統計信息更新後,數據又發生了變化。這種預估偏差,可能會導致排序操作的中間結果溢出到磁盤,或者也可能讓 SQL Server 錯誤選擇索引查找,而實際全表掃描的效率會更高.
在上述計劃中,SQL Server 做出了低效的選擇了索引查找 + 鍵查找,結果的數據頁數量比表本身的總數據頁數實際還多。在這種情況下,你確實需要頻繁更新統計信息——而在一個非常活躍的網站上,即便頻繁更新統計信息,統計信息的更新速度也未必能跟上數據變化,無法讓執行計劃精準反映未來幾小時內的表數據情況。這就是人們最終訴諸查詢提示、強制執行計劃,甚至為未來的待入庫數據創建虛擬統計信息的原因。(我自己從沒試過最後這種方法,但覺得這種思路很有意思。)
但對於其他列,頻繁的統計信息更新會適得其反.如果我寫一個查詢,要求 “顯示所有Location 為 San Diego, CA 的用户”,這個數據分佈並不會頻繁變化。當然,隨着表中用户數量不斷增加,查詢的行數預估可能會出現幾行甚至幾百行的偏差,但在數週的時間裏,單個取值對應的數據分佈不會發生大幅變化。對於有多年曆史的成熟數據庫,Location(所在地)列的統計信息即便連續數月不更新,也完全無需擔心。
表內的整體數據分佈不會在短時間內發生太大變化。
但每個查詢的數據分佈卻在不斷變化。
假設我在 Location 上有一個索引,並且有一個存儲過程如下:
DropIndexes;
GO
CREATE INDEX Location ON dbo.Users(Location);
GO
CREATE OR ALTER PROC dbo.usp_SearchUsers
@Location NVARCHAR(100)
AS
SELECT TOP 1000 *
FROM dbo.Users
WHERE Location = @Location
ORDER BY Reputation DESC;
GO
在統計信息更新後,第一次調用該存儲過程時傳入的 Location 參數,會決定當天所有用户執行該查詢的性能表現:
- 如果首次傳入是像印度這樣的用户較多的的地區,那麼所有地區都會獲得並行表掃描,並獲得大量的內存授權。
- 如果首次傳入的是聖地亞哥這類用户數量較少的地區,那麼後續所有執行都會採用單線程的索引查找 + 鍵查找,且僅會被授予少量內存。
因此,在遭遇參數嗅探問題時,最糟糕的做法就是每天更新這張表的統計信息。這樣一來,你每天上班都會面臨 50% 的概率出現全表掃描,還有 50% 的概率出現臨時數據庫(TempDB)數據溢出的問題。每天都會遇到新的性能緊急問題 —— 即便表的實際數據分佈根本沒有任何變化。
對執行計劃緩存有深入研究的工程師,可以通過查詢系統視圖 sys.dm_exec_query_stats 中的 plan_generation_num(執行計劃生成次數)列發現這一問題。每當因統計信息變化等原因導致執行計劃重新編譯時,該列的數值就會遞增。數值越高,説明執行計劃的編譯頻率越高;但同時需要注意,即便 plan_generation_num 的值為 1,也不代表你的數據庫不存在參數嗅探問題。(關於這一點,我會在《精通參數嗅探》課程中深入講解.)
這也是為什麼我會選擇每週更新一次統計信息,除非有明確的理由,否則不會提高更新頻率。在實際工作中,我遇到的參數嗅探問題,遠比日期範圍遞增導致的統計信息失效問題要多。
我更傾向於將每週更新統計信息作為默認策略,這能讓執行計劃緩存更穩定,也能讓工作日的早上少些麻煩。即便發現某類統計信息在一兩天內就嚴重過期,我也不會改為每日更新 —— 而是會先嚐試優化索引和查詢語句,讓 SQL Server 能更輕鬆地生成高速、高效的執行計劃。因為如果為了解決如下這類查詢的性能問題,就選擇每日更新統計信息:
CREATE OR ALTER PROC dbo.usp_SearchUsersByDate
@LastAccessDateStart DATETIME,
@LastAccessDateEnd DATETIME
AS
SELECT *
FROM dbo.Users
WHERE LastAccessDate >= @LastAccessDateStart
AND LastAccessDate <= @LastAccessDateEnd
ORDER BY DisplayName;
GO
那你很可能忽略了一個重要問題:這個查詢本身也極易遭遇參數嗅探問題!
在每日的統計信息更新任務完成後,如果有人恰好傳入一個跨一年(或僅一小時)的時間範圍參數,那麼生成的執行計劃又會再次失效,讓所有用户的查詢性能陷入困境。