

隨着大模型在社會應用中逐漸普及,人們在享受便利的同時,也面臨着“AI 幻覺”產生的風險。訓練數據是影響大模型“認知能力”的關鍵要素,近期,上海合合信息科技股份有限公司(簡稱“合合信息”)TextIn“大模型加速器 2.0”版本正式上線,基於領先的智能文檔處理技術,對複雜文檔的版式、佈局和元素進行精準解析及結構化處理,從數據源頭降低大模型“幻覺”風險,讓大模型在與人類的溝通中“更靠譜”。
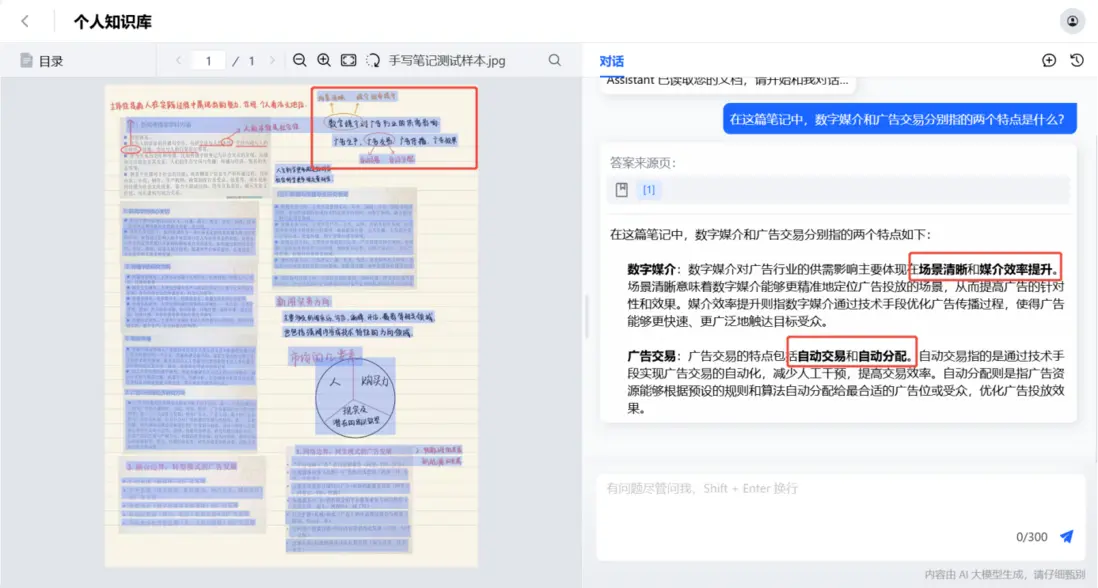
“大模型加速器 2.0”文檔解析引擎助力知識庫理解手寫筆記示意圖
據悉,升級後的“大模型加速器”在複雜版面理解、表格及圖表處理、內容溯源等能力上實現新突破,可精準識別上千種文檔中的跨頁表格、合併單元格、密集表格、手寫字符及公式,解析穩定率達99.99%,單頁處理耗時較行業可比產品降低超30%;可“逆還原”十餘種專業圖表數據,並將其轉化為大模型可理解的結構化數據。此外,“大模型加速器 2.0”版本新增知識庫系列開源組件,助力醫療、製造、教育等行業開發者構建個性化的知識庫。
文檔解析技術助力教育大模型建設
大模型需要不斷“吸收”正確的專業知識,才能應對實際應用問題。合合信息技術團隊成員表示,在處理年報、論文、實驗室報告等專業文檔的過程中,一個符號的解析失誤,便可能“誤導”大模型,得出與事實相悖的結論。可信性的缺失,也制約了大模型在實際應用場景中的縱深拓展。
賽爾教育科技發展有限公司(簡稱“賽爾教育”)系“中國教育和科研計算機網CERNET”的運營公司賽爾網絡的重要子公司,是教育國際化、教育信息化、數字化教育方案的提供商。賽爾教育CTO、教育數字化事業部總經理楊林提到,教育行業中所涉及的文檔格式多樣,在內容上也包含了表格、公式、手寫字符、多語言文字等信息。如何高效準確地提取各類文檔中的文本信息,並非易事。
“教育行業的大模型建設工作中,數據的數量和質量起着決定性作用。我們做了很多嘗試,模型的速度和準確性都達不到要求,嚴重影響科研工作的進展。”楊林表示,行業知識庫的構建基於大量文檔的文本信息提取,需要高效率、高準確率的工具。合合信息文檔解析技術提供了專業的技術支持和服務,有效解決了文檔處理過程中的問題。
在“大模型加速器”的支持下,合合信息與賽爾教育共同協作,提升大模型對複雜版面、元素的“理解力”,使其按照人類正常的閲讀順序識別文檔結構,智能劃分標題、段落、表格和圖表等內容塊,幫助大模型理解版面、內容間的對應關係,減少AI“幻覺”現象。

圖表解析模塊將圖表還原為表格數據
除了複雜的版面佈局,種類繁多、空間結構複雜的圖表元素也是解析難點所在。“大模型加速器2.0”圖表解析模塊可智能提取多種圖表中的關鍵數據點、座標軸信息、圖例説明等,在精準解析不同類型圖表數據的基礎上,將其還原為一組完整的Excel表格數據,作用於教育行業大模型微調,學科知識庫建設、智能審閲等環節。
智能溯源讓大模型用得更“安心”
近期,多家券商機構紛紛宣佈接入大模型,幫助分析師、行業研究員等專業人士提高工作效率。為幫助用户簡化專業文檔數據篩選和數據抽取流程,提升文檔內容解讀效率與準確率,“大模型加速器 2.0”上線了知識庫產品組件,支持複雜文檔的智能問答、總結與檢索。
為了讓行業“安心”使用大模型,知識庫產品推出溯源功能,通過在“投喂”給知識庫的Markdown及JSON文件中標記頁碼、座標等空間位置信息,實現對句子、段落的精確溯源,為用户提供了一個快速檢驗的路徑。以財務分析為例,大模型在多份高達上千頁的財報文件中找到收入、利潤等關鍵數據後,券商分析師可利用溯源功能定位原表格,對信息進行復核,防止錯誤、遺漏。

知識庫對財報數據所在表格進行精準溯源
目前,知識庫組件已面向開發者開源,幫助其根據自身需要快速構建個性化行業知識庫。此前,合合信息已開源智能文檔處理“百寶箱”系列產品,解決文檔解析精度低、解析效果評估難等問題,開發者可根據研發需求靈活搭配使用。未來,“大模型加速器”將持續優化迭代,助力大模型在各行各業中“百花齊放”。