

計算機網絡是指互聯的計算機系統之間通過通信設備和通信線路進行數據交換的系統。計算機網絡可以分為局域網、城域網、廣域網和因特網等不同的類型。計算機網絡使用各種協議來實現不同的功能和服務,例如 TCP/IP 協議用於互聯網通信,HTTP 協議用於網頁瀏覽,SMTP 協議用於電子郵件傳輸等等
網絡協議是計算機之間進行數據交換的一類規則協議、標準集合,不同計算機之間的通信必須建立在相同的標準上,如:HTTP協議、TCP協議等等,在這些協議中TCP/IP協議影響力最大,是必須學習的協議,本模塊會列出常見的協議並進一步分析,加深印象和理解
掃碼關注公眾號,查看更多優質內容

網絡層次劃分
為什麼要進行網絡層次劃分?互聯網的通信都必須建立在同一標準上才能夠正常進行,劃分層次可以進一步促進不同層次標準化,使得不同的供應商和組織可以遵循相同的標準進行設計和實現;進行模塊劃分、簡化整體設計更有利於不同標準的實現、維護和擴展,提高網絡的靈活性
網絡協議層次劃分的兩個經典代表:OSI模型、TCP/IP模型
OSI模型
OSI七層模型是國際標準化組織(ISO)在20世紀70年代提出的一個計算機網絡通信模型。當時,由於不同的廠商和組織都在開發自己的網絡協議,這導致了網絡之間的互操作性和標準化問題。為此,ISO組織提出了OSI七層模型,以便解決這些問題。總之,<u>OSI七層模型推動了網絡協議的標準化和互操作性,為網絡設計和實現提供了重要的參考模型,對於推動計算機網絡的發展和應用具有重要的作用</u>
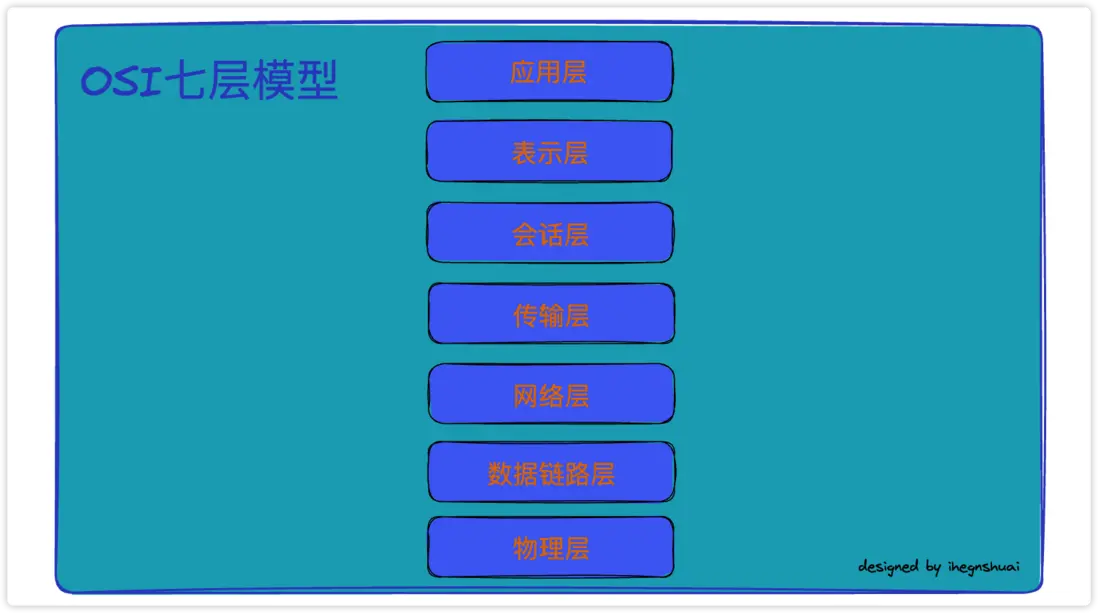
以上是OSI七層模型,層層向上每一層為上一層提供服務
- 應用層(Application Layer):負責提供各種應用程序所需的服務,如文件傳輸、電子郵件、網頁瀏覽等
- 表示層(Presentation Layer):負責數據格式的轉換,提供數據加密和壓縮等功能
- 會話層(Session Layer):負責建立和管理會話連接,提供數據交換和同步功能
- 傳輸層(Transport Layer):負責建立端到端的可靠傳輸連接,提供數據流的分段和重組功能,包括協議TCP和UDP等
- 網絡層(Network Layer):負責在數據鏈路層上建立邏輯連接,選擇最佳傳輸路徑,進行數據包的傳輸和路由選擇
- 數據鏈路層(Data Link Layer):負責在物理層上建立數據鏈路,進行數據幀的傳輸和接收,並進行錯誤檢測和糾正
- 物理層(Physical Layer):主要負責傳輸比特流,包括建立物理連接、信號編碼、調製解調製等
TCP/IP模型
TCP/IP協議的誕生背景是20世紀60年代末和70年代初,當時美國國防部的ARPA(高級研究計劃局)在研究如何建立一種去中心化、可靠的通信網絡,以應對核戰爭帶來的威脅。ARPA的研究成果最終演變成了TCP/IP協議
可以説是TCP/IP協議是OSI的具體實現,其中典型的的代表是TCP和IP協議。TCP協議負責數據的可靠傳輸,它將數據分成小的數據包並確保它們以正確的順序被髮送到目的地。IP協議則負責數據包的路由和尋址,它將數據包從一個網絡設備傳輸到另一個網絡設備,使得不同類型的計算機和網絡設備能夠相互通信,並且能夠在全球範圍內進行數據傳輸,它是互聯網的基礎

- 應用層:應用層是TCP/IP協議的最高層,它負責處理應用程序之間的通信。這個層次包括許多協議,如HTTP、FTP、SMTP等,這些協議決定了應用程序如何在網絡上進行通信
- 傳輸層:傳輸層負責處理數據的傳輸,如TCP協議提供了可靠的連接服務,能夠確保數據的完整性和順序性;UDP協議則提供了無連接服務,適合於需要快速傳輸的數據
- 網絡層:網絡層負責數據包的路由和尋址,它使用IP協議來實現數據包的傳輸。IP協議能夠將數據包從一個網絡設備傳輸到另一個網絡設備,同時還能夠進行網絡地址轉換(NAT)
- 數據鏈路層:數據鏈路層負責將數據包封裝成幀併發送到物理層,也負責接收物理層傳輸的幀並解封裝成數據包。這個層次包括了以太網、Wi-Fi、藍牙等協議,它們決定了數據在物理層如何傳輸
傳輸過程

瞭解了網絡模型後那數據到底是怎麼傳輸的呢?假如以上計算機A、B要進行通訊,A在瀏覽器上提交網頁登錄信息點擊發送,這裏我們認定他使用HTTP協議,接着將數據發送到傳輸層當然這裏會使用TCP協議作為可靠傳輸。TCP協議中會添加自己的相關信息作為數據的首部,如:源端口和目標端口、窗口大小、相關標識等等,形成數據段,再提交給網絡層。網絡層ARP協議會探測源IP地址的mac地址,IP會添加源IP和目標IP等信息作為首部形成數據包,再提交給數據鏈路層。鏈路層將添加以源mac地址和目標mac地址等信息為首部,交給物理層。物理層以比特流的形式開始轉發,假如遇到路由器時路由器識別目標ip並根據路由表進行轉發,期間會將源mac地址修改為路由器另一出口網卡的mac地址,然後再經過其他的路由器或交換機,這樣層層轉發直到目標主機。目標主機鏈路層去掉鏈路首部給到網絡層,網絡層去掉IP首部給到傳輸層,傳輸層去掉TCP首部給到應用層,應用層拿到數據後根據不同情況進行響應或拒絕
以上簡單的概述了兩端數據轉發的過程
mac地址每經過一個路由器時都會將源mac地址修改會其某一網絡接口的mac地址,而IP地址不會,因此IP地址決定了數據的起點和終點,mac地址決定了下一跳地址,二者缺一不可
TCP/IP協議
TCP/IP協議是互聯網最重要的協議,它是萬物互聯的基礎。<u>TCP/IP協議不是一種協議而是一類協議,是個協議簇包含了很多不同層次協議</u>,因為TCP、IP兩種協議比較經典而作為重要代表。以下列出TCP/IP協議中各層所包含的協議:
- 應用層:HTTP、FTP、Telnet、SMTP、DNS、POP3等等
- 傳輸層:TCP、UDP、TLS、QUIC等等
- 網絡層:IP、ARP、RARP、ICMP等等
- 數據鏈路層:PPP、HDLC、CSMA等等
TCP/IP協議中包含很多重要的協議,如:HTTP協議對於web開發者瞭解其數據報文信息很有用、TCP協議連接過程(面試考點)、IP劃分(子網掩碼、網段等等)、ARP尋址、ICMP網絡診斷等在實際開發或網絡排錯中都很有用
總之搞懂這些協議是非常有用的,瞭解網絡傳輸本質對於網絡的學習也很有幫助,接下來以TCP/IP為範疇詳細講解部分協議
為什麼要懂計算機網絡?
可以説計算機網絡是每個工程師的基礎,瞭解它會讓我們明白其背後的原理是怎麼樣的,比如:前後端的數據傳輸,使用的什麼協議,換成什麼協議可以加快數據傳輸等等。總之學習計算機網絡是很重要的,可以拓寬自己視野發展,總之關於網絡中的盲區最好還是填補一下
TCP(Transmission Control Protocol,傳輸控制協議)是一種在計算機網絡中常用的協議,它是一種<u>面向連接的、可靠的、基於字節流的傳輸層協議。TCP協議主要負責對數據進行分段、組裝、傳輸和確認,以保證數據的可靠傳輸</u>。
特點
- 可靠性:TCP協議可以保證數據的可靠傳輸,通過數據分段、校驗和、確認機制等手段來確保數據不會丟失、損壞或重複
- 面向連接:TCP協議在傳輸數據之前需要先建立連接,傳輸完成後再釋放連接。這種連接方式可以保證數據的有序傳輸,避免數據混亂
- 流式傳輸:TCP協議是基於字節流的傳輸層協議,將數據按照字節流方式分段傳輸,不需要考慮數據的長度和格式
- 擁塞控制:TCP協議可以根據網絡狀態來控制數據的發送速度,避免網絡擁塞導致數據丟失和延遲
TCP首部

- 源端口:發送方端口,長度為2個字節16位,因此最大值為
2的16次方65536 - 1,故TCP的端口範圍為0 ~ 65535 - 目標端口:另一方的端口,範圍同上
- 序列號:代表着數據的位置,最大序號為
2的32次方-1,每發一次數據就要累加一次該數據的長度,當序號超過最大值又會從0開始。序列號不一定從0或1開始,而是從建立連接的隨機數作為其初始值,在建立連接和斷開連接時發送的SYN包和FIN包雖然並不攜帶數據,但是也會作為1個字節增加對應的序列號。 - 確認號:指下一次應該收到的數據的序列號
- 數據偏移:字段長4位,單位為4字節,代表着數據包開始的位置,也可以理解成TCP首部總長度。從圖中可以知道首部的固定長度為20字節,在沒有可選數據時其最小值為5(二進制表示
0101),最大值2的4次方減1(二進制1111)15再乘4為60字節,由此可知可選部分的最大長度為40字節 - 保留位:4位長度,以後擴展使用,到目前為止還沒有任何用處
-
控制位:8位長度,由左到右分別是
CWR(Congestion Window Reduced)、ECE(Explicit Congestion Notification)、URG(Urgent Flag)、ACK(Acknovledgement Flag)、PSH(Push Flag)、RST(Reset Flag)、SYN(Synchronize Flag)、FIN(Fin Flag),當他們的值為1時都表示一定的含義- CWR:減小擁塞窗口,發送方降低發送速率
- ECE:ECN回顯,發送方接受到了一個更早的擁塞通知(ECN是一種擁塞控制機制,用於在發生擁塞時通知TCP發送方降低發送速率,從而避免網絡擁塞)
- URG:表示當前數據需要緊急處理
- ACK:表示確認需要有效,也就是ACK為1時上圖中的確認號才會有效
- PSH:表示數據需要立刻傳給上層協議
- RST:表示連接出現非常嚴重的錯誤必須重新連接
- SYN:表示希望建立連接,並將當前的序號作為初始值
- FIN:表示希望斷開連接不會有數據發送了
- 窗口:字段長為16位,用於通知從確認號開始能夠接受的數據大小,如果窗口的值為0時表示可以發送窗口偵測,通常情況下TCP會根據窗口大小進行分段傳輸,每段最大傳輸數據大小(MSS)為1460,實際情況的最大長度為1448(減去12字節的時間戳選項)
- 校驗和:端到端校驗機制確保數據的正確性,由發送方通過頭部、數據計算得到的校驗和,接收方方會重新校驗進行對比
- 緊急指針:在URG控制位為1時有效,該字段的數值表示數據中的緊急數據,也就是説從數據的開始到緊急指針的位置為緊急數據,因此緊急指針也代表了緊急數據的末尾
- 選項:選項類型(無操作、最大段大小MSS、窗口縮放因子、時間戳等等),每個選項的第一個字節為種類指明選項的類型,種類為0和1的選項僅佔1字節,其他種類選項根據種類來確定字節數,種類1允許發送者用多個4字節組填充字段
:::warning 注意
在老版本的TCP協議中可能只會存在6為控制位,而CWR、ECE控制位可能不存在,新版本都會有8位控制位
:::

以上的字段明細都可以使用wireshark抓包工具捕獲到,如果你對此工具還不熟悉可以參考我的「wireshark網絡抓包」一文
連接與終止
TCP是可靠傳輸協議,其數據傳輸前通信雙方必須建立一條連接,總體來説TCP通信是個複雜的過程(超時重傳、流量控制、分包組裝等等),整體通信大致過程示意圖如下:

三次握手
關於TCP的三次握手和四次揮手是常問的考點,搞清楚它非常簡單,這裏總結下二者。TCP的連接需要三個步驟:發起端發送SYN、接收端發送SYN+ACK、發送端發送ACK。為什麼需要三次呢?一次行不行?答案是否定的,三次正好符合可靠傳輸的特點。這就好比2人打電話,甲方打給乙方,甲方問你是乙方嗎,乙方回答我是那你是誰呢,甲方再次回乙方説我是誰,這樣下來雙方都知道對方的身份並且知道電話已經打通了,可以收發數據。而TCP連接也是這樣的,下方是三次握手連接的示意圖:

- 剛開始Client處於close狀態,Server處於Listen狀態
- Client主動打開發送
SYN=1、Seq=x請求表示主動連接(注意:<u>seq在初始化時是個隨機數,它會根據時間戳變化,超時重傳時使用相同的seq,新的連接會生成新的序列號,來避免歷史或其他連接的錯誤問題</u>),此時Client進入SYN_SENT狀態 - Server接受到客户端的
SYN請求後,需要應答Client併發送SYN=1、ACK=1、Seq=y請求,其中確認號為x+1且有效期望下一次客户端的發送序列號應為x+1,而SYN表示也想連接Client且序號為y,此時Server進入SYN_RCVD狀態 - Client收到Server的
ACK響應後進入ESTABLISHED狀態表示已連接(半連接狀態),然後發送Seq=x+1、ACK=1的請求,序列號為y+1且有效,表示確認了Server的連接請求,並期望Server下一次發送的序號為y+1 - Server收到客户端的
ACK響應後也進入ESTABLISHED狀態,雙方進入全連接狀態,三次握手完畢可以進行數據傳輸了
抓包結果:

TCP握手期間雖然沒有真實的數據進行傳輸,但在這期間會進行相關重要數據的約定,如:窗口大小、MSS等有用的信息
重置連接
三次握手是TCP連接的正常過程,但還有其他非正常的連接出現嚴重的連接錯誤,此時就會通過標記RST來重置連接,比如主機A使用telnet連接主機B的某個未開放端口,就會被主機B拒絕:
# 使用主機A192.168.10.8登錄 主機B192.168.10.9:8080
➜ telnet 192.168.10.9 8080
Trying 192.168.10.9...
telnet: connect to address 192.168.10.9: Connection refused當主機B接受到TCP連接請求時被認為成錯誤的連接,此時主機B會主動發送一個RST的響應,表示連接錯誤,需要重新連接,可以使用抓包工具查看:

連接隊列
上面的三次握手只是簡單的概述了主要的連接過程,在真實環境中存在請求隊列的概念,如同時併發多個TCP請求,就會將其排列成隊列進行處理
在TCP連接中存在兩個重要的隊列SYN隊列(半連接隊列)和Accept隊列(全連接隊列),它們分別用於<u>處理連接請求和已經建立連接的數據傳輸</u>
- SYN隊列:用於存儲SYN(同步)請求的隊列。當一個客户端請求與服務器建立TCP連接時,它會向服務器發送一個SYN包。服務器在收到SYN包後,將在SYN隊列中排隊等待確認,並向客户端發送一個SYN-ACK包作為確認
- Accept隊列:用於存儲已經建立連接的隊列(未被上層應用程序使用)。當服務器收到客户端第三次握手的ACK請求後,客户端和服務器之間的連接就建立了,此時連接會被添加到accept隊列中,等待應用程序使用
大致處理過程示意圖如下:

首先Client主動發送SYN連接請求,Server收到後創建半連接對象將其放入SYN隊列,Server發送ACK+SYN給Client後,直到收到Client的ACK響應後,創建全連接對象將其連接放入Accept隊列,最後由應用程序接受處理
SYN隊列的的最大限制通常是1000,Accept隊列的最大限制通常是128,可以通過以下方式查看:
# 查看syn隊列最大值
➜ cat /proc/sys/net/core/netdev_max_backlog
1000
# accept隊列最大值
➜ cat /proc/sys/net/ipv4/tcp_max_syn_backlog
128總的來説兩個隊列並不是很大,但實際情況中由於CPU、內存等相關因素的影響,我們的應用程序可能達不到很高的併發處理請求,因此TCP的請求就會被延時,或當SYN、Accept隊列溢出時,Server也會忽略掉Client的SYN請求包,根據重傳機制Client等待一段時間重新發送SYN,此時Server表現出繁忙的狀態
SYN泛洪
SYN泛洪也稱SYN攻擊,是TCP常見的網絡攻擊手段,其利用TCP連接三次握手的第一階段,當Client向Server瘋狂發送SYN請求,卻不響應Server的ACK+SYN請求時,Server的SYN隊列會很快被打滿,從而主動丟棄後面的SYN請求,也就無法進行正常的TCP連接了,大量的SYN請求也會消耗Server的資源,產生不正常的消耗
如何避免SYN攻擊呢,可以從防火牆、SYN Cookies、減小SYN隊列、SYN ACK重傳次數等着手:
-
開啓SYN Cookies:
什麼是SYN Cookies?當SYN隊列溢出時,如果再收到SYN請求不會為其分配任何存儲資源,而只有當SYN+ACK報文段被確認時才分配到Accept隊列裏。SYN Cookies是由Server通過一定的算法加隨機值計算而來,再作為序列號發送給Client,Server收到Client的ACK報文後會校驗合法性,如果合法將會放入Accept隊列,否則直接丟棄,這樣就繞過了SYN隊列資源。
可以通過以下方式設置syncookies:
# 0 表示關閉 # 1 SYN隊列溢出時開啓 # 2 永久開啓 ➜ cat /proc/sys/net/ipv4/tcp_syncookies 1服務器通常用下面的方法設置初始序列號:首5位是t模32的結果,其中t是一個32位的計數器,每隔 64秒增1;接着3位是對服務器最大段大小(8種可能之一)的編碼值;剩餘的24位保存了 4元組與t值的散列值,該數值是根據服務器選定的散列加密算法計算得到的。Server根據其中的t值可以計算出與加密 的散列值相同的結果,那麼服務器才會為該SYN重新構建隊列
-
減小SYN ACK重傳次數
減小重傳次數讓其達到最大重傳次數時,釋放掉SYN資源斷開連接,SYN ACK重傳次數由linux內核決定的,可以通過以下方式進行查看和設置:
➜ cat /proc/sys/net/ipv4/tcp_synack_retries 5
四次揮手
TCP斷開需要4步完成

- 假如Client想要釋放連接將會發送
FIN請求給Server端,接着進入FIN_WAIT_1狀態 - Server收到Client的
FIN請求後,給Client回了一個ACK響應,進入CLOSED_WAIT狀態 - Client收到Server的
ACK響應後,進入FIN_WAIT_2狀態,等待Server發送FIN請求 - Server處理完數據發送
FIN請求給Client,進入LAST_ACK狀態 - Client終於等到了Server的
FIN請求,趕緊給Server回了一個ACK響應,緊接着進入TIME_WAIT狀態,在等待2MSL時間後也會進入CLOSE狀態 - Server收到Client的
ACK響應後進入CLOSE狀態,此時Server已經完全關閉
抓包結果:

為什麼看到的是3次揮手?
不是説TCP斷開需要4次揮手嗎?為什麼實際抓包的結果卻是3次就完成了?這裏就需要了解TCP的延時確認機制
TCP的延遲確認(Delayed ACK)是一種優化TCP傳輸性能的機制。TCP協議默認採用延遲確認機制,即接收方不會立即發送確認消息,而是等待一定時間(通常是200ms),看是否需要返回數據,如果無需數據就會等待一會看後面的請求是否需要返回數據,便一起返回發送一個確認消息,以減少確認消息的數量和網絡負載,否則需要數據就會立刻返回ACK
而三次回收的情況通常是接收端不需要再發送數據了,根據延時確認機制便會將2、3次揮手(ACK&FIN)合併成一次數據返回,這就是為什麼實際網絡中看到的是3次揮手的原因。可以通過修改TCP的延遲發送值來禁用此功能,這裏不再展開
什麼是MSL?為啥需要2MSL
MSL(Maximum Segment Lifetime)是報文最大生存時間,也就是説網絡中最大的存活時間,否則將會丟棄。<u>MSL的時間通常大於TTL的跳數時間,IP的傳輸存活時間是基於TTL的跳數,每過一個路由器TTL都會減去1,直到為0時將會丟棄報文,同時發送ICMP報文通知源主機目標不可達</u>
MSL默認值通常為30,TTL的默認跳數為64,系統認為30s內IP可以被轉發64次。為什麼是2MSL呢?2MSL是從Client接收到Server的FIN報文後發送ACK報文開始計算的,假如ACK報文由於網絡原因在MSL時間內沒有到達Server,Server會觸發超時重傳機制再次發送FIN報文給Client,所以2MSL是最保險的時間,當Client等待2MSL內沒有收到任何Server的包就會被關閉掉
通過以下方式查看系統默認的TTL跳數和MSL時間
# TTL 默認跳數
➜ cat /proc/sys/net/ipv4/ip_default_ttl
64
# FIN默認超時時間(2MSL時間)
➜ cat /proc/sys/net/ipv4/tcp_fin_timeout
60有趣的是處於TIME_WAIT(2MSL)狀態下的端口還不能重新被使用!雖然Client已經收到Server的FIN報文併發送了ACK報文確定要斷開連接了,但在TIME_WAIT期間其端口還是不能被使用(儘管Server可能已經被關閉了),這個原因其實和為啥要等待2MSL道理一樣,都是為了避免2MSL期間Server重傳FIN報文。我們來驗證下端口不可用:
# 訪問本地nginx
➜ curl localhost
# 查看TCP的連接狀態,可以很明顯本地的 `33196` 端口關聯了 80端口,即curl隨機選用了 33196 端口訪問nginx
➜ netstat -ant | grep 80
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:33196 127.0.0.1:80 TIME_WAIT
# 使用nodejs監聽33196端口,拋出異常 端口被佔用
➜ node index.js
events.js:377
throw er; // Unhandled 'error' event
^
Error: listen EADDRINUSE: address already in use :::33196上述等再次查看33196已經被完全斷開時就可以正常啓動了
查看TCP狀態
可以在主機上通過netstat命令查看tcp的連接狀態,netstat是一個用於顯示網絡狀態和統計信息的命令行工具,可以用來查看系統的網絡連接、路由表、接口狀態等
➜ netstat -antp | more
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 872/rpcbind
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1229/nginx: master
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1211/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 1454/master
tcp 0 0 0.0.0.0:10010 0.0.0.0:* LISTEN 1229/nginx: master
tcp 0 196 192.168.10.9:22 192.168.10.1:65308 ESTABLISHED 1691/sshd: root@pts
tcp 0 0 127.0.0.1:33196 127.0.0.1:80 TIME_WAIT -可以從上看出tcp監聽的端口號、進程、連接狀態等等。如:nginx監聽了80端口、ssh監聽了22端口,22端口和65308端口保持連接(這裏我在主機用terminal連接了虛擬機)處於ESTABLISHED建立狀態,33196端口和80端口已經處於斷開但還在TIME_WAIT狀態
半連接、半斷開、半打開
要了解這幾種狀態含義需要明白TCP是個全雙工連接協議,它提供了全雙工的數據傳輸能力。全雙工連接指的是通信雙方可以同時發送和接收數據,而不受對方數據傳輸的影響。這意味着,在一個TCP連接中,數據可以沿着兩個方向同時傳輸,而不需要等待對方的回覆
半連接:在TCP三次握手時,Client如果不回覆Server端ACK報文時,Server端就處於SYN_RCVD狀態,消耗Server端的資源,常見的SYN攻擊就是基於半連接漏洞產生的
半斷開:在TCP四次揮手期間,Client發送了FIN報文後,卻一直等不到Server的FIN報文,此時Client只能收到報文而不能發送報文
半打開:正常的TCP連接雙方都可以收發數據報文,假如在某時間段兩端不進行任何數據傳輸,而一端由於某種原因斷開了且不發送任何FIN報文,另一端也不會知道是不是斷開了,這時就處於半打開狀態。而系統內核一般對TCP有一個保活機制(KeepAlive)來心跳檢測是否還處於連接狀態,當TCP在指定時間不發送任何數據,系統則認為已斷開連接
:::warning 注意
HTTP也有一個KeepAlive的概念,但與TCP的KeepAlive完全不同;HTTP的KeepAlive是開啓長連接,在HTTP/1.1默認會開啓,主要是提供HTTP請求可以在同一個TCP連接上完成,減小網絡開支;而TCP的KeepAlive是個保活機制,在長時間沒有進行數據傳輸時用來探測是否還處於連接狀態
:::
數據傳輸
我們知道TCP是個可靠傳輸協議,那麼它是如何實現數據傳輸的可靠性的呢?通常情況下TCP會對傳輸的數據進行分段並進行編號,當接受方收到數據後重新進行組裝。若在傳輸的過程中出現了丟包,發送端便會重傳丟失的包,其具體實現看下一小節
分段傳輸
TCP協議的每段最大數據長度通常被稱為MSS(Maximum Segment Size)1460,這個值是根據IP層MTU(Maximum Transmission Unit)最大傳輸單元計算的,MTU值一般為1500,如果過大會造成網絡中路由器的緩衝壓力,當IP層所傳輸的數據大小大於MTU時就會進行IP分片
如果IP分片傳輸中有一個IP片丟失了就會重傳所有的IP片段,這無疑會浪費網絡資源。所以TCP為了不讓數據在IP分片,通常設置為每片IP最大數據承載大小也稱為MSS。<u>MTU的值為1500字節,IP頭佔用20字節,TCP頭佔用20字節,因此MSS的值通常為1500-20-20=1460字節</u>
可以通過設備上的某個網卡查看MTU大小:
➜ cat /sys/class/net/ens160/mtu
1500在實際中MSS的值通常都是1448比1460少了12個字節,這通常是TCP的頭部選項部分會多12字節的時間戳等信息,其用來服務超時重傳等功能
滑動窗口
TCP的數據可靠傳輸類似於一問一答的形式,每發送一個數據包會通過另一方的確認來判斷是否丟包,但如果每次只能發送一個數據包將大大提高時延,因此TCP中引入了窗口的概念
什麼是TCP窗口(Window)?<u>窗口通常用來限制數據包的發送速率,是一個流量控制機制,通過動態改變窗口的大小進行控制發送速率</u>。窗口的大小通常等於接收方的窗口大小,會根據接收方的確認消息動態調整,在三次握手期間雖然沒有進行實質的數據傳輸,但通常都會協商一些有用的信息,其中就包含窗口的大小
窗口其實是個緩存空間,每一方都會在緩存空間中維護着一些有用的信息,如:已發送的數據、未發送的數據等等。假如發送方的窗口大小為3,那麼就會連續發送3個數據包,而不需要等待一個一個確認,同時緩衝區會記錄這些已發送和未發送的信息,從而改變窗口大小和位置
滑動窗口的概念則是調整發送數據的起始位置,TCP在傳輸數據時會將數據分成多段MSS大小的數據段並進行編號,然後便會以窗口大小為基本單位按順序發送數據,因此窗口範圍內的數據發送期必早於窗口後的數據。而窗口內通常會包含多個數據片段,每段數據被實際接收的時間會因為網絡原因進行波動,所以發送方收到不同數據片段的ACK時間也會不同,當窗口的前部分被確認後,就會進行窗口滑動,這樣後面未在窗口內的數據段就會被放入窗口內等待發送
大概的滑動窗口示意圖如下:

窗口的大小會根據接收方的確認信息、發送時延、擁塞控制動態改變的,然後來控制發送速率,達到數據傳輸的可靠、高效,接下來了解下TCP如何完成數據傳輸的可靠性
重傳機制
大家知道TCP是個可靠的傳輸協議,所以會有特殊的機制來保證傳輸數據的可靠性,而其中一個重要的特性就是超時重傳。當發送方發送一個報文後在指定的時間內沒有收到另一方的響應後,就會認為數據包已經丟失,便會根據重傳機制重新發送數據包
由於網絡波動等種種原因,超時重傳是避不開的問題,重傳有兩種機制:<u>基於時間和基於冗餘ACK,通常後者比前者更高效</u>
RTT、RTO
瞭解超時重傳前需要知道RTT、RTO兩個時間概念
RTT(Round-Trip Time)是指TCP數據包從發送方發送到收到接收到另一方的ACK所需的時間
RTO(Retransmission Timeout)是指TCP發送方在未收到確認的情況下等待重傳的時間
超時重傳是根據RTO的時間進行判斷的,RTO是根據RTT進行動態計算的,如何確定RTO的時間是非常關鍵的,通常略大於RTT的時間,過小造成網絡資源浪費,過大網絡延時偏大,這裏不具體展開其實現算法
超時重傳
當TCP發送一個數據包時會啓用一個定時器進行倒計時,如果在RTO的時間範圍內收到了對方的ACK包則重置定時器不會重傳報文,反之沒有收到另一方的ACK,則會重新發送數據包,並重啓定時器,當超時重傳時會把定時器的時間設置為上一次的2倍,也稱二進制指數避退(binary exponential backof),當然不會無線重傳下去,會有重傳的閾值,當超過了這個值就會斷開TCP連接,默認操作系統的重傳次數可以通過以下方式進行查看:
➜ cat /proc/sys/net/ipv4/tcp_syn_retries
6快速重傳
快速重傳不是基於定時器,而是基於數據進行重傳的,通常發生在沒有延時的情況下。若TCP累積確認無法返回新的ACK,或者當ACK包含選擇確認信息(SACK)表明出現失序報文段時,快速重傳會推斷出現丟包
通常來説,當發送端認為接收端可能出現數據丟失時,需要決定發送新(真正丟包的) 數據還是重傳所有的問題,處理不好就會造成網絡資源的浪費
TCP提供了SACK(Selective Acknowledgment)方法來提高重傳的效率。該機制允許接收方向發送方發送選擇性確認(SACK),即確認接收到的連續數據塊,同時告知發送方已經接收到丟失數據塊的位置,發送方一般都會維護一個緩衝區用來標識已發送的和超時的,從而讓發送方只重傳丟失的數據塊
擁塞控制
擁塞控制是一種網絡流量控制機制,用於避免在網絡中發生擁塞而導致網絡性能下降或崩潰。該機制通過動態調整發送數據的速率來控制網絡中的擁塞程度,並確保網絡能夠承載傳輸的數據量
TCP的擁塞控制算法通常基於網絡擁塞的反饋信息,例如丟包、延遲等。當TCP發送方收到這些反饋信息時,它會採取一系列措施來減少發送數據的速率,以避免過多的數據流入網絡中而導致擁塞。<u>通過改變發送窗口進行速率的控制,發送窗口一般等於接收窗口,而有了擁塞控制後,發送窗口會取擁塞窗口和接收窗口的最小值</u>
慢啓動
在TCP連接建立時,發送方會將擁塞窗口的大小設置為一個較小的值,通常為2個最大分段大小(MSS)。發送方將擁塞窗口的大小逐漸增加,每發送一個數據段就將窗口大小加1,這樣可以使得發送方逐漸探測網絡的可用帶寬。但不可能一直這樣增長下去,當擁塞窗口大小達到一個閾值時,發送方將進入擁塞避免階段,此時擁塞窗口的增加速率將變慢
假如擁塞窗口剛開始為1,當接受到1個ACK後,窗口大小加1可以同時發送2個SYN,然後接受到2個ACK後變成窗口大小變為4;接着發送4個SYN收到後大小變成8;就這樣反覆增加直到達到最大閾值,慢啓動算法就是以指數的形式增加,增加速度比較快
擁塞避免
當達到慢啓動的閾值時就會進入擁塞避免算法,以防止指數級的發送造成網絡堵塞問題,擁塞避免算法當收到1個ACK時,擁塞窗口增加1/n個大小,這樣窗口的增長速率會越來越小
除了慢啓動、擁塞避免算法外,還有快速恢復算法快速來恢復發送速率,這裏不再展開了
總結
本文從TCP的首部、建立斷開、傳輸過程、重傳機制、擁塞控制等多方面講述了TCP協議的工作方式和細節,而TCP遠不止這麼簡單內容,作為非網絡工程師對於更深的概念瞭解下即可,掌握這些通常足夠了
參考文獻
- 計算機網絡(自定向下方法第7版)
- TCP/IP詳解 卷1:協議(原書第2版)