

一、簡要介紹

Transformer在計算機視覺領域迅速普及,特別是在目標識別和檢測領域。在檢查最先進的目標檢測方法的結果時,我們注意到,在幾乎每個視頻或圖像數據集中,transformer始終優於完善的基於cnn的檢測器。雖然基於transformer的方法仍然處於小目標檢測(SOD)技術的前沿,但本文旨在探索如此廣泛的網絡所提供的性能效益,並確定其SOD優勢的潛在原因。小目標由於其低可見性,已被確定為檢測框架中最具挑戰性的目標類型之一。論文的目的是研究可以提高transformer在SOD中的性能的潛在策略。本調查對跨越2020年至2023年的60多個針對SOD任務開發的transformer的研究進行了分類。這些研究包括各種檢測應用,包括在通用圖像、航空圖像、醫學圖像、主動毫米圖像、水下圖像和視頻中的小目標檢測。論文還編制並提供了12個適合SOD的大規模數據集,這些數據集在以前的研究中被忽視了,並使用流行的指標如平均平均精度(mAP)、每秒幀(FPS)、參數數量等來比較回顧研究的性能。
二、研究背景
小型目標檢測(SOD)已被認為是最先進的(SOTA)目標檢測方法的一個重大挑戰。術語“小目標”指的是佔據輸入圖像的一小部分的目標。例如,在廣泛使用的MS COCO數據集中,它定義了在典型的480×640圖像中,邊界框為32×32像素或更小的目標(圖1)。其他數據集也有自己的定義,例如,佔圖像10%的目標。小目標經常被錯誤的局部邊界框遺漏或發現,有時還會有不正確的標籤。SOD中定位不足的主要原因是輸入圖像或視頻幀中提供的信息有限,再加上它們在深度網絡中通過多層時隨後經歷的空間退化。由於小目標經常出現在行人檢測、醫學圖像分析、人臉識別、交通標誌檢測、交通燈檢測、船舶檢測、基於合成孔徑雷達(SAR)的目標檢測等各種應用領域中,因此值得研究現代深度學習SOD技術的性能。在本文中,作者比較了基於transformer的檢測器與基於卷積神經網絡(CNNs)的檢測器在其小目標檢測方面的性能。在性能明顯優於cnn的情況下,論文然後試圖揭示transformer的強大性能背後的原因。一個直接的解釋可能是,transformer建模了輸入圖像中成對位置之間的相互作用。這是一種有效的編碼上下文的方式。而且,在人類和計算模型中,上下文都是檢測和識別小目標的主要信息來源。然而,這可能不是解釋transformer成功的唯一因素。具體來説,論文的目標是從幾個維度來分析這一成功,包括目標表示、對高分辨率或多尺度特徵圖的快速關注、完全基於transformer的檢測、架構和塊修改、輔助技術、改進的特徵表示和時空信息。此外,論文還指出了有可能提高SOD transformer性能的方法。

在之前的工作中,論文調查了許多基於深度學習的策略,以提高到2022年在光學圖像和視頻中的小目標檢測的性能。論文發現,除了適應transformer等較新的深度學習結構之外,流行的方法還包括數據增強、超分辨率、多尺度特徵學習、上下文學習、基於注意力的學習、區域建議、損失函數正則化、利用輔助任務和時空特徵聚合。此外,論文觀察到,transformer是在大多數數據集中定位小目標的主要方法之一。然而,考慮到之前的工作主要評估了160多篇關注於基於cnn的網絡的論文,因此沒有對以transformer為中心的方法進行深入的探索。認識到該領域的增長和探索速度,現在有了一個及時的窗口來深入研究針對小目標檢測的當前transformer模型。 在本文中,作者的目標是全面瞭解影響transformer在應用於小目標檢測時令人印象深刻的性能的因素,以及它們與用於通用目標檢測的策略的區別。為了奠定基礎,論文首先突出了著名的基於transformer的SOD目標檢測器,並將它們的進展與現有的基於cnn的方法並列起來。 自2017年以來,該領域已經發表了大量的綜述文章。在之前的調查中介紹了這些評論的廣泛討論和清單。最近的另一篇綜述文章也主要關注基於cnn的技術。當前綜述的敍述與之前的敍述不同。本文中的重點特別縮小到transformer——一個之前沒有探索過的方面——將它們定位為圖像和視頻SOD的主導網絡架構。這需要針對這種創新體系結構量身定製的獨特分類法,有意識地避開基於cnn的方法。鑑於這個主題的新穎性和複雜性,論文的評論主要優先考慮2022年後提出的作品。此外,論文還闡明瞭在更廣泛的應用範圍中用於定位和檢測小目標的新數據集。 本調查中的研究主要提出了針對小目標定位和分類的方法,或間接解決了SOD的挑戰。推動我們進行分析的是這些論文中為小目標指定的檢測結果。然而,早期的研究注意了SOD結果,但在其開發方法中表現出不佳或忽略了SOD特定參數,沒有考慮納入本綜述。在本調查中,我們假設讀者已經熟悉了通用的目標檢測技術、它們的架構和相關的性能度量。 本文的結構如下:在第3節中,論文提出了一個基於transformer的SOD技術的分類,並對每個類別進行了全面的深入研究。第4節展示了用於SOD的不同數據集,並跨一系列應用程序對它們進行了評估。在第5節中,論文分析並將這些結果與之前來自CNN網絡的結果進行了對比。本文在第6節中總結了一些結論。
三、用於小目標檢測的transformer
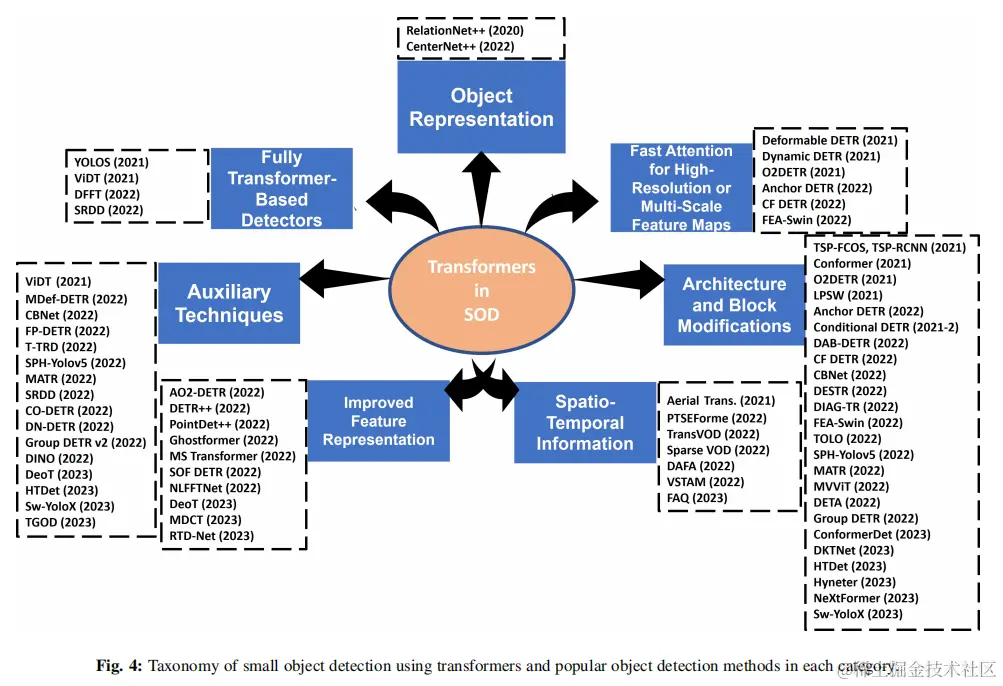
在本節中,論文將討論基於transformer的SOD網絡。小目標檢測器的分類法如圖4所示。論文表明,現有的基於新型transformer的檢測器可以通過以下一個或幾個角度進行分析:目標表示、對高分辨率或多尺度特徵圖的快速注意力、完全基於transformer的檢測、架構和塊修改、輔助技術、改進的特徵表示和時空信息。在下面的小節中,將分別詳細討論這些類別。
3.1 Object Representation
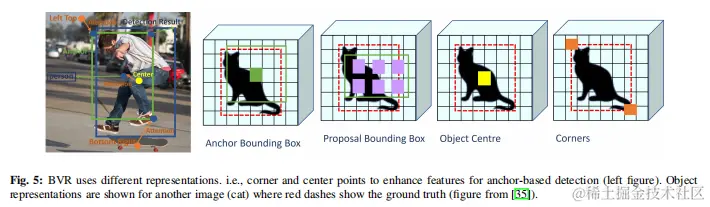
在目標檢測技術中已經採用了各種目標表示技術。感興趣的目標可以用矩形框、中心點和點集、概率目標和關鍵點來表示。在需要註釋格式和小目標表示方面,每種目標表示技術都有自己的優缺點。在保持現有表示技術的所有優勢的同時,尋找最優表示技術的追求,從RelationNet++開始。這種方法連接了各種異構的視覺表示,並通過一個稱為橋接視覺表示(BVR)的模塊結合了它們的優勢。BVR可以有效地運行,但並不破壞主要表示所採用的整體推理過程,它利用了關鍵採樣和共享位置嵌入的新技術。更重要的是,BVR依賴於一個注意模塊,該模塊將一種表示形式指定為“主表示”(或查詢),而其他表示則被指定為“輔助”表示(或鍵)。BVR塊如圖5所示,它通過將中心點和角點(鍵)無縫集成到基於錨定(查詢)的目標檢測方法中,增強了錨定盒的特徵表示。
3.2 Fast Attention for High-Resolution or Multi-Scale Feature Maps
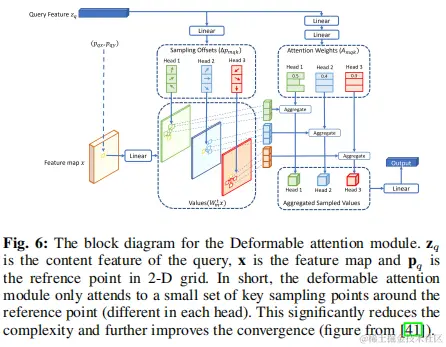
以往的研究表明,保持高分辨率的特徵圖是保持SOD中高性能的必要步驟。與cnn相比,transformer本質上表現出明顯更高的複雜度,這是因為它們的複雜度相對於令牌的數量(例如,像素數量)呈二次增加。這種複雜性來自於跨所有令牌的成對相關性計算的要求。因此,訓練時間和推理時間都超過了預期,使得檢測器不適用於高分辨率圖像和視頻中的小目標檢測。在他們關於可變形的DETR的工作中,Zhu等人解決了第一次在DETR中觀察到的這個問題。他們建議只關注一個參考文獻周圍的一小部分關鍵採樣點,這大大降低了複雜性。採用這種策略,通過使用多尺度變形注意模塊有效地保持了空間分辨率。值得注意的是,該方法消除了特徵金字塔網絡的必要性,從而大大提高了對小目標的檢測和識別。變形注意中多頭注意模塊的第i個輸出為:
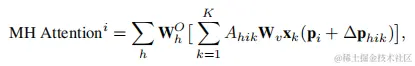
其中,i = 1,···,T和pi是查詢的參考點,∆phik是K個採樣(K<<T=HW)的採樣偏移量(2D)。圖6説明了其多頭注意模塊內的計算過程。可變形的DETR受益於它的編碼器和解碼器模塊,編碼器內的複雜度順序為O(HW C2),其中H和W為輸入特徵圖的高度和寬度,C為通道數。與DETR編碼器相比,複雜度為O(H2W2C),隨着H和W的增加,複雜性呈二次增長。可變形注意在其他各種檢測器中發揮了突出的作用,例如在T-TRD中。隨後,DETR,具有動態編碼器和動態解碼器,利用從低分辨率到高分辨率表示的特徵金字塔,從而實現高效的粗到細的目標檢測和更快的收斂。動態編碼器可以看作是完全自我注意的順序分解近似,基於尺度、空間重要性和表徵動態調整注意機制。可變形DETR和動態DETR都利用可變形卷積進行特徵提取。在一種獨特的方法中,O2DETR 證明了自注意模塊提供的全局推理實際上對航空圖像並不是必需的,在航空圖像中,目標通常密集地聚集在同一圖像區域。因此,用局部卷積代替注意模塊,並集成多尺度特徵映射,被證明可以在面向目標檢測的環境中提高檢測性能。RCDA作者提出了行-列解耦注意(RCDA)的概念,將關鍵特徵的二維注意分解為兩種更簡單的形式:一維行注意和列注意。在CF-DETR 的情況下,提出了一種FPN的替代方法,即在第5級(E5)用編碼器特徵替換C5特徵,從而改進了目標表示。該創新被命名為transformer增強型FPN(TEF)模塊。在另一項研究中,Xu等人通過將跳躍連接操作與Swintransformer集成,開發了一個加權的雙向特徵金字塔網絡(BiFPN)。這種方法有效地保存了與小目標相關的信息。
3.3 Fully Transformer-Based Detectors
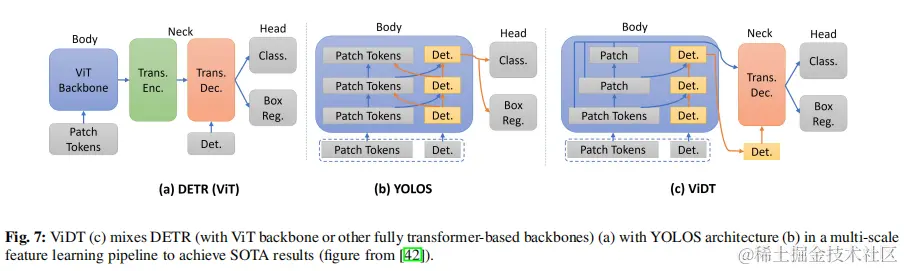
Transformer的出現及其在計算機視覺中許多複雜任務中的出色性能,逐漸促使研究人員從基於cnn或混合系統轉向完全基於transformer的視覺系統。這項工作始於圖像識別任務,該任務稱為ViT。ViDT擴展了YOLOS模型(第一個完全基於transformer的檢測器),以開發出第一個適用於SOD的高效檢測器。在ViDT中,DETR中用於特徵提取的ResNet被各種ViT變體所取代,如Swintransformer、ViTDet 和DeiT ,以及重新配置的注意模塊(RAM)。RAM能夠處理[PATCH]×[PATCH]、[DET]×[PATCH]和[PATCH]×[DET]的注意。這些交叉和自我注意模塊是必要的,因為與YOLOS類似,ViDT在輸入中附加了[DET]和[PATCH]標記。ViDT只利用一個transformer解碼器作為其頸部,以利用在其身體步驟的每個階段產生的多尺度特徵。圖7説明了ViDT的總體結構,並突出了其與DETR和YOLOS的區別。
認識到解碼器模塊是基於transformer的目標檢測低效的主要來源,無解碼器全transformer(DFFT)利用兩個編碼器:尺度聚合編碼器(SAE)和任務對齊編碼器(TAE),以保持較高的準確性。SAE將多尺度特徵(四個尺度)聚合成一個單一特徵圖,而TAE則對單一特徵圖進行對齊,用於目標類型、位置分類和迴歸。採用面向檢測的transformer(DOT)骨幹技術進行了具有強語義的多尺度特徵提取。 在基於稀疏roi的可變形DETR(SRDD)中,作者提出了一種帶有評分系統的輕量級transformer,以最終去除編碼器中的冗餘令牌。這是通過在端到端學習方案中使用基於roi的檢測來實現的。
3.4 Architecture and Block Modifications
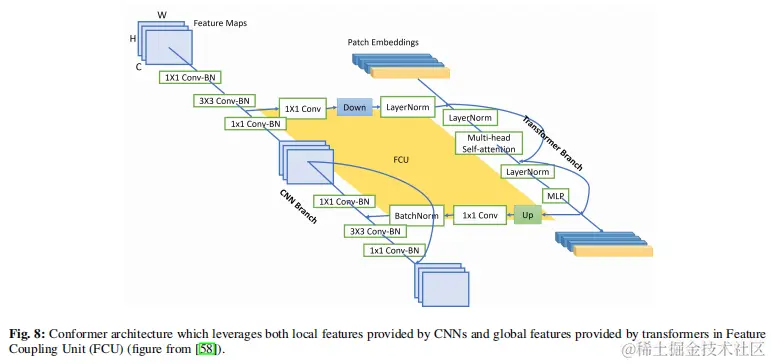
DETR是第一種端到端目標檢測方法,它在訓練過程中延長了收斂時間,在小目標上表現較差。一些研究工作已經解決了這些問題,以提高SOD的性能。一個值得注意的貢獻來自Sun等人,他從FCOS(一個完全卷積單級檢測器)和faster RCNN中獲得靈感,提出了兩種僅編碼器的DETR變體,稱為TSP-FCOS和TSP-RCNN。這是通過消除解碼器中的交叉注意模塊來實現的。他們的研究結果表明,解碼器中的交叉注意和匈牙利損失的不穩定性是DETR後期收斂的主要原因。這一發現導致他們放棄瞭解碼器,並在這些新的變體中引入了一種新的二部匹配技術,即TSP-FCOS和TSP-RCNN。 Peng等人通過聯合使用cnn和transformer的方法,提出了一種稱為“構形”的混合網絡結構。該結構將cnn提供的局部特徵表示與不同分辨率的transformer提供的全局特徵表示相結合(見圖8)。這是通過特徵耦合單元(FCUs)實現的,實驗結果證明了其與ResNet50、ResNet101、DeiT等模型相比的有效性。
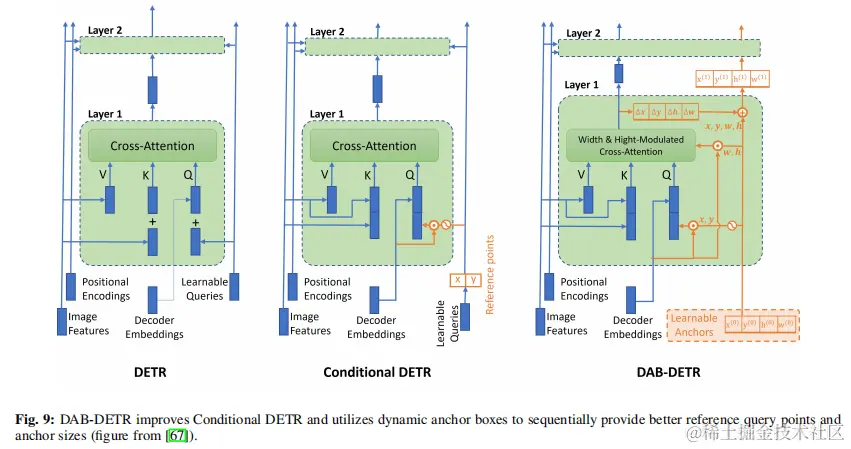
認識到局部感知和隨機相關性的重要性,Xu等人在Swintransformer的Swintransformer塊中添加了一個局部感知塊(LPB)。這種新的主幹,稱為局部感知振盪變換(LPSW),顯著地改進了空中圖像中小目標的檢測。DIAG-TR 在編碼器中引入了一個全局-局部特徵交織(GLFI)模塊,以自適應和分層地將局部特徵嵌入到全局表示中。這種技術平衡了小目標的尺度差異。此外,可學習的錨盒座標被添加到transformer解碼器中的內容查詢中,提供了一個歸納偏差。在最近的一項研究中,Chen等人提出了混合網絡transformer,它通過將卷積嵌入到transformer塊中擴展了局部信息的範圍。這一改進增強了對MS COCO數據集的檢測結果。在另一項研究中,作者提出了一種名為NeXtfrorm的新主幹,它結合了CNN和transformer,以增強小目標的局部細節和特徵,同時也提供了一個全局的接受域。 在各種方法中,O2DETR 用深度可分離卷積代替了transformer中的注意機制。這一變化不僅降低了與多尺度特徵相關的內存使用和計算成本,而且還潛在地提高了航空照片的檢測精度。 Wang等人質疑之前工作中使用的目標查詢,提出了錨點DETR,它使用錨點進行目標查詢。這些錨點增強了目標查詢位置的可解釋性。對每個錨點使用多個模式,改進了對一個區域內的多個目標的檢測。相比之下,Conditional DETR 強調從解碼器內容中衍生出的條件空間查詢,從而導致空間注意預測。隨後的一個版本,條件DETR v2 ,通過將目標查詢重新構造為方框查詢的形式,增強了體系結構。此修改涉及嵌入一個參考點和針對參考點轉換框。在隨後的工作中,DABDETR通過使用動態可調的錨定盒,進一步改進了查詢設計的思想。這些錨點框既作為參考查詢點,又作為錨點尺寸(參見圖9)。
在另一項工作 中,作者觀察到,雖然DETR中小目標的平均平均精度(mAP)不能與最先進的(SOTA)技術競爭,但它在小IoU閾值下的性能驚人地優於其競爭對手。這表明,雖然DETR提供了較強的感知能力,但它需要進行微調,以獲得更好的定位精度。作為一種解決方案,提出了粗到精細的檢測transformer(CF-DETR),通過解碼器層中的自適應尺度融合(ASF)和局部交叉注意(LCA)模塊來進行這種細化。在之前的一個研究中,作者認為,基於transformer的檢測器的次優性能可以歸因於使用單一的交叉注意模塊進行分類和迴歸、內容查詢的初始化不足以及在自注意模塊中缺乏利用先驗知識等因素。為了解決這些問題,他們提出了檢測分裂transformer(DESTR)。該模型將交叉注意力分為兩個分支,一個用於分類,另一個用於迴歸。此外,DESTR使用了一個迷你檢測器來確保在解碼器中適當的內容查詢初始化,並增強了自注意模塊。另一項研究引入了FEA-Swin,它利用了Swintransformer框架中的高級前景增強關注,將上下文信息集成到原始的主幹中。這是由於Swintransformer不能充分處理密集的目標檢測,由於缺少相鄰目標之間的連接。因此,前景增強突出了需要進一步進行相關性分析的目標。TOLO 是最近的工作之一,旨在通過一個簡單的頸部模塊將感應偏差(使用CNN)引入transformer架構。該模塊結合了來自不同層的特性,以合併高分辨率和高語義的屬性。設計了多個光transformer磁頭,用於檢測不同尺度下的目標。由Liang等人提出的CBNet,不是修改每個架構中的模塊,而是將通過複合連接連接的多個相同的主幹進行分組。 在多源聚合transformer(MATR)中,該transformer的交叉注意模塊用於利用來自不同視圖的同一目標的其他支持映像。一項研究中也採用了類似的方法,其中多視圖視覺transformer(MVViT)框架結合了來自多個視圖的信息,包括目標視圖,以提高當目標在單一視圖中不可見時的檢測性能。 其他工作更喜歡堅持YOLO架構。例如,SPH-Yolov5 在Yolov5網絡的較淺層中增加了一個新的分支,以融合特徵,以改進小目標定位。它還首次在Yolov5管道中加入了Swintransformer預測頭。 另一項研究中,作者認為,匈牙利損失的直接一對一的邊界盒匹配方法可能並不總是有利的。他們證明了使用單組分配策略和使用NMS(非最大抑制)模塊可以導致更好的檢測結果。與這個觀點相同,Group DETR 通過一對一的標籤分配實現了K組目標查詢,從而對每個地面真實目標進行K個正目標查詢,以提高性能。 DKTNet提出了一種雙鍵transformer網絡,其中使用了兩個鍵——一個是Q流,另一個是V流。這增強了Q和V之間的一致性,從而改善了學習能力。此外,通過計算通道注意而不是空間注意,並使用一維卷積來加速該過程。
3.5 Auxiliary Techniques
實驗結果表明,輔助技術或任務與主任務相結合,可以提高性能。在transformer的背景下,已經採用了幾種技術,包括: (i)輔助解碼/編碼損失:這是指為邊界框迴歸和目標分類而設計的前饋網絡連接到單獨的解碼層的方法。因此,將不同尺度上的個體損失組合起來來訓練模型,從而獲得更好的檢測結果。該技術或其變體已用於ViDT ,MDef-DETR,CBNet,SRDD 。(ii)迭代框細化:在這種方法中,每個解碼層內的邊界框都是根據前一層的預測進行細化的。這種反饋機制逐步提高了檢測精度。該技術已用於ViDT 。(iii)自上而下的監督:這種方法利用人類可理解的語義來幫助檢測小的或類不可知的目標的複雜任務,例如,MDef-DETR 中的對齊圖像文本對,或TGOD 中的文本引導目標檢測器。(iv)預訓練:這包括在大規模數據集上進行訓練,然後對檢測任務進行特定的微調。該技術已被用於CBNet V2-TTA 、FPDETR、T-TRD、SPH-Yolov5、MATR ,並廣泛應用於DETR v2組。(v)數據增強:該技術通過應用旋轉、翻轉、放大、裁剪、翻譯、添加噪聲等各種增強技術,豐富了檢測數據集。數據增強是一種常用的解決各種不平衡問題的方法,例如,在深度學習數據集中目標大小的不平衡。數據增強可以被看作是一種間接的方法,以最小化訓練集和測試集之間的差距。一些方法在檢測任務中使用了增強功能,包括TTRD [43]、SPH-Yolov5 、MATR 、NLFFTNet 、DeoT、HTDet和Sw-YoloX 。(vi)一對多標籤分配:DETR中的一對一匹配會導致編碼器內較差的鑑別特徵。因此,在其他方法中,一對多的作業,如Faster-RCNN、RetinaNet和FCOS已經被用作CO-DETR的輔助頭部。(vii)去噪訓練:該技術旨在提高DETR中解碼器的收斂速度,由於二部匹配而經常面臨不穩定的收斂問題。在去噪訓練中,解碼器將有噪聲的地面真實標籤和盒子輸入解碼器。然後訓練該模型來重建原始的GT值(在一個輔助損失的引導下)。像DINO 和DN-DETR 這樣的實現已經證明了該技術在提高解碼器的穩定性方面的有效性。
3.6 Improved Feature Representation
儘管當前的目標檢測器在常規大小或大型目標的廣泛應用中出色,但某些用例需要專門的特性表示來改進SOD。例如,當涉及到檢測航空圖像中的定向目標時,任何目標旋轉都可以大大改變特徵表示,因為在場景中增加的背景噪聲或雜波(區域建議)。為了解決這個問題,Dai等人提出了AO2-DETR,這是一種設計為對任意目標旋轉具有魯棒性的方法。這是通過三個關鍵組件來實現的: (i)定向候選的生成,(ii)定向候選的改進模塊,它提取旋轉不變特徵,以及(iii)旋轉感知集匹配損失。這些模塊有助於抵消目標的任何旋轉的影響。在一種相關的方法中,DETR++使用了多個雙向特徵金字塔層(BiFPN),它們以自底而上的方式應用於來自C3、C4和C5的特徵圖。然後,只選擇一個代表所有尺度特徵的尺度,輸入DETR框架進行檢測。對於一些特定的應用程序,如工廠安全監測,其中感興趣的目標通常與人類工人相關,利用這些上下文信息可以極大地改善特徵表示。PointDet++ 利用了這一點,結合了人體姿態估計技術,集成了局部和全局特徵來提高SOD性能。影響特徵質量的另一個關鍵因素是主幹網絡及其提取語義和高分辨率特徵的能力。GhostNet提供了一個精簡和更高效的網絡,為transformer提供高質量、多尺度的功能。他們在這個網絡中的Ghost模塊部分生成輸出特徵圖,其餘部分使用簡單的線性操作來恢復。這是緩解骨幹網絡複雜性的關鍵步驟。在醫學圖像分析的背景下,MStransformer使用自監督學習方法對輸入圖像執行隨機掩模,這有助於重建更豐富的特徵,較不敏感的噪聲。與分層transformer相結合,這種方法優於具有各種骨幹的DETR框架。小目標偏好DETR(SOFDETR),特別支持通過在輸入到DETR-transformer之前合併來自第3層和第4層的卷積特徵來檢測小目標。NLFFTNet通過引入非局部特徵融合transformer卷積網絡,捕獲不同特徵層之間的長距離語義關係,解決了當前融合技術中只考慮局部交互的侷限性。DeoT 將一個僅限編碼器的transformer與一個新的特徵金字塔融合模塊合併。通過在通道細化模塊(CRM)和空間細化模塊(SRM)中使用通道和空間注意力,增強了這種融合,從而能夠提取出更豐富的特徵。HTDet 的作者提出了一種細粒度的FPN來累積融合低級和高級特徵,以更好地進行目標檢測。同時,在MDCT 中,作者提出了一個多核擴展卷積(MDC)模塊,以同時利用小目標的本體和相鄰空間特徵來提高小目標相關特徵提取的性能。該模塊利用深度可分離卷積來降低計算成本。最後,RTD-Net的一個特徵融合模塊配對了一個輕量級的主幹,通過拓寬接受域來增強小目標的視覺特徵。RTD-Net中的混合注意模塊,通過合併小目標周圍的上下文信息,使系統能夠檢測部分被遮擋的目標。
3.7 Spatio-Temporal Information
在本節中,我們的重點完全是基於視頻的目標檢測器,旨在識別小目標。雖然許多這些研究已經在ImageNet VID數據集上進行了測試,但該數據集最初並不是用於小目標檢測的。儘管如此,也有一些工作報告了他們對ImageNet VID數據集的小目標的結果。跟蹤和檢測視頻中的小目標的主題也已經利用transformer體系結構進行了探索。雖然基於圖像的SOD技術可以應用於視頻,但它們通常不利用有價值的時間信息,這對於識別雜亂或遮擋幀中的小目標特別有用。transformer在一般目標檢測/跟蹤中的應用始於跟蹤transformer和TransT。這些模型使用了幀到幀(設置前一幀作為參考)設置預測和模板到幀(設置一個模板幀作為參考)檢測。Liu等人是第一批使用transformer專門用於基於視頻的小目標檢測和跟蹤的人之一。他們的核心概念是更新模板框架,以捕捉由小目標的存在引起的任何小的變化,並在模板框架和搜索框架之間提供一個全局的注意驅動的關係。 通過引入端到端目標檢測器TransVOD,基於transformer的目標檢測獲得了正式的識別。該模型將空間和時間transformer應用於一系列視頻幀,從而識別和連接到這些幀中的目標。TransVOD已經產生了幾個變體,每個變體都有獨特的特性,包括實時檢測功能。PTSE採用漸進策略,關注時間信息和目標幀間的空間轉換。它採用了多尺度的特徵提取來實現這一目標。與其他模型不同,PT-SEFrorter直接從相鄰幀而不是整個數據集迴歸目標查詢,提供了一種更本地化的方法。Sparse VOD 提出了一種端到端可訓練的視頻目標檢測器,它結合了時間信息來提出區域建議。相比之下,DAFA 強調了視頻中全局特徵的重要性,而不是局部時間特徵。DEFA指出了FIFO記憶結構的低效,並提出了一種採用目標級記憶代替幀級記憶的多樣性感知記憶作為注意模塊。VSTAM 在逐個元素的基礎上提高了特徵質量,然後在將這些增強的特徵用於目標候選區域檢測之前執行稀疏聚合。該模型還結合了外部記憶,以利用長期的上下文信息。在FAQ工作中,提出了一種在解碼器模塊中使用查詢特徵聚合的新型視頻目標檢測器。這與專注於編碼器中的特性聚合的方法或對不同幀執行後處理的方法不同。研究表明,該技術的檢測性能優於SOTA方法。
四、結果和基準
在本節中,論文將定量和定性地評估以前的小目標檢測工作,確定一個特定應用的最有效的技術。在此比較之前,論文引入了一系列專門用於小目標檢測的新數據集,包括用於不同應用程序的視頻和圖像。
4.1數據集
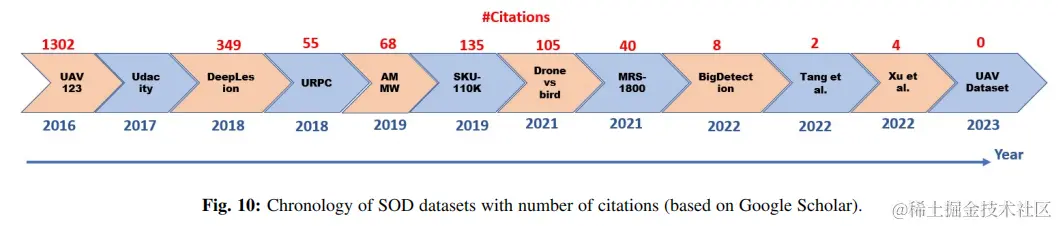
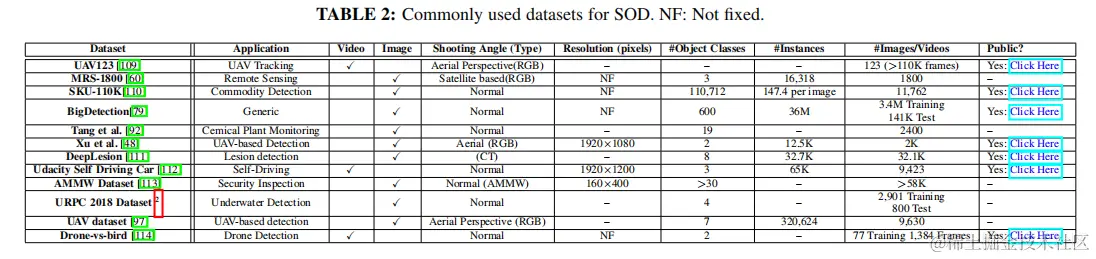
在本小節中,除了廣泛使用的MS COCO數據集外,還彙編並呈現了12個新的SOD數據集。這些新的數據集主要是為特定的應用程序而定製的,除了通用環境和海洋環境。圖10顯示了這些數據集的時間順序以及截至2023年6月15日的引文計數。
UAV123:該數據集包含123個用無人機獲取的123個視頻,是全球最大的幀數超過110K幀的目標跟蹤數據集之一。 MRS-1800:該數據集由來自其他三個遙感數據集的圖像組合組成: DIOR 、NWPU VHR-10 和HRRSD。MRD-1800是為了檢測和實例分割的雙重目的,有1800張手動註釋的圖像,其中包括3種類型的目標:飛機、船隻和儲罐。 SKU-110K :該數據集可作為商品檢測的嚴格測試平台,以從世界各地的各種超市捕獲的圖像為特色。該數據集包括一系列的尺度、相機角度、照明條件等。 BigDetection:這是一個大規模的數據集,通過集成現有的數據集,細緻地消除重複的盒子,同時標記被忽略的目標。它具有各種大小的目標數量的平衡,使它成為推進現場目標檢測的關鍵資源。使用此數據集進行預訓練和隨後對MS COCO進行微調,可以顯著提高性能結果。 Tang等人:該數據集源自化工廠現場活動的視頻片段,涵蓋了各種類型的工作,如熱作業、空中作業、密閉空間作業等。它包括人、頭盔、滅火器、手套、工作服等相關物品等分類標籤。 Xu等人:這個公開的數據集專注於無人機捕獲的圖像,幷包含2K張圖像,旨在檢測行人和車輛。這些圖像是使用大疆無人機收集的,並具有不同的條件,如不同的光照水平和密集停放的車輛。 DeepLesion:包括4427名患者的CT掃描,該數據集是同類數據中最大的。它包括多種病變類型,如肺結節、骨異常、腎臟病變和腫大淋巴結。這些圖像中感興趣的目標通常很小,並伴隨着噪聲,這使得它們的識別具有挑戰性。 Udacity Self Driving Car:僅為教育用途設計,該數據集具有在山景城和附近城市的駕駛場景,以2Hz的圖像採集率捕獲。該數據集中的類別標籤包括汽車、卡車和行人。 AMMW數據集:它是為安全應用程序而創建的,這個活動的毫米波圖像數據集包含了30多個不同類型的目標。這包括兩種打火機(由塑料和金屬製成),一種模擬槍支,一把刀,一把刀片,一個子彈殼、手機、湯、鑰匙、磁鐵、液體瓶、吸收材料、火柴等等。 URPC 2018數據集:該水下圖像數據集包括四種類型的目標:全息魚、棘魚、扇貝和海星。 UAV數據集:該圖像數據集包括無人機在不同天氣、光照條件和各種複雜背景下捕獲的9K多個圖像。這個數據集中的目標是轎車、人、馬達、自行車、卡車、公共汽車和三輪車。 Drone-vs-bird:這個視頻數據集旨在解決無人機在敏感地區飛行的安全問題。它提供了帶標記的視頻序列,以區分在各種照明、照明、天氣和背景條件下的鳥類和無人機 表2提供了這些數據集的摘要,包括它們的應用程序、類型、分辨率、類/實例/圖像/幀的數量,以及到它們的網頁的鏈接。
4.2視覺應用程序中的基準測試
在本小節中,將介紹各種基於視覺的應用程序,其中對小目標的檢測性能至關重要。對於每個應用程序,我們選擇一個最流行的數據集,並報告其性能指標,以及實驗設置的細節。 4.2.1通用應用程序 對於通用應用程序,論文在具有挑戰性的MS COCO基準測試上評估所有小型目標檢測器的性能。該數據集的選擇是基於它在目標檢測領域的廣泛接受度和性能結果的可訪問性。MS COCO數據集由橫跨80個類別的大約160K張圖像組成。雖然建議作者使用COCO 2017訓練和驗證集來訓練他們的算法,但它們並不侷限於這些子集。
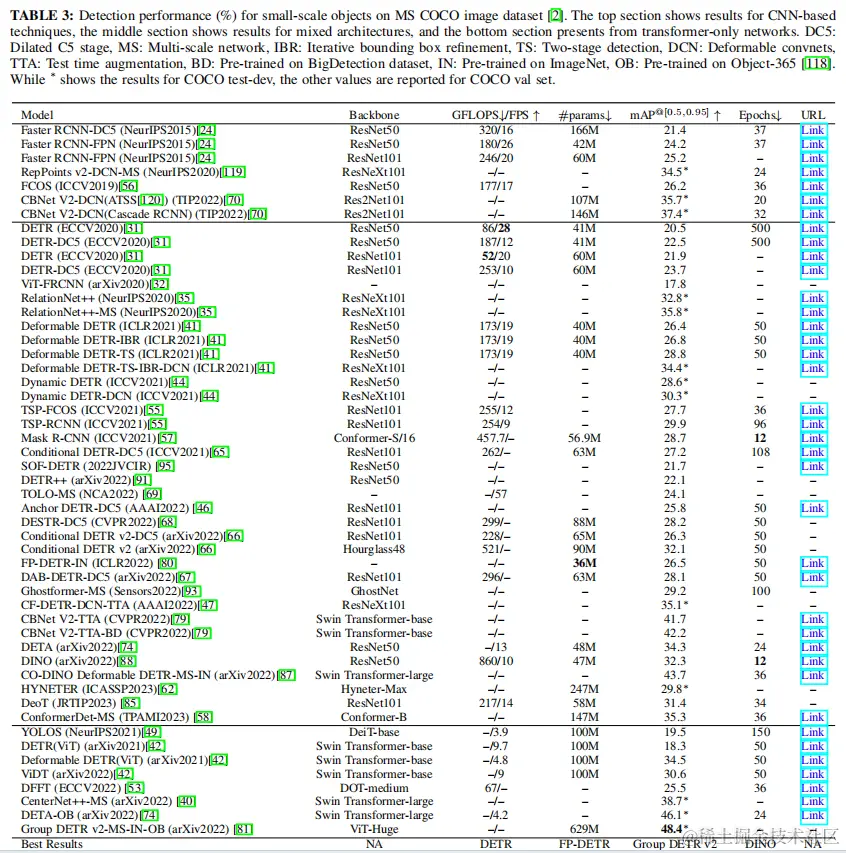
在表3中,檢查和評估了所有報告其在MS COCO上的結果(從他們的論文彙編)的檢測技術的性能。該表提供了關於主幹架構、GFLOPS/FPS(表示計算花費和執行速度)、參數數量(表示模型的規模)、mAP(平均平均精度:目標檢測性能的度量)和epoch(表示推理時間和收斂特性)的信息。此外,還提供了指向每個方法網頁的鏈接以供進一步參考。這些方法被分為三組:基於cnn的方法,混合的方法和transformer專用的方法。每個度量的最佳性能方法顯示在表的最後一行中。應該指出的是,這種比較只適用於那些報告了每個特定度量值的方法。在出現平局的情況下,平均平均精度最高的方法被認為是最好的。默認的mAP值為“COCO2017val”集,而“COCO test-dev”集的mAP值用星號標記。請注意,所報告的mAP僅適用於具有<322目標的區域。 通過檢查表3,很明顯,大多數技術都受益於使用CNN和transformer架構的混合,本質上是採用混合策略。值得注意的是,僅依賴於基於transformer的架構的組DETR v2,獲得的mAP為48.4%的mAP。然而,實現這樣的性能需要採用額外的技術,如在兩個大規模數據集上進行預訓練和多尺度學習。在收斂性方面,DINO僅在12個時代後就達到了穩定的結果,同時也獲得了值得稱讚的32.3%的mAP。相反,原始的DETR模型具有最快的推理時間和最低的GFLOPS。FP-DETR擁有最輕的網絡,只有36M的參數。 根據這些發現,論文得出結論,預訓練和多尺度學習是最有效的策略。這可能是由於下游任務的不平衡和小目標中缺乏信息特徵。 圖11以及圖12中更詳細的對應內容,説明了各種transformer和基於cnn的方法的檢測結果。它們使用從COCO數據集中選擇的圖像進行相互比較,並由論文使用它們在GitHub頁面上提供的公共模型來實現。分析表明,faster RCNN和SSD在準確檢測小目標方面存在不足。具體來説,SSD要麼錯過了大多數目標,要麼生成了大量帶有假標籤的邊界框和位置不佳的邊界框。雖然faster RCNN表現得更好,但它仍然會產生低可信度的邊界框,並偶爾分配不正確的標籤。 =



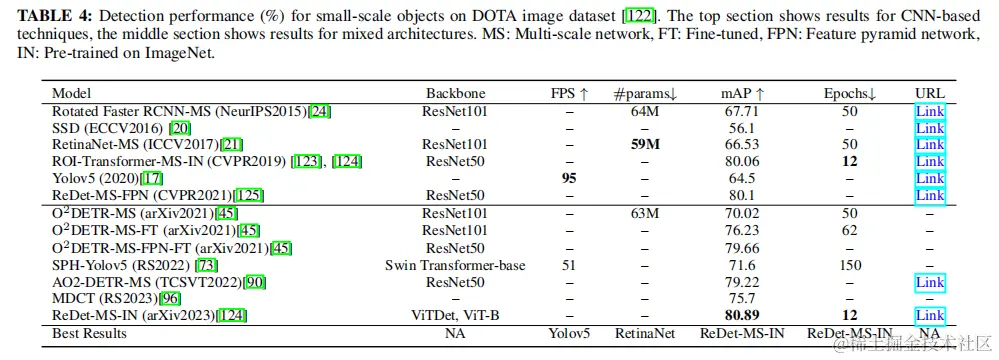
相比之下,DETR有高估目標數量的傾向,導致單個目標的多個邊界框。人們通常注意到,DETR容易產生假陽性。最後,在評價的方法中,CBNet V2以其優越的性能而突出。正如觀察到的,它對它檢測到的目標產生高置信分數,即使它偶爾會錯誤識別某些目標。 4.2.2在航空圖像中的小目標檢測 檢測小目標的另一個有趣的用途是在遙感領域。這一領域特別吸引人,因為許多組織和研究機構的目標是通過航空圖像定期監測地球表面,以收集國家和國際數據進行統計。雖然這些圖像可以使用各種方式獲得,但本調查只關注非sar圖像。這是因為SAR圖像已經得到了廣泛的研究,值得它們自己的單獨研究。儘管如此,本調查中討論的學習技術也可以適用於SAR圖像。 在航空圖像中,由於目標與照相機的距離很遠,它們通常看起來很小。鳥瞰圖也增加了目標檢測任務的複雜性,因為目標可以位於圖像內的任何地方。為了評估為此類應用設計的基於transformer的檢測器的性能,論文選擇了DOTA圖像數據集,它已成為目標檢測領域廣泛使用的基準。圖13顯示了來自DOTA數據集中的具有小目標的一些示例圖像。該數據集包括一個預定義的訓練集、驗證集和測試集。與一般應用相比,這種特殊的應用受到的transformer專家的關注相對較少。然而,如表4所示(結果來自論文),ReDet通過其多尺度學習策略和在ImageNet數據集上的預訓練進行區分,達到了最高的精度值(80.89%),只需要12個訓練期。這反映了從COCO數據集分析中獲得的見解,表明通過解決下游任務中的不平衡和包括來自小目標的信息特徵,可以獲得最佳性能。

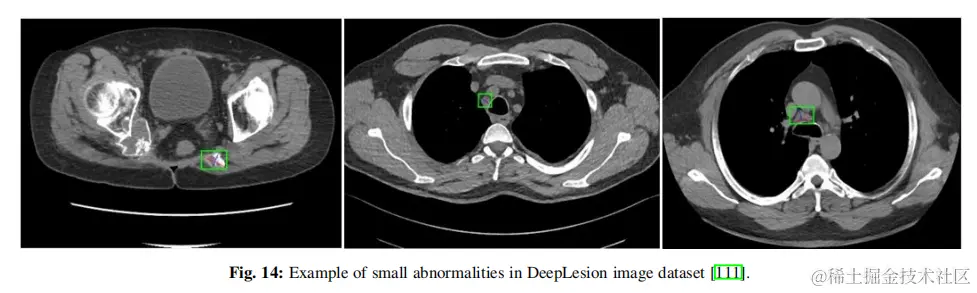
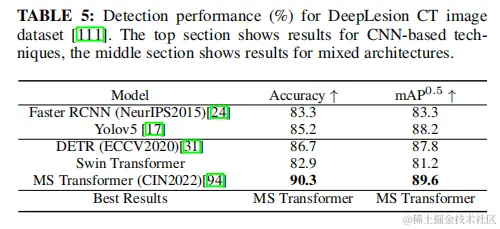
4.2.3醫學圖像中的小目標檢測 在醫學成像領域,專家的任務往往是早期發現和識別異常。即使是幾乎看不見或很小的異常細胞缺失,也會對患者造成嚴重的影響,包括癌症和危及生命的疾病。這些小目標可見於糖尿病患者視網膜異常、早期腫瘤、血管斑塊等。儘管這一研究領域具有關鍵的性質和潛在的危及生命的影響,但只有少數研究解決了在這一關鍵應用中與檢測小目標相關的挑戰。對於那些對這個主題感興趣的人,因為特定數據集的結果的可用性,論文選擇了深度病變CT圖像數據集作為基準。來自這個數據集的樣本圖像如圖14所示。該數據集被分為三組:訓練(70%)、驗證(15%)和測試(15%)集。表5比較了三種基於transformer的研究與兩級和一級檢測器的準確性和mAP(結果彙編自他們的論文)。MStransformer成為這個數據集上最好的技術,儘管競爭有限。它的主要創新在於自我監督學習和在一個分層transformer模型中加入一個掩碼機制。總的來説,該數據集的準確率為90.3%,mAP為89.6%,與其他醫學成像任務相比似乎沒有挑戰性,特別是考慮到一些腫瘤檢測任務幾乎是看不見的。
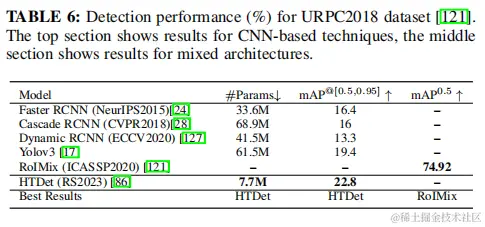
4.2.4在水下圖像中的小目標檢測 隨着水下活動的增長,為了生態監測、設備維護和沉船捕魚監測等目的,監測朦朧和低光環境的需求增加。諸如水的散射和光吸收等因素,使SOD的任務更具挑戰性。圖15顯示了這種具有挑戰性的環境的示例圖像。基於transformer的檢測方法不僅應該能夠識別小目標,而且還需要對在深水中發現的低圖像質量,以及由於每個通道的光衰減率不同而導致的顏色通道的變化具有魯棒性。 表6顯示了該數據集現有研究報告的性能指標(結果從他們的論文整理)。HTDet是為此特定應用程序而確定的唯一的基於transformer的技術。它的性能顯著優於基於SOTA cnn的方法(mAP為3.4%)。然而,相對較低的mAP分數證實了在水下圖像中的目標檢測仍然是一項困難的任務。值得注意的是,URPC 2018的訓練集包含2901張標記圖像,測試集包含800張未標記圖像。

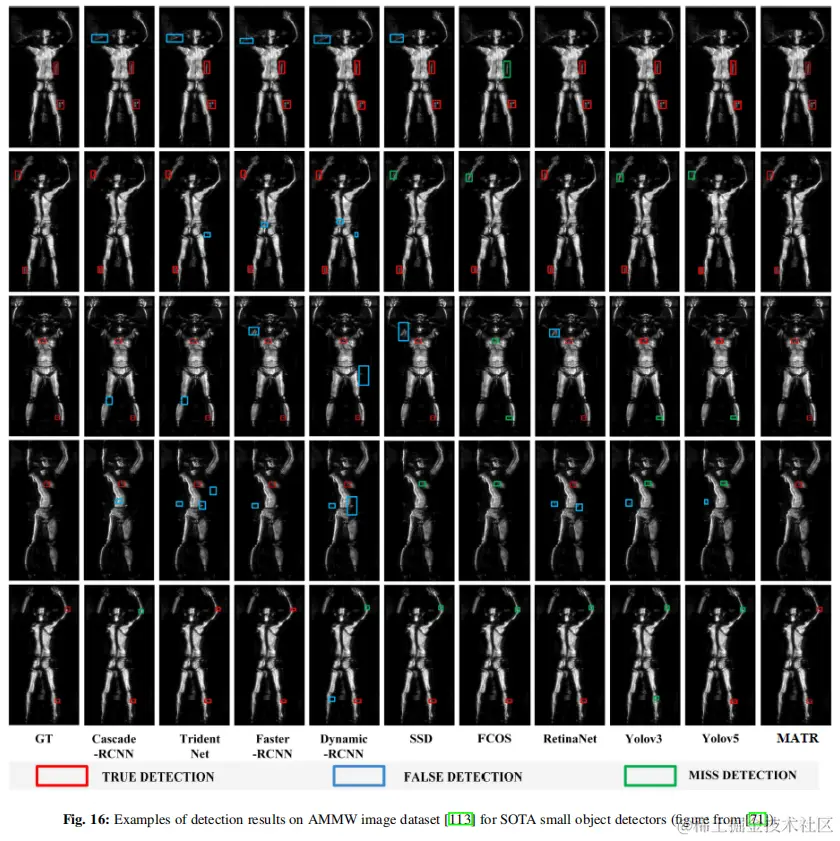
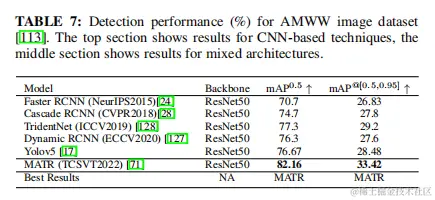
4.2.5 主動毫米波圖像中的小目標檢測 小目標可以很容易地隱藏在普通的RGB攝像頭中,例如,在機場的一個人的衣服裏。因此,主動成像技術對於安全目的至關重要。在這些場景中,通常從不同的角度捕獲多個圖像,以提高檢測哪怕是微小目標的可能性。有趣的是,就像在醫學成像領域一樣,transformer很少被用於這種特殊的應用。 在論文的研究中,重點關注了使用AMMW數據集的現有技術的檢測性能,如表7所示(結果來自他們的論文)。作者確定,MATR是為該數據集結合transformer和cnn的唯一技術。儘管是唯一一種基於transformer的技術,但它可以顯著提高相同主幹(ResNet50)的SOD性能。圖16直觀地比較了MATR與其他基於SOTA cnn的技術。在這種成像方法中,在很大程度上結合不同角度的圖像有助於識別即使是小的目標。對於訓練和測試,分別使用了35426張和4019張圖像。
4.2.6視頻中的小目標檢測 由於視頻中的時間信息可以提高檢測性能,視頻中的目標檢測領域最近得到了廣泛的關注。為了對SOTA技術進行基準測試,ImageNet VID數據集已經被用於特別關注數據集中的小目標的結果。該數據集包括3862個訓練視頻和555個驗證視頻,包含30類目標。表8報告了幾種最近開發的基於transformer的技術的映射。雖然transformer越來越多地用於視頻目標檢測,但它們在SOD中的性能仍然很少被探索。在已經在ImageNet VID數據集上報告了SOD性能的方法中,帶有FAQ的可變形DETR獲得了最高的性能。這突出了基於視頻的SOD領域的一個重大研究差距。

五、討論
在這篇綜述文章中,探討了基於transformer的方法如何解決SOD的挑戰。論文的分類法將基於transformer的小目標檢測器分為7個主要類別:目標表示、快速關注(用於高分辨率和多尺度特徵圖)、架構和塊修改、時空信息、改進的特徵表示、輔助技術和完全基於transformer的檢測器。 當將此分類與基於CNN的技術的分類並置時,論文觀察到其中一些類別重疊,而另一些類別是基於transformer的技術所特有的。某些策略被隱式地嵌入到transformer中,如注意學習和上下文學習,它們通過編碼器和解碼器中的自我注意模塊和交叉注意模塊來執行。另一方面,多尺度學習、輔助任務、體系結構修改和數據增強在這兩種範式中都被普遍使用。然而,需要注意的是,當cnn通過3D-CNN、RNN或特徵隨時間聚合來處理時空分析時,transformer通過使用連續的時空transformer或更新解碼器中連續幀的目標查詢來實現這一點。 論文觀察到,預訓練和多尺度學習是最常用的策略,在不同的數據集上為不同的數據集提供了最先進的性能。數據融合是另一種廣泛應用於SOD的方法。在基於視頻的檢測系統中,重點是如何收集時間數據並將其集成到特定於幀的檢測模塊中的有效方法。 雖然transformer在小目標的定位和分類方面取得了實質性的進步,但所付出的代價是很重要的。這些包括大量的參數(數十億個左右),幾天的訓練(幾百個迭代的epoch)和在非常大的數據集上進行預訓練(如果沒有強大的計算資源,這是不可行的)。所有這些方面都限制了能夠為其下游任務訓練和測試這些技術的用户池。現在,認識到對具有高效學習範式和架構的輕量級網絡的需求比以往任何時候都更加重要。儘管現在參數的數量與人類大腦相當,但在小目標檢測方面的性能仍然遠遠落後於人類的能力,這凸顯了當前研究中的一個重大差距。 此外,基於圖11和圖12中的發現,論文確定了小目標檢測中的兩個主要挑戰:缺失目標或假陰性,以及冗餘的檢測框。丟失目標的問題很可能是由於令牌中嵌入的信息有限所致。這可以通過使用高分辨率圖像或增強特徵金字塔來解決,儘管這帶有增加延遲的缺點——這可能通過使用更高效、輕量級的網絡來抵消。重複檢測的問題傳統上是通過後處理技術,如非最大抑制(NMS)來管理的。然而,在transformer的上下文中,這個問題應該通過最小化解碼器中的目標查詢相似性來解決,可能是通過使用輔助損失函數。 論文還研究了使用基於transformer的方法,專門在一系列基於視覺的任務中進行小目標檢測(SOD)的研究。這些檢測包括通用檢測、航空圖像檢測、醫學圖像中的異常檢測、用於安全目的的主動毫米波圖像中的小隱藏目標檢測、水下目標檢測和視頻中的小目標檢測。除了通用和航空圖像應用,transformer在其他應用中還不發達,與之前工作關於海上檢測的觀察一致。考慮到transformer在醫學成像等生命領域可能產生的重大影響,這尤其令人驚訝。
六、結論
本綜述論文回顧了60多篇研究論文,專注於開發小目標檢測任務的transformer,包括純基於transformer和集成cnn的混合技術。這些技術已經從七個不同的角度進行了研究:目標表示、用於高分辨率或多尺度特徵圖的快速注意機制、架構和塊的修改、時空信息、改進的特徵表示、輔助技術和完全基於transformer的檢測。這些類別都包括幾種最先進的(SOTA)技術,每一種都有自己的優點。論文還將這些基於transformer的方法與基於cnn的框架進行了比較,討論了兩者之間的異同。此外,對於一系列的視覺應用程序,論文引入了成熟的數據集,作為未來研究的基準。此外,本文還詳細討論了在SOD應用中使用的12個數據集,為未來的研究工作提供了便利。在未來的研究中,可以探索和解決與每個應用程序中的小目標檢測相關的獨特挑戰。像醫學成像和水下圖像分析等領域將從使用transformer模型中獲得顯著的收益。此外,除了使用更大的模型來提高transformer的複雜性外,還可以探索替代策略來提高性能。