

1、JVM模板
-Xms4096M -Xmx4096M -Xmn3072M -Xss1M -XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFaction=92 -XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSParallelInitialMarkEnabled
-XX:+CMSScavengeBeforeRemark -XX:+DisableExplicitGC -XX:+PrintGCDetails -Xloggc:gc.log
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/app/oom年輕代
-XX:MaxTenuringThreshold,默認值是15,多少次垃圾回收進入老年代
動態年齡判斷
-XX:PretenureSizeThreshold 大對象,直接進入老年代
S區放不下
空間分配擔保機制,老年代可用空間 > 新生代所有存活對象,yong gc,老年代可用空間 > 歷史yong gc平均大小,yong gc,否則full gc
老年代
-XX:CMSInitiatingOccupancyFraction,大於該值
碎片整理
-XX:+UseCMSCompactAtFullCollection
執行多少次Full GC進行一次內存碎片整理
-XX:CMSFullGCsBeforeCompaction=0
-XX:+CMSParallelInitialMarkEnabled 初始標記開啓多線程併發執行,默認是true
-XX:+CMSScavengeBeforeRemark 在CMS的重新標記階段之前,先儘量執行一次young gc(避免大量掃描)
-XX:+DisableExplicitGC 是防止System.gc()去隨便觸發GC,高峯情況下,調用System.gc()會發生Full GC
-XX:MetaspaceSize 默認20M,反射 jdk,cglib動態生成類,推薦512MB
-Xms -> ms是memory start簡稱,-Xmx mx是memory max的簡稱
-XX:+PrintTLAB 加這個參數可以看到 TLAB的分配,其中 refills 申請TLAB次數,slow allocs : 慢速分配的次數
XX:+ExplicitGCInvokesConcurrent 和 -XX:+ExplicitGCInvokesConcurrentAndUnloadsClasses 參數來將 System.gc 的觸發類型從 Foreground 改為 Background
CMS GC 共分為 Background 和 Foreground 兩種模式,前者就是我們常規理解中的併發收集,可以不影響正常的業務線程運行,但 Foreground Collector 卻有很大的差異,他會進行一次壓縮式 GC。此壓縮式 GC 使用的是跟 Serial Old GC 一樣的 Lisp2 算法,其使用 Mark-Compact 來做 Full GC,一般稱之為 MSC(Mark-Sweep-Compact),它收集的範圍是 Java 堆的 Young 區和 Old 區以及 MetaSpace。由上面的算法章節中我們知道 compact 的代價是巨大的,那麼使用 Foreground Collector 時將會帶來非常長的 STW
Java7 之後常量池等字面量(Literal)、類靜態變量(Class Static)、符號引用(Symbols Reference)等幾項被移到 Heap 中
2、查看JVM中的參數
java -XX:+PrintFlagsFinal -version
看JVM所有可以設置的參數
3、String.intern()
簡單理解就是擴充常量池的一個方法;當一個String實例str調用intern()方法時,Java查找常量池中是否有相同Unicode的字符串常量,
如果有,則返回其引用,如果沒有,則在常量池中添加一個Unicode等於str的字符串並返回它的引用(所以注意 s1.intern()是沒有用的,需要的是s1 = s1.intern())
jdk1.7之後,字符串常量池已經轉移到堆區,常量還是在元數據區中
4、棧內存溢出
棧是線程私有,它的生命週期和線程相同。每個方法在執行的同時都會創建一個棧幀用於存儲局部變量表、操作數棧、動態鏈接、方法出口等信息,方法調用
的過程就是棧幀入棧和出棧的過程
在Java虛擬機規範中,對虛擬機棧定義了兩種異常:
1、如果線程請求的棧深度大於虛擬機所允許的深度,將拋出StackOverflowError異常
2、如果虛擬機棧可以動態擴展,並且擴展時無法申請到足夠內存,拋出OutOfMemeoryError異常
棧對應線程,棧幀對應方法
5、JVM內存區域
線程共享 : 堆、元數據區
線程私有化 : 虛擬機棧、本地方法棧和程序計數器
元數據空間和永久代類似,都是對JVM規範中方法區的實現。不過元數據空間與永久代之間最大的區別在於 : 元數據空間並不在虛擬機中,而是使用本地內存。因此,默認情況下,元數據空間的大小僅受本地內存限制
本地方法棧與虛擬機棧發揮的作用是類似的,區別是虛擬機棧為虛擬機執行Java方法(也就是字節碼)服務,而本地方法棧為虛擬機適應到的Native方法服務
程序計數器 : 當前線程鎖執行的字節碼的行號指示器,為了線程切換後能恢復到正確的執行位置,每個線程都有一個獨立的程序計數器,各個線程之間計數器互不影響,獨立存儲
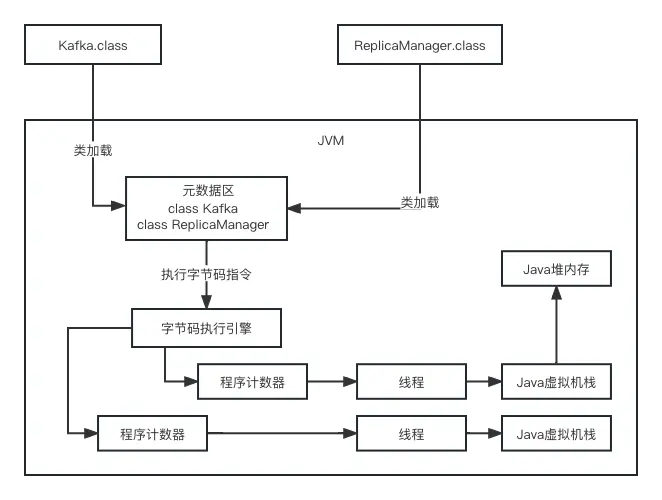
6、xx.java文件是怎麼加載到JVM中的
xx.java -> xx.class -> 類加載器 -> JVM
一個類從加到到使用,一般會經歷下面的過程 :
加載 -> 驗證 -> 準備 -> 解析 -> 初始化 -> 使用 -> 卸載
加載 : 全限定查找此類字節碼文件,創建一個Class對象
驗證 : 是否符合規範
準備 : 靜態變量初始化,比如説 public static int flushInterval; 為0,不包含final修飾的static,final在編譯的時候已經分配了
類變量會分配在方法區中,實例變量是隨着對象一起分配到Java堆中
解析 : 符號引用變為直接引用
初始化 : 靜態方法和靜態代碼塊執行(比如MySQL Driver staic方法向DriverManager 註冊驅動)
什麼時候初始化類呢 ?
1、new 類()
2、Class.forName()
3、classLoader.loadClass
7、類加載器和雙親委派機制
啓動類加載器 : lib包下核心類庫,C++寫
擴展類加載器 : 默認是 jre/lib/ext,可以通過 -Djava.ext.dir 指定
應用類加載器 : ClassPath環境變量所指定的路徑中的類,java -cp 指定classpath路徑
自定義類加載器
雙親委派機制,從下往上找,防備下層的類加載器把父類的類重寫了,比如説String,沙箱安全機制
第三方包加載方式,反向委派機制,説清楚就是核心代碼在rt.jar中,實現類用户自已定義,比如SPI,這種情況下我們就需要一種特殊的類加載器來加載第三方的類庫,而線程上下文類加載器(雙親委派的破壞者),就是很好的選擇,Thread.currentThread().getContextClassLoader(),也就是
classpath中的jar
Tomcat類加載器 :
BootstarpClassLoader -> ExtClassLoader -> AppClassLoader -> CommonClassLoader
CommonClassLoader 並行分為 CatalinaClassLoader 和 ShareClassLoader
ShareClassLoader 下面 WepAppClassLoader
CatalinaClassLoader 用於隔離 Tomcat本身和Web
ShareClassLoader 本質是兩個Web應用之間怎麼共享類,並且不能重複加載相同的類
Tomcat的自定義類加載WebAppClassLoader打破了雙親委派機制,它首先自己嘗試去加載某個類,如果找不到再代理給父類加載器,其目的是優先加載Web應用自己定義的類。具體實現就是重新ClassLoader的兩個方法:findClass和loadClass,loadClass調用了findClass方法
破壞雙親委派的點在於,findClass中是優先使用 WebAppClassLoader 來加載,而不是一直雙親委派依次向上找,找不到再向上找
loadClass 其實還是遵循 啓動類加載器、擴展類加載的,沒有,使用 WebAppClassLoader,在沒有向上找
8、為什麼要分代?以及不同代不同的垃圾回收機制?
分代其實為了關聯不同的垃圾回收機制,年輕代大部分被回收,所以複製算法,存活少,複製活的對象到S區,剩餘直接清理
老年代存活對象多,所以標記+清除+整理
9、方法區內會不會進行垃圾回收?
首先,該類的所有實例對象都已經從Java堆內存裏被回收
其次,加載這個類的ClassLoader已經被回收
最後,對該類的Class對象沒有任何引用
只要滿足以上條件,方法區類的元數據信息就會被回收
使用 URLClassLoader 進行類加載器,最後進行URLClassLoader close方法,通過重寫 finalize 打印方法查看是否被回收
最好的方式就是讓所有的不管是加載的clazz,還是ClassLoader,還是實例化的對象都為null,然後close ClassLoader,就肯定不會元數據區溢出
10、誰才能作為GC Root?
局部變量和靜態變量,為什麼實例變量不行?實例變量是不是屬於堆對象中,一定是需要外界引用,外界引用它只能是局部變量和靜態變量
11、引用類型
強、軟、弱和虛引用
強是什麼?就是寧可JVM內存溢出,我也要存在
軟是什麼?內存不足,壯烈犧牲
弱是什麼?只要GC(前提是沒有強引用哈),就要銷燬
虛是什麼?虛引用的主要作用是跟蹤對象被垃圾回收的狀態,僅僅是提供了一種確保對象被finalize以後,做某些事情的機制,虛引用必須和引用隊列同時使用
12、ParNew + CMS(STW)
ParNew對應新生代,複製算法,不能工作
CMS對應老年代,標記 + 清理,系統一邊工作一邊清理
1、初始標記,快,從GC Root出發
2、併發標記,慢,相當於是遞歸追蹤,無所謂,程序是可以運行的
3、重新標記,快,增量標記
4、併發清理,慢,垃圾回收
不使用的場景,大機器內存,比如説64G,給JVM 32G,回收需要很長時間
13、為啥老年代的Full GC要比新生代的Yong GC慢很多,一般在10倍以上?
新生代 :
新生代執行速度其實很快,因為直接從GC Roots觸發就追蹤哪些對象是或的就行了,新生代對象存活是很少的,這個速度是極快的,不需要追蹤多少對象
其實年輕代GC幾乎沒什麼好調優的,因為他的運行邏輯非常簡單,就是Eden一旦滿了無法放心對象就觸發一次GC,一般來説,真要對年輕代GC調優,
只要你給系統分配足夠的內存即可,核心點點在於堆內存的分配、新生代內存的分配
老年代 :
存活對象很多,併發清理階段,不是一次性回收一大批內存,而是找零零散散在各個地方的垃圾對象,完事了,還要一次碎片整理
14、什麼時候會觸發Concurrent Mode Failure ?
説白了其實就是比如説在併發清理的時候,我在清理數據,你比如説新生代發生yong gc,你要往老年代放數據,抱歉,放不了,我正在垃圾回收呢?
所以現在這個情況就會出現 Concurrent Mode Failure,然後CMS切換為Serial Old,直接禁止程序運行
15、G1(Garbage-First,G1)
優先回收垃圾,不會等到空間全部佔滿,然後進行回收
把Java堆內存拆分為多個大小相等的Region(最多2048個region),G1新生代和老年代是邏輯上的概念,設置一個垃圾回收的預期停頓時間
計算回收價值,比如説1個Region中的垃圾對象有10M,回收需要1s;另外一個Region,垃圾20M,200ms
核心理念 : 最少回收時間和最多回收對象的Region進行垃圾回收
大對象在G1中比較特殊,有特殊的region來保存,在新生代或者老年代發生gc的時候,會順帶大對象回收
-XX:UseG1GC
-XX:G1HeapRegionSize
-XX:G1MaxNewSizePercent 5%~60%
-XX:MaxGCPauseMillis 默認200ms
-XX:InitiatingHeapOccupancyPercent 45%
-XX:G1MixedGCCountTarget 混合回收的過程中,最後一個階段執行幾次混合回收,默認是8次
-XX:G1HeapWastePercent 默認值是5%,混合回收,一旦空閒出來Region數量達到了堆的5%,立即停止混合回收
-XX:G1MixedGCLiveThresholdPercent 默認值是85%,確定要回收的Region的時候,必須是存活對象低於85%的Region才可以進行回收,如果大於不會放到CSet中
-XX:GCTimeRatio GC與應用的耗費時間比,如果G1 GC時間與應用運行的時間佔比不超過10%的時候,不需要動態擴展
使用場景 : 大內存的場景
Mixed GC(混合回收),G1特有
新生代分區、自由分區、老年代分區和大對象分區
G1不能手動指定分區個數
停頓預測模型 + 動態調整機制保障我們GC百分之九十能夠保持在某個停頓時間內的關鍵
16、常用命令
jstack -l pid 要在某個用户啓動情況下執行,查看線程情況
jstat -gc pid period count 看每個代的容量變化
jmap -histo pid 對象分佈
17、有哪些溢出?
棧溢出、堆溢出、元數據溢出、堆外內存溢出
棧溢出 : 遞歸
堆溢出 : 就是內存不能再創建對象
元數據溢出 : JDK反射或者CGLIB反射,根本原因是ClassLoader一直加載類,最終元數據空間放滿
堆外內存溢出 :
場景1 : 瞬時大量請求,DirectByteBuffer,其實會是堆和堆外有一個映射關係,創建大量堆外內存,不能創建了溢出
場景2 : 新生代設置不合理,每次,young gc,一些請求未執行完畢,當然就會進入老年代,而老年代設置的又比較大,這一直創建堆外內存,而且老年代比較大,又不回收
最終就會導致堆外內存溢出
怎麼解決呢?每次分配新的堆外內存的時候,都會調用System.gc()去提醒JVM主動執行一下gc去回收掉一些垃圾沒人引用的DirectByteBuffer對象,釋放堆外內存空間
但是不能設置 -XX:+DisableExplicitGC
18、G1為什麼要滿足新生代的動態擴展?
動態調整內存分區的佔比,來滿足回收時間。如果不做動態調整,那麼GC時間過長,就沒法滿足停頓時間。動態增加、減少,才能調整到一個合理的值
擴展機制 : 新生代分區列表 + 自由分區 + 擴展分區
19、停頓預測模型
衰減標準差算法,簡單來説其實就是線程加權(距離本地預測越近的GC影響比重就佔的越高才行)
20、TLAB
LAB(Thread Local Allocation Buffer,指針碰撞法來分配對象,dummy對象填充碎片空間)
對象分配很複雜,需要鎖整個堆,效率低下。所以G1採取的就是本地緩衝區的思想來分配的,每個線程都有一個自己線程的本地分配緩衝區
這個緩衝區,保證了一個線程過來的時候,儘可能的走這個TLAB來分配對象,能夠快速分配,並實現了無鎖化分配
TLAB是和線程對象的,一個進行啓動的線程是有數的,幾個線程就鎖幾次堆,使用CAS來分配TLAB
TLAB太小,會導致TLAB快速被填滿,從而導致對象不走TLAB分配,效率變差
如果TLAB過大,造成內存碎片
假如TLAB滿了(refill_waste,可以浪費空閒空間,如果剩餘小於等於這個值,認為已經滿了),無法分片對象了,會怎麼處理?
在G1中,就是説,如果説無法分片對象了,就優先去申請一個新的TLAB來存儲對象
如果無法申請新的TLAB,才有可能會走堆內存加鎖,然後直接在堆上分配對象的邏輯
一邊運行一邊調整refillwaste和TLAB大小
系統程序 -> 分配對象 -> 對象需要空間大於refill_waste(堆內存直接分配) -> TLAB剩餘內存夠分配對象嗎?(直接TLAB分配)
-> 申請一個新的TLAB ->分配對象
21、快速分配和慢速分配
簡説快速分配其實就是走TLAB,慢速分配不走TLAB(慢速分配需要加鎖,甚至可能要涉及到GC的過程,所以速度非常慢)
慢速分配
1、去創建新的TLAB
2、擴展分區
3、垃圾回收
ObjSize > regionSize/2的時候,就成為大對象,同時設置TLAB的最大值,限定在最大為regionsize/2,這樣子,大對象就一定
大於TLAB的大小,所有可以直接走慢速分配,為什麼呢?很簡單,一個大對象就佔滿了TLAB,會造成其他普通的對象進入慢速分配
使用TLAB進行快速分配的過程,第一次進入慢速分配,擴展空間失敗的時候,就是ygc活着mixed gc,再次進行慢速分配,有可能還會執行gc,
在分配過程中執行的這個ygc或者mixed gc,慢速分配也失敗的時候,就會進入最終的嘗試,最終嘗試執行兩次full gc,一次不回收軟引用,
一次回收軟引用
22、為了提升GC的效率,G1設置了哪些核心機制?
1、Rset記憶集 Memember Set
G1回收 young gc -> mixed gc -> full gc
新生代對象不一定只有新生代引用,有可能會有老年代的對象引用新生代的對象。那麼我們直接在觸發新生代gc的時候,我們在老年代的裏面有一些對象也在我們的
引用鏈中。RSet記錄了誇代引用的引用關係,在gc的時候,可以快速藉助記憶集 + GC Roots搞定同代引用及跨代引用的可達對象分析問題
RSet記憶集的維度是對每一個region,都搞一塊內存,存儲region裏面所有的對象被引用關係
RSet中只保存老年代到新生代的引用(young gc使用,不要在young gc的時候遍歷老年代)
老年代到老年代的引用,mixed gc只是選擇部分的region進行回收,如果通過RSet是最快的,而不是GC Root一直遞歸找
2、位圖(BitMap),G1採取了位圖的方式描述內存是否使用了
3、卡表,G1中,卡表是用一個字節(8位)來描述512字節的空間的使用情況,及內存被誰使用了。JVM使用了RSet+卡表來作為分代模型中,跨帶引用關係不好判定,不好追蹤問題的解決思路
耗時操作 : 初始標記、併發標記、重新標記和併發清理,最耗時其實就是引用關係不好判定,內存是否使用不好判定
首先,初始標記過程,要從GC Roots觸發,標記所有直接被引用的關係是吧?然後再併發標記階段,追蹤所有間接被引用的對象,如果出現跨代引用,比如我新生代對象
被老年代引用了,我肯定不能被回收啊,那麼RSet就避免了對老年代的遍歷
引用關係怎麼找?RSet裏肯定不能直接記錄哪個對象引用了哪個對象,不然一個系統1000w個對象,引用關係還特別複雜,可能要記錄很多遍,那豈不是一個RSet比整個系統
佔用的內存還要大?所以,這個時候cardTable就出現了,cardTable裏面可以用一個字節來描述512字節內存的引用關係,那麼RSet裏面直接記錄cardTable相關內容這一樣可以節省很多內存
比如,我發現老年代有一塊512B的空間裏的對象引用了新生代的一個對象,RSet直接記錄這個512B的空間開標裏面的位置就OK了
位圖和併發標記是息息相關的,簡單來説,就是在併發標記階段,可以藉助位圖描述內存使用情況,避免內存使用衝突的問題,也避免GC線程無效遍歷一些未使用的內存
新生代引用老年代,一般不需要記錄為什麼?
我們要知道,gc回收過程是沒有老年代單獨的回收的,所以如果要回收老年代的時候,肯定是會帶着一次新生代回收,或者直接full gc,所以不需要記錄
卡表其實就是位圖思想的一種實現方式,只是粒度不同罷了。位圖用每一位來描述對應數據的裝他,卡表,其實就是按照位圖的思想,用一個字來描述512字節的內存狀態,
引用等相關數據,Rset記錄的是卡表地址
23、RSet更新
如果引用關係發生了改變,RSet是否需要更新,應該怎麼更新?
要知道每個Region中是由一個RSet的,對象更新,如果加鎖的方式更新RSet,會造成性能問題
JVM核心是 : 對象分配和垃圾回收
對象分配是不需要RSet的,因為我們在分配一個對象的時候,值需要看內存夠不夠,剩餘空間是否能夠分配一個對象,分配完成以後,直接更新一下內存的使用情況就OK了,並不需要藉助RSet
RSet本身就是為了垃圾回收的時候更加方便,不需要遍歷所有空間而設計的,所以RSet即使需要更新,而我們沒有把他更新,其實也無所謂,因為不影響程序運行,只是在垃圾回收的時候,我一定需要更新RSet,不然就會報錯
G1的髒數據隊列異步消費,更新RSet。G1設計了一個隊列,叫做DCQ(Dirty Card Queue)。在每次引用關係變更的時候,就把這個變更操作,發動一個消息到DCQ裏面,然後又一個專門的線程去異步消費(refine線程)
針對DCQ G1是設計了二級緩存來解決併發衝突的
第一層緩存是在線程這一層,也就是説,DCQ其實是屬於每一個線程的,也就是説,每一個工作線程都會關聯一個DCQ,每個線程在執行了引用更新操作的時候,都會往自己的那個DCQ裏面寫入變更信息。DCQ默認長度是256,如果寫滿了,就重新申請一個新的DCQ,並把這個老DCQ提交到第二級緩存,也就是一個DCQ Set裏面去,叫做二級緩存為DCQS
refine直接從DCQS取DCQ去消費的,如果DCQS已經不能再放下更多的DCQ了,此時工作線程就會自己處理,自己去處理DCQ,更新RSet
24、G1垃圾回收
如果老年代對象佔用達到了某個閾值,就會觸發老年代的回收,ParNew + CMS直接Full GC,G1中是觸發mixed gc
首先會進行ygc,老年代存活對象越來越多,會進入mixed gc,mixed gc會從老年代中選擇部分回收價值比較高的region進行回收,滿足用户設置的MaxGCPauseMillis值,當mixed gc之後,對象還是無法分片成功的時候,觸發full gc,
full gc會暫停程序運行,對整個堆進行全面的垃圾回收,包括新生代、老年代和大對象等
25、G1 Young GC
並行處理
STW -> 選擇需要回收的分區全部新生代region -> GC Roots + RSet -> 把直接引用的對象field放入一個set,-> 放入survior -> 繼續遍歷field set -> 複製到survior中
串行處理
弱引用、軟引用和虛引用追蹤 -> 複製到survivor區 -> 一些G1優化,比如字符串去重 -> 重建RSet -> 清理垃圾(嘗試回收大對象) -> 嘗試擴展分區(GC佔用時間達到程序10%) -> 調整新生代數量 -> 要看GC對DCQS的處理,調整DCQS的幾個閾值 -> 判斷是否開啓併發標記,如果判斷通過(老年代45%的使用率)就啓動併發標記
第一次YGC的時候,應該是 -Xmx * 5%的年輕代使用量的時候,大概是這個值
26、Mixed回收
1、初始標記
一定會伴隨一次YGC,在YGC的時候會做一個判斷,是否要開啓併發標記,如果需要開啓併發標記,那麼本次YGC的整體過程,會額外做一些事情,
把GC Roots直接引用的老年代的對象也標記起來,作為併發標記的其實對象的一部分
初始標記的時候會發生YGC,YGC結束之後,在survivor區的對象會作為一部分的併發標記的起始對象(跟對象,可以理解為GC Roots對象)
所以,在初始標記階段中,必然會發生一次YGC
2、併發標記
Survivor區存儲的對象 + GC Roots引用的老年代對象集合RSet進行標記,並引入位圖 + 三色標記法來做對象是否存活的標記
白色大表死亡、黑色代表存活、灰色代表存活但其子對象尚未標記完全
引用變化,對象變為灰色,重新標記,防止誤刪除
SATB多次併發標記過程中,出現的引用變化都會記錄下來
3、最終標記 STW
主要是對併發標記階段由於系統運行造成的錯標漏表情況修正處理。本質上是把所有SATB隊列裏面的對象重新做遍歷標記處理。最終把對象全表標記為黑色
或者保持原本的白色
4、預回收
存活對象計數的階段
5、混合回收階段,會選擇一些分區,成為Cset(Collect Set),回收
需要注意的是,在選擇CSet的時候,是按照一定的選擇算法來選擇CSet的(-XX:G1MixedGCLiveThresholdPercent存活小於85%才會放入到CSet中)。我們在上一個階段,已經統計出來了Region的存活對象的數量,垃圾對象的數量,
那麼其實CSet的選擇就是根據這個基礎來做的
回收時間 約定於 對象的複製時間(從垃圾region轉移到空閒region)
混合回收是否要執行的條件 :
-XX:G1HeapWastePercent 默認是5%,即,在併發標記結束之後,如果説我們選擇的CSet中可以被回收的垃圾佔用堆內存空間的佔比大於5%,才會進行混合回收
的回收節點,否則本次是不開啓垃圾回收的過程的,即使併發標記,重新標記都完成,也不開啓垃圾回收的過程
MixedGC的最後一步,垃圾回收過程,-XX:G1MixedGCCountTarget,默認是8,會最多通過8次對CSet進行分配回收
G1OldCSetRegionThredShouldPercent,參數是10,表示,每次在執行混合回收的時候,回收掉的分區數量不能超過整個堆內存分區數量的10%
27、Full GC
TLAB分配 -> 擴展TLAB進行分配 -> 申請新的TLAB -> 從自由分區新的region給新生代 -> 堆外內存擴展分區給新生代 -> 垃圾回收(YGC、MixedGC) ->
FULL GC(第一次) -> FULL GC(第二次,回收軟引用)
FULL GC的一些優化點總結
1、使用多線程進行垃圾回收,CMS一塊內存衝突比較多(整理、壓縮),所以單線程;G1天生分區多線程(整理、壓縮)
2、標記過程採用多線程並行處理
3、採取了任務竊取策略,提升整體的效率
4、採取了單個線程的那些分區整體壓縮的處理,提升空閒region的產生的可能性
YGC和FULL GC會進行字符串去重
-Xms10M -Xmx10M -Xss1M -XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M -XX:+UseParNewGC -XX:+UseConcMarkSweepGC
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintTLAB
-XX:+PrintGCDetails -Xloggc:gc.log
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users/qiaozhanwei/IdeaProjects/jdk
// -XX:+UnlockExperimentalVMOptions -XX:G1LogLevel=finest 這兩個選項是打開詳情日誌
-XX:InitialHeapSize=128M -XX:MaxHeapSize=128M -XX:+UseG1GC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
-XX:+PrintTLAB -XX:+UnlockExperimentalVMOptions -XX:G1LogLevel=finest -XX:MaxGCPauseMillis=20 -Xloggc:gc.log
-Xmx256M -XX:+UseG1GC -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -XX:MaxGCPauseMillis=20 -Xloggc:gc.logJDK9 中G1被設置為默認的垃圾回收器
如感興趣,點贊加關注哦!
