

作者:京東科技 孫亮
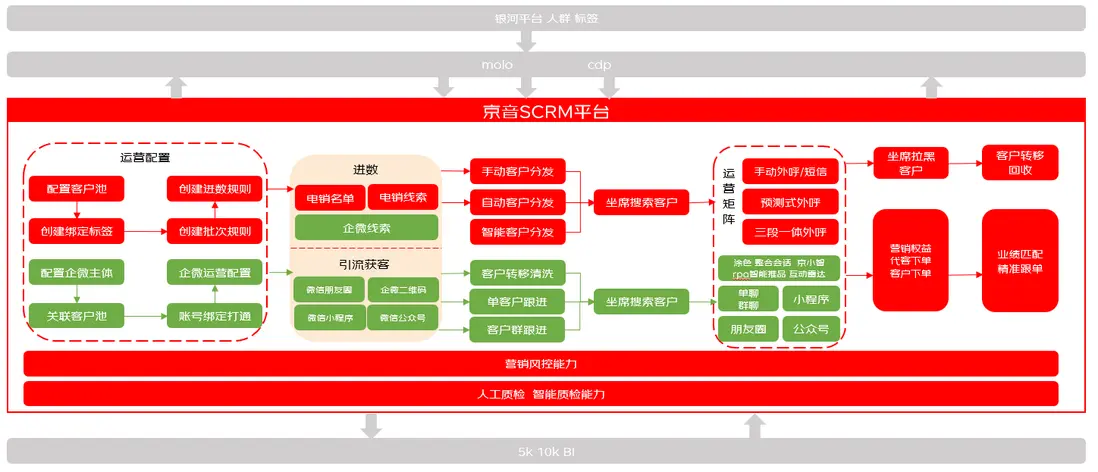
微電平台
微電平台是集電銷、企業微信等於一體的綜合智能SCRM SAAS化系統,涵蓋多渠道管理、全客户生命週期管理、私域營銷運營等主要功能,目前已經有60+京東各業務線入駐,專注於為業務提供職場外包式的一站式客户管理及一體化私域運營服務。
導讀
本文介紹電銷系統在遇到【客户名單離線打標】問題時,從排查、反覆驗證到最終解決問題並額外提升50%吞吐的過程,適合所有服務端研發同學,提供生產環遇到一些複雜問題時排查思路及解決方案,正確使用京東內部例如sgm、jmq、jsf等工具抓到問題根因並徹底解決,用技術為業務發展保駕護航~
下面開始介紹電銷系統實際生產環境遇到的離線拒絕營銷打標流程吞吐問題。
案例背景
1、概述
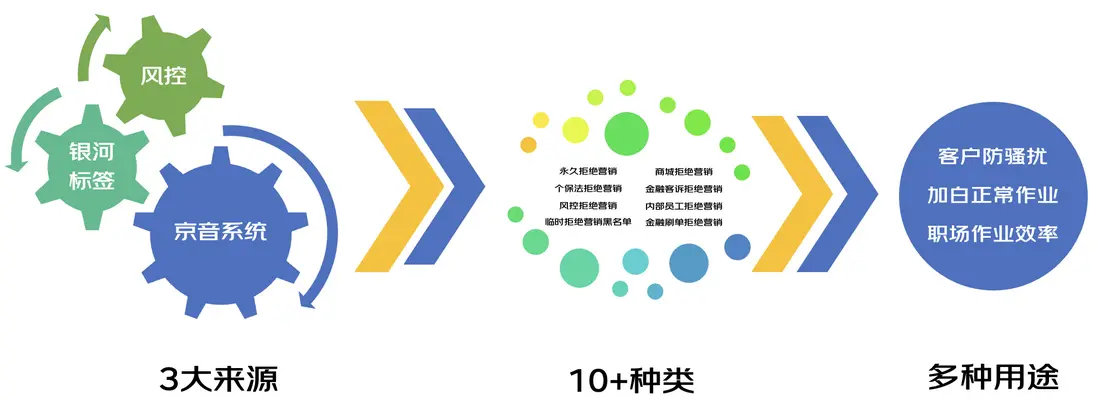
每日凌晨1~8點會使用80台機器為電銷系統上億客户名單進行拒絕營銷打標,平均95萬名單/分鐘,拒絕營銷jsf服務總tps約2萬,tp99在100~110ms,若夜間沒有完成標記加工操作,會導致白天職場無法正常作業,並且存在客户騷擾隱患、降低職場運營效率的問題,因外部接口依賴數量較多打標程序只能凌晨啓動和結束。
2、複雜度
面向業務提供千人千面的配置功能,底層基於規則引擎設計實現,調用鏈路中包含眾多外部接口,例如金融刷單標記、風控標記、人羣畫像標記、商城風控標記、商城實名標記等,包含的維度多、複雜度較高。
3、問題
2023年2月24日早上通過監控發現拒絕營銷打標沒有執行完成,表現為jmq消費端tp99過高、進而降低了打標程序吞吐,通過臨時擴容、下掉“問題機器”(上帝視角:其實是程序導致的問題機器)提高吞吐,加速完成拒絕營銷打標。
但,為什麼會頻繁有機器問題?為什麼機器有問題會降低40%吞吐?後續如何避免此類情況?
帶着上述問題,下面開啓問題根因定位及解決之旅~
抓出幕後黑手
1、為什麼幾台機器出問題就會導致吞吐急劇下降?
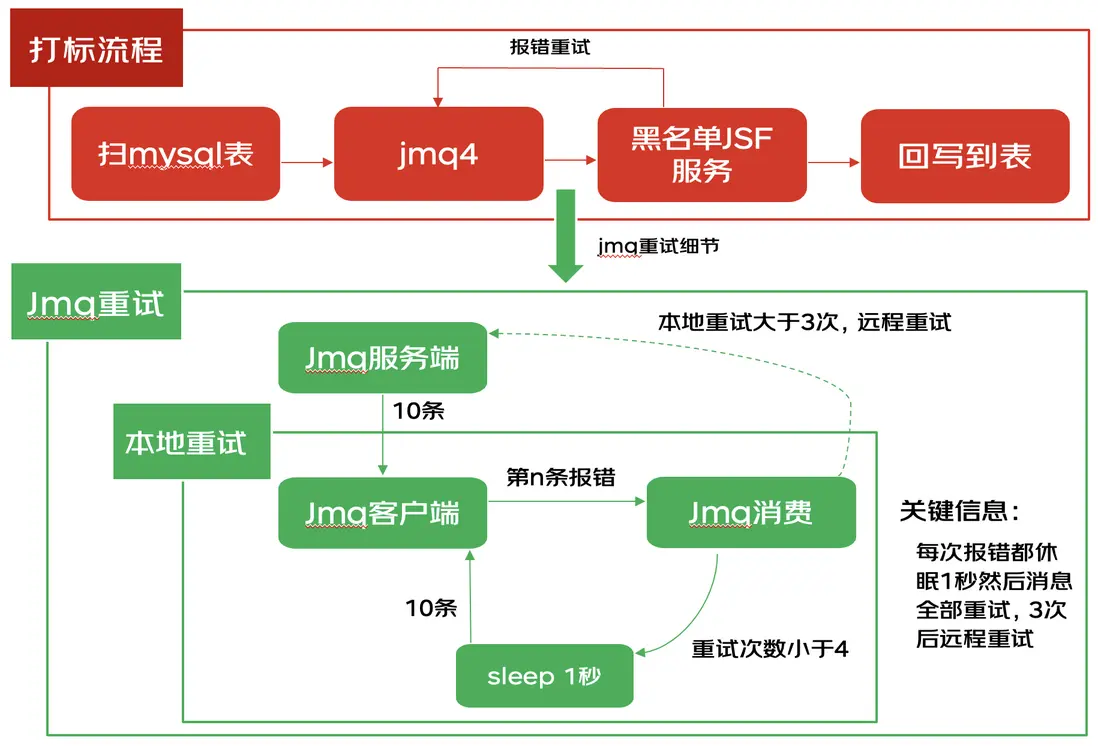
如上圖所示,每有一條消息消費報錯(在本案例中是打到“問題機器”上),會本地嘗試sleep並重新消費拉下來的所有消息(本案例中jmq的batchSize=10),即每次報錯產生的總耗時至少會增加一千毫秒,一共80台機器,jsf使用默認負載均衡算法,服務請求打到4台問題機器的概率是5%,jmq一次拉下來10條消息,只要有一條消息命中“問題機器”就會極大降低吞吐。
綜上所述,少量機器有問題吞吐就會急劇降低的原因是jsf隨機負載均衡算法下每個實例的命中率相同以及報錯後jmq consumer重試時默認休眠1秒的機制導致。
解決:當然consumer不報錯是完全可以規避問題,那如果保證不了不報錯,可以通過:
1)修改jmq的重試次數、重試延遲時間來儘可能的減少影響
<jmq:consumer id="cusAttributionMarkConsumer" transport="jmqTransport">
<jmq:listener topic="${jmq.topic}" listener="jmqListener" retryDelay="10" maxRetryDelay="20" maxRetrys="1"/>
</jmq:consumer>2)修改jsf負載均衡算法
配置樣例:
<jsf:consumer loadbalance="shortestresponse"/>原理圖:
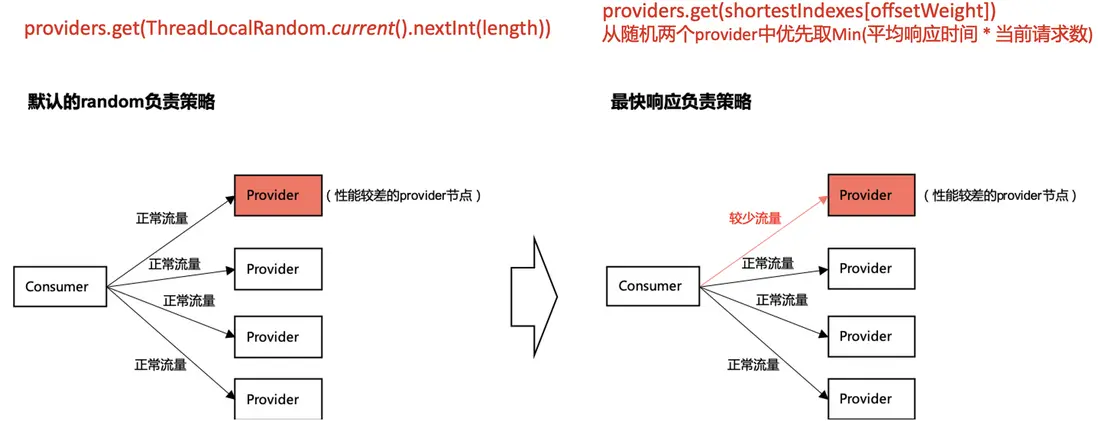
上圖中的consumer圖是從jsf wiki裏摘取,上面的紅字是看jsf代碼提取的關鍵信息,總而言之就是:默認的random是完全隨機算法,最快響應時間是基於服務請求表現進行負載均衡,所以使用最快響應算法可以很大程度上規避此類問題,類似於熔斷的作用(本次解決過程中也使用了jsf的實例熔斷、預熱能力,具體看jsf wiki,在此不過多介紹)。
2、如何判定是實例問題、找出有問題的實例ip?
通過監控觀察,耗時高的現象只存在於4台機器上,第一反應確實是以為機器問題,但結合之前(1月份有過類似現象)的情況,覺得此事必有蹊蹺。
下圖是第一反應認為是機器問題的日誌(對應sgm監控這台機器耗時也是連續高),下掉此類機器確實可以臨時解決問題:
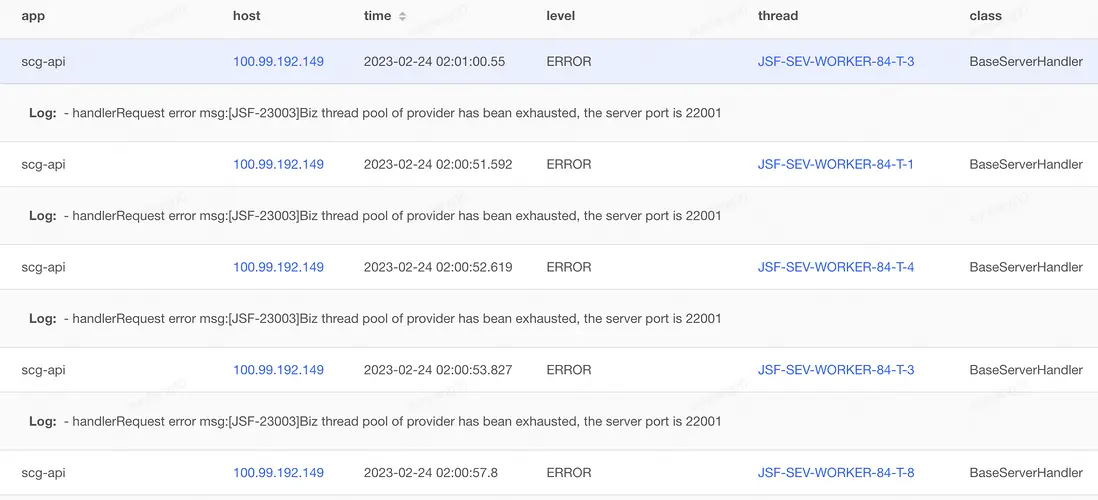
綜上所述,當時間段內耗時高或失敗的都是某個ip,此時可以判定該ip對應的實例有問題(例如網絡、硬件等),如果是大量ip存在類似現象,判定不是機器本身的問題,本案例涉及到的問題不是機器本身問題而是程序導致的現象,繼續往下看揭曉答案。
3、是什麼導致機器頻繁假死、成為故障機器?
通過上述分析可以得知,問題機器報錯為jsf線程池打滿,機器出問題期間tps幾乎為0,期間有請求過來就會報jsf線程池(非業務線程池)打滿,此時有兩種可能,一是jsf線程池有問題,二是jsf線程池的線程一直被佔用着,抱着信任中間件的思路,選擇可能性二繼續排查。
通過行雲進行如下操作:
1)dump內存對象
無明顯問題,內存佔用也不大,符合監控上的少量gc現象,繼續排查堆棧
2)jstack堆棧
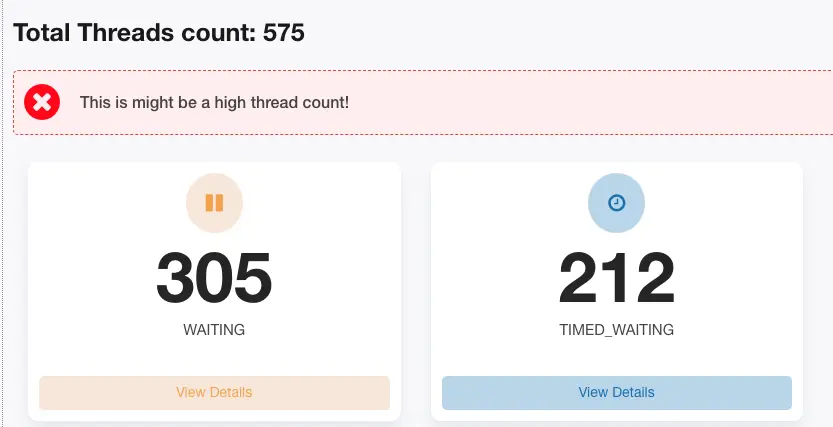
從此來看與問題機器表象一致了,基本得出結論:所有jsf線程都在waiting,所以有流量進來就會報jsf線程池滿錯誤,並且與機器cpu、內存都很低現象相符,繼續看詳細棧信息,抽取兩個比較有代表的jsf線程。
線程編號JSF-BZ-22000-92-T-200:
stackTrace:
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007280021f8> (a java.util.concurrent.FutureTask)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.FutureTask.awaitDone(FutureTask.java:429)
at java.util.concurrent.FutureTask.get(FutureTask.java:191)
at com.jd.jr.scg.service.common.crowd.UserCrowdHitResult.isHit(UserCrowdHitResult.java:36)
at com.jd.jr.scg.service.impl.BlacklistTempNewServiceImpl.callTimes(BlacklistTempNewServiceImpl.java:409)
at com.jd.jr.scg.service.impl.BlacklistTempNewServiceImpl.hit(BlacklistTempNewServiceImpl.java:168)線程編號JSF-BZ-22000-92-T-199:
stackTrace:
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
- parking to wait for <0x00000007286c9a68> (a java.util.concurrent.FutureTask)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.FutureTask.awaitDone(FutureTask.java:429)
at java.util.concurrent.FutureTask.get(FutureTask.java:191)
at com.jd.jr.scg.service.biz.BlacklistBiz.isBlacklist(BlacklistBiz.java:337)
````
**推斷**:線程編號JSF-BZ-22000-92-T-200在UserCrowdHitResult的36行**等待**,線程編號JSF-BZ-22000-92-T-199在BlacklistBiz的337行**等待**,查到這,基本能推斷出問題原因是線程等待,**造成問題的類似代碼場景**是1)main線程讓線程池A去執行一個任務X;2)任務X中又讓同一個線程池去執行另一個任務,當第二步獲取不到線程時就會一直等,然後第一步又會一直等第二步執行完成,就是造成線程互相等待的假死現象。
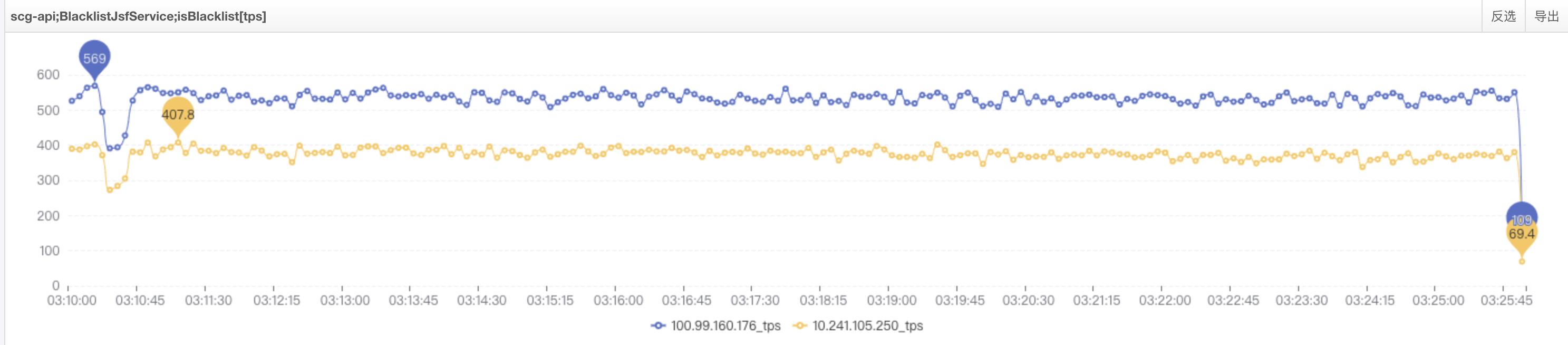
**小結**:查到這基本可以確認問題,但因代碼維護人離職以及程序錯綜複雜,此時為驗證結論先修改業務線程池A線程數:50->200(此處是為了驗證沒有線程等待現象時的吞吐表現),再進行驗證,結論是**tps會有小範圍抖動**,但不會出現tps到0或是大幅降低的現象。
單機tps300~500,流量正常了,即**未產生線程等待問題時可以正常提供服務**,如圖:
**印證推斷**:通過堆棧定位到具體代碼,代碼邏輯如下:
BlacklistBiz->【線程池A】blacklistTempNewService.hit
blacklistTempNewService.hit->callTimes
callTimes->userCrowdServiceClient.isHit->【線程池A】crowdIdServiceRpc.groupFacadeHit
**小結**:BlacklistBiz作為主線程通過線程池A執行了blacklistTempNewService.hit任務,然後blacklistTempNewService.hit中又使用線程池A執行了crowdIdServiceRpc.groupFacadeHit造成了**線程等待、假死現象**,與上述推斷一致,至此,問題已完成定位。
**解決**:辦法很簡單,額外新增一個線程池**避免線程池嵌套**使用。
## 4、意外收穫,發現一個影響拒絕營銷服務性能的問題點
查看堆棧信息時發現存在大量**waiting to lock**的信息:
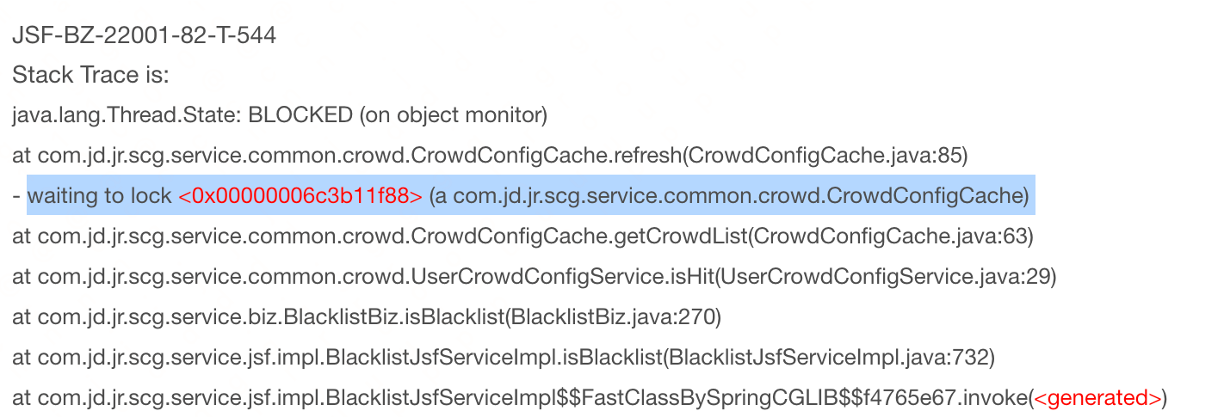
**問題**:通過上述堆棧進而排查代碼發現一個服務鏈路中的3個方法使用了**同一把鎖**,性能不降低都怪了 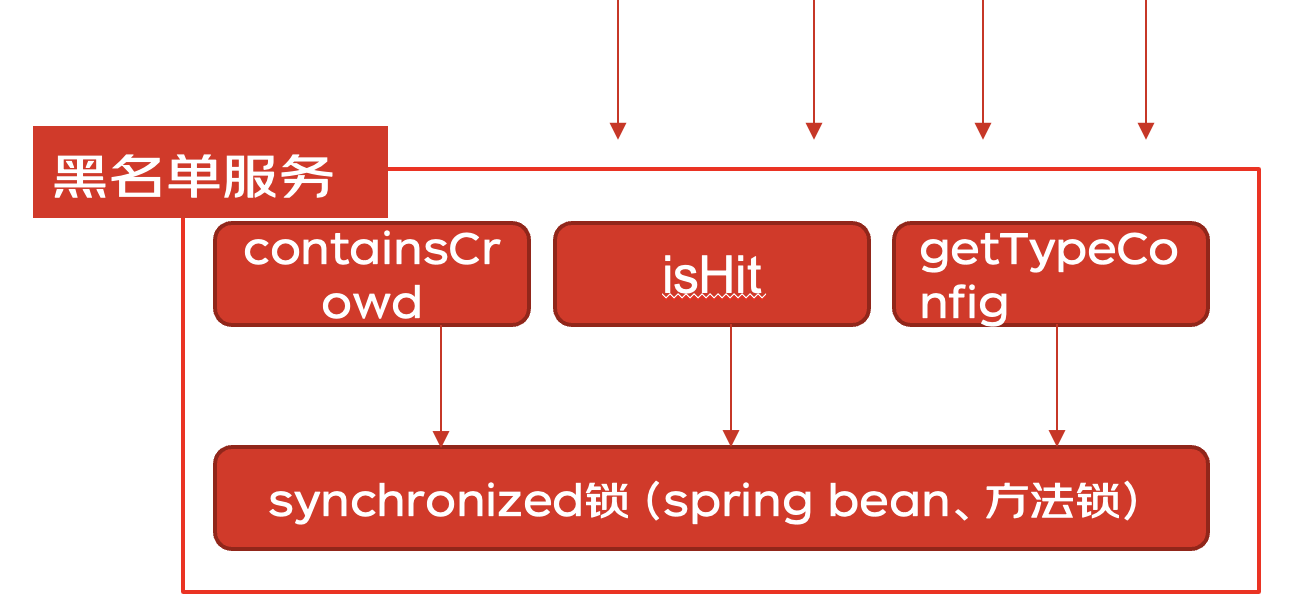 **解決**:通過引入caffeine本地緩存替換掉原來使用同步鎖維護的手寫本地緩存。
## 5、額外收穫,你知道jsf線程池滿的時候報RpcException客户端不會進行重試嗎?
這個讓我挺意外的,之前看jsf代碼以及和jsf架構師交流得到的信息是:所有RpcException都會進行重試,重試的時候通過負載均衡算法重新找provider進行調用,但在實際驗證過程中發現若服務端報:handlerRequest error msg:\[JSF-23003\]Biz thread pool of provider has bean exhausted, the server port is 22001,**客户端不會發起重試**,此結論最終與jsf架構師達成一致,所以此類場景想要重試,需要在客户端程序中想辦法,實現比較簡單,這裏不貼樣例了。
# 事件回顧
 解決問題後對以前的現象和類似問題做了進一步挖掘,梳理出瞭如上圖的整個鏈路(問題代碼同學早已不在、大可忽略問題人,此處從上帝視角覆盤整個事件),通過2月24號的問題,不但徹底解決了問題,還對影響性能的因素做了優化,最終效果有:
1、解決拒絕營銷jsf服務線程等待安全隱患、去掉同步鎖提升吞吐,tps從**2萬提升至3萬**的情況下,tp99從**100ms降低至65ms**;
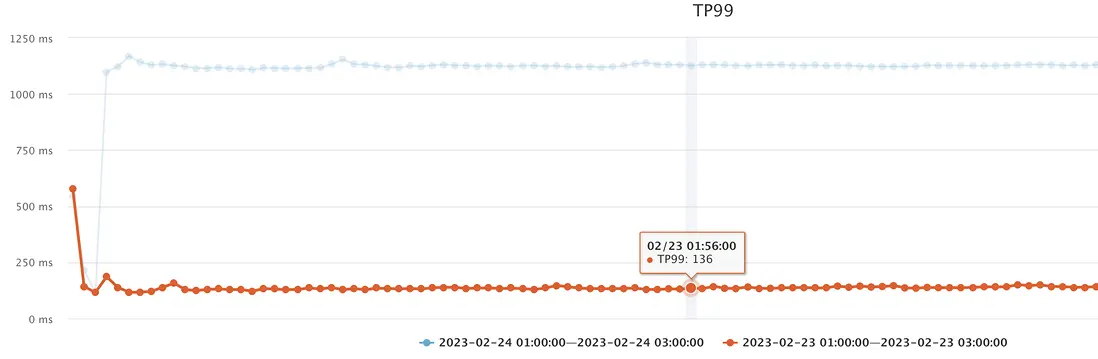
2、jmq重試等待及延遲時間調優,規避重試時吞吐大幅降低:tp99從**1100ms降低至300ms**;
3、jsf負載均衡算法調優,規避機器故障時仍然大量請求打到機器上,效果是服務相對**穩定**;
**最終從8點多執行完提前至5點前完成,整體時間縮減了57%,並且即使機器出現“問題”也不會大幅降低整體吞吐,收益比較明顯。**
優化後的運行圖如下:
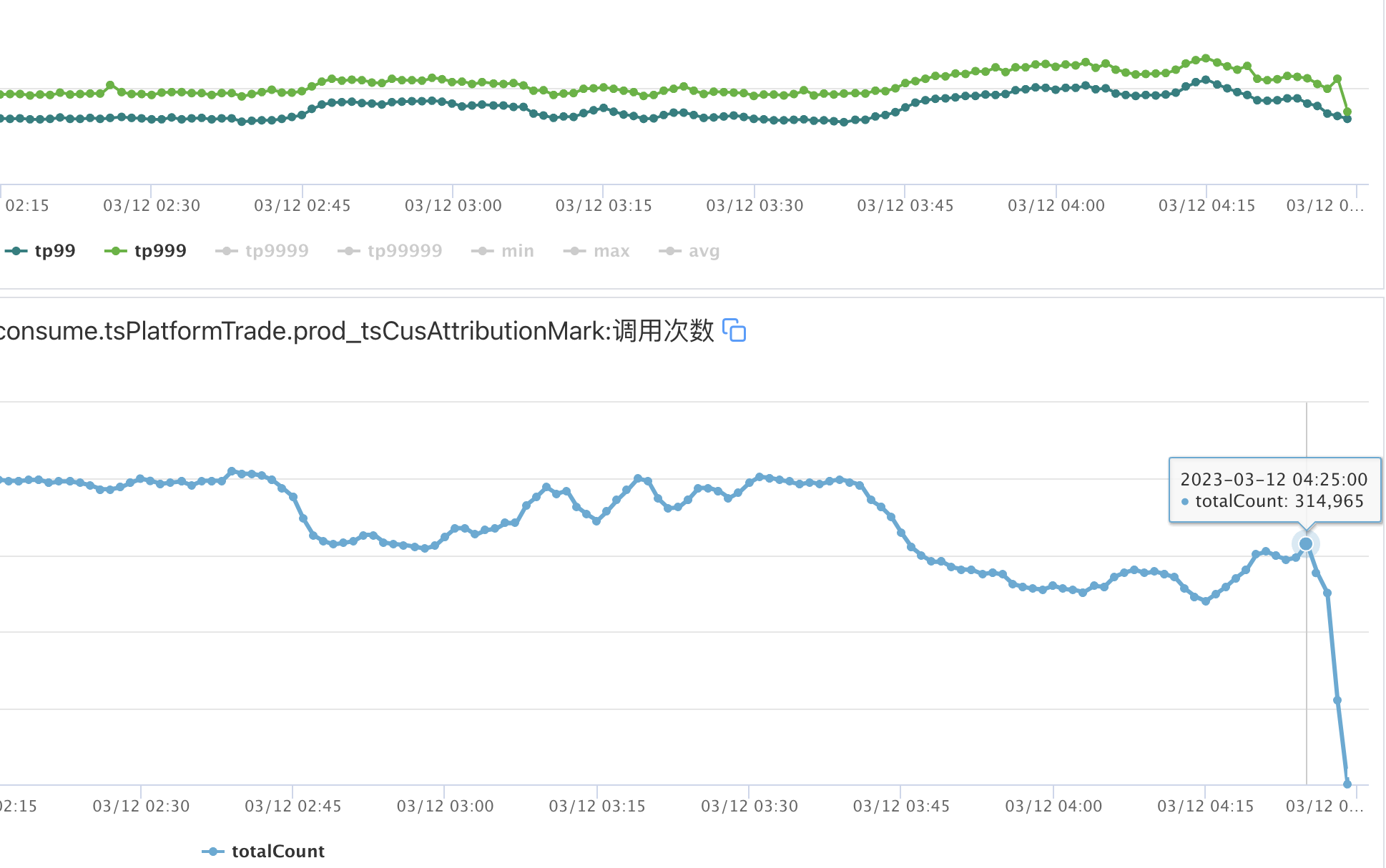
# 寫在最後
微電平台雖説不在黃金鍊路,但場景複雜度(業務複雜度、rpa等機器人用户複雜度)以及流量量級使我們經常面臨各種挑戰,好在我們都解決了,這裏共勉一句話:“**在前進的路上總會有各種意想不到的情況,但是,都會撥雲見日**”。