

有時,進步難以察覺,特別是當你正身處其中時。而對比新舊資料之間的差異,尋找那些推動變革的信息源,我們就可以清晰地看到進步的發生。在Linux(以及大部分Unix系統)中,都可以印證這一點。
Unix V7 是 Unix 操作系統的一個重要的早期版本,於 1979 年發佈,是貝爾實驗室最後一個廣泛分發的版本。它是第一個真正可移植的 Unix 版本,被移植到了多種平台上,包括 DEC PDP-11, VAX, x86, Motorola 68000 等。Unix V7 的 VAX 移植版本,叫做 UNIX/32V,是流行的 4BSD 系列 Unix 系統的直接祖先。許多老牌的 Unix 用户認為 Unix V7 是 Unix 發展的頂峯。
Unix V7 Research Release 的源代碼可以在 unix-history-repo 這個由 Diomidis Spinellis 維護的項目中找到。如果你想深入瞭解 Unix 的設計原理,可以參考 Maurice J. Bach 的經典著作 The Design of the Unix Operating System,並查看 Research V7 Snapshot 這個分支的代碼庫。

Machines
1974 年,計算機擁有一個“核心”,即中央處理單元。然而,在某些計算機中,這個“核心”已經發生了變化。不再是由多個部件(如算術邏輯單元、寄存器、順序控制器和微碼存儲器)組成的設備,而是一顆單一的集成芯片,單個芯片上集成了數千個晶體管。它們被叫做“小型計算機”。
Kernels
在 Unix 中,我們通過配置頭文件(header file)來處理系統資源。如下圖所示,這裏顯示了頭文件中配置的默認值,數據結構是數組,所示值是相應的數組大小。如果要更改它們,則需要編輯文件,重新編譯和鏈接內核,然後重新啓動系統。

它有一個文件系統緩衝區緩存(file system buffer cache),使用 NBUF(29)個磁盤塊,每個磁盤塊的大小是 512 字節,用來暫時存儲磁盤上的數據塊和 inode,從而加速文件系統訪問。另外還有一個索引節點數組(inode array),它有 NINODE (200)個條目,每個條目對應一個文件的元數據,還可以同時掛載 NMOUNT (8)個文件系統。每個用户最多可以運行MAXUPRC(25)個進程,總共有 NPROC(150)個系統進程。每個進程最多可以打開 NOFILE(20)個文件。
閲讀 Bach 的著作和 V7 源代碼是很有趣的,儘管它們已經完全過時。因為這些源代碼中呈現出的許多核心概念更加清晰,結構更簡潔,有時甚至帶有古老的風格。然而,正是這些概念定義了 Unix 文件系統。V7 Unix 被寫入了 POSIX 標準,之後的每個文件系統都必須遵守它。如果您想了解更多相關示例,請參考 But Is It Atomic?
核心概念
Unix 文件系統的基本概念和結構來自這個系統。其中一些概念甚在現代系統中依然存在。
磁盤由一系列數據塊(block)組成,從第 0 塊開始,一直到第 n 塊結束。在文件系統的開始部分,我們可以找到超級塊(superblock)。它位於文件系統的第 1 塊。超級塊存儲了文件系統的一些基本信息,比如文件系統的大小、空閒塊的數量、空閒索引節點的數量等。當我們執行掛載(mount)系統調用時,系統會找到一個空閒的掛載結構(mount structure),並且從磁盤上讀取超級塊,把它作為掛載結構的一部分。
Inode
內存中的超級塊(in-memory superblock)是磁盤上超級塊的副本,用於加快文件系統的訪問速度。它包含一個 short 類型的字段,用於存儲一個索引節點數組(inode array)在磁盤上的位置。
索引節點(inode)是一個描述文件內容和屬性的結構,文件內容由一系列數據塊(block)組成,每個數據塊的大小是固定的(通常是 512 字節或 1024 字節),文件屬性包含文件名、大小、權限、時間戳等元數據(metadata)。

文件系統中的 inode 數組是一個 short 類型的計數器,它的最大值是 65535,也就是説文件系統中最多隻能有 65535 個 inode。由於每個文件都需要一個 inode,因此每個文件系統最多隻能容納 65535 個文件。
每個文件具有一些固定屬性:
- (2字節)mode,它包含了文件的類型和訪問權限;
- (2字節)nlink,它表示這個文件有多少個名字;
- (2字節)uid,文件的所有者;
- (2字節)gid,文件所有者的組 ID;
- (4字節)size,文件的長度,以字節為單位(定義為 off_t,長整型);
- (40字節)addr 數組,包含了文件的數據塊在磁盤上的地址;
- (3x 4字節)三個時間,atime(訪問時間),mtime(修改時間)和 ctime(所謂的創建時間,但實際上是最後一個 inode 更改的時間)。
總大小為 64 字節。
bmap()
Addr 數組包含 40 個字節,但它存儲了 13 個磁盤塊地址,每個地址使用 3 個字節。這對於 24 位來説非常適用,或者説對應於 16 個大小為 512 字節的兆塊,總文件系統大小為 8M 千字節,即 8GB。

PDP-11 RL02K磁盤盒可容納 10.4 MB,而更新的 RA92 可存儲 1.5 GB。
Addr 數組在 bmap() 函數中被使用。該函數接收一個 inode(ip)和一個邏輯塊號 bn,並返回一個物理塊號。也就是説,它將文件中的一個塊映射到磁盤上的一個塊,因此得名。
前 10 個塊指針直接存儲在 inode 中。例如,要訪問塊 0,bmap() 將在 inode 中查找 di_addr[0] 並返回該塊號。
額外的塊存儲在一個間接塊中,而間接塊則存儲在 inode 中。對於更大的文件,會分配一個雙間接塊,並指向更多的間接塊,最終非常大的文件需要甚至三次間接塊。
代碼首先確定需要多少層間接尋址,也就是要通過多少個間接塊才能找到文件內容的磁盤塊。然後,獲取相應的間接塊。最後,代碼按照適當的次數解析間接尋址,也就是根據層數依次從間接塊中讀取其他間接塊或直接塊的地址,直到找到文件內容的磁盤塊。
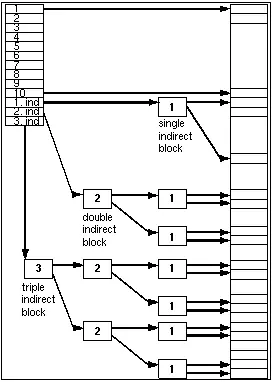
對於越來越大的文件,原始的 Unix 文件結構採用了逐漸增加的間接訪問次數。這樣形成了一個壓縮的數組,其中較短的文件可以直接通過 inode 中的數據進行訪問,而較大的文件則需要通過越來越多的間接訪問來獲取數據。為了提高性能,保持間接塊在文件系統緩衝區高速緩存中是至關重要的。
這種擴展性取決於塊大小(早期為 512 字節,現在為 4096 字節)和塊號的字節大小(最初為 3 字節,後來為 4 字節甚至 8 字節)。
Atomic writes
文件的寫入是在加鎖的狀態下進行的,因此它們始終具有原子性。即使是跨越多個數據塊的寫入操作,也是如此。這一點在 But Is It Atomic? 中有詳細討論。
這也意味着即使有多個寫入進程,在單個文件上,任何時刻只能有一個磁盤寫入操作處於活躍狀態。這對數據庫系統的開發者來説非常不便利。
Naming files
目錄是一個具有特殊類型和固定記錄結構的文件。

一個目錄條目包含一個inode號(一個無符號整數)和一個文件名,文件名的長度最多可以達到14個字節。這使得一個磁盤塊可以容納32個目錄條目,而一個目錄文件的直接塊可以引用的10個磁盤塊可以容納320個目錄條目。
下層(lower)的文件系統中充滿了大量的文件。這些文件沒有名稱,只有編號。
上層 (upper)的文件系統使用一種特殊類型的文件,具有簡單的16字節記錄結構,用於為文件分配最多14個字符的名稱。一個特殊的函數namei()將文件名轉換為inode號。
傳遞給namei()的路徑名具有層次結構:它們可以包含/作為路徑分隔符,並以\0(NUL)作為終止符。路徑名若以/開頭,則遍歷將從文件系統的根目錄開始,形成絕對路徑名;若不以/開頭,則遍歷將從u.u_cdir,即當前目錄開始。
該函數逐個消耗路徑名的各個組成部分,使用當前活動目錄,並在該目錄中線性搜索當前組件的名稱。當找到最後一個路徑名組件或在任何階段找不到組件時,該函數結束。如果在路徑中的任何目錄的任何點上,我們沒有 x 權限,它也會結束。
該函數按順序逐個處理路徑名的各個組成部分。它使用當前目錄,並在該目錄中線性搜索當前組成部分的名稱。函數的結束條件有兩種情況:一是找到了路徑名的最後一個組成部分,二是在路徑的任何目錄中,出現了無法訪問的情況。
掛載點是特殊條目,它會從當前節點和文件系統的目錄條目切換到掛載文件系統的根inode。這使得Unix中的所有文件系統看起來像是一棵單一的樹,如果要進行"硬盤修改"的操作,只需簡單地切換到不同的目錄。
最終,該函數將返回給定路徑名的inode指針,根據需要和需求創建(或刪除)inode(和目錄條目)。它是目錄遍歷和訪問權限檢查的集中點。
一些創新的想法以及限制
這個早期的Unix文件系統具有許多很好的特性:
- 它將多個文件系統呈現為一個統一的樹形結構;
- 文件是無結構的字節數組;
- 這些數組以可動態增加深度的動態數組的形式存儲。它們內部使用一種逐漸嵌套的間接塊系統,其中數組的元素可以是指向其他數組或數據的指針,從而形成層次嵌套的結構。這使得磁盤搜索的複雜度為O(1);
- 下層文件系統創建文件和上層的文件系統組織文件互相隔離,分工明確。獲取inode的唯一方式是路徑名遍歷,並且在此過程中始終檢查權限;
- 文件名中只有很少的特殊字符,即/和\0(空字符)。
但也有明顯的限制:
- 文件只能有16M個塊;
- 文件系統只能有非常有限的65535個inode。
還有一些令人討厭的限制:
- 文件只能有一個正在寫入的進程,這會導致併發性受限;
- 目錄查找是線性掃描,因此對於大型目錄(超過320個條目),速度變得非常慢;
- 沒有強制文件鎖定系統。但存在幾種用於諮詢式文件鎖定的系統。
還有一些特殊情況:
- 在 Unix V7 系統中,沒有 delete() 系統調用,而是 unlink() 系統調用,它可以刪除一個文件的名字,並且那些沒有任何文件名和打開文件句柄的文件會被自動清理。這會導致一些不符合預期的結果,例如,只有當一個完全沒有文件名的文件被完全關閉時,它佔用的磁盤空間才會被釋放。許多 Unix 系統管理員都曾經問過他們的磁盤空間去哪了,當他們刪除了 /var/log 目錄下的日誌文件,卻忘記了有一些進程還在使用它;
- 最初沒有 mkdir() 和 rmdir() 系統調用,這導致了存在可被利用的競態條件。競態條件是指在多線程或多進程環境中,由於操作的順序和時機不確定性,可能導致安全漏洞或錯誤行為的情況。這在 Unix 的後續版本中得到了修復;
- 有一些操作在特定條件下具有原子性(例如write(2)系統調用),或者經過修改後具有原子性(mknod(2)和mkdir(2))。
在結構上,inode表和塊和inode的空閒映射位於文件系統的開頭,磁盤空間也是從磁盤的前端線性分配的。這導致了頻繁的尋址操作,並且可能導致文件系統的碎片化(即文件存儲在非相鄰的塊中)。
遍歷目錄結構意味着從磁盤開頭讀取目錄的inode,然後向後移動到更遠的數據塊,再從磁盤開頭讀取下一個路徑名組成部分的下一個inode,並向後移動到相應的數據塊。這個過程在每個路徑名組成部分上來回進行,速度並不快。
改進
在之後的發展中,minix文件系統忠實繼承了PDP-11 V7 Unix文件系統,保留了它的特性包括侷限。然而,隨着時間的推移,在現代的Linux系統中,由於其不再具備實用性,它已經從內核源代碼中移除。
在稍後的一篇文章中,我們將會了解到關於BSD快速文件系統,如何更好地佈局磁盤上的數據,如何實現更長的文件名、更多的inode,以及如何通過考慮磁盤的物理特性來加快速度。
要解決目錄查找時間線性增長、單個寫入者或有限的文件元數據這些問題需要更新的文件系統。
翻譯自:《50 years in filesystems》 由 KRISTIAN KÖHNTOPP 撰寫。
如有幫助的話歡迎關注我們項目 Juicedata/JuiceFS 喲! (0ᴗ0✿)