

做過數據分析和爬蟲程序的小夥伴想必對 Scrapy 這個爬蟲框架已經很熟悉了。今天給大家介紹下,如何基於 Scrapy 快速編寫一個爬蟲程序並利用 Easysearch 儲存、檢索、分析爬取的數據。我們以極限科技的官網 Blog 為數據源,做下實操演示。
安裝 scrapy
使用 Scrapy 可以快速構建一個爬蟲項目,從目標網站中獲取所需的數據,並進行後續的處理和分析。
pip install scrapy
# 新建項目 infini_spiders
scrapy startproject infini_spiders
# 初始化爬蟲
cd infini_spiders/spiders
scrapy genspider blog infinilabs.cn爬蟲編寫
編寫一個爬蟲文件 blog.py ,它會首先訪問 start_urls 指定的地址,將結果發給 parse 函數解析。通過這一步解析,我們得到了每一篇博客的地址。然後我們對每個博客的地址發送請求,將結果發給 parse_blog 函數進行解析,在這裏才會真正提取每篇博客的 title、tag、url、date、content 內容。
from typing import Any, Iterable
import scrapy
from bs4 import BeautifulSoup
from scrapy.http import Response
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["infinilabs.cn"]
start_urls = ["https://infinilabs.cn/blog/"]
def parse(self, response):
links = response.css("div.blogs a")
yield from response.follow_all(links, self.parse_blog)
def parse_blog(self, response):
title = response.xpath('//div[@class="title"]/text()').extract_first()
tags = response.xpath('//div[@class="tags"]/div[@class="tag"]/text()').extract()
url = response.url
author = response.xpath('//div[@class="logo"]/div[@class="name"]//text()').extract_first()
date = response.xpath('//div[@class="date"]/text()').extract_first()
all_text = response.xpath('//p//text() | //h3/text() | //h2/text() | //h4/text() | //ol/li//text()').extract()
content = '\n'.join(all_text)
yield {
'title': title,
'tags': tags,
'url': url,
'author': author,
'date': date,
'content': content
}提取完我們想要的內容後,接下來就要考慮存儲了。考慮到要對內容進行檢索、分析,接下來我們將內容直接存放到 Easysearch 當中。
安裝插件
通過安裝 ScrapyElasticsearch pipeline 可將 scrapy 爬取的內容存入到 Easysearch 中。
pip install ScrapyElasticSearch修改 scrapy 自帶的配置文件 settings.py ,添加以下內容。
ITEM_PIPELINES = {
'scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline': 10
}
ELASTICSEARCH_SERVERS = ['http://192.168.56.3:9210']
ELASTICSEARCH_INDEX = 'scrapy'
ELASTICSEARCH_INDEX_DATE_FORMAT = '%Y-%m-%d'
ELASTICSEARCH_TYPE = '_doc'
ELASTICSEARCH_USERNAME = 'admin'
ELASTICSEARCH_PASSWORD = '9423d1d5345ed6d0db19'ScrapyElasticSearch 會以 bulk 方式寫入 Easysearch,每次批量的大小由 scrapyelasticsearch.scrapyelasticsearch.ElasticSearchPipeline 參數控制,大家可自行修改。
在上述配置中,我們會將爬到的數據存放到 scrapy-yyyy-mm-dd 索引中。
啓動爬蟲
在 infini_spiders/spiders 目錄下,使用命令啓動爬蟲。
scrapy crawl blog
blog 就是爬蟲的名字,對應到 blog.py 裏面的 name 變量。運行完成後,就可以去 Easysearch 裏查看數據了,當然我們還是使用 Console 進行查看。
查看數據
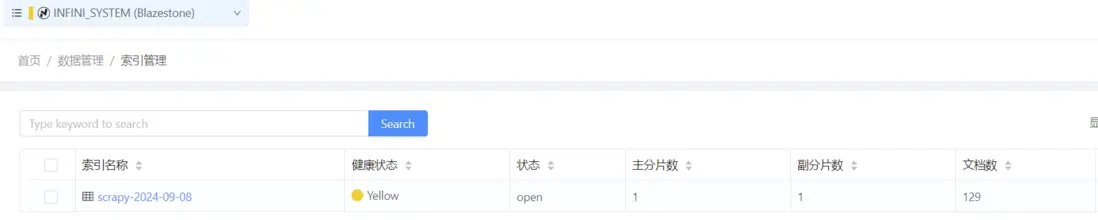
先查看下索引情況,scrapy 索引已經生成,裏面有 129 篇博客。
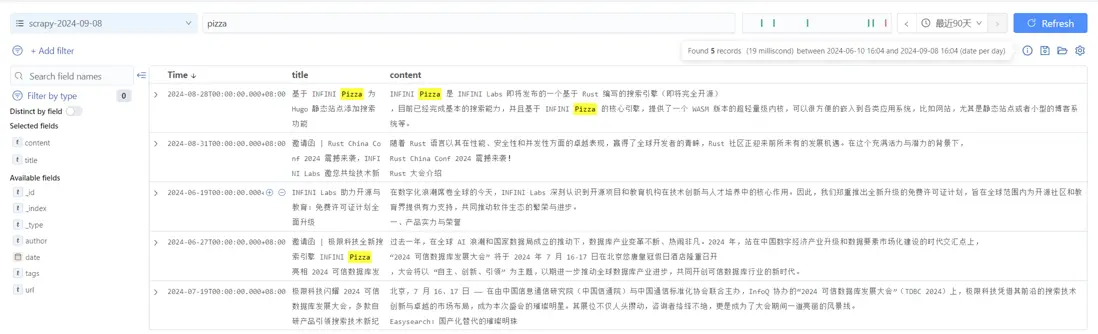
查看詳細內容,確保博客正文已經保存。

到了這一步,我們就能使用 Console 對博客進行搜索、分析了。
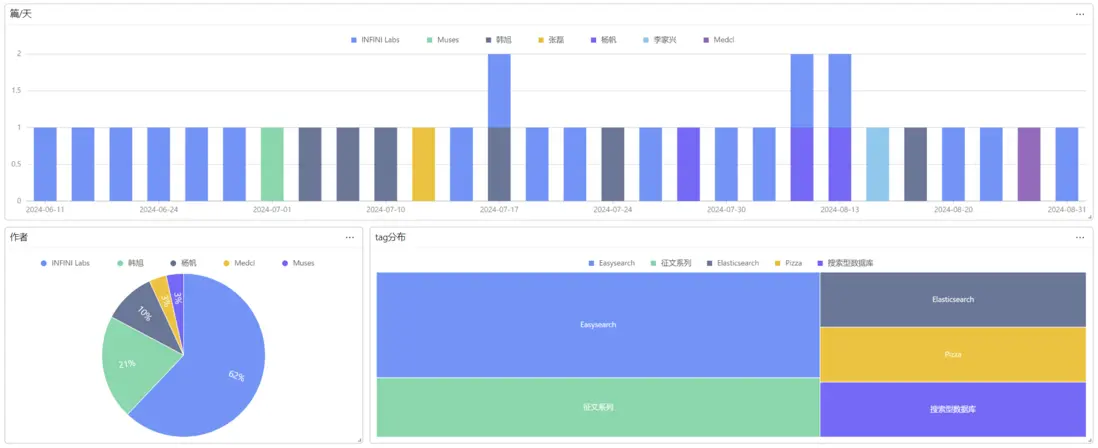
這次的分享就到這裏了。歡迎與我一起交流 ES 的各種問題和解決方案。





