

我們在這篇文章中新增了 Chandra 和 OlmOCR-2,並附上了它們在 OlmOCR 基準上的得分 🫡
摘要:
強大的視覺語言模型 (Vision-Language Models, VLMs) 的崛起,正在徹底改變文檔智能 (Document AI) 的格局。每種模型都有其獨特的優勢,因此選擇合適的模型變得棘手。相比閉源模型,開源權重的模型在成本效率和隱私保護上更具優勢。為了幫助你快速上手,我們整理了這份指南。
在本指南中,你將瞭解到:
- 當前 OCR 模型的整體格局及其能力
- 何時需要微調模型,何時可直接使用
- 為你的場景選擇合適模型時應考慮的關鍵因素
- 如何超越傳統 OCR,探索多模態檢索與文檔問答
讀完之後,你將知道如何選擇合適的 OCR 模型、開始構建應用,並對文檔 AI 有更深入的理解。讓我們開始吧!
現代 OCR 簡介
光學字符識別 (Optical Character Recognition,簡稱 OCR) 是計算機視覺領域最早、也是持續時間最長的研究方向之一。AI 的許多早期實際應用都集中在“將印刷文字轉化為可編輯的數字文本”上。
隨着 視覺語言模型 (Vision-Language Models, VLMs) 的興起,OCR 的能力迎來了飛躍式提升。如今,許多 OCR 模型都是在現有 VLM 的基礎上進行微調得到的。但現代模型的能力已遠超傳統 OCR —— 你不僅可以識別文字,還能基於內容檢索文檔,甚至直接進行問答。
得益於更強大的視覺理解能力,這些模型能處理低質量掃描件、理解複雜元素 (如表格、圖表、圖片等) ,並將文本與視覺內容融合,以回答跨文檔的開放式問題。
模型能力
文本識別
最新的模型能夠將圖像中的文字轉錄為機器可讀格式。輸入內容可能包括:
- 手寫文字
- 各類文字體系 (如拉丁文、阿拉伯文、日文等)
- 數學公式
- 化學方程式
- 圖片、版面或頁碼標籤
OCR 模型會將這些內容轉換為機器可讀的文本,輸出格式多種多樣,比如 HTML、Markdown 等。
處理文檔中的複雜組件
除了文字,某些模型還能識別:
- 圖片
- 圖表
- 表格
部分模型能識別文檔中圖片的精確位置,提取其座標,並在輸出中將圖片嵌入對應位置。
另一些模型還能為圖片生成説明文字 (caption) ,並在適當位置插入。這對於後續將機器可讀輸出傳入 LLM (大型語言模型) 尤為有用。
例如, OlmOCR (AllenAI 出品) 和 PaddleOCR-VL (PaddlePaddle 出品) 就是代表。
不同模型使用不同的輸出格式,例如 DocTags、HTML、Markdown (後文輸出格式一節有詳細説明) 。
模型處理表格與圖表的方式通常取決於所採用的輸出格式:
- 有些模型將圖表當作圖片直接保留;
- 有些模型則會將其轉換為可解析的結構化格式,如 Markdown 表格或 JSON。
例如,下圖展示了一個柱狀圖如何被轉換成機器可讀的形式:

同樣地,表格中的單元格也會被解析為機器可讀格式,並保留列名與標題的上下文關係:

輸出格式
不同 OCR 模型採用的輸出格式不同,以下是幾種主流格式的簡介:
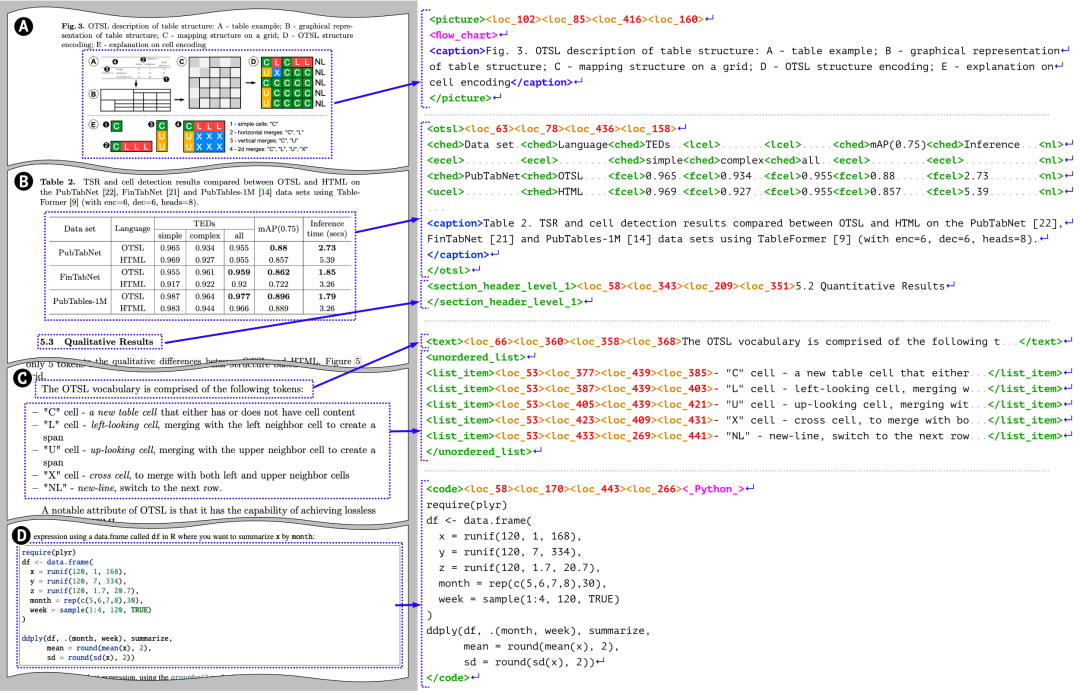
- DocTag: 一種類似 XML 的文檔標記格式,可表達位置信息、文本樣式、組件層級等。下圖展示了一篇論文如何被解析為 DocTags。該格式由開源的 Docling 模型使用。
-
HTML: 是最常見的文檔解析格式之一,能較好地表達結構與層級信息。
-
Markdown: 人類可讀性最強,格式簡潔,但表達能力有限 (如無法準確表示多列表格) 。
-
JSON: 通常用於表示表格或圖表中的結構化信息,而非完整文檔。
選擇合適的模型,取決於你對輸出結果的用途:
| 目標場景 | 推薦格式 |
|---|---|
| 數字化重建 (重現原始文檔版式) | 使用保留佈局的格式,如 DocTags 或 HTML |
| LLM 輸入或問答場景 | 使用輸出 Markdown 和圖像説明的模型 (更接近自然語言) |
| 程序化處理 (如數據分析) | 選擇能輸出結構化 JSON 的模型 |
OCR 的位置感知
文檔常常結構複雜,比如多欄文本、浮動圖片、腳註等。早期的 OCR 模型通常先識別文字,再通過後處理手動推斷頁面佈局,以恢復閲讀順序——這種方式既脆弱又易錯。
現代 OCR 模型則會在輸出中直接包含版面佈局信息 (稱為 “錨點”或 “grounding”) ,如文字的邊界框 (bounding box) 。
這種“錨定”機制能有效保持閲讀順序與語義連貫性,同時減少“幻覺式識別” (即錯誤生成內容) 。
模型提示
OCR 模型通常接收圖像輸入,並可選地接受文字提示 (prompt) ,這取決於模型的架構與預訓練方式。
部分模型支持基於提示的任務切換,例如 granite-docling 可以通過不同提示詞執行不同任務:
- 輸入 “Convert this page to Docling” → 將整頁轉換為 DocTags;
- 輸入 “Convert this formula to LaTeX” → 將頁面中的公式轉換為 LaTeX。
而另一些模型則只能處理整頁內容,任務由系統提示固定定義。
例如,OlmOCR (AllenAI) 使用一個長系統提示詞進行推理。OlmOCR 本質上是基於 Qwen2.5VL 微調的 OCR 模型,雖然它也能處理其他任務,但在 OCR 場景之外性能會明顯下降。
前沿開源 OCR 模型
過去一年,我們見證了 OCR 模型領域的爆發式創新。由於開源生態的推動,不同團隊之間可以相互借鑑、迭代,從而加速了技術進步。一個典型例子是 AllenAI 發佈的 OlmOCR,它不僅開源了模型本身,還公開了訓練所用的數據集,為他人提供了可復現與可擴展的基礎。
這個領域正以前所未有的速度發展,但如何選擇最合適的模型,仍然是一個不小的挑戰。
最新模型對比
為了幫助大家更清晰地瞭解當前格局,以下是一些當前主流開源 OCR 模型的非完整對比。
這些模型都具備版面理解能力 (layout-aware) ,能解析表格、圖表與數學公式。
各模型支持的語言範圍可在其 model card 中查看。除 Chandra (OpenRAIL 許可) 與 Nanonets (許可證不明) 外,其餘均為開源許可。
表格中展示的平均得分來自 Chandra 與 OlmOCR 模型卡中在 OlmOCR Benchmark (僅英文) 上的測試結果。
此外,許多模型基於 Qwen2.5-VL 或 Qwen3-VL 微調,因此我們也附上了 Qwen3-VL 作為參考。
| 模型名稱 | 輸出格式 | 特性 | 模型大小 | 是否多語言 | OlmOCR 基準平均得分 |
|---|---|---|---|---|---|
| Nanonets-OCR2-3B | 結構化 Markdown (含語義標註、HTML 表格等) | 圖片自動生成説明
可提取簽名與水印 識別複選框、流程圖、手寫體 |
4B | ✅ 英語、中文、法語、阿拉伯語等 | N/A |
| PaddleOCR-VL | Markdown、JSON、HTML 表格與圖表 | 支持手寫體與舊文檔
支持提示詞輸入 可將表格與圖表轉換為 HTML 可直接提取並插入圖片 |
0.9B | ✅ 支持 109 種語言 | N/A |
| dots.ocr | Markdown、JSON | 支持 grounding
可提取並插入圖片 支持手寫體 |
3B | ✅ 多語言 (具體未説明) | 79.1 ± 1.0 |
| OlmOCR-2 | Markdown、HTML、LaTeX | 具備 grounding 能力
優化了大規模批處理性能 |
8B | ❎ 僅英語 | 82.3 ± 1.1 |
| Granite-Docling-258M | DocTags | 支持基於提示的任務切換
可指定元素位置 輸出內容豐富 |
258M | ✅ 英語、日語、阿拉伯語、中文 | N/A |
| DeepSeek-OCR | Markdown、HTML | 支持通用視覺理解
能將圖表、表格完整渲染為 HTML 識別手寫體 內存高效,圖像文字識別能力強 |
3B | ✅ 近 100 種語言 | 75.4 ± 1.0 |
| Chandra | Markdown、HTML、JSON | 具備 grounding 能力
能原樣提取並插入圖片 |
9B | ✅ 支持 40+ 種語言 | 83.1 ± 0.9 |
| Qwen3-VL | 任意格式輸出 (多模態語言模型) | 識別古文文本
支持手寫體 圖片可原樣提取插入 |
9B | ✅ 支持 32 種語言 | N/A |
注:
Qwen3-VL 是一款強大的通用視覺語言模型,支持多種文檔理解任務,但並未針對 OCR 任務進行特別優化。
其他模型多采用固定提示詞進行微調,專為 OCR 任務設計。
因此若使用 Qwen3-VL,建議嘗試不同提示詞以獲得更佳效果。
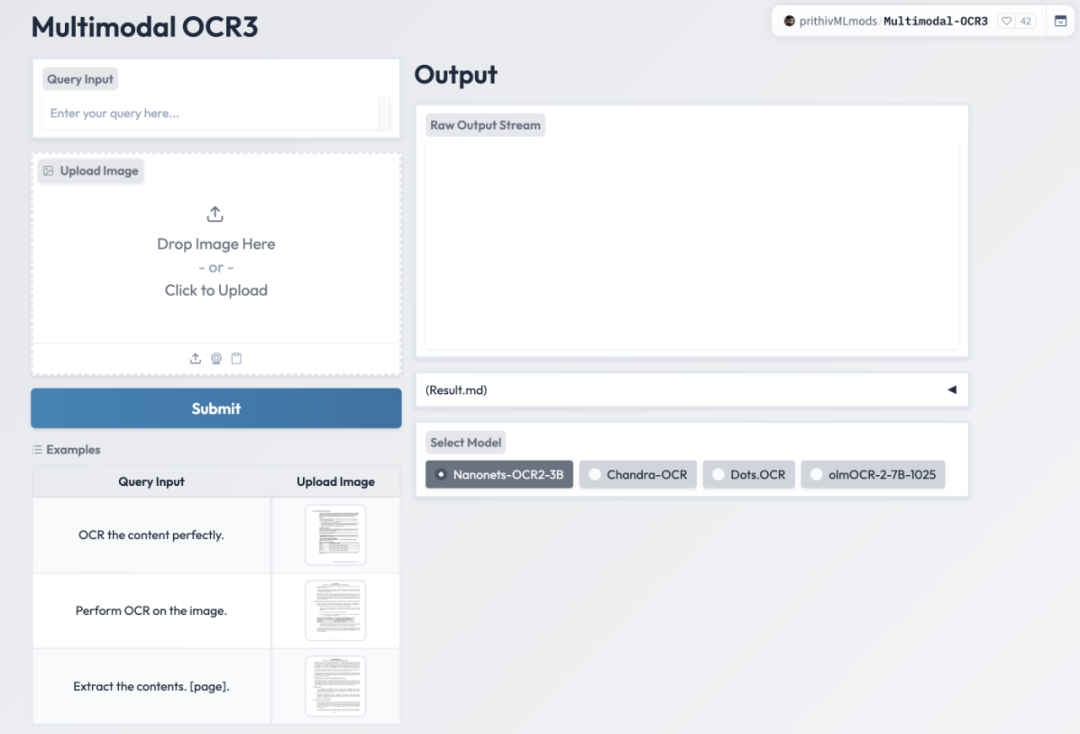
你可以通過這個 在線演示 體驗部分最新模型並比較輸出效果:
模型評估
基準測試
沒有任何一款模型能在所有場景中都是“最優”。
例如: 表格應以 Markdown 還是 HTML 呈現?哪些元素需要提取?如何量化文本識別準確度?👀
這些都取決於具體任務。
目前已有多個公開評測集與工具,但仍無法覆蓋所有情況。
我們推薦以下常用的評測基準:
- OmniDocBenchmark
- 這是目前使用最廣泛的文檔識別基準之一。
- 覆蓋文檔類型豐富: 書籍、雜誌、教材等。
- 支持多格式 (HTML 與 Markdown) 表格評測。
- 使用新型算法評估閲讀順序;公式會在評估前標準化。
- 指標基於“編輯距離”或“樹編輯距離” (表格部分) 。
- 標註數據部分由 SoTA VLM 或傳統 OCR 生成。
- OlmOCR-Bench
- 採用“單元測試式”評估方式。
- 例如: 表格評估通過驗證單元格間關係完成。
- 數據源為公開 PDF,標註來自多種閉源 VLM。
- 特別適合評估英文 OCR 模型。
- CC-OCR (Multilingual)
- 與前兩者相比,CC-OCR 的文檔質量與多樣性較低。
- 但它是唯一涵蓋英語與中文以外語言的多語言評測集。
- 圖片多為低質量拍攝,文本較少。
- 儘管不完美,但目前仍是最佳的多語言評估選項。
在不同文檔類型、語言與任務場景下,模型表現差異明顯。
如果你的業務領域不在現有評測集中體現,我們建議收集代表性樣本,構建自定義測試集,比較不同模型在你的特定任務上的效果。
成本與效率
大多數 OCR 模型的規模在 3B~7B 參數之間,也有一些小型模型 (如 PaddleOCR-VL 僅 0.9B) 。
成本不僅與模型大小相關,還取決於是否支持高效推理框架。
例如:
- OlmOCR-2 提供 vLLM 與 SGLang 實現。
- 若在 H100 GPU ($2.69/小時) 上運行,推理成本約為 每百萬頁 $178。
- DeepSeek-OCR 能在一塊 40GB A100 上每天處理 20 萬頁以上。
- 以此估算,其成本與 OlmOCR 大致相當 (視 GPU 供應商而定) 。
若任務對精度要求不高,還可選擇 量化版本 (Quantized Models) ,進一步降低成本。
總體而言,開源模型在大規模部署時幾乎總比閉源方案更經濟。
開源 OCR 數據集
儘管近年來開源 OCR 模型大量涌現,但公開的訓練與評測數據集仍相對稀缺。
一個例外是 AllenAI 的 olmOCR-mix-0225,
截至目前,該數據集已被用於訓練至少 72 個模型 (可能更多) 。
更廣泛的數據共享將極大推動開源 OCR 的進步。
以下是幾種常見的數據集構建方式:
- 合成數據生成 (Synthetic Data Generation)
例如: isl_synthetic_ocr - VLM 自動轉錄,再經人工或啓發式過濾
- 利用現有 OCR 模型生成新訓練數據,以訓練更高效的領域專用模型
- 基於人工校正語料的再利用,如 英國印度醫學史數據集,其中包含大量人工修正的歷史文檔 OCR
值得注意的是,許多此類數據集已存在但尚未“訓練化” (training-ready) 。
若能系統化整理並公開,將為開源社區釋放巨大潛力。
模型運行工具
我們收到許多關於“如何開始使用 OCR 模型”的問題,因此這裏總結了幾種簡單的方式——
包括在本地運行推理,或通過 Hugging Face 進行遠程託管。
本地運行
目前大多數先進 OCR 模型都提供 vLLM 支持,並可通過 transformers 庫直接加載推理。
你可以在各模型的 Hugging Face 頁面找到具體説明。
下面我們以 vLLM 推理方式為例演示基本流程。
使用 vLLM 啓動服務
vllm serve nanonets/Nanonets-OCR2-3B
然後,你可以通過 OpenAI SDK 進行調用,例如:
from openai import OpenAI
import base64
client = OpenAI(base_url="http://localhost:8000/v1")
model = "nanonets/Nanonets-OCR2-3B"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def infer(img_base64):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_base64}"},
},
{
"type": "text",
"text": "Extract the text from the above document as if you were reading it naturally.",
},
],
}
],
temperature=0.0,
max_tokens=15000
)
return response.choices[0].message.content
img_base64 = encode_image(your_img_path)
print(infer(img_base64))
使用 Transformers 運行推理
Transformers 庫提供了標準化的模型定義與接口,可輕鬆進行推理或微調。
模型可能有兩種加載方式:
- 官方實現 (在 transformers 內定義)
- remote code 實現 (由模型作者定義,允許 transformers 自動加載)
以下示例展示瞭如何用 transformers 調用 Nanonets OCR 模型:
# 安裝依賴: flash-attn 和 transformers
from transformers import AutoProcessor, AutoModelForImageTextToText
model = AutoModelForImageTextToText.from_pretrained(
"nanonets/Nanonets-OCR2-3B",
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2"
)
model.eval()
processor = AutoProcessor.from_pretrained("nanonets/Nanonets-OCR2-3B")
def infer(image_url, model, processor, max_new_tokens=4096):
prompt = """Extract the text from the above document as if you were reading it naturally. Return the tables in html format. Return the equations in LaTeX representation. If there is an image in the document and image caption is not present, add a small description of the image inside the <img></img> tag; otherwise, add the image caption inside <img></img>. Watermarks should be wrapped in brackets. Ex: <watermark>OFFICIAL COPY</watermark>. Page numbers should be wrapped in brackets. Ex: <page_number>14</page_number> or <page_number>9/22</page_number>. Prefer using ☐ and ☑ for check boxes."""
image = Image.open(image_path)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image", "image": image_url},
{"type": "text", "text": prompt},
]},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(text=[text], images=[image], padding=True, return_tensors="pt").to(model.device)
output_ids = model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return output_text[0]
result = infer(image_path, model, processor, max_new_tokens=15000)
print(result)
使用 MLX (適用於 Apple 芯片)
MLX 是蘋果推出的機器學習框架,專為 Apple Silicon (M 系列) 設計。
在此基礎上構建的 MLX-VLM 能輕鬆運行視覺語言模型。
你可以在 Hugging Face 搜索所有支持 MLX 的 OCR 模型 (包括量化版本) 。
安裝 MLX-VLM:
pip install -U mlx-vlm
示例運行:
wget https://huggingface.co/datasets/merve/vlm_test_images/resolve/main/throughput_smolvlm.png
python -m mlx_vlm.generate \
--model ibm-granite/granite-docling-258M-mlx \
--max-tokens 4096 \
--temperature 0.0 \
--prompt "Convert this chart to JSON." \
--image throughput_smolvlm.png
遠程運行
使用 Inference Endpoints 部署模型 (託管推理服務)
你可以通過 Hugging Face Inference Endpoints 在託管環境中部署兼容 vLLM 或 SGLang 的 OCR 模型。
該服務提供 GPU 加速、自動伸縮、監控與安全託管,無需自行維護基礎設施。
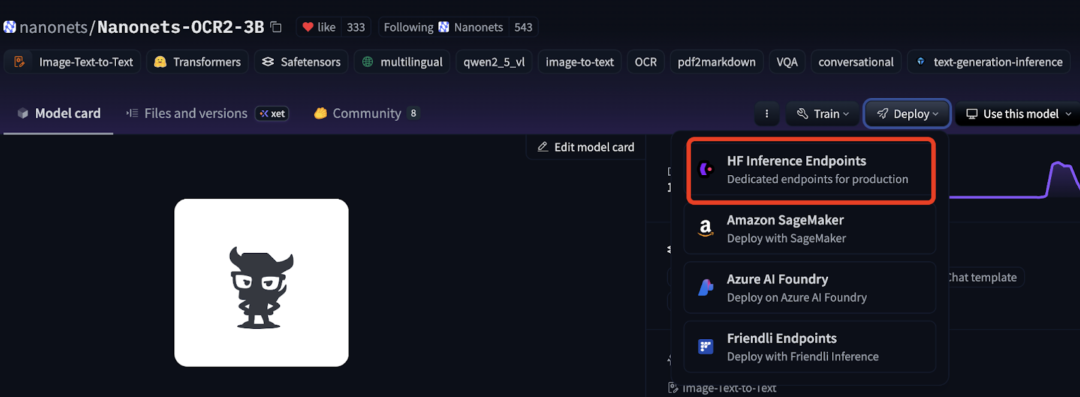
部署步驟如下:
-
進入模型倉庫 nanonets/Nanonets-OCR2-3B
-
點擊頁面上的 “Deploy” 按鈕,選擇 “HF Inference Endpoints”
- 在彈出的窗口中配置部署參數 (GPU 類型、實例數量等)
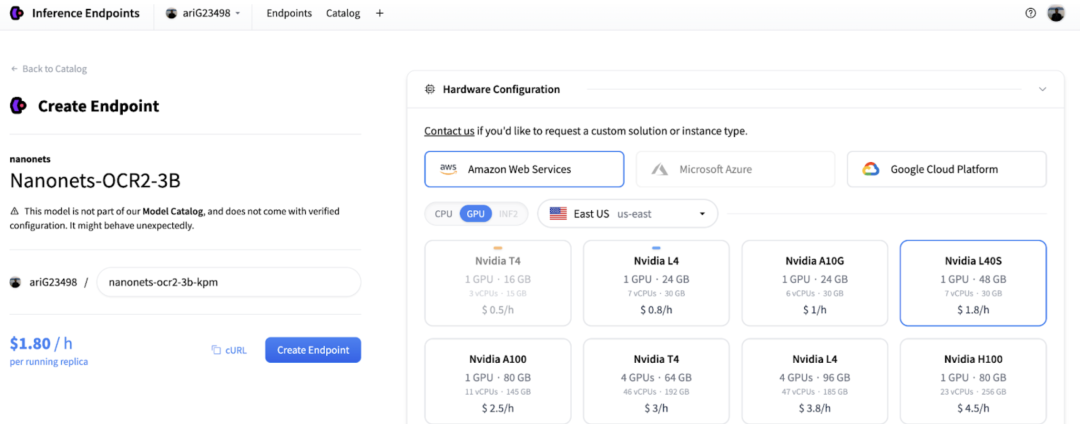
- 部署完成後,你可以直接通過上文示例中的 OpenAI 客户端腳本調用該 Endpoint。
更多信息可參閲官方文檔: 👉 Inference Endpoints (vLLM)
使用 Hugging Face Jobs 進行批量推理
對於 OCR 場景,往往需要批量處理成千上萬張圖像。
這類任務可通過 vLLM 的離線推理模式 實現高效並行。
為了簡化流程,我們創建了 uv-scripts/ocr,
它是一組適配 Hugging Face Jobs 的可直接運行腳本,能實現:
- 對數據集列中的所有圖片進行批量 OCR
- 將 OCR 結果以 Markdown 形式新增為新列
- 自動將帶結果的數據集回傳到 Hub
例如,處理 100 張圖片的命令如下:
hf jobs uv run --flavor l4x1 \
https://huggingface.co/datasets/uv-scripts/ocr/raw/main/nanonets-ocr.py \
your-input-dataset your-output-dataset \
--max-samples 100
這些腳本會自動處理所有 vLLM 配置與批次推理邏輯,
讓批量 OCR 變得無需 GPU 或複雜部署。
超越 OCR
如果你對文檔智能 (Document AI) 感興趣,不僅僅侷限於文字識別 (OCR) ,以下是我們的一些推薦方向。
視覺文檔檢索
視覺文檔檢索 (Visual Document Retrieval) 指的是:
當你輸入一條文本查詢時,系統能夠從大量 PDF 文檔中直接檢索出最相關的前 k 篇。
與傳統文本檢索模型不同,視覺文檔檢索器直接在“文檔圖像”層面進行搜索。
除了獨立使用外,你還可以將它與視覺語言模型結合,構建 多模態 RAG (Retrieval-Augmented Generation) 管線。
相關示例可參考: ColPali + Qwen2_VL 多模態 RAG 教程。
你可以在 Hugging Face Hub 找到所有可用的視覺文檔檢索模型。
目前主流的視覺檢索器分為兩類:
| 類型 | 特點 | 適用場景 |
|---|---|---|
| 單向量模型 (Single-vector Models) | 內存效率高、速度快,但性能略弱 | 輕量化部署、大規模索引 |
| 多向量模型 (Multi-vector Models) | 表徵能力強、檢索精度高,但佔用顯存更大 | 高精度檢索、知識密集任務 |
大多數此類模型都支持 vLLM 和 transformers,因此你可以很方便地用它們進行向量索引,然後結合向量數據庫 (vector DB) 執行高效搜索。
基於視覺語言模型的文檔問答 (Document Question Answering)
如果你的任務目標是基於文檔回答問題 (而不是僅僅提取文字) ,
你可以直接使用經過文檔任務訓練的視覺語言模型 (VLM) 。
許多用户習慣於:
- 先將文檔轉換成純文本;
- 再把文本傳入 LLM 進行問答。
這種方式雖然可行,但存在明顯缺陷:
- 一旦文檔佈局複雜 (如多欄結構、圖表、圖片説明等) ,轉換後的文本就可能丟失關鍵信息;
- 圖表被轉為 HTML、圖片説明生成錯誤時,LLM 就會誤判或忽略內容。
因此,更好的做法是:
直接將原始文檔圖像 + 用户問題 一起輸入支持多模態理解的模型,
例如 Qwen3-VL。
這樣模型就能同時利用視覺與文本信息,不會錯過任何上下文細節。
總結
在這篇文章中,我們為你概覽了現代 OCR 技術的核心要點,包括:
- 如何選擇合適的 OCR 模型
- 當前最前沿的開源模型及其能力
- 在本地或雲端運行模型的工具
- 以及如何在 OCR 之上構建更復雜的文檔智能應用
如果你希望進一步深入瞭解 OCR 與視覺語言模型 (VLM) ,
以下是我們推薦的延伸閲讀與教程資源 👇
延伸閲讀與資源
-
📘 Vision Language Models Explained (視覺語言模型詳解)
—— 深入理解 VLM 的工作原理與發展歷程。 -
🧠 Vision Language Models 2025 Update (2025 年視覺語言模型更新)
—— 最新 VLM 技術進展總結。 -
🔍 PP-OCR-v5 技術博客
—— 來自百度的高性能 OCR 系統優化介紹。 -
🧩 教程: 微調 Kosmos2.5 進行 Grounded OCR
—— 實踐指南,教你如何讓模型具備“錨定式”識別能力。 -
📄 教程: 在 DocVQA 數據集上微調 Florence-2
—— 基於視覺問答任務的微調實例。 -
📱 在設備端實現 SOTA OCR (Core ML + dots.ocr)
—— 展示如何在移動端高效部署 OCR 模型。
總結一句話: 開源視覺語言模型正在重新定義 OCR 的邊界。從純文本識別到多模態理解、從圖像到語義、從離線推理到大規模部署——如今的開源生態為每一個開發者和研究者提供了前所未有的自由度與創新空間。
無論你是在構建下一代文檔智能系統,還是僅想更高效地解析 PDF,希望這篇指南能幫助你找到最合適的起點 🚀
英文原文: https://huggingface.co/blog/ocr-open-models
原文作者: merve, Aritra Roy Gosthipaty, Daniel van Strien, Hynek Kydlicek, Andres Marafioti, Vaibhav Srivastav, Pedro Cuenca
譯者: Luke, Hugging Face Fellow