
【項目背景描述】
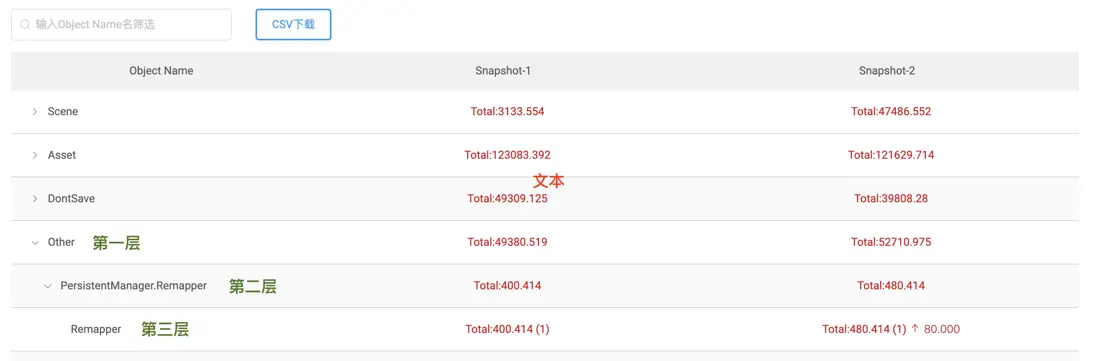
有一個表格,描述的是Snapshot-1和Snapshot-2之間的對比,數據對比的結果是由後端算出來的,前端只要負責渲染就可以。
後端返回的數據本質是一個“森林”,每棵“樹”都是三層,分別是:type/ class name/ object name。由於每棵樹的計算量比較大,孩子節點也比較多,所以在前端渲染的時候,使用懶加載做了優化,即只有當用户展開某層的時候才會call到後端請求數據。所以,頁面第一次渲染的時候,顯示的是森林裏所有樹的第一層。
除了頁面的數據展示,Diff表格還支持csv download,由於csv需要拿到全量的對比數據,也就是整片森林,所以當用户點擊CSV下載的時候,會先call後端拿到全量數據,再csv format,最後輸出。
【出現問題】
有用户反饋説:CSV下載等了好久都在loading,問怎麼回事?
【排查過程】
1.前述環境
- 我們有本地開發環境(對應自己本地的數據庫,可以操作後端代碼and前端代碼)
- 用户出現問題的是prod環境(本地的前端是無法call到prod環境的DB的)
2.找到瓶頸
- 打開用户的報告,確實數據量很大,點擊csv download,感覺下載一個diff文件,大概需要30s左右的時間。也就是説代碼邏輯沒有問題,就是慢。
- 打開控制枱,看數據返回時間。其實時間不是很長,只有7s,因此,時間的瓶頸不在這裏。
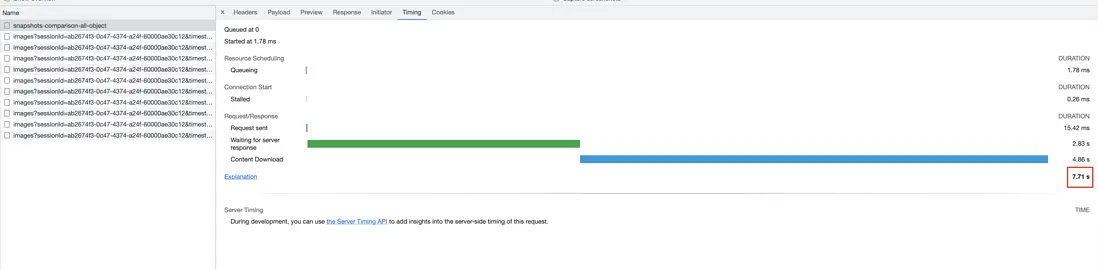
- 接下來,就是看api callback裏面的處理邏輯有什麼可以優化的地方了。但是,如何拿到用户的數據呢?由於本地開發環境是沒有辦法連上prod的數據庫的。
- 【解決方案】:可以在開發者模式下,拿到api返回的數據,並將其保存成json,在前端代碼裏import進來進行處理。
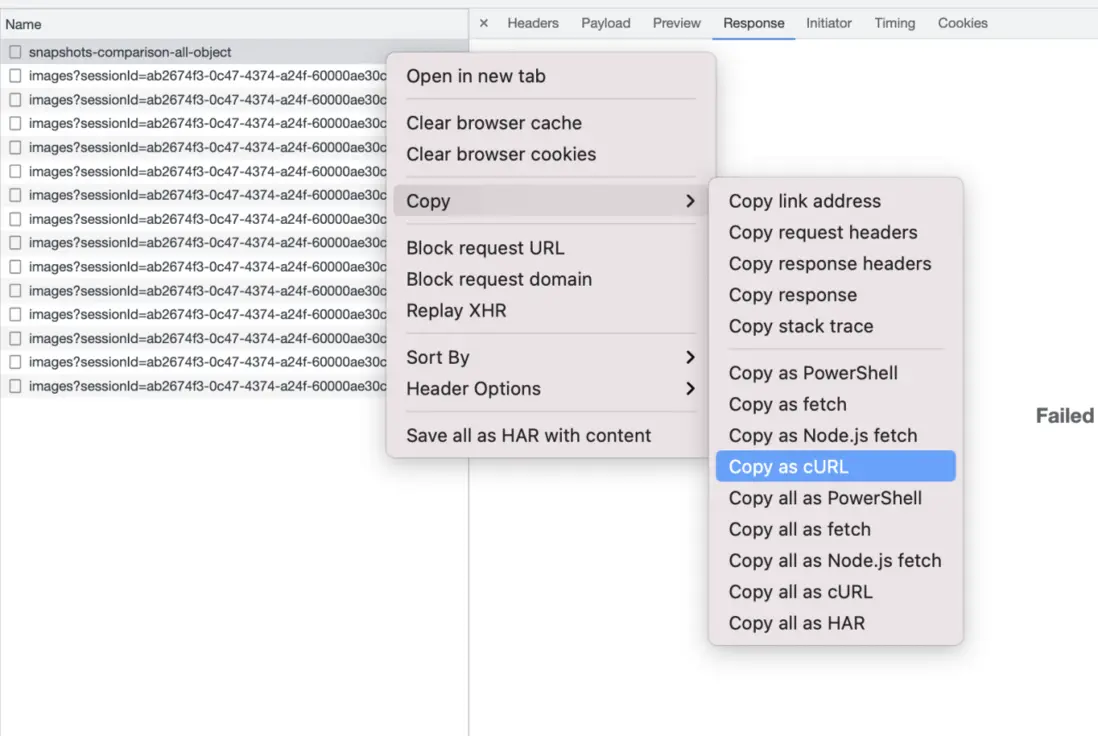
- 但是,由於返回的結果過於龐大,response無法load,“複製粘貼”的計劃失敗。

- 【解決方案】:右擊url,找到Copy as cURL,並在命令的結尾加上“>> 1.txt”,可以將response結果直接輸出到文件,而不是命令行,方便複製。
- 萬事俱備,開始查看瓶頸。在csv format中的每個函數後面,console.log一個時間戳,便於查看究竟哪裏比較耗時。最終發現,sort函數佔用了大量的時間,因為有2層for循環。重新查看代碼,其實call回來的api在後端處理的時候,其實已經是排好順序的,因此,前端無需“多此一舉”。
- 綜上所述,刪除前端sort函數即可。(省略後續測試步驟......)
【知識點回顧】
curl 是常用的命令行工具,用來請求 Web 服務器。它的名字就是客户端(client)的 URL 工具的意思。有很多不同的命令行參數,方便開發者在cmd裏請求api。