

一、PTQ 模型量化問題
1.1、模型問題
基於公版模型訓練,沒有對模型做範圍做約束,weight\_decay=1e-6, 訓練出的 float 模型數值分佈很大,如圖 2,可以看到模型的後面幾層數據分佈範圍很廣,最大閾值超過了 8000,對我們量化來説並不友好。
1.2、算子問題
如圖 2,基於全 int16 算子配置量化,當前版本 resize 算子有約束(請查閲工具鏈算子支持情況),只能支持 int8 量化,即使配置了 int16,但算子依舊退化到 int8,因此算子的 cosine 相似度也比較低,基於此閾值,max\_qscale=6653/127=52.385,此 scale 過於大,並不能精細化量化模型,所以全 BPU 算子的整體精度都不高。
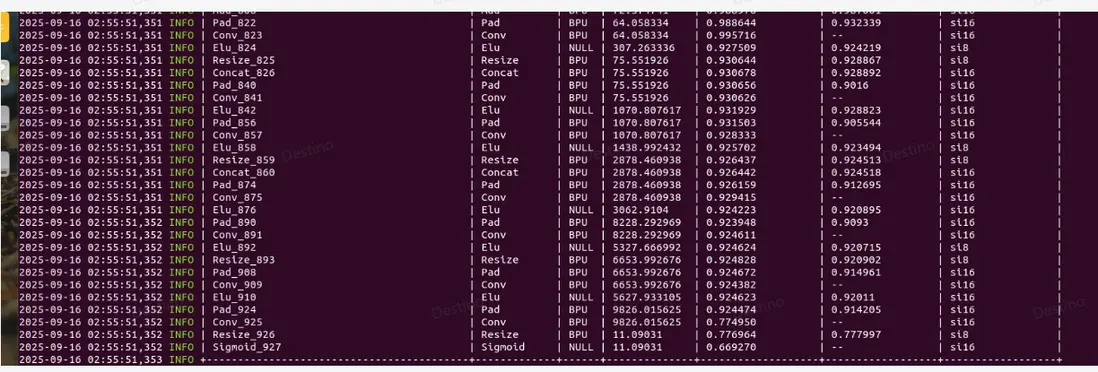
圖 1 公版訓練 float 模型
二、精度優化
2.1、cpu 高精度定位
resize 算子有限制,但對於回退 cpu 算子,就能實現 float 精度推理,配置如圖 2,
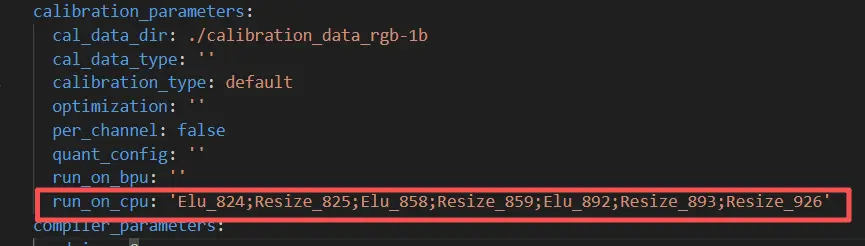
圖 2 配置 cpu 算子
配置了算子後,精度提升了,如圖 3,可視化效果對比如圖 4,整體量化精度可對齊,定位到了具體問題就是 resize 算子限制導致。
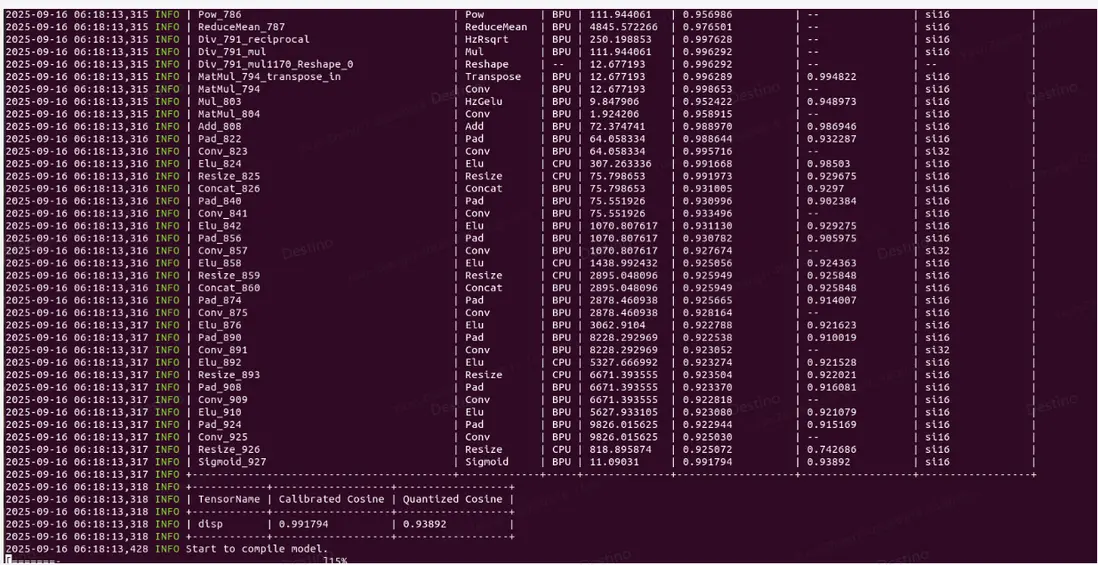
圖 3 cpu 算子精度

圖 4 cpu 算子可視化精度
2.2、添加 bn,加大 weight\_decay
在最後的 conv 層後加上 bn 算子限制特徵數據分佈,同時 weight\_decay 從 1e-6 調整到 1e-3,整體數據範圍如圖 5、圖 6,模型的數據分佈變小了,最後的 cosine 相似度精度也很高,非常利於 int8 量化,後期配置了 int8 量化,模型也可實現高精度量化。
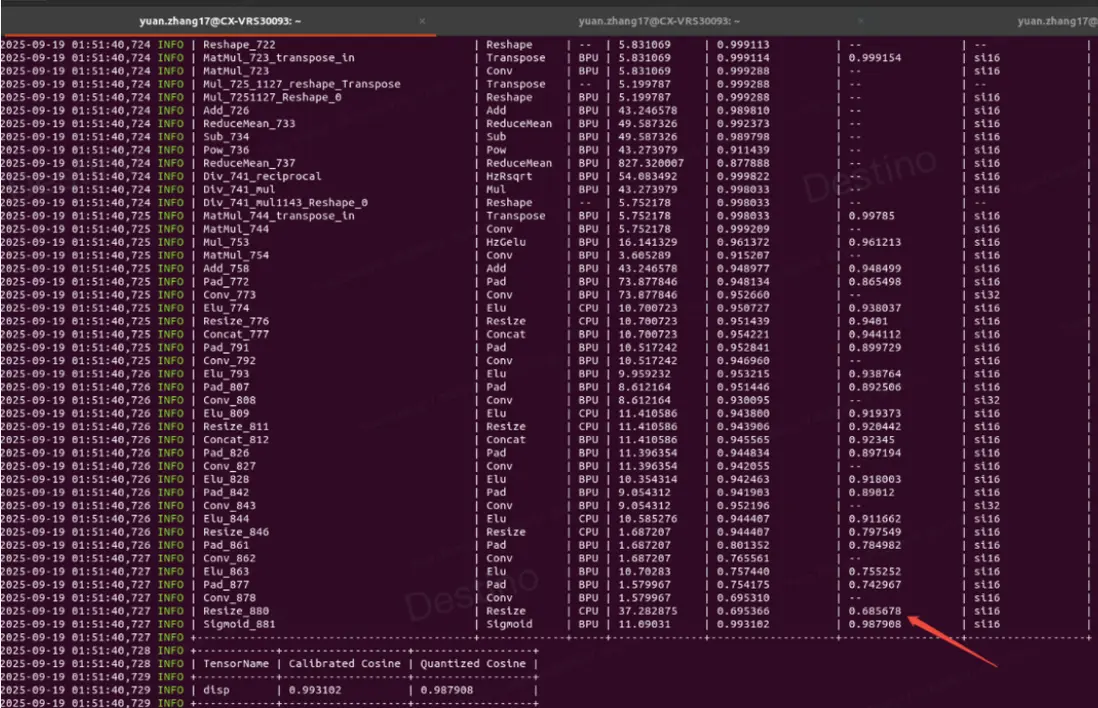
圖 5 全 int16 量化
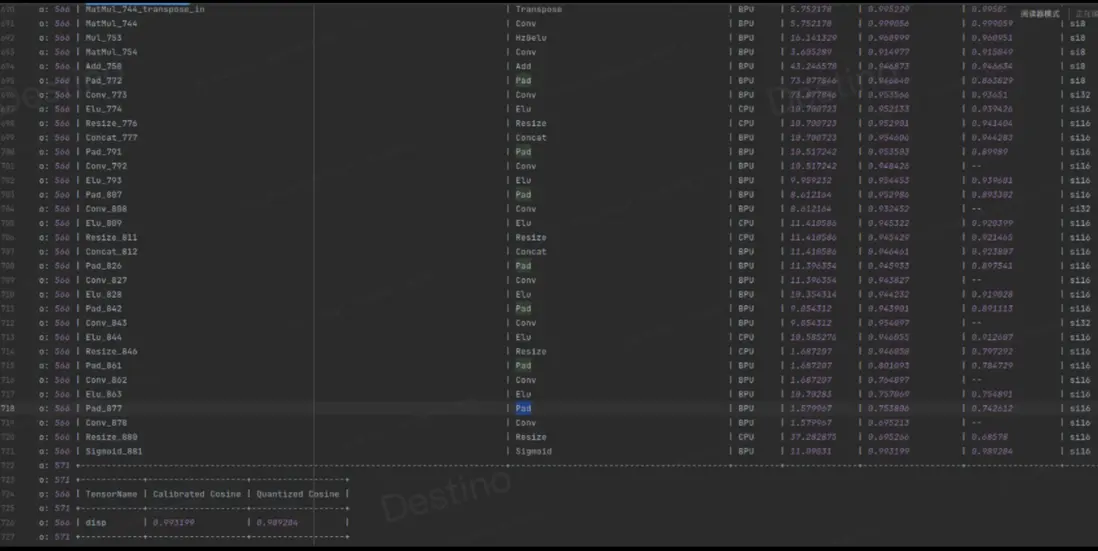
圖 6 部分 int16 量化