

在一個網絡編程性能優化項目中,利用perf trace進行性能分析。
背景:一個進程負責處理socket消息,在需要處理消息數量達到32k條100+字節的消息量時,耗時大概需要25分鐘
目標:定位耗時的熱區
環境:linux
假設1:用户態耗時多,進程耗時多是消耗在算法計算上?
該進程只進行簡單的消息處理,不涉及過多數據結構和算法,排除該可能性。
假設2:系統態耗時多,進程耗時多是消耗在系統調用上?
由於消息量大,進行了32k*n 數量級的系統調用,假設有可能成立。
在這裏,選擇使用linux的perf工具進行統計分析:
perf trace -p $PID -s
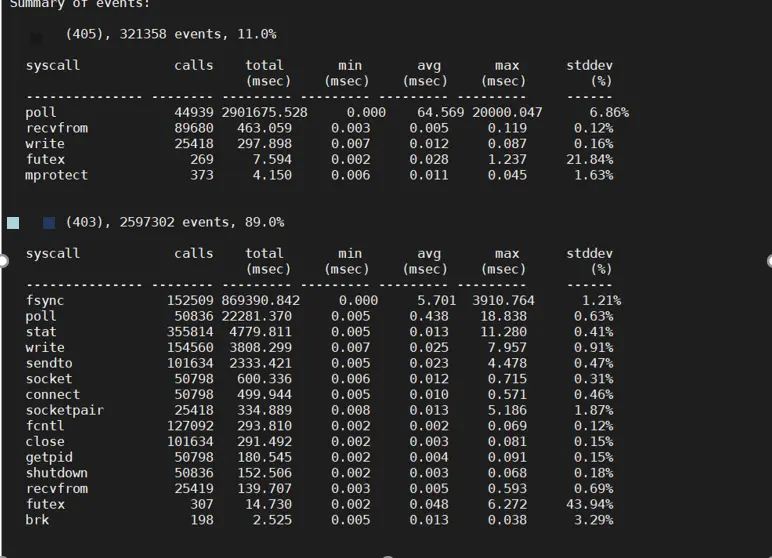
由上圖可見,在處理一條消息的過程中,大致流程涉及到與socket相關的 poll->recvfrom->sendto,同時還有與文件IO相關的系統調用。處理32k條消息,涉及到的系統調用數量在數量級上符合預期。
- 指標統計分析:
fsync(), 該系統調用用時最多,消耗了大概15分鐘。該系統調用用於同步寫入磁盤,調用後會阻塞,直至等待內核緩衝區數據寫入磁盤後,內核才會返回。定位到該系統調用位於進程的日誌模塊。 - 針對該系統調用改善:
業務數據日誌,降低其日誌等級,在運行進程時通過日誌等級開發將對應的等級關閉,減少日誌輸出;同時在日誌模塊中刪除fsync()調用,該類日誌不需要實時同步至磁盤中。
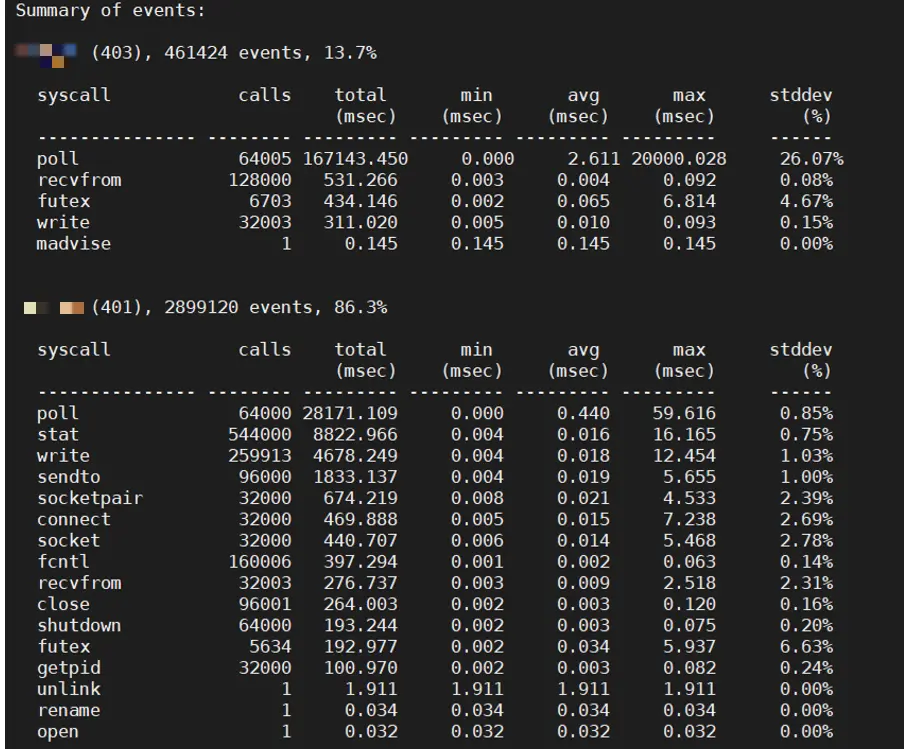
重新執行相同的測試,進程總用時大約50s。從本次檢測到的系統調用指標來看,解決了fsync()帶來了極大的提升空間。
在這個實踐中,可以看到perf trace的一個用處:統計一定時間內的系統調用的次數以及其耗時分佈。
思考1:perf trace統計的系統調用,各列中的時間是系統時間還是時鐘時間?個人認為是時鐘時間,因為儘管是系統調用,內核態也會處於一種阻塞狀態,該狀態不消耗CPU資源。例如進程調用fsync(),陷入內核態,DMA把系統緩衝區的數據同步至磁盤,此過程進程睡眠,沒有佔用CPU資源,同步至磁盤完成後,DMA會中斷,CPU進行響應處理,此時fsync()調用結束,返回用户態。