前言
程序員的終極追求是什麼?當系統流量大增,用户體驗卻絲滑依舊?沒錯!然而,在大量文件傳輸、數據傳遞的場景中,傳統的“數據搬運”卻拖慢了性能。為了解決這一痛點,Linux 推出了 零拷貝 技術,讓數據高效傳輸幾乎無需 CPU 操心。今天,我就用最通俗的語言講解零拷貝的工作原理、常見實現方式和實際應用,徹底幫你搞懂這項技術!
1、傳統拷貝:數據搬運的“舊時代”
為了理解零拷貝,我們先看看傳統數據傳輸的工作方式。想象一下,我們需要把一個大文件從硬盤讀取後發送到網絡上。這聽起來很簡單,但實際上,傳統的數據傳輸涉及多個步驟並佔用大量 CPU 資源。
1.1 一個典型的文件傳輸過程(沒有 DMA 技術):
假設我們要將一個大文件從硬盤讀取後發送到網絡。以下是傳統拷貝方式的詳細步驟:
- 讀取數據到內核緩衝區:使用
read()系統調用,數據從硬盤讀取到內核緩衝區。此時,CPU 需要協調和執行相關指令來完成這一步。 - 拷貝數據到用户緩衝區:數據從內核緩衝區被拷貝到用户空間的緩衝區。這一步由
read()調用觸發,CPU 完全負責這次數據拷貝。 - 寫入數據到內核緩衝區:通過
write()系統調用,數據從用户緩衝區被再次拷貝回內核緩衝區。CPU 再次介入並負責數據拷貝。 - 傳輸數據到網卡:最終,內核緩衝區的數據被傳輸到網卡,發送到網絡。如果沒有 DMA 技術,CPU 需要拷貝數據至網卡。
1.2 來看個圖,更直觀點:
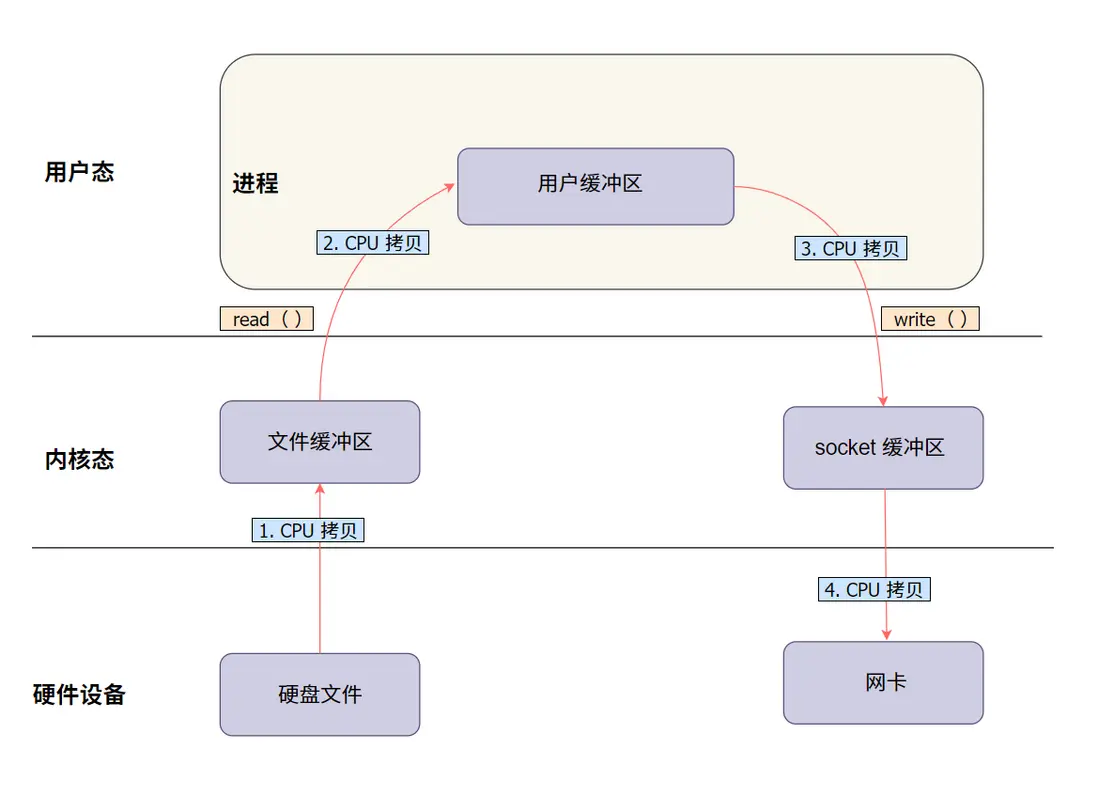
1.3 數據傳輸的“四次拷貝”
在這個過程中,數據在系統中經歷了四次拷貝:
- 硬盤 -> 內核緩衝區(CPU 參與,負責數據讀取和傳輸)
- 內核緩衝區 -> 用户緩衝區(
read()調用觸發,CPU 負責拷貝) - 用户緩衝區 -> 內核緩衝區(
write()調用觸發,CPU 負責拷貝) - 內核緩衝區 -> 網卡(最終發送數據,CPU 參與傳輸)
1.4 性能瓶頸分析
這種傳統拷貝方式的問題顯而易見:
- CPU 資源佔用高:每次
read()和write()調用都需要 CPU 進行多次數據拷貝,嚴重佔用 CPU 資源,影響其他任務的執行。 - 內存佔用:當數據量較大時,內存使用量明顯增加,可能導致系統性能下降。
- 上下文切換開銷:每次
read()和write()調用涉及用户態和內核態的切換,加重了 CPU 的負擔。
這些問題在處理大文件或高頻率傳輸時尤為明顯,CPU 被迫充當“搬運工”,性能因此受到嚴重限制。那麼, 有沒有一種方法能夠減少 CPU 的“搬運”工作?此時,DMA(Direct Memory Access,直接內存訪問)技術登場了。
2、DMA:零拷貝的前奏
DMA(Direct Memory Access,直接內存訪問) 是一種讓數據在硬盤和內存之間直接傳輸的技術,不需要 CPU 逐字節參與。簡單來説,DMA 是 CPU 的“好幫手”,減少了它的工作量。
2.1 DMA 如何幫 CPU?
在傳統的數據傳輸中,CPU 需要親自把數據從硬盤搬到內存,再送到網絡,這很耗費 CPU 資源。而 DMA 的出現讓 CPU 可以少幹活:
- 硬盤到內核緩衝區:由 DMA 完成,CPU 只需要下指令,DMA 就自動將數據拷貝至內核緩衝區。
- 內核緩衝區到網卡:DMA 也能處理這部分,把數據直接送到網卡,CPU 只需監督整體流程。
有了 DMA,CPU 只需要説一句:“嘿,DMA,把數據從硬盤搬到內存去!” 然後 DMA 控制器就會接過這活,自動把數據從硬盤傳到內核緩衝區,CPU 只需要在旁邊監督一下。
2.2 有了 DMA , 再來看看數據傳輸的過程:
為了更好地理解 DMA 在整個數據搬運中的角色,我們用圖來説明:
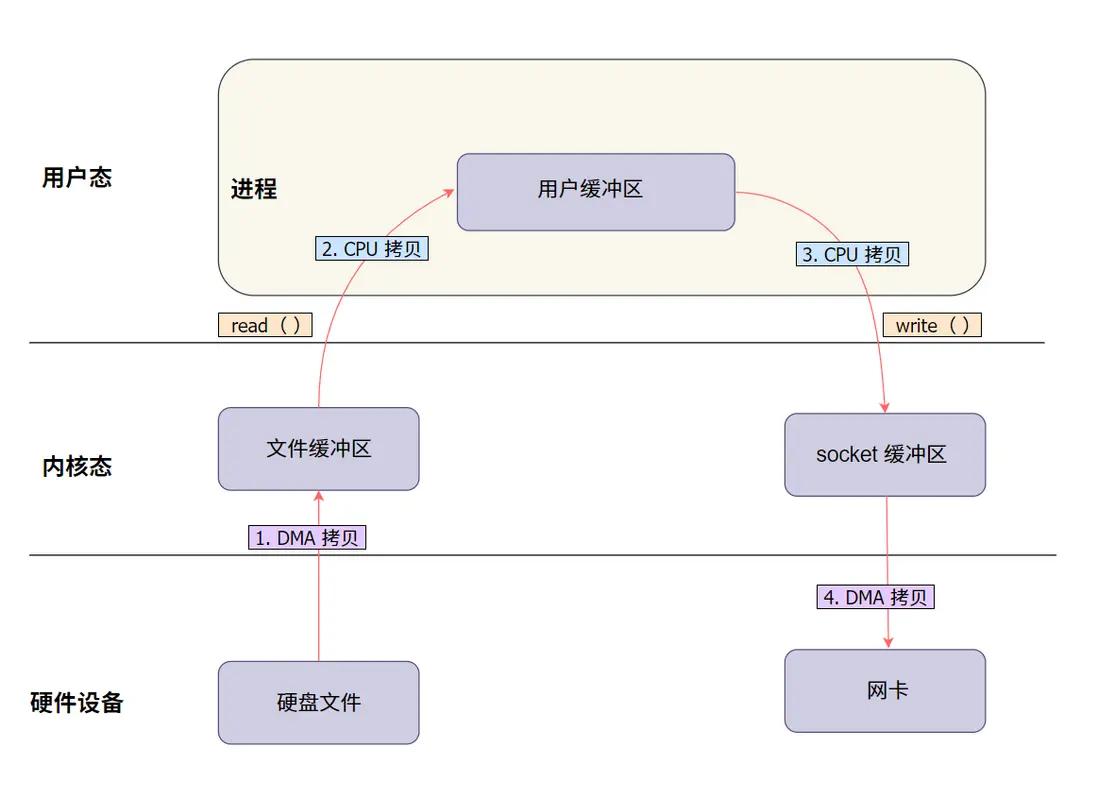
説明:
- DMA 負責硬盤到內核緩衝區和內核到網卡的傳輸。
- CPU 仍需處理內核和用户緩衝區之間的數據傳輸。
2.3 哪些步驟仍需 CPU 參與?
雖然 DMA 能幫 CPU 分擔一些任務,但它並不能全權代理所有數據拷貝工作。CPU 還是得負責以下兩件事:
- 內核緩衝區到用户緩衝區:數據需要被 CPU 拷貝到用户空間供程序使用。
- 用户緩衝區回到內核緩衝區:程序處理完數據後,CPU 還得把數據拷回內核,準備進行後續傳輸。
就像請了一個幫手,但有些細緻活兒還得自己幹。所以,在高併發或大文件傳輸時,CPU 依舊會因為這些拷貝任務感到壓力。
2.4 總結一下
總結來説,DMA 確實減輕了 CPU 在數據傳輸中的負擔,讓數據從硬盤傳輸到內核緩衝區和內核緩衝區到網卡時幾乎無需 CPU 的參與。然而,DMA 無法徹底解決數據在內核和用户空間之間的拷貝問題。CPU 依然需要進行兩次數據搬運,特別是在高併發和大文件傳輸場景下,這個限制變得尤為突出。
3、零拷貝:讓數據“直達”
因此,為了進一步減少 CPU 的參與,提升傳輸效率,Linux 推出了 零拷貝 技術。這項技術的核心目標是:讓數據在內核空間內直接流轉,避免在用户空間的冗餘拷貝,從而最大限度減少 CPU 的內存拷貝操作,提高系統性能。
接下來,我們來詳細看看 Linux 中的幾種主要零拷貝實現方式:

注意:Linux 中零拷貝技術的實現需要硬件支持 DMA。
3.1 sendfile:最早的零拷貝方式
sendfile 是最早在 Linux 中引入的零拷貝方式,專為文件傳輸設計。
3.2 sendfile 的工作流程
- DMA(直接內存訪問)直接將文件數據加載到內核緩衝區。
- 數據從內核緩衝區直接進入網絡協議棧中的 socket 內核緩衝區。
- 數據通過網絡協議棧處理後,通過網卡直接發往網絡。
通過 sendfile,整個傳輸過程 CPU 只需要一次數據拷貝,減少了 CPU 的使用。
3.3 簡單圖解:
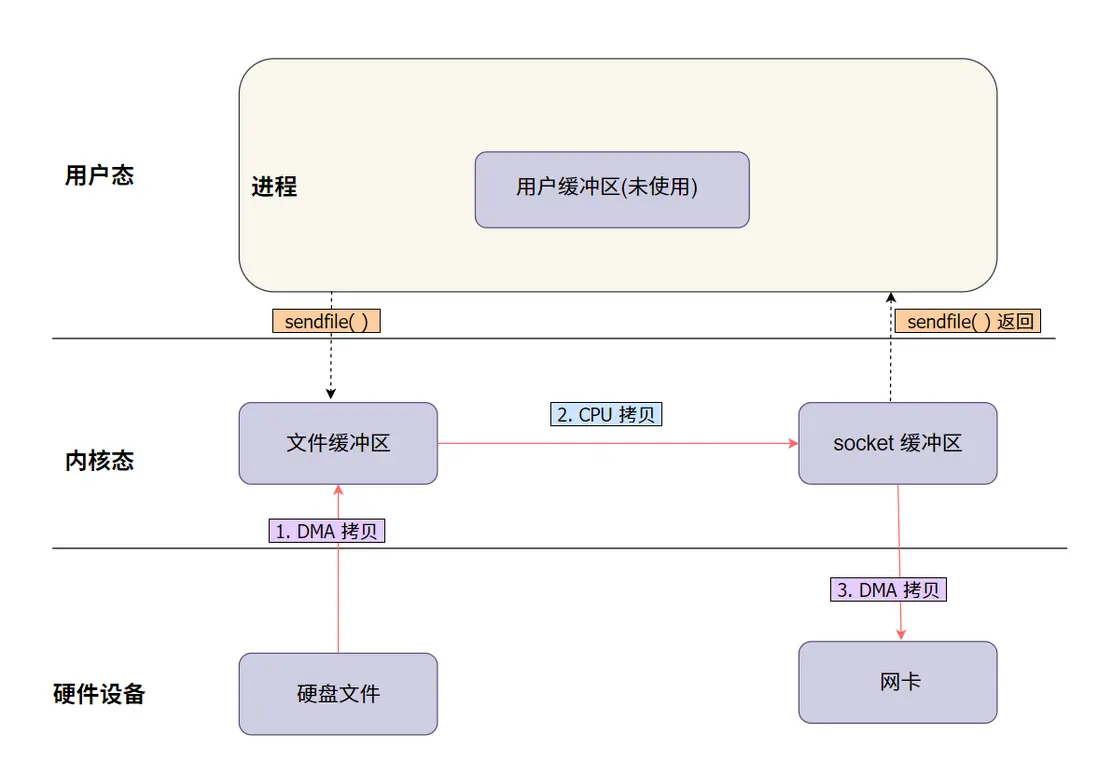
sendfile 圖解説明:
- 從硬盤讀取數據:文件數據通過 DMA 從硬盤讀取,直接加載到內核緩衝區,這個過程不需要 CPU 的參與。
- 拷貝數據至網絡協議棧的 socket 緩衝區:數據不進入用户空間,而是從內核緩衝區直接進入網絡協議棧中的 socket 緩衝區,在這裏經過必要的協議處理(如 TCP/IP 封裝)。
- 數據通過網卡發送:數據最終通過網卡直接發往網絡。
3.4 sendfile 接口説明
sendfile函數定義如下:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);out_fd:目標文件描述符,一般是 socket 描述符,用於網絡發送。in_fd:源文件描述符,通常是從硬盤讀取的文件。offset:偏移量指針,用於指定從文件的哪個位置開始讀取。如果為NULL,則從當前偏移位置開始讀取。count:要傳輸的字節數。
返回值是實際傳輸的字節數,出錯時返回 -1,並設置 errno 來指示錯誤原因。
3.5 簡單代碼示例
#include <sys/sendfile.h>
int main() {
int input_fd = open("input.txt", O_RDONLY);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
sendfile(client_fd, input_fd, NULL, 1024);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}這個例子展示瞭如何使用 sendfile 將本地文件發送到一個通過網絡連接的客户端。只需要調用 sendfile,數據就能從 input_fd 直接傳輸到 output_fd。
3.6 適用場景
sendfile 主要用於將文件數據直接傳輸到網絡,非常適合需要高效傳輸大文件的情況,例如文件服務器、流媒體傳輸、備份系統等。
在傳統的數據傳輸方式中,數據需要經過多個步驟:
- 首先,數據從硬盤讀取到內核空間。
- 然後,數據從內核空間拷貝到用户空間。
- 最後,數據從用户空間再拷貝回內核,送到網卡發出去。
總結來説,sendfile 可以讓數據傳輸更加高效,減少 CPU 的干預,特別適合簡單的大文件傳輸場景。然而,如果遇到更復雜的傳輸需求,比如要在多個不同類型的文件描述符之間移動數據,splice 則提供了一種更加靈活的方法。接下來我們來看看 splice 是如何實現這一點的。
4. splice : 管道式零拷貝
splice 是 Linux 中另一種實現零拷貝的數據傳輸系統調用,專為在不同類型的文件描述符之間高效地移動數據而設計,適用於在內核中直接傳輸數據,減少不必要的拷貝。
4.1 splice 的工作流程
- 從文件讀取數據:使用
splice系統調用將數據從輸入文件描述符(例如硬盤文件)讀取,數據直接通過 DMA(直接內存訪問)進入內核緩衝區。 - 傳輸到網絡 socket:隨後,
splice繼續將內核緩衝區中的數據直接傳輸到目標網絡 socket 的文件描述符中。
整個過程在內核空間內完成,避免了數據從內核空間到用户空間的往返拷貝,大大減少了 CPU 的參與,提高了系統性能。
4.2 簡單圖解:
和 sendfile 圖解類似,只是接口不一樣。
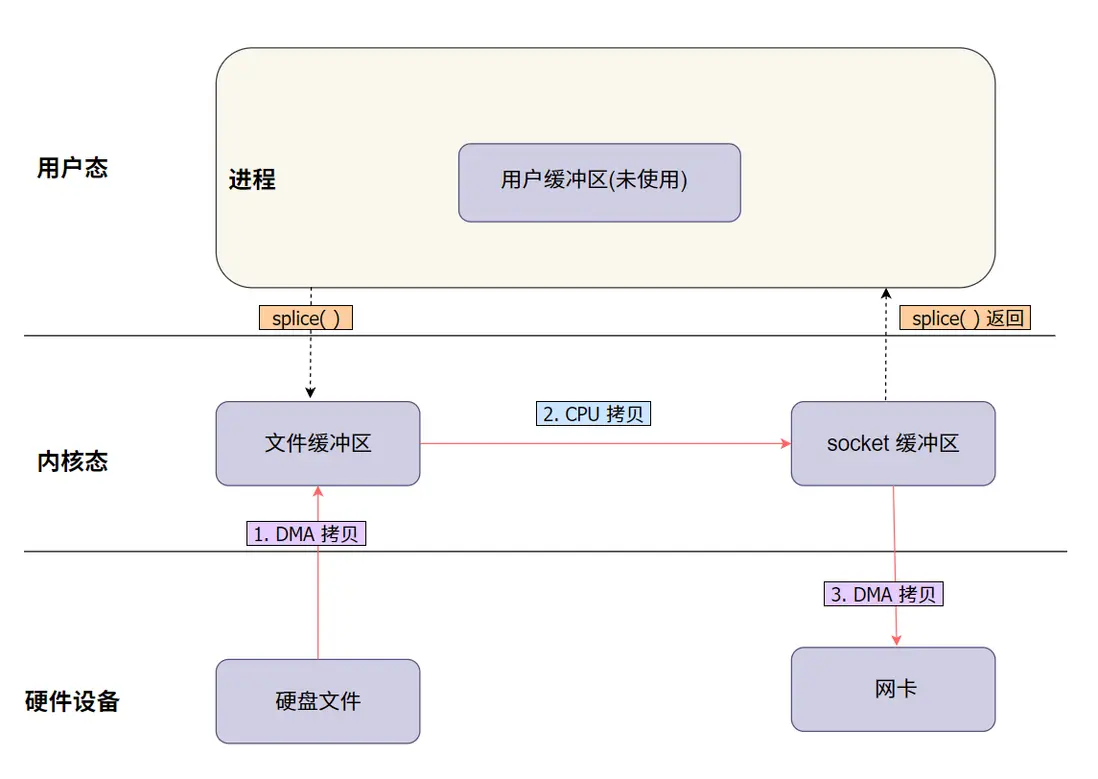
splice 圖解説明:
數據通過 splice 從文件描述符傳輸到網絡 socket。數據首先通過 DMA 進入內核緩衝區,然後直接傳輸到網絡 socket,整個過程避免了用户空間的介入,顯著減少了 CPU 的拷貝工作。
4.3 splice 接口説明
splice 函數的定義如下:
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);fd_in:源文件描述符,數據從這裏讀取。off_in:指向源偏移量的指針,如果為NULL,則使用當前偏移量。fd_out:目標文件描述符,數據將被寫入這裏。off_out:指向目標偏移量的指針,如果為NULL,則使用當前偏移量。len:要傳輸的字節數。flags:控制行為的標誌,例如SPLICE_F_MOVE、SPLICE_F_MORE等。
返回值是實際傳輸的字節數,出錯時返回 -1,並設置 errno 來指示錯誤原因。
4.4 簡單代碼示例
int main() {
int input_fd = open("input.txt", O_RDONLY);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
splice(input_fd, NULL, client_fd, NULL, 1024, SPLICE_F_MORE);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}這個例子展示瞭如何使用 splice 將本地文件直接發送到網絡 socket,以實現高效的數據傳輸。
4.5 適用場景
splice 適用於在文件描述符之間進行高效、直接的數據傳輸,例如從文件到網絡 socket 的傳輸,或在文件、管道和 socket 之間傳遞數據。在這種情況下,數據在內核空間內完成傳輸,無需進入用户空間,從而顯著減少拷貝次數和 CPU 的參與。另外 splice 特別適合需要靈活數據流動和減少 CPU 負擔的場景,例如日誌處理、實時數據流處理等。
4.6 sendfile 與 splice 的區別
雖然 sendfile 和 splice 都是 Linux 提供的零拷貝技術,用於高效地在內核空間傳輸數據,但它們在應用場景和功能上存在一些顯著區別:
數據流動方式:
- sendfile:直接將文件中的數據從內核緩衝區傳輸到 socket 緩衝區,適合文件到網絡的傳輸。適合需要簡單高效的文件到網絡的傳輸場景。
- splice:更靈活,可以在任意文件描述符之間進行數據傳輸,包括文件、管道、socket 等。因此,splice 可以在文件、管道和 socket 之間實現更復雜的數據流轉。
適用場景:
- sendfile:主要用於文件到網絡的傳輸,非常適合文件服務器、流媒體等需要高效傳輸文件的場景。
- splice:更適合複雜的數據流動場景,例如在文件、管道和網絡之間需要多步傳輸或靈活控制數據流向的情況。
靈活性:
- sendfile:用於直接、高效地將文件發送到網絡,雖然操作單一,但性能非常高效。
- splice:可以結合管道使用,實現更復雜的數據流向控制,例如先通過管道對數據進行處理,再發送到目標位置。
5. mmap + write:映射式零拷貝
除了以上兩種方式,mmap + write 也是一種常見的零拷貝實現方式。這種方式主要是通過內存映射來減少數據拷貝的步驟。
5.1 mmap + write 的工作流程
- 使用
mmap系統調用將文件映射到進程的虛擬地址空間中,這樣數據就可以直接在內核空間和用户空間共享,而不需要額外的拷貝操作。 - 使用
write系統調用將映射的內存區域直接寫入到目標文件描述符中(比如網絡 socket),完成數據傳輸。
這種方式減少了數據拷貝,提高了效率,適合需要靈活操作數據後再發送的場景。通過這種方式,數據不需要顯式地從內核空間拷貝到用户空間,而是通過映射的方式共享,從而減少了不必要的拷貝。
5.2 簡單圖解:
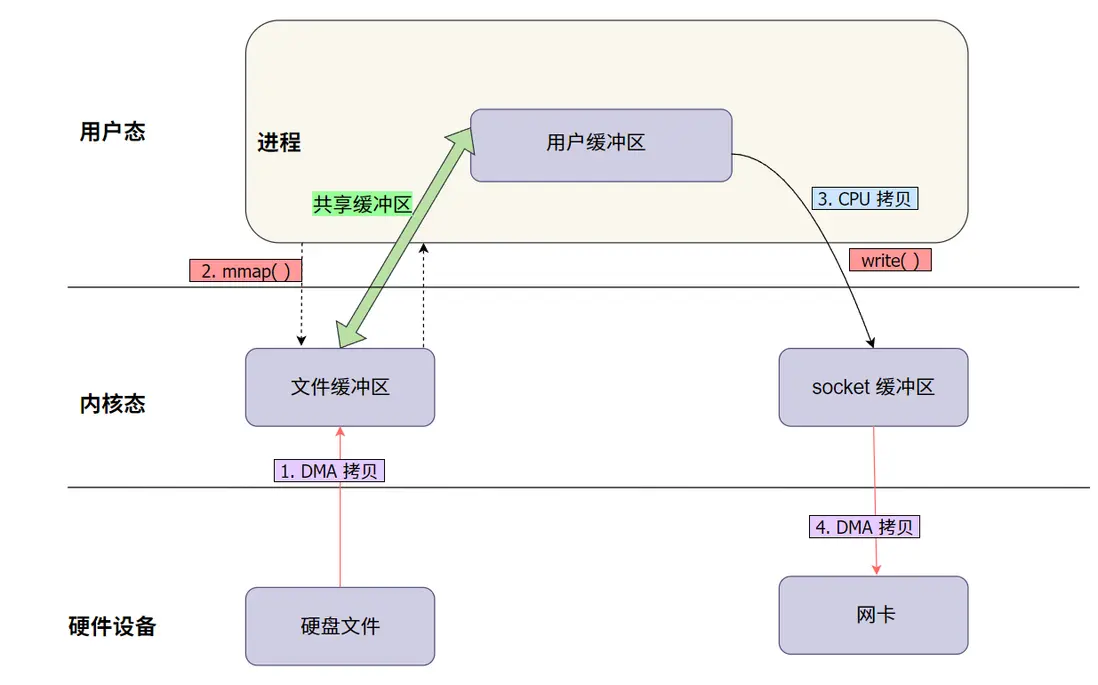
mmap + write 圖解説明:
- 使用
mmap將文件數據映射到進程的虛擬地址空間,避免顯式的數據拷貝。 - 通過
write直接將映射的內存區域數據發送到目標文件描述符(如網絡 socket)。
5.3 mmap 接口説明
mmap 函數的定義如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);addr:指定映射內存的起始地址,通常為NULL由系統決定。length:要映射的內存區域的大小。prot:映射區域的保護標誌,例如PROT_READ、PROT_WRITE。flags:影響映射的屬性,例如MAP_SHARED、MAP_PRIVATE。fd:文件描述符,指向需要映射的文件。offset:文件中的偏移量,表示從文件的哪個位置開始映射。
返回值為映射內存區域的指針,出錯時返回 MAP_FAILED,並設置 errno。
5.4 簡單代碼示例
int main() {
int input_fd = open("input.txt", O_RDONLY);
struct stat file_stat;
fstat(input_fd, &file_stat);
char *mapped = mmap(NULL, file_stat.st_size, PROT_READ, MAP_PRIVATE, input_fd, 0);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
write(client_fd, mapped, file_stat.st_size);
munmap(mapped, file_stat.st_size);
close(input_fd);
close(client_fd);
close(server_fd);
return 0;
}這個例子展示瞭如何使用 mmap 將文件映射到內存,然後通過 write 將數據發送到網絡連接的客户端。
5.5 適用場景
mmap + write 適用於需要對文件數據進行靈活操作的場景,例如需要在發送數據前進行修改或部分處理。與 sendfile 相比,mmap + write 提供了更大的靈活性,因為它允許在用户態訪問數據內容,這對於需要對文件進行預處理的應用場景非常有用,例如壓縮、加密或者數據轉換等。
然而,這種方式也帶來了更多的開銷,因為數據需要在用户態和內核態之間進行交互,這會增加系統調用的成本。因此,mmap + write 更適合那些需要在數據傳輸前進行一些自定義處理的情況,而不太適合純粹的大文件高效傳輸。
6. tee:數據複製的零拷貝方式
tee 是 Linux 中的一種零拷貝方式,它可以把一個管道中的數據複製到另一個管道,同時保留原管道中的數據。這意味着數據可以同時被髮送到多個目標,而不影響原來的數據流,非常適合日誌記錄和實時數據分析等需要把同樣的數據送往不同地方的場景。
6.1 tee 的工作流程
- 數據複製到另一個管道:
tee系統調用可以將一個管道中的數據複製到另一個管道,而不改變原有的數據。這意味着數據可以在內核空間中被同時用於不同的目的,而無需經過用户空間的拷貝。
6.2 tee 接口説明
tee 函數的定義如下:
ssize_t tee(int fd_in, int fd_out, size_t len, unsigned int flags);fd_in:源管道文件描述符,數據從這裏讀取。fd_out:目標管道文件描述符,數據將被寫入這裏。len:要複製的字節數。flags:控制行為的標誌,例如SPLICE_F_NONBLOCK等。
返回值是實際複製的字節數,出錯時返回 -1,並設置 errno 來指示錯誤原因。
6.3 簡單代碼示例
int main() {
int pipe_fd[2];
pipe(pipe_fd);
int server_fd = socket(AF_INET, SOCK_STREAM, 0);
struct sockaddr_in address;
address.sin_family = AF_INET;
address.sin_addr.s_addr = INADDR_ANY;
address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr *)&address, sizeof(address));
listen(server_fd, 3);
int client_fd = accept(server_fd, NULL, NULL);
// 使用 tee 複製數據
tee(pipe_fd[0], pipe_fd[1], 1024, 0);
splice(pipe_fd[0], NULL, client_fd, NULL, 1024, SPLICE_F_MORE);
close(pipe_fd[0]);
close(pipe_fd[1]);
close(client_fd);
close(server_fd);
return 0;
}這個例子展示瞭如何使用 tee 將管道中的數據複製,並通過 splice 將數據發送到網絡 socket,從而實現高效的數據傳輸和複製。
6.4 適用場景
tee 非常適合需要將數據同時發送到多個目標的場景,比如實時數據處理、日誌記錄等。 通過 tee,可以在內核空間內實現多目標數據複製,提高系統性能,減少 CPU 負擔。
總結對比:
下面我將 Linux 的幾種零拷貝方式做了總結,方便大家對比學習:
| 方法 | 描述 | 零拷貝類型 | CPU 參與度 | 適用場景 |
|---|---|---|---|---|
| sendfile | 直接將文件數據發送到套接字,無需拷貝到用户空間。 | 完全零拷貝 | 極少,數據直接傳輸。 | 文件服務器、視頻流傳輸等大文件場景。 |
| splice | 在內核空間內高效地在文件描述符之間傳輸數據。 | 完全零拷貝 | 極少,完全在內核內。 | 文件、管道與 socket 之間的複雜傳輸場景。 |
| mmap + write | 將文件映射到內存並使用 write 發送數據,靈活處理數據 | 部分零拷貝 | 中等,需要映射和寫入。 | 數據需要處理或修改的場景,如壓縮加密。 |
| tee | 將管道中的數據複製到另一個管道,無需消耗原始數據。 | 完全零拷貝 | 極少,數據複製在內核。 | 日誌處理、實時數據監控等多目標場景。 |
最後:
希望這篇文章讓你對 Linux 的零拷貝技術有了更全面、更清晰的瞭解!這些技術看起來可能有些複雜,但一旦掌握後,你會發現它們非常簡單, 並且在實際項目中非常實用。
如果覺得這篇文章對你有幫助,記得給我點個在看和贊 👍,並分享給有需要的小夥伴吧!也歡迎大家來關注我公眾號 「跟着小康學編程」
關注我能學到什麼?
- 這裏分享 Linux C、C++、Go 開發、計算機基礎知識 和 編程面試乾貨等,內容深入淺出,讓技術學習變得輕鬆有趣。
- 無論您是備戰面試,還是想提升編程技能,這裏都致力於提供實用、有趣、有深度的技術分享。快來關注,讓我們一起成長!
怎麼關注我的公眾號?
非常簡單!掃描下方二維碼即可一鍵關注。

此外,小康最近創建了一個技術交流羣,專門用來討論技術問題和解答讀者的疑問。在閲讀文章時,如果有不理解的知識點,歡迎大家加入交流羣提問。我會盡力為大家解答。期待與大家共同進步!