

關於流計算
流計算是面向流式數據的計算,即對持續不斷產生的數據流進行實時採集、處理、分析與輸出,最終將處理結果寫入目標表。流計算的核心是 “邊產生數據邊處理”,而非等待數據全部存儲後再批量計算。因此,流計算的一大關鍵優勢就是——能夠極大地縮短從數據產生到獲取洞察之間的時間,在更短時間內挖掘數據價值。
為什麼需要流計算?
一、傳統架構侷限性大
延遲高、吞吐低
傳統批處理延遲>5s,難以應對百萬級 TPS 吞吐,數據延遲導致業務決策滯後,錯失市場機會。
響應慢,缺乏靈活性
靜態數據處理模式難以應對動態業務變化,缺乏實時告警和即時響應能力。
二、實時數據處理需求激增
業務決策實時化
智能製造、智慧能源等領域需在秒級內完成數據清洗、異常檢測並觸發告警,延遲容忍度極低。
數據價值時效性
設備故障預測等場景要求對最新數據即時分析,歷史批處理模式無法滿足業務敏捷性需求。
多系統協同需求
實時處理結果需同步推送至其它業務系統,要求數據通道具備低延遲訂閲能力。
KaiwuDB 的流計算設計理念與架構
一、核心設計理念
✅ 計算 - 存儲融合
摒棄 “存儲 - 傳輸 - 計算” 分離模式,通過 “本地計算” 將流處理邏輯嵌入存儲層,如邊緣節點直接執行振動數據異常檢測(WHERE vibration > 閾值)。
✅ 邊緣 - 雲端協同
根據數據訪問頻率動態調整存儲層級,邊緣節點預處理後僅上傳聚合結果(如每小時均值)。
二、數據處理流程
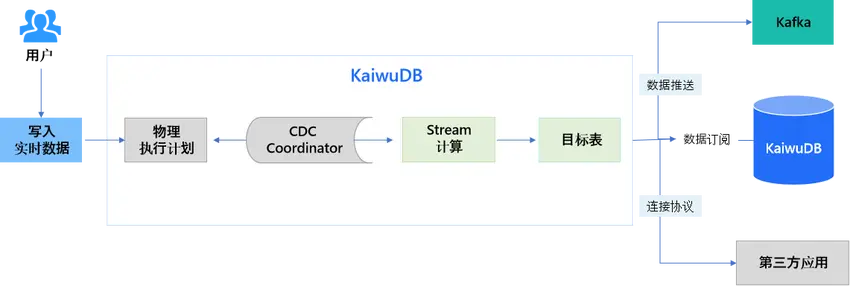
KaiwuDB 使用 SQL 定義實時流變換,當數據被寫入流的源表後,數據會被以定義的方式自動處理,並根據定義的觸發模式向目的表推送結果,替代了傳統複雜流處理系統(如 Kafka、Flink),在高吞吐的數據寫入的情況下,提供毫秒級的計算結果延遲。
KaiwuDB 流計算核心功能
一、觸發模式
• 立即觸發:當有新數據寫入時,就會立即觸發流式計算。
• 窗口函數觸發:實時數據滿足窗口(滑動窗口、會話窗口、狀態窗口)條件,聚合窗口正常關閉並觸發計算。
二、數據處理範圍
支持 where 進行行級條件過濾、標量計算、分組聚合查詢、窗口計算。
三、數據處理策略
• 斷點數據處理策略:當用户啓動一個處於停止狀態的流計算時,系統會檢查是否存在斷點數據(未處理數據)並使用流計算最低水位線標識斷點數據的範圍並進行相應的處理。
• 歷史數據處理策略:用户可通過 PROCESS_HISTORY 參數控制是否處理時序表中的存量數據,默認情況下,流計算只處理任務開啓後新寫入的數據。
• 亂序數據處理策略:用户可以通過 SYNC_TIME 參數指定流計算的亂序數據時間範圍。
• 過期數據處理策略:如果新入庫的數據落入了已關閉的聚合窗口,則稱為過期數據。系統默認丟棄過期數據,用户也可通過將參數設置為 off 實現對對應窗口數據的重新加載並計算。
四、目標端
經過流計算後的處理結果既可以寫入時序目標表,也可寫入目標關係表。
應用場景與價值
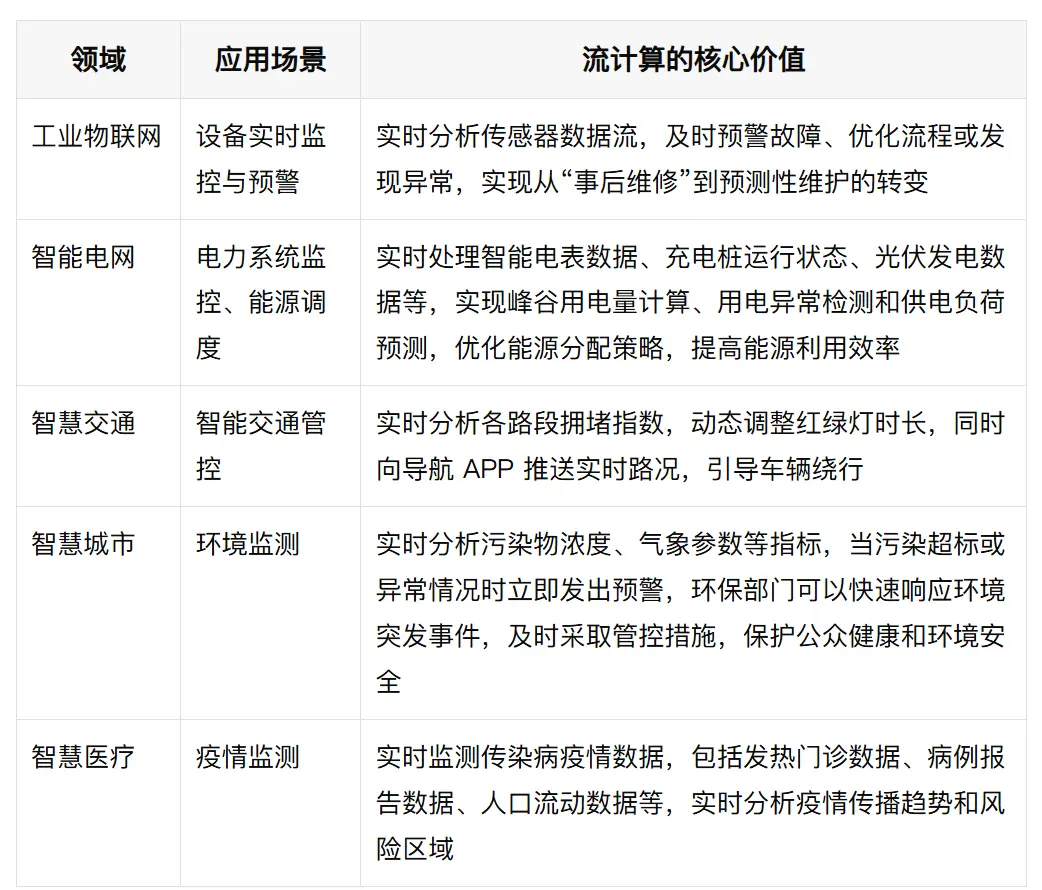
📝 部分典型場景
💡 應用價值
• 數據預處理與降維
入庫前開展全流程數據預處理,通過精準數據清洗(剔除噪聲、修正偏差)、智能插值補全(填補缺失值)、時序聚合降採樣(將秒級高頻數據優化聚合成分鐘級)等操作,既大幅提升數據潔淨度與一致性,為後續分析提供高質量可信輸入,又有效壓縮數據存儲體量、降低計算複雜度,顯著節省硬件存儲與算力資源成本。
• 預計算加速決策
基於業務場景預設的指標定義規則,對流式原始數據進行實時預聚合與中間結果緩存,查詢時直接調用預處理後的聚合結果,無需觸發全量數據重算。這一機制將數據分析模式從傳統 “事後覆盤” 升級為 “事中即時干預”,助力業務決策響應速度從分鐘級壓縮至秒級甚至毫秒級,大幅提升核心業務的決策敏捷性。
• 實時監控與告警
依託流計算持續迭代的計算能力,對持續流入的高頻數據流進行毫秒級連續監測與智能判斷。一旦數據滿足預設閾值規則,或被機器學習模型識別為異常模式,將立即觸發多級告警通知,同時可聯動執行預定義的自動化響應動作,真正實現 “異常發現即行動”,構建高效的異常處置閉環。