

索引概念
索引是 MySQL 中用於加速數據查詢的核心數據結構,本質是對錶中一列或多列數據進行排序後的 “快速查找目錄”。通過索引,MySQL 無需全表掃描即可快速定位目標數據,大幅提升查詢效率;但索引會佔用額外存儲空間,且會降低插入 / 更新 / 刪除(寫操作)的性能(需同步維護索引結構),因此需合理設計與使用。
索引的核心作用
核心價值:加速查詢
-
無索引時:MySQL 需執行「全表掃描」(逐行遍歷表中所有數據),數據量越大,查詢越慢;
-
有索引時:通過索引結構(如 B+Tree)快速定位數據所在的物理位置,查詢時間與數據量規模解耦(類似查字典時先查目錄,而非逐頁翻找)。
輔助作用
-
保證數據唯一性:如主鍵索引(PRIMARY KEY)、唯一索引(UNIQUE)可強制列值不重複;
-
優化排序 / 分組:若查詢的 ORDER BY/GROUP BY 子句與索引列一致,MySQL 可直接利用索引的有序性避免額外排序(即 “Using index for 排序” 優化)。
索引的底層數據結構
MySQL 絕大多數索引(主鍵、唯一、普通、聯合索引)均基於 B+Tree 實現(InnoDB 引擎默認使用聚簇 B+Tree,MyISAM 用非聚簇 B+Tree),其結構設計專為數據庫優化:
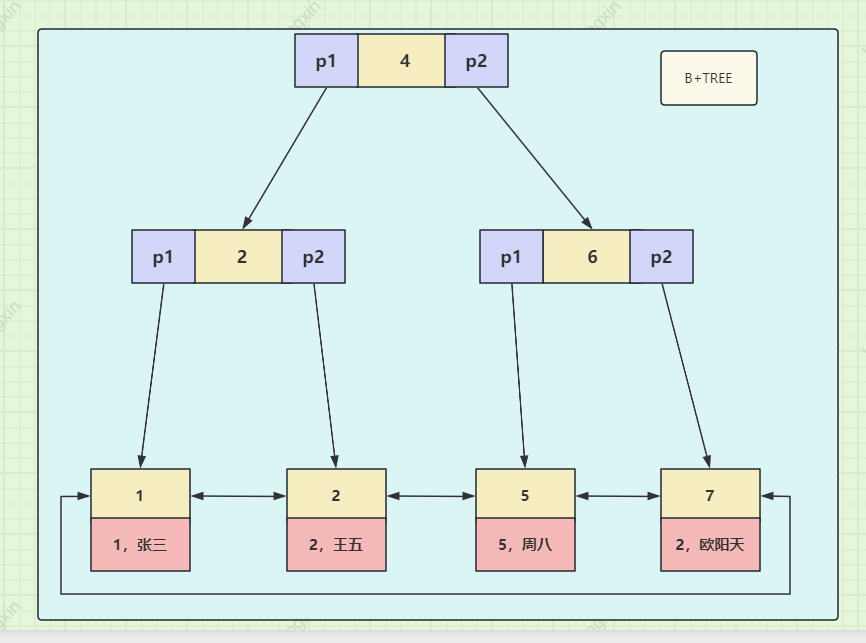
-
B+TREE索引是自平衡二叉樹的升級版,B+TREE索引將數據存儲在葉子節點,並且葉子節點之間採用雙向鏈表互相連接,這樣很適合範圍查詢,且葉子節點是排好序的。所以我們MySQL數據庫是默認根據主鍵索引升序排序的
-
B+TREE的非葉子節點只有索引值和指針,沒有數據,所以非葉子節點可以存儲更多的索引值,這樣可以使B+TREE更矮更胖,減少檢索的深度(也就是減少磁盤IO),提高檢索效率。
聚簇索引 vs 非聚簇索引(InnoDB 核心區別):
- 聚簇索引(主鍵索引):葉子節點直接存儲整行數據,InnoDB 表必須有聚簇索引(默認主鍵,無主鍵則選唯一非空列,否則自動生成隱藏主鍵);
- 非聚簇索引(二級索引,如普通索引、唯一索引):葉子節點存儲主鍵值,查詢時需先通過二級索引找到主鍵,再回表查聚簇索引獲取整行數據(即 “回表查詢”)。
MySQL索引分類
主鍵索引(PRIMARY KEY)
作用:用來組織存儲表的數據行信息的,也可以理解為數據行信息都是按照聚簇索引結構進行存儲的,即按區分配空間的;
特點:索引列數據唯一且非空,一張表只能有一個主鍵索引;
創建方式
- 方式一:創建數據表時,顯示的創建主鍵索引
CREATE TABLE user (
id INT PRIMARY KEY, -- 主鍵索引
name VARCHAR(20)
);
- 方式二:創建完表之後添加索引
alter table 表名 ADD PRIMARY KEY (id);
- 方式三:沒有顯示的構建主鍵索引時,會將第一個不為空的unique約束作為主鍵索引
- 方式四:以上條件都不符合時,會生成一個6字節的隱藏列作為主鍵索引
唯一索引(UNIQUE)
作用:保證數據唯一性(如手機號、郵箱),同時加速查詢;
特性:索引列的值必須唯一,但允許有空值
創建方式
- 方式一:創建表時指定
CREATE TABLE user (
id INT PRIMARY KEY,
phone VARCHAR(11) UNIQUE -- 唯一索引
);
- 方式二:創建完表之後指定
ALTER TABLE 表名 ADD UNIQUE 索引名稱 on (name) ;
普通索引(INDEX)
作用:純粹加速查詢,是最常用的索引類型;
特性:無唯一性約束,允許重複值和 NULL;
創建方式
- 方式一:創建表時指定
create table 表名 (id int,name char(10),index 索引名稱(name));
create table 表名 (id int,name char(10),index 索引名稱(name(5))); -- 設置前綴
create table 表名 (id int,name char(10),age char(5),index xiaoA(name desc)); -- 設置索引排序方式,默認升序
- 方式二:創建完表後指定
alter table 表名 add index 索引名稱(name);
alter table 表名 add index 索引名稱(name(length)); -- 設置前綴
alter table 表名 add index 索引名稱(name desc) ; -- 調整排序方式
聯合索引
核心特性:基於多列組合創建的索引(如 (col1, col2, col3));
作用:優化多列聯合查詢(如 WHERE a=? AND b=?),比單列索引更高效;
聯合索引命中規則
最左前綴匹配原則—— 查詢時必須從索引的第一列開始匹配,否則無法命中索引!!!
例如聯合索引 (a, b, c):
命中索引:WHERE a=1、WHERE a=1 AND b=2、WHERE a=1 AND b=2 AND c=3;
未命中索引:WHERE b=2、WHERE a=1 AND c=3(跳過 b 列);
創建方式
- 方式一:創建表時指定
create table 表名 (id int,name char(10),age char(5),index 索引名稱(name,age));
- 方式二:創建完表後指定
alter table 表名 add index 索引名稱(name,age);
索引的優缺點
優點
-
提高查詢性能:通過創建索引,可以大大減少數據庫查詢的數據量,從而提高查詢的速度
-
加速排序,當查詢需要按照某個字段進行排序時,索引可以加速排序的過程,提高排序的效率
-
減少磁盤的IO,索引可以減少磁盤IO的次數,這對於磁盤讀寫速度較低的場景,尤其重要
缺點
-
佔據額外的存儲空間,索引需要佔據額外的存儲空間,特別是在大型數據庫系統中,索引可能佔據較大的空間
-
增刪改的操作會導致索引更新,會導致操作的性能降低
-
資源消耗較大,索引需要佔用額外的內存和cpu資源,特別是在大規模併發訪問的情況下,可能對系統的性能產生影響
什麼時候建議使用索引?
- 頻繁執行查詢操作的字段:如果這些字段經常被查詢,使用索引可以提高查詢的性能,減少查詢的時間。
- 大表:當表的數據量較大時,使用索引可以快速定位到所需的數據,提高查詢效率。
- 需要排序或者分組的字段:在對字段進行排序或者分組操作時,索引可以減少排序或者分組的時間。
- 外鍵關聯的字段:在進行表之間的關聯查詢時,使用索引可以加快關聯查詢的速度。
什麼時候不建議使用索引
- 頻繁執行更新操作的表:如果表經常被更新數據,使用索引可能會降低更新操作的性能,因為每次更新都需要維護索引。
- 小表:對於數據量較小的表,使用索引可能並不會帶來明顯的性能提升,反而會佔用額外的存儲空間。
- 對於唯一性很差的字段,一般不建議添加索引。當一個字段的唯一性很差時,查詢操作基本上需要掃描整個表的大部分數據。如果為這樣的字段創建索引,索引的大小可能會比數據本身還大,導致索引的存儲空間佔用過高,同時也會導致查詢操作的性能下降。