

文檔預處理之文本化
近日,我們收到來自專業用户的使用心得,通過測試淺析結構化信息提取技術,輔助完成技術選型。結構化信息提取的重要性數據作為大模型時代的核心生產資料,其結構化處理能力直接影響AI系統的實用價值。
結構化信息提取的重要性
數據作為大模型時代的核心生產資料,其結構化處理能力直接影響AI系統的實用價值。儘管知識圖譜、RAG等技術依賴海量文本資源,但現實中的歷史檔案、法律文書等重要數據多以掃描件、圖像等非結構化形式存在,導致信息抽取、語義解析等環節面臨顯著技術障礙。
當前結構化信息提取技術雖呈現多樣化發展,但對於開發者而言,結構化信息提取的“落地”與“可用性”才是真正的考驗,研究論文中的指標和高精度模型在生產環境中可能面臨性能瓶頸、成本過高、部署難度大等現實挑戰。本文將梳理主流技術方案,立足實際需求,結合一系列實測數據與實踐經驗,評估各方法在不同場景下的表現與優劣勢。
從技術指標到生產可行性,我們將為開發者提供一份實用的兼顧算法效能與部署成本的參考指南。
評價標準
測評
使用的待測試pdf:隨機選取的一份上交所上市公司的2023年年報,全文193頁。



金融年報是電子文檔中相對複雜的一類,文字密度大,表格複雜度高,標題層級多,對模型能力有較大考驗。遂選取之作為測試素材。
基於大模型的識別方案舉例
市面上流行的幾個開源pdf轉markdown方法,大體可以分為兩種,一類走傳統版面分析+公式表格識別+OCR方案,另一類則是走視覺大模型路線。
利用大模型執行pdf轉markdown算是一種邏輯上比較容易的辦法,藉助大模型本身強大的視覺識別能力,進行力大磚飛的轉換。
從原理上,這種方法可以自如地進行轉換,同時可以在轉換過程中保留儘可能多的視覺信息,基礎的諸如標題層級,進階的還可以對圖片進行一定的語義解釋。
視覺大模型的接口也容易獲得,有條件的情況下可以本地部署。
本次實驗採取識別能力靠前[2]且常用的gpt-4o模型配合 gptpdf 來進行實驗:
測試
gptpdf的封裝度較高,且依賴較少,一次pip即可安裝。
如果是使用openai服務的話,只需填寫上自己的key即可。如果自己有大模型部署的話,也可改成自己的代理地址,也可使用本地的視覺模型。
測試代碼用的是單線程,由於速度較慢遠低於預期,遂只拆出前30頁進行測試。效果如下:
可以看到,問題還是比較多的,比如幻覺問題:

大模型幻覺出了一些奇怪的標題。
識別結構不穩定:

此處本應是一個表格。
我使用的是gptpdf默認的prompt,可能有優化空間。但是效果的確不盡如人意。
而且速度也是有夠慢,僅僅三十頁運行了477.34s,就算可以多線程,單頁16s的開銷也使其很難用於快速文檔解析場景。
小結
本次測試還有一些可以優化的點,例如使用經過調試的提示詞,或者換用對中文視覺支持更好的大模型。但該方案整體上價格偏高,單管道處理速度也較慢,除非和一些基於大模型的預處理進行步驟合併,否則不推薦使用。
基於本地OCR的識別方案舉例
相對視覺大模型方案,OCR方案則小巧且複雜,其使用較小的模型各司其職,並對結果進行拼接。其算力要求相對低的特點也使其適用於本地部署,一個廣受好評的解決方案是MinerU,作為開源的數據提取工具,目前在github上已經有24.3k stars.
測試
minerU的安裝相對複雜些,且如果要安裝gpu版本需要額外的步驟。
該方案是完全開源的,好消息是有些組件可以根據需求定製化更改。壞消息是,可能有一些bug,需要查issues自行修復。
解析速度還算過關,在i7-2700+3090上運行,平均4.52s每頁。在不同階段使用的算力硬件也不同,多線程情況下速度或許會更快。
值得注意的是,由於markdown格式表格不易於顯示覆雜表,minerU的默認表格識別將會把表格轉換為html格式,從純文本打開的話會像是這樣:

issues中有人給出了能轉換為markdown格式的替代方案,但是這同樣需要額外的配置,在此暫不討論。來看看效果:

標題只有一層,即是標題/不是標題。在表格識別能力上偏弱,偶爾會出現例如:

無限復讀機;

換頁時文本錯誤/表格結構錯誤。
小結
大概是開源領域最好的ocr方案了,如果有本地算力且文件保密要求高的話還是比較推薦的。默認的html格式個人認為有些雞肋,不能保證準確性,同時也不利於大模型讀取。先前提到的轉換為markdown格式的替代方案我也嘗試過,能一定程度減少識別錯誤,但會增加使用難度,且還是有較多錯誤。
基於雲端OCR的識別方案舉例
如果項目沒有本地部署需求,那麼雲端OCR是個好方案,價格相對大模型方法低廉許多,且響應速度快。橫評了一眾中文OCR方案,Textin的數據是最好的。
測試
速度奇快,一份193頁的pdf文件僅消耗了13s,幾乎是其餘方案的百倍。
幾乎沒有錯誤,只是偶有標題會被漏標:

只有極複雜的表格才能使其產生小錯誤:原表格:

識別後:

小結
綜合下來是速度且效果最好的OCR方案了,適用大多數場景,非常推薦。
大結論
總表
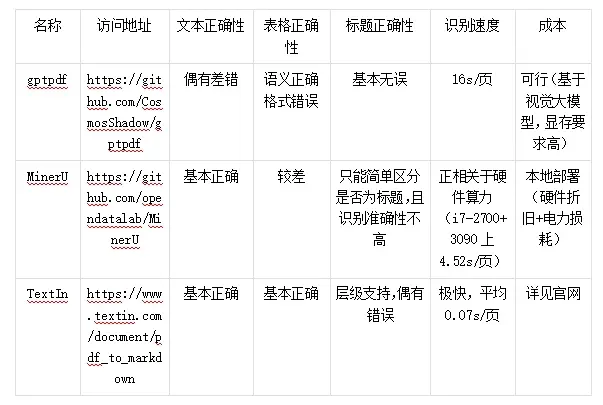
從效果上,幾種方法都在可接受的範圍內。
視覺大模型方案成本高昂且可靠性較差,儘管近來有較多類似功能的開源倉庫,但效果較差,價格高,速度慢,因此不建議使用此類方案。
從部署成本來説,如果有較強的本地算力,用量大且成本有限,建議使用本地OCR識別方案;如果對精確度要求高,資金充足,則建議使用雲端OCR的識別方案;如果對精確度和數據安全都有較高的要求,可以選擇TextIn本地部署。
最後附上測試代碼和結果,也可以幫助你便捷完成批量轉換。
mdfy_test:https://github.com/RwandanMtGorilla/mdfy_test
參考文獻
[1] OCR Hinders RAG: Evaluating the Cascading Impact of OCR on Retrieval-Augmented Generation https://arxiv.org/abs/2412.02592v1
[2] llm的基礎OCR識字能力 CC-OCR: A Comprehensive and Challenging OCR Benchmark for Evaluating Large Multimodal Models in Literacy https://arxiv.org/pdf/2412.02210
[3] Document Parsing Unveiled: Techniques, Challenges,and Prospects for Structured Information Extraction 文檔解析綜述 https://arxiv.org/pdf/2410.21169
[4] A Comparative Study of PDF Parsing Tools Across Diverse Document Categories https://arxiv.org/pdf/2410.0987