


在本次案例中,京東雲的中台技術工程師遇到了來自客户提出的打破K8s產品功能限制的特殊需求,面對這個極具挑戰的任務,攻城獅最終是否克服了重重困難,幫助客户完美實現了需求?且看本期K8s技術案例分享!(友情提示:文章篇幅較長,建議各位看官先收藏再閲讀,同時在閲讀過程中注意勞逸結合,保持身心健康!)
第一部分:“頗有個性”的需求
某日,我們京東雲的技術中台工程師接到了客户的求助。客户在雲上環境使用了託管K8s集羣產品部署測試集羣。因業務需要,研發同事需要在辦公網環境能直接訪問K8s集羣的clueterIP類型的service和後端的pod。通常K8s的pod只能在集羣內通過其他pod或者集羣node訪問,不能直接在集羣外進行訪問。而pod對集羣內外提供服務時需要通過service對外暴露訪問地址和端口,service除了起到pod應用訪問入口的作用,還會對pod的相應端口進行探活,實現健康檢查。同時當後端有多個Pod時,service還將根據調度算法將客户端請求轉發至不同的pod,實現負載均衡的作用。常用的service類型有如下幾種:
service類型簡介
1、 clusterIP類型,創建service時如果不指定類型的話的默認會創建該類型service,clusterIP類型的service只能在集羣內通過cluster IP被pod和node訪問,集羣外無法訪問。通常像K8s集羣系統服務kubernetes等不需要對集羣外提供服務,只需要在集羣內部進行訪問的service會使用這種類型;
2、 nodeport類型,為了解決集羣外部對service的訪問需求,設計了nodeport類型,將service的端口映射至集羣每個節點的端口上。當集羣外訪問service時,通過對節點IP和指定端口的訪問,將請求轉發至後端pod;
3、 loadbalancer類型,該類型通常需要調用雲廠商的API接口,在雲平台上創建負載均衡產品,並根據設置創建監聽器。在K8s內部,loadbalancer類型服務實際上還是和nodeport類型一樣將服務端口映射至每個節點的固定端口上。然後將節點設置為負載均衡的後端,監聽器將客户端請求轉發至後端節點上的服務映射端口,請求到達節點端口後,再轉發至後端pod。Loadbalancer類型的service彌補了nodeport類型有多個節點時客户端需要訪問多個節點IP地址的不足,只要統一訪問LB的IP即可。同時使用LB類型的service對外提供服務,K8s節點無需綁定公網IP,只需要給LB綁定公網IP即可,提升了節點安全性,也節約了公網IP資源。利用LB對後端節點的健康檢查功能,可實現服務高可用。避免某個K8s節點故障導致服務無法訪問。
Part1小結
通過對K8s集羣service類型的瞭解,我們可以知道客户想在集羣外對service進行訪問,首先推薦使用的是LB類型的service。由於目前K8s集羣產品的節點還不支持綁定公網IP,因此使用nodeport類型的service無法實現通過公網訪問,除非客户使用專線連接或者IPSEC將自己的辦公網與雲上網絡打通,才能訪問nodeport類型的service。而對於pod,只能在集羣內部使用其他pod或者集羣節點進行訪問。同時K8s集羣的clusterIP和pod設計為不允許集羣外部訪問,也是出於提高安全性的考慮。如果將訪問限制打破,可能會導致安全問題發生。所以我們的建議客户還是使用LB類型的service對外暴露服務,或者從辦公網連接K8s集羣的NAT主機,然後通過NAT主機可以連接至K8s節點,再訪問clusterIP類型的service,或者訪問後端pod。
客户表示目前測試集羣的clusterIP類型服務有上百個,如果都改造成LB類型的service就要創建上百個LB實例,綁定上百個公網IP,這顯然是不現實的,而都改造成Nodeport類型的service的工作量也十分巨大。同時如果通過NAT主機跳轉登錄至集羣節點,就需要給研發同事提供NAT主機和集羣節點的系統密碼,不利於運維管理,從操作便利性上也不如研發可以直接通過網絡訪問service和pod簡便。
第二部分:方法總比困難多?
雖然客户的訪問方式違背了K8s集羣的設計邏輯,顯得有些“非主流”,但是對於客户的使用場景來説也是迫不得已的強需求。作為技術中台的攻城獅,我們要盡最大努力幫助客户解決技術問題!因此我們根據客户的需求和場景架構,來規劃實現方案。
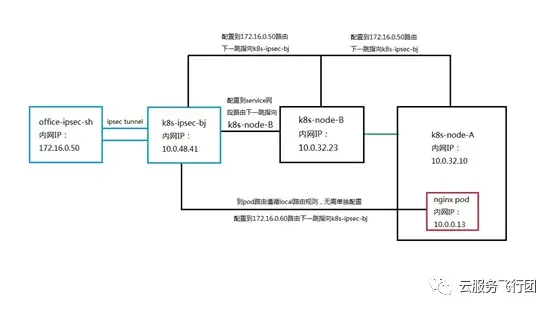
既然是網絡打通,首先要從客户的辦公網和雲上K8s集羣網絡架構分析。客户辦公網有統一的公網出口設備,而云上K8s集羣的網絡架構如下,K8s集羣master節點對用户不可見,用户創建K8s集羣后,會在用户選定的VPC網絡下創建三個子網。分別是用於K8s節點通訊的node子網,用於部署NAT主機和LB類型serivce創建的負載均衡實例的NAT與LB子網,以及用於pod通訊的pod子網。K8s集羣的節點搭建在雲主機上,node子網訪問公網地址的路由下一跳指向NAT主機,也就是説集羣節點不能綁定公網IP,使用NAT主機作為統一的公網訪問出口,做SNAT,實現公網訪問。由於NAT主機只有SNAT功能,沒有DNAT功能,因此也就無法從集羣外通過NAT主機訪問node節點。
關於pod子網的規劃目的,首先要介紹下pod在節點上的網絡架構。如下圖所示:
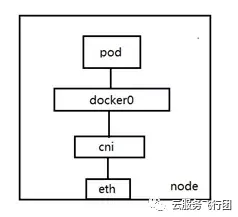
在節點上,pod中的容器通過veth對與docker0設備連通,而docker0與節點的網卡之間通過自研CNI網絡插件連通。為了實現集羣控制流量與數據流量的分離,提高網絡性能,集羣在每個節點上單獨綁定彈性網卡,專門供pod通訊使用。創建pod時,會在彈性網卡上為Pod分配IP地址。每個彈性網卡最多可以分配21個IP,當一張彈性網卡上的IP分配滿後,會再綁定一張新的網卡供後續新建的pod使用。彈性網卡所屬的子網就是pod子網,基於這樣的架構,可以降低節點eth0主網卡的負載壓力,實現控制流量與數據流量分離,同時pod的IP在VPC網絡中有實際對應的網絡接口和IP,可實現VPC網絡內對pod地址的路由。
你需要了解的打通方式
瞭解完兩端的網絡架構後我們來選擇打通方式。通常將雲下網絡和雲上網絡打通,有專線產品連接方式,或者用户自建VPN連接方式。專線產品連接需要佈設從客户辦公網到雲上機房的網絡專線,然後在客户辦公網側的網絡出口設備和雲上網絡側的bgw邊界網關配置到彼此對端的路由。如下圖所示:

基於現有專線產品BGW的功能限制,雲上一側的路由只能指向K8s集羣所在的VPC,無法指向具體的某個K8s節點。而想要訪問clusterIP類型service和pod,必須在集羣內的節點和pod訪問。因此訪問service和pod的路由下一跳,必須是某個集羣節點。所以使用專線產品顯然是無法滿足需求的。
我們來看自建VPN方式,自建VPN在客户辦公網和雲上網絡各有一個有公網IP的端點設備,兩個設備之間建立加密通訊隧道,實際底層還是基於公網通訊。如果使用該方案,雲上的端點我們可以選擇和集羣節點在同一VPC的不同子網下的有公網IP的雲主機。辦公網側對service和pod的訪問數據包通過VPN隧道發送至雲主機後,可以通過配置雲主機所在子網路由,將數據包路由至某個集羣節點,然後在集羣節點所在子網配置到客户端的路由下一跳指向端點雲主機,同時需要在pod子網也做相同的路由配置。至於VPN的實現方式,通過和客户溝通,我們選取ipsec隧道方式。
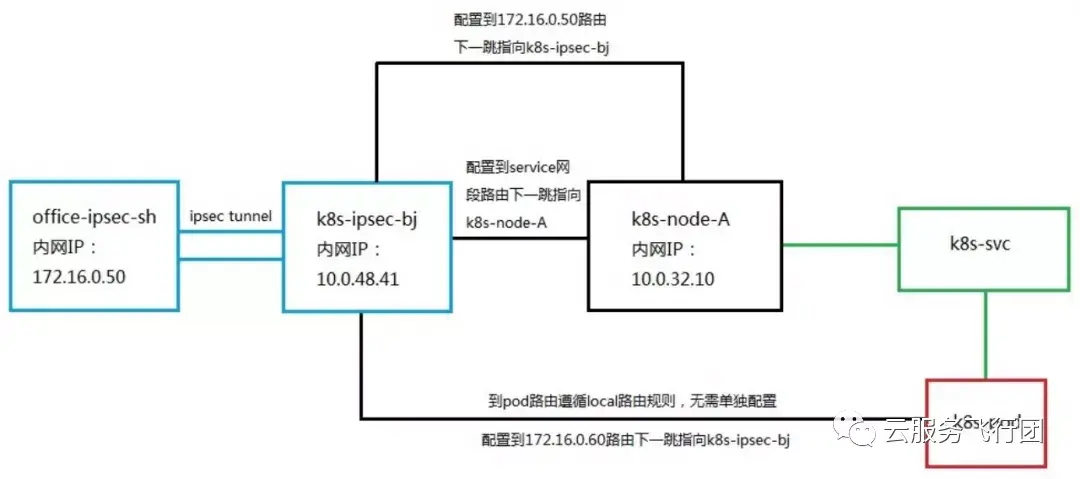
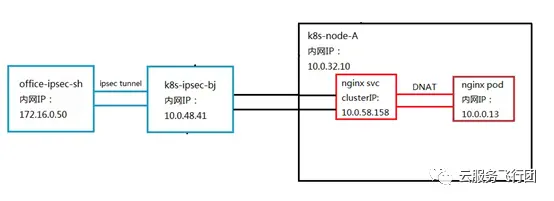
確定了方案,我們需要在測試環境實施方案驗證可行性。由於我們沒有云下環境,因此選取和K8s集羣不同地域的雲主機代替客户的辦公網端點設備。在華東上海地域創建雲主機office-ipsec-sh模擬客户辦公網客户端,在華北北京地域的K8s集羣K8s-BJTEST01所在VPC的NAT/LB子網創建一個有公網IP的雲主機K8s-ipsec-bj,模擬客户場景下的ipsec雲上端點,與華東上海雲主機office-ipsec-sh建立ipsec隧道。設置NAT/LB子網的路由表,添加到service網段的路由下一跳指向K8s集羣節點K8s-node-vmlppp-bs9jq8pua,以下簡稱node A。由於pod子網和NAT/LB子網同屬於一個VPC,所以無需配置到pod網段的路由,訪問pod時會直接匹配local路由,轉發至對應的彈性網卡上。為了實現數據包的返回,在node子網和pod子網分別配置到上海雲主機office-ipsec-sh的路由,下一跳指向K8s-ipsec-bj。完整架構如下圖所示:
第三部分:實踐出“問題”
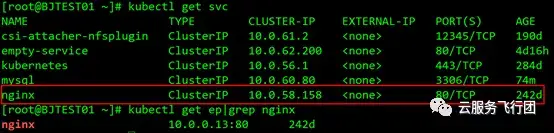
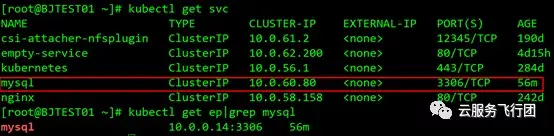
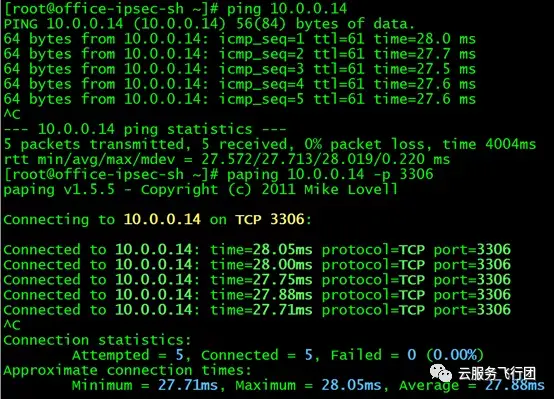
既然確定了方案,我們就開始搭建環境了。首先在K8s集羣的NAT/LB子網創建K8s-ipsec-bj雲主機,並綁定公網IP。然後與上海雲主機office-ipsec-sh建立ipsec隧道。關於ipsec部分的配置方法網絡上有很多文檔,在此不做詳細敍述,有興趣的童鞋可以參照文檔自己實踐下。隧道建立後,在兩端互ping對端的內網IP,如果可以ping通的話,證明ipsec工作正常。按照規劃配置好NAT/LB子網和node子網以及pod子網的路由。我們在K8s集羣的serivce中,選擇一個名為nginx的serivce,clusterIP為10.0.58.158,如圖所示:
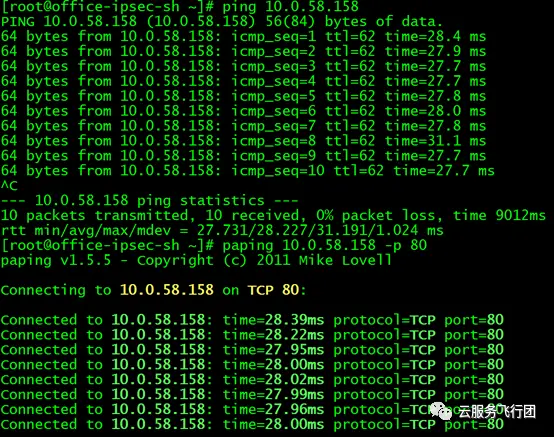
該服務後端的pod是10.0.0.13,部署nginx默認頁面,並監聽80端口。在上海雲主機上測試ping service的IP 10.0.58.158,可以ping通,同時使用paping工具ping服務的80端口,也可以ping通!
使用curl http://10.0.58.158進行http請求,也可以成功!
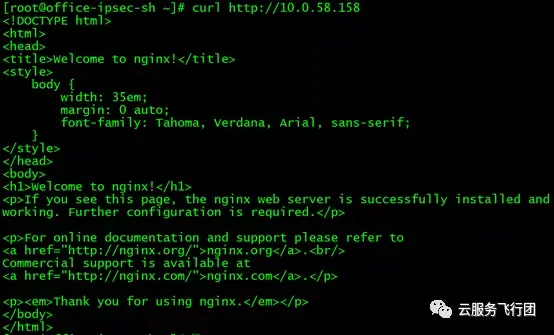
再測試直接訪問後端pod,也沒有問題:)
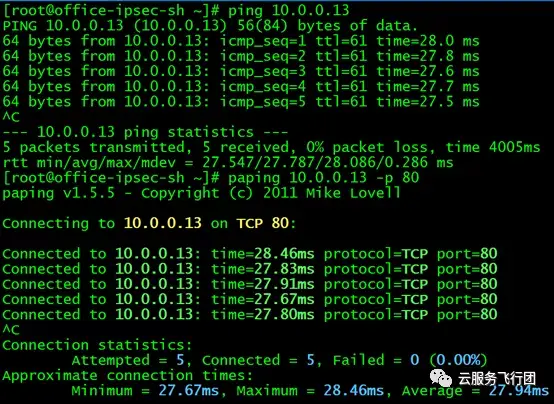
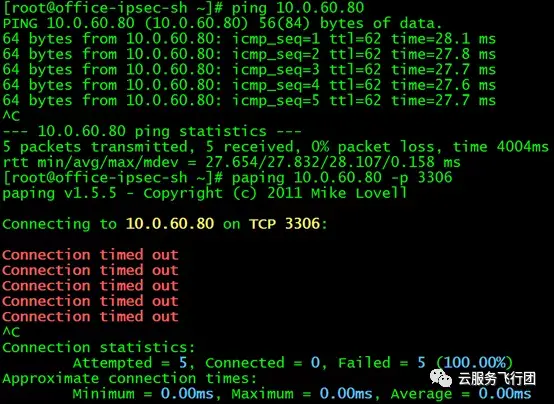
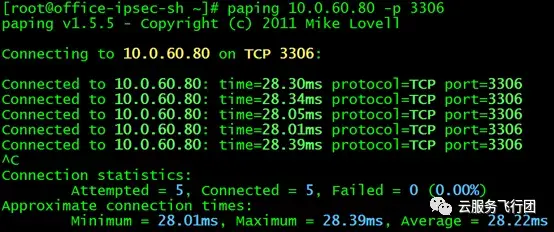
正當攻城獅心裏美滋滋,以為一切都大功告成的時候,測試訪問另一個service的結果猶如一盆冷水潑來。我們接着選取了mysql這個service,測試訪問3306端口。該serivce的clusterIP是10.0.60.80,後端pod的IP是10.0.0.14。
在上海雲主機直接ping service的clusterIP,沒有問題。但是paping 3306端口的時候,居然不通了!
然後我們測試直接訪問serivce的後端pod,詭異的是,後端pod無論是ping IP還是paping 3306端口,都是可以連通的!
腫麼回事?
這是腫麼回事?經過攻城獅一番對比分析,發現兩個serivce唯一的不同是,可以連通nginx服務的後端pod 10.0.0.13就部署在客户端請求轉發到的node A上。而不能連通的mysql服務的後端pod不在node A上,在另一個節點上。為了驗證問題原因是否就在於此,我們單獨修改NAT/LB子網路由,到mysql服務的下一跳指向後端pod所在的節點。然後再次測試。果然!現在可以訪問mysql服務的3306端口了!
第四部分:三個為什麼?
此時此刻,攻城獅的心中有三個疑問:
(1)為什麼請求轉發至service後端pod所在的節點時可以連通?
(2)為什麼請求轉發至service後端pod不在的節點時不能連通?
(3)為什麼不管轉發至哪個節點,service的IP都可以ping通?
深入分析,消除問號
為了消除我們心中的小問號,我們就要深入分析,瞭解導致問題的原因,然後再對症下藥。既然要排查網絡問題,當然還是要祭出經典法寶——tcpdump抓包工具。為了把焦點集中,我們對測試環境的架構進行了調整。上海到北京的ipsec部分維持現有架構不變,我們對K8s集羣節點進行擴容,新建一個沒有任何pod的空節點K8s-node-vmcrm9-bst9jq8pua,以下簡稱node B,該節點只做請求轉發。修改NAT/LB子網路由,訪問service地址的路由下一跳指向該節點。測試的service我們選取之前使用的nginx服務10.0.58.158和後端pod 10.0.0.13,如下圖所示:
當需要測試請求轉發至pod所在節點的場景時,我們將service路由下一跳修改為K8s-node-A即可。
萬事俱備,讓我們開啓解惑之旅!Go Go Go!
首先探究疑問1場景,我們在K8s-node-A上執行命令抓取與上海雲主機172.16.0.50的包,命令如下:
tcpdump -i any host 172.16.0.50 -w /tmp/dst-node-client.cap
各位童鞋是否還記得我們之前提到過,在託管K8s集羣中,所有pod的數據流量均通過節點的彈性網卡收發?在K8s-node-A上pod使用的彈性網卡是eth1。我們首先在上海雲主機上使用curl命令請求http://10.0.58.158,同時執行命令抓取K8s-node-A的eth1上是否有pod 10.0.0.13的包收發,命令如下:
tcpdump –i eth1 host 10.0.0.13
結果如下圖:

並沒有任何10.0.0.13的包從eth1收發,但此時上海雲主機上的curl操作是可以請求成功的,説明10.0.0.13必然給客户端回包了,但是並沒有通過eth1回包。那麼我們將抓包範圍擴大至全部接口,命令如下:
tcpdump -i any host 10.0.0.13
結果如下圖:
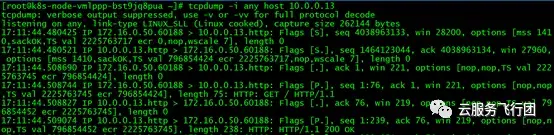
可以看到這次確實抓到了10.0.0.13和172.16.0.50交互的數據包,為了便於分析,我們使用命令tcpdump -i any host 10.0.0.13 -w /tmp/dst-node-pod.cap將包輸出為cap文件。
同時我們再執行tcpdump -i any host 10.0.58.158,對service IP進行抓包。
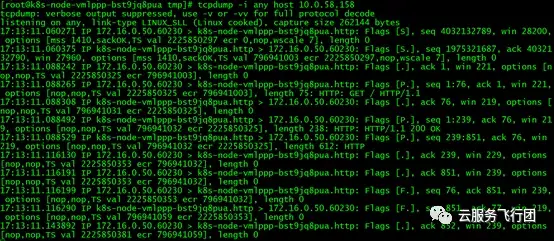
可以看到172.16.0.50執行curl請求時可以抓到數據包,且只有10.0.58.158與172.16.0.50交互的數據包,不執行請求時沒有數據包。由於這一部分數據包會包含在對172.16.0.50的抓包中,因此我們不再單獨分析。
將針對172.16.0.50和10.0.0.13的抓包文件取出,使用wireshark工具進行分析,首先分析對客户端172.16.0.50的抓包,詳情如下圖所示:
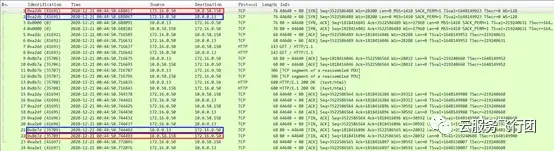
可以發現客户端172.16.0.50先給service IP 10.0.58.158發了一個包,然後又給pod IP 10.0.0.13發了一個包,兩個包的ID,內容等完全一致。而最後回包時,pod 10.0.0.13給客户端回了一個包,然後service IP 10.0.58.158也給客户端回了一個ID和內容完全相同的包。這是什麼原因導致的呢?
通過之前的介紹,我們知道service將客户端請求轉發至後端pod,在這個過程中客户端請求的是service的IP,然後service會做DNAT(根據目的IP做NAT轉發),將請求轉發至後端的pod IP。雖然我們抓包看到的是客户端發了兩次包,分別發給service和pod,實際上客户端並沒有重新發包,而是由service完成了目的地址轉換。而pod回包時,也是將包回給service,然後再由service轉發給客户端。因為是相同節點內請求,這一過程應該是在節點的內部虛擬網絡中完成,所以我們在pod使用的eth1網卡上並沒有抓到和客户端交互的任何數據包。再結合pod維度的抓包,我們可以看到針對client抓包時抓到的http get請求包在對pod的抓包中也能抓到,也驗證了我們的分析。


那麼pod是通過哪個網絡接口進行收發包的呢?執行命令netstat -rn查看node A上的網絡路由,我們有了如下發現:
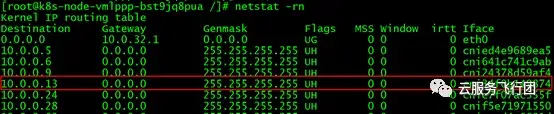
在節點內,所有訪問10.0.0.13的路由都指向了cni34f0b149874這個網絡接口。很顯然這個接口是CNI網絡插件創建的虛擬網絡設備。為了驗證pod所有的流量是否都通過該接口收發,我們再次在客户端請求service地址,在node A以客户端維度和pod維度抓包,但是這次以pod維度抓包時,我們不再使用-i any參數,而是替換為-i cni34f0b149874。抓包後分析對比,發現如我們所料,客户端對pod的所有請求包都能在對cni34f0b149874的抓包中找到,同時對系統中除了cni34f0b149874之外的其他網絡接口抓包,均沒有抓到與客户端交互的任何數據包。因此可以證明我們的推斷正確。
綜上所述,在客户端請求轉發至pod所在節點時,數據通路如下圖所示:
接下來我們探究最為關心的問題2場景,修改NAT/LB子網路由到service的下一跳指向新建節點node B,如圖所示
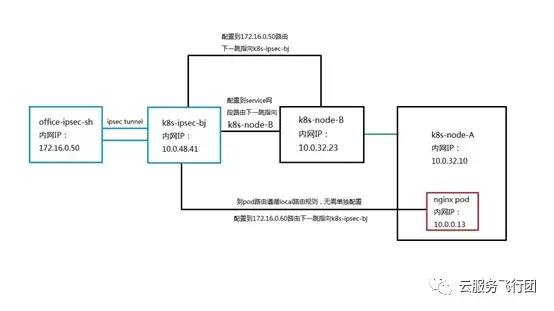
這次我們需要在node B和node A上同時抓包。在客户端還是使用curl方式請求service地址。在轉發節點node B上,我們先執行命令tcpdump -i eth0 host 10.0.58.158抓取service維度的數據包,發現抓取到了客户端到service的請求包,但是service沒有任何回包,如圖所示:
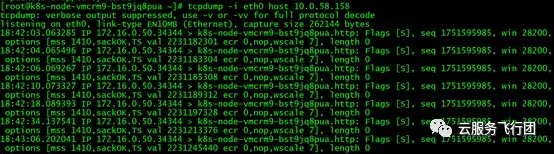
各位童鞋可能會有疑惑,為什麼抓取的是10.0.58.158,但抓包中顯示的目的端是該節點名?實際上這與service的實現機制有關。在集羣中創建service後,集羣網絡組件會在各個節點上都選取一個隨機端口進行監聽,然後在節點的iptables中配置轉發規則,凡是在節點內請求service IP均轉發至該隨機端口,然後由集羣網絡組件進行處理。所以在節點內訪問service時,實際訪問的是節點上的某個端口。如果將抓包導出為cap文件,可以看到請求的目的IP仍然是10.0.58.158,如圖所示:

這也解釋了為什麼clusterIP只能在集羣內的節點或者pod訪問,因為集羣外的設備沒有K8s網絡組件創建的iptables規則,不能將請求service地址轉為請求節點的端口,即使數據包發送至集羣,由於service的clusterIP在節點的網絡中實際是不存在的,因此會被丟棄。(奇怪的姿勢又增長了呢)
回到問題本身,在轉發節點上抓取service相關包,發現service沒有像轉發到pod所在節點時給客户端回包。我們再執行命令tcpdump -i any host 172.16.0.50 -w /tmp/fwd-node-client.cap以客户端維度抓包,包內容如下:

我們發現客户端請求轉發節點node B上的service後,service同樣做了DNAT,將請求轉發到node A上的10.0.0.13。但是在轉發節點上沒有收到10.0.0.13回給客户端的任何數據包,之後客户端重傳了幾次請求包,均沒有迴應。
那麼node A是否收到了客户端的請求包呢?pod又有沒有給客户端回包呢?我們移步node A進行抓包。在node B上的抓包我們可以獲悉node A上應該只有客户端IP和pod IP的交互,因此我們就從這兩個維度抓包。根據之前抓包的分析結果,數據包進入節點內之後,應該通過虛擬設備cni34f0b149874與pod交互。而node B節點訪問pod應該從node A的彈性網卡eth1進入節點,而不是eth0,為了驗證,首先執行命令tcpdump -i eth0 host 172.16.0.50和tcpdump -i eth0 host 10.0.0.13,沒有抓到任何數據包。
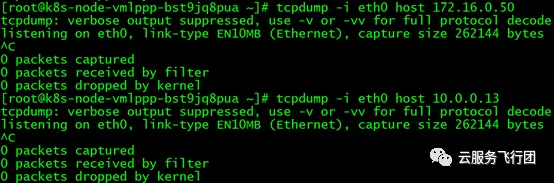
説明數據包沒有走eth0。再分別執行tcpdump -i eth1 host 172.16.0.50 -w /tmp/dst-node-client-eth1.cap和tcpdump -i cni34f0b149874 host 172.16.0.50 -w /tmp/dst-node-client-cni.cap抓取客户端維度數據包,對比發現數據包內容完全一致,説明數據包從eth1進入Node A後,通過系統內路由轉發至cni34f0b149874。數據包內容如下:

可以看到客户端給pod發包後,pod給客户端回了包。執行tcpdump -i eth1 host 10.0.0.13 -w /tmp/dst-node-pod-eth1.cap和tcpdump -i host 10.0.0.13 -w /tmp/dst-node-pod-cni.cap抓取pod維度數據包,對比發現數據包內容完全一致,説明pod給客户端的回包通過cni34f0b149874發出,然後從eth1網卡離開node A節點。數據包內容也可以看到pod給客户端返回了包,但沒有收到客户端對於返回包的迴應,觸發了重傳。

那麼既然pod的回包已經發出,為什麼node B上沒有收到回包,客户端也沒有收到回包呢?查看eth1網卡所屬的pod子網路由表,我們恍然大悟!

由於pod給客户端回包是從node A的eth1網卡發出的,所以雖然按照正常DNAT規則,數據包應該發回給node B上的service端口,但是受eth1子網路由表影響,數據包直接被“劫持”到了K8s-ipsec-bj這個主機上。而數據包到了這個主機上之後,由於沒有經過service的轉換,回包的源地址是pod地址10.0.0.13,目的地址是172.16.0.50,這個數據包回覆的是源地址172.16.0.50,目的地址10.0.58.158這個數據包。相當於請求包的目的地址和回覆包的源地址不一致,對於K8s-ipsec-bj來説,只看到了10.0.0.13給172.16.0.50的reply包,但是沒有收到過172.16.0.50給10.0.0.13的request包,雲平台虛擬網絡的機制是遇到只有reply包,沒有request包的情況會將request包丟棄,避免利用地址欺騙發起網絡攻擊。所以客户端不會收到10.0.0.13的回包,也就無法完成對service的請求。在這個場景下,數據包的通路如下圖所示:
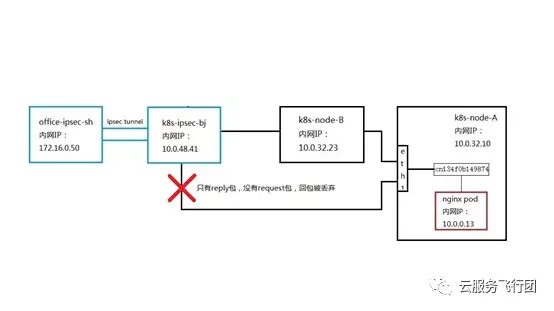
此時客户端可以成功請求pod的原因也一目瞭然 ,請求pod的數據通路如下:
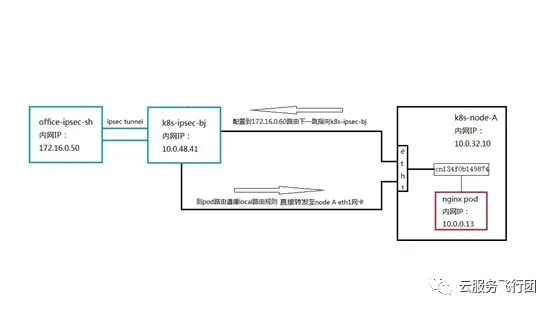
請求包和返回包的路徑一致,都經過K8s-ipsec-bj節點且源目IP沒有發生改變,因此pod可以連通。
看到這裏,機智的童鞋可能已經想到,那修改eth1所屬的pod子網路由,讓去往172.16.0.50的數據包下一跳不發送到K8s-ipsec-bj,而是返回給K8s-node-B,不就可以讓回包沿着來路原路返回,不會被丟棄嗎?是的,經過我們的測試驗證,這樣確實可以使客户端成功請求服務。但是別忘了,用户還有一個需求是客户端可以直接訪問後端pod,如果pod回包返回給node B,那麼客户端請求pod時的數據通路是怎樣的呢?
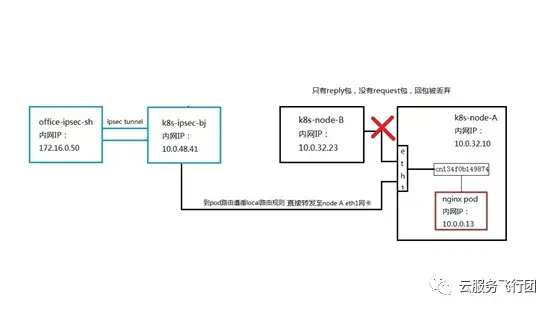
如圖所示,可以看到客户端對Pod的請求到達K8s-ipsec-bj後,由於是同一vpc內的地址訪問,所以遵循local路由規則直接轉發到node A eth1網卡,而pod給客户端回包時,受eth1網卡路由控制,發送到了node B上。node B之前沒有收到過客户端對pod的request包,同樣會遇到只有reply包沒有request包的問題,所以回包被丟棄,客户端無法請求pod。
至此,我們搞清楚了為什麼客户端請求轉發至service後端pod不在的節點上時無法成功訪問service的原因。那麼為什麼在此時雖然請求service的端口失敗,但是可以ping通service地址呢?攻城獅推斷,既然service對後端的pod起到DNAT和負載均衡的作用,那麼當客户端ping service地址時,ICMP包應該是由service直接應答客户端的,即service代替後端pod答覆客户端的ping包。為了驗證我們的推斷是否正確,我們在集羣中新建一個沒有關聯任何後端的空服務,如圖所示:
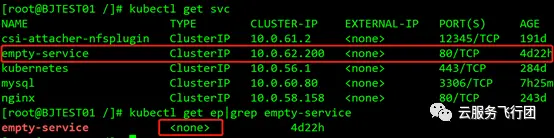
然後在客户端ping 10.0.62.200,結果如下:
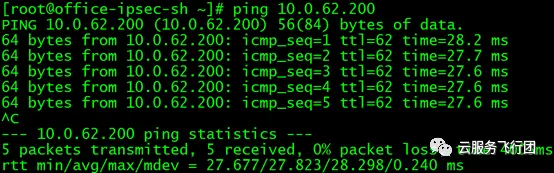
果不其然,即使service後端沒有任何pod,也可以ping通,因此證明ICMP包均為service代答,不存在實際請求後端pod時的問題,因此可以ping通。
第五部分:天無絕人之路
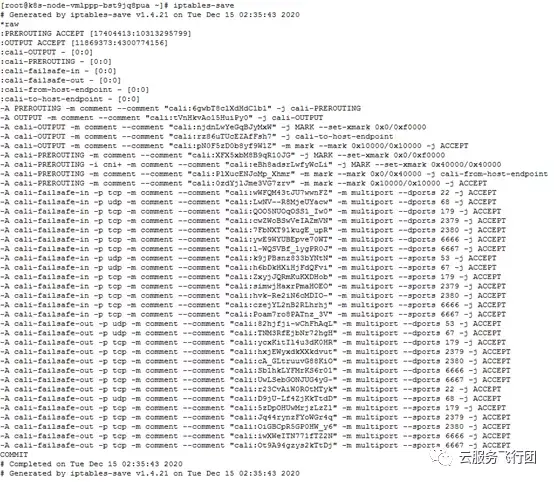
既然費盡周折找到了訪問失敗的原因,接下來我們就要想辦法解決這個問題。事實上只要想辦法讓pod跨節點給客户端回包時隱藏自己的IP,對外顯示的是service的IP,就可以避免包被丟棄。原理上類似於SNAT(基於源IP的地址轉換)。可以類比為沒有公網IP的局域網設備有自己的內網IP,當訪問公網時需要通過統一的公網出口,而此時外部看到的客户端IP是公網出口的IP,並不是局域網設備的內網IP。實現SNAT,我們首先會想到通過節點操作系統上的iptables規則。我們在pod所在節點node A上執行iptables-save命令,查看系統已有的iptables規則都有哪些。
敲黑板,注意啦
可以看到系統創建了近千條iptables規則,大多數與K8s有關。我們重點關注上圖中的nat類型規則,發現了有如下幾條引起了我們的注意:

首先看紅框部分規則
-A KUBE-SERVICES -m comment --comment "Kubernetes service cluster ip + port for masquerade purpose" -m set --match-set KUBE-CLUSTER-IP src,dst -j KUBE-MARK-MASQ
該規則表示如果訪問的源地址或者目的地址是cluster ip +端口,出於masquerade目的,將跳轉至KUBE-MARK-MASQ鏈,masquerade也就是地址偽裝的意思!在NAT轉換中會用到地址偽裝。
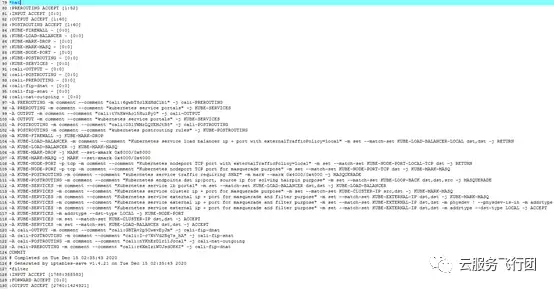
接下來看藍框部分規則
-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000
該規則表示對於數據包打上需要做地址偽裝的標記0x4000/0x4000。
最後看黃框部分規則
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
該規則表示對於標記為0x4000/0x4000需要做SNAT的數據包,將跳轉至MASQUERADE鏈進行地址偽裝。
這三條規則所做的操作貌似正是我們需要iptables幫我們實現的,但是從之前的測試來看顯然這三條規則並沒有生效。這是為什麼呢?是否是K8s的網絡組件裏有某個參數控制着是否會對訪問clusterIP時的數據包進行SNAT?
這就要從負責service與pod之間網絡代理轉發的組件——kube-proxy的工作模式和參數進行研究了。我們已經知道service會對後端pod進行負載均衡和代理轉發,要想實現該功能,依賴的是kube-proxy組件,從名稱上可以看出這是一個代理性質的網絡組件。它以pod形式運行在每個K8s節點上,當以service的clusterIP+端口方式訪問時,通過iptables規則將請求轉發至節點上對應的隨機端口,之後請求由kube-proxy組件接手處理,通過kube-proxy內部的路由和調度算法,轉發至相應的後端Pod。最初,kube-proxy的工作模式是userspace(用户空間代理)模式,kube-proxy進程在這一時期是一個真實的TCP/UDP代理,類似HA Proxy。由於該模式在1.2版本K8s開始已被iptables模式取代,在此不做贅述,有興趣的童鞋可以自行研究下。
1.2版本引入的iptables模式作為kube-proxy的默認模式,kube-proxy本身不再起到代理的作用,而是通過創建和維護對應的iptables規則實現service到pod的流量轉發。但是依賴iptables規則實現代理存在無法避免的缺陷,在集羣中的service和pod大量增加後,iptables規則的數量也會急劇增加,會導致轉發性能顯著下降,極端情況下甚至會出現規則丟失的情況。
為了解決iptables模式的弊端,K8s在1.8版本開始引入IPVS(IP Virtual Server)模式。IPVS模式專門用於高性能負載均衡,使用更高效的hash表數據結構,為大型集羣提供了更好的擴展性和性能。比iptables模式支持更復雜的負載均衡調度算法等。託管集羣的kube-proxy正是使用了IPVS模式。
但是IPVS模式無法提供包過濾,地址偽裝和SNAT等功能,所以在需要使用這些功能的場景下,IPVS還是要搭配iptables規則使用。等等,地址偽裝和SNAT,這不正是我們之前在iptables規則中看到過的?這也就是説,iptables在不進行地址偽裝和SNAT時,不會遵循相應的iptables規則,而一旦設置了某個參數開啓地址偽裝和SNAT,之前看到的iptables規則就會生效!於是我們到kubernetes官網查找kube-proxy的工作參數,有了令人激動的發現:

好一個驀然回首!攻城獅的第六感告訴我們,--masquerade-all參數就是解決我們問題的關鍵!
第六部分:真·方法比困難多
我們決定測試開啓下--masquerade-all這個參數。kube-proxy在集羣中的每個節點上以pod形式運行,而kube-proxy的參數配置都以configmap形式掛載到pod上。我們執行kubectl get cm -n kube-system查看kube-proxy的configmap,如圖所示:
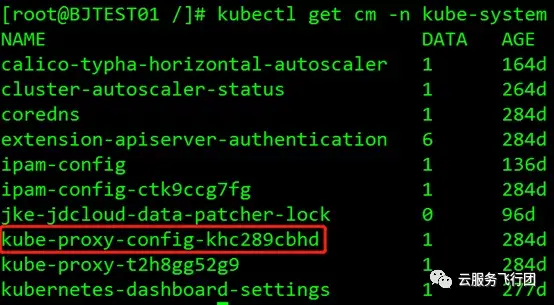
紅框裏的就是kube-proxy的配置configmap,執行kubectl edit cm kube-proxy-config-khc289cbhd -n kube-system編輯這個configmap,如圖所示
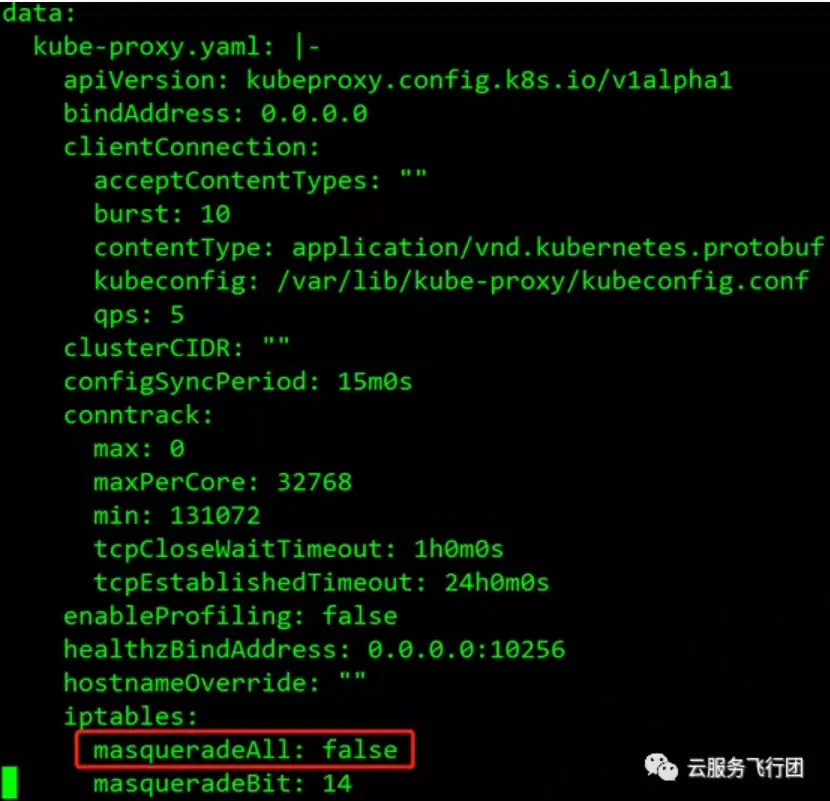
找到了masqueradeALL參數,默認是false,我們修改為true,然後保存修改。
要想使配置生效,需要逐一刪除當前的kube-proxy pod,daemonset會自動重建pod,重建的pod會掛載修改過的configmap,masqueradeALL功能也就開啓了。如圖所示:
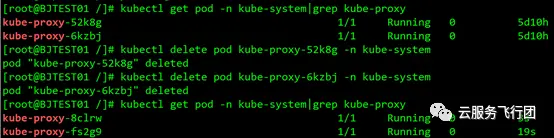
期待地搓手手
接下來激動人心的時刻到來了,我們將訪問service的路由指向node B,然後在上海客户端上執行paping 10.0.58.158 -p 80觀察測試結果(期待地搓手手):
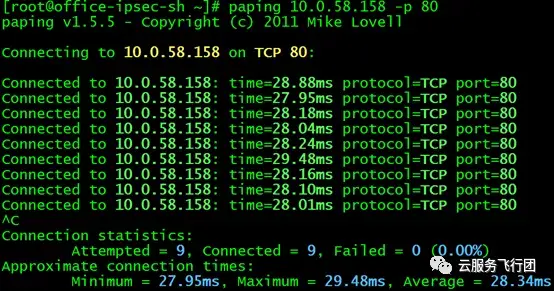
此情此景,不禁讓攻城獅流下了欣喜的淚水……
再測試下curl http://10.0.58.158 同樣可以成功!奧力給~
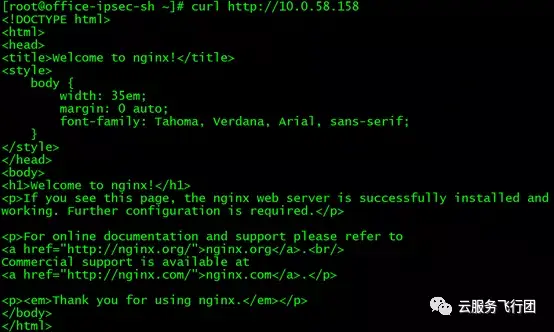
再測試下直接訪問後端Pod,以及請求轉發至pod所在節點,都沒有問題。至此客户的需求終於卍解,長舒一口氣!
大結局:知其所以然
雖然問題已經解決,但是我們的探究還沒有結束。開啓masqueradeALL參數後,service是如何對數據包做SNAT,避免了之前的丟包問題呢?還是通過抓包進行分析。
首先分析轉發至pod不在的節點時的場景,客户端請求服務時,在pod所在節點對客户端IP進行抓包,沒有抓到任何包。

説明開啓參數後,到後端pod的請求不再是以客户端IP發起的。
在轉發節點對pod IP進行抓包可以抓到轉發節點的service端口與pod之間的交互包。
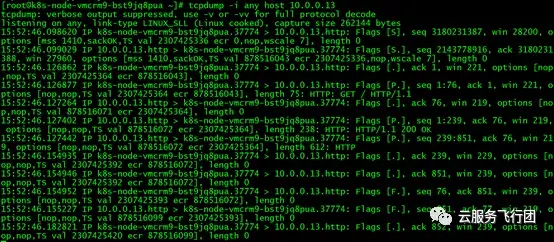
説明pod沒有直接回包給客户端172.16.0.50。這樣看來,相當於客户端和pod互相不知道彼此的存在,所有交互都通過service來轉發。
再在轉發節點對客户端進行抓包,包內容如下:

同時在pod所在節點對pod進行抓包,包內容如下:

可以看到轉發節點收到序號708的curl請求包後,在pod所在節點收到了序號相同的請求包,只不過源目IP從172.16.0.50/10.0.58.158轉換為了10.0.32.23/10.0.0.13。這裏10.0.32.23是轉發節點的內網IP,實際上就是節點上service對應的隨機端口,所以可以理解為源目IP轉換為了10.0.58.158/10.0.0.13。而回包時的流程相同,pod發出序號17178的包,轉發節點將相同序號的包發給客户端,源目IP從10.0.0.13/10.0.58.158轉換為了10.0.58.158/172.16.0.50
根據以上現象可以得知,service對客户端和後端都做了SNAT,可以理解為關閉了透傳客户端源IP的負載均衡,即客户端和後端都不知道彼此的存在,只知道service的地址。該場景下的數據通路如下圖:
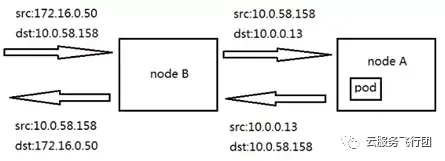
對Pod的請求不涉及SNAT轉換,與masqueradeALL參數不開啓時是一樣的,因此我們不再做分析。
當客户端請求轉發至pod所在節點時,service依然會進行SNAT轉換,只不過這一過程均在節點內部完成。通過之前的分析我們也已經瞭解,客户端請求轉發至pod所在節點時,是否進行SNAT對訪問結果沒有影響。
總結
至此對於客户的需求,我們可以給出現階段最優的方案。當然在生產環境,為了業務安全和穩定,還是不建議用户將clusterIP類型服務和pod直接暴露在集羣之外。同時masqueradeALL參數開啓後,對集羣網絡性能和其他功能是否有影響也沒有經過測試驗證,在生產環境開啓的風險是未知的,還需要謹慎對待。通過解決客户需求的過程,我們對K8s集羣的service和pod網絡機制有了一定程度的瞭解,並瞭解了kube-proxy的masqueradeALL參數,對今後的學習和運維工作還是受益匪淺的。
在此感謝各位童鞋閲讀,如果能夠對大家有所幫助,歡迎點贊轉發,並關注我們的公眾號,更多精彩內容會持續放送!
推薦閲讀
- DevOps專題|玩轉Kubernetes網絡
- 在線公開課 | 讀完這篇,輕鬆開啓Kubernetes之旅
- 乾貨 | 京東雲Kubernetes集羣+Traefik實戰
歡迎點擊【京東科技】,瞭解開發者社區
更多精彩技術實踐與獨家乾貨解析
歡迎關注【京東科技開發者】公眾號
