

1.前言
本文旨在提供 征程 6H/P 計算平台的部署指南,將會從硬件、軟件兩部分進行介紹,本文整理了我們推薦的使用流程,和大家可能會用到的一些工具特性,以便於您更好地理解工具鏈。某個工具具體詳 l 細的使用説明,還請參考用户手冊。
2.征程 6H/P 硬件配置
2.1 BPU®Nash
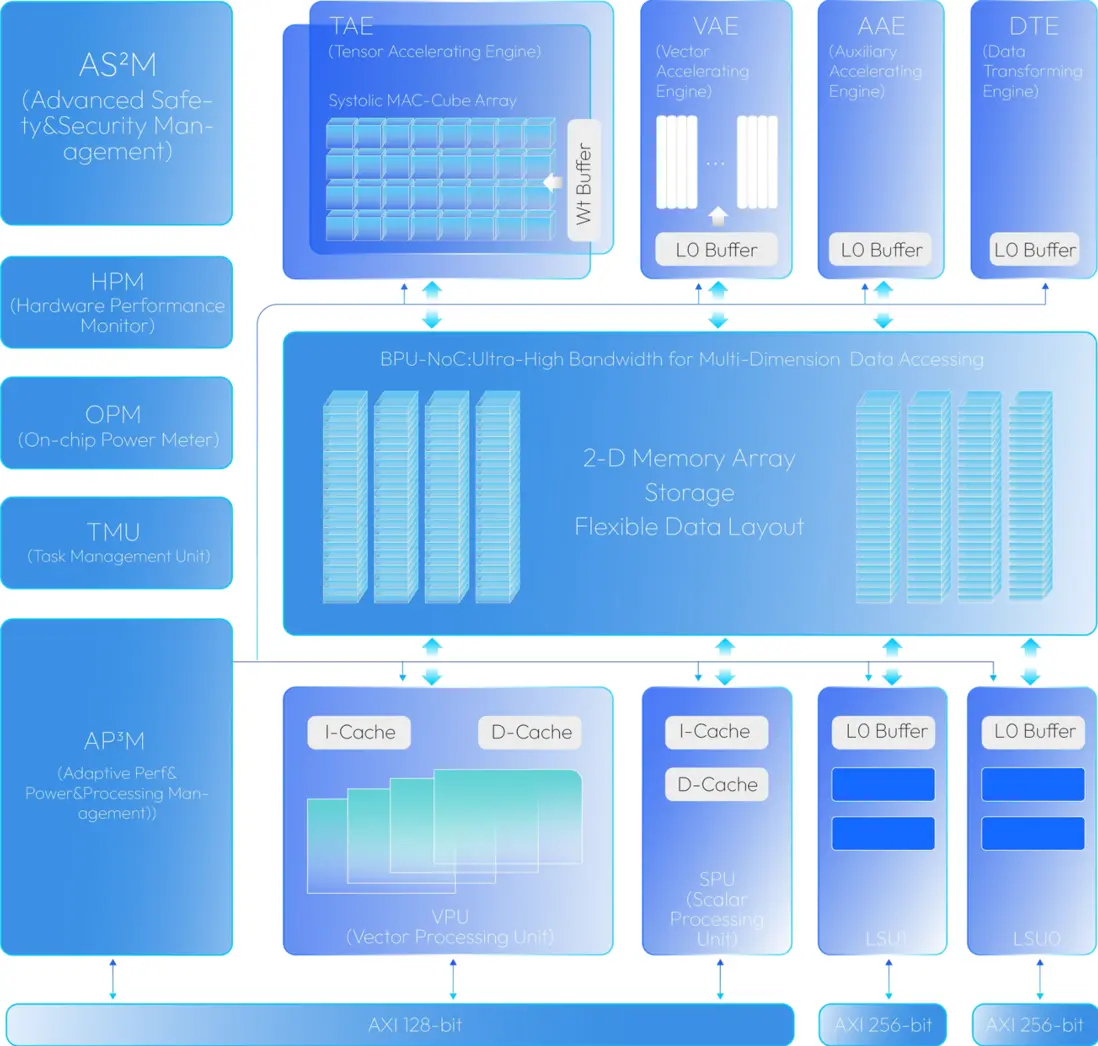
2.2 硬件規格
| BPU | DSP | ||||||
|---|---|---|---|---|---|---|---|
| | 算力 | TAE 浮點輸出 | VAE 浮點 | VPU | SPU | APM | |
| 征程 6E | 80T | N | N | Y | Y | Y | Q8*1 |
| 征程 6M | 128T | N | N | Y | Y | Y | Q8*1 |
| 征程 6P | 560T | Y | Y | Y | Y | Y | Q8*2 |
| 征程 6H | 420T | Y | Y | Y | Y | Y | Q8*2 |
| 征程 6B-Base | 18T | Y | Y | N | N | Y | V130*1 |
BPU 內部器件:
TAE:BPU 內部的張量加速引擎,主要用於 Conv、MatMul、Linear 等 Gemm 類算子加速
VAE:BPU 內部的 SIMD 向量加速引擎,主要用於完成 vector 計算
VPU:BPU 內部的 SIMT 向量加速單元,主要用於完成 vector 計算
SPU:BPU 內部的 RISC-V 標量加速單元,主要用於實現 TopK 等算子
APM:BPU 內部另一塊 RISC-V 標量加速單元,主要用於 BPU 任務調度等功能
L1M:一級緩存,BPU 核內共享
L2M:二級緩存,BPU 核間共享
2.3 與其他征程 6 計算平台的主要區別
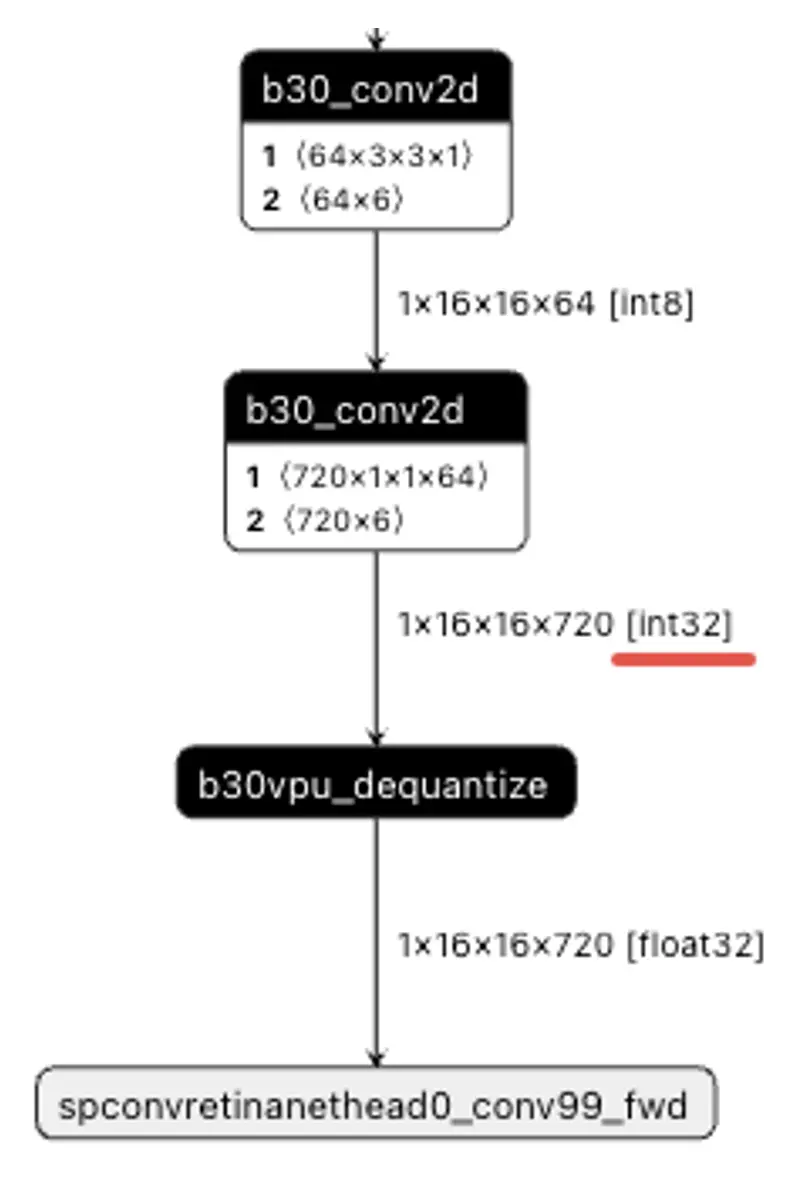
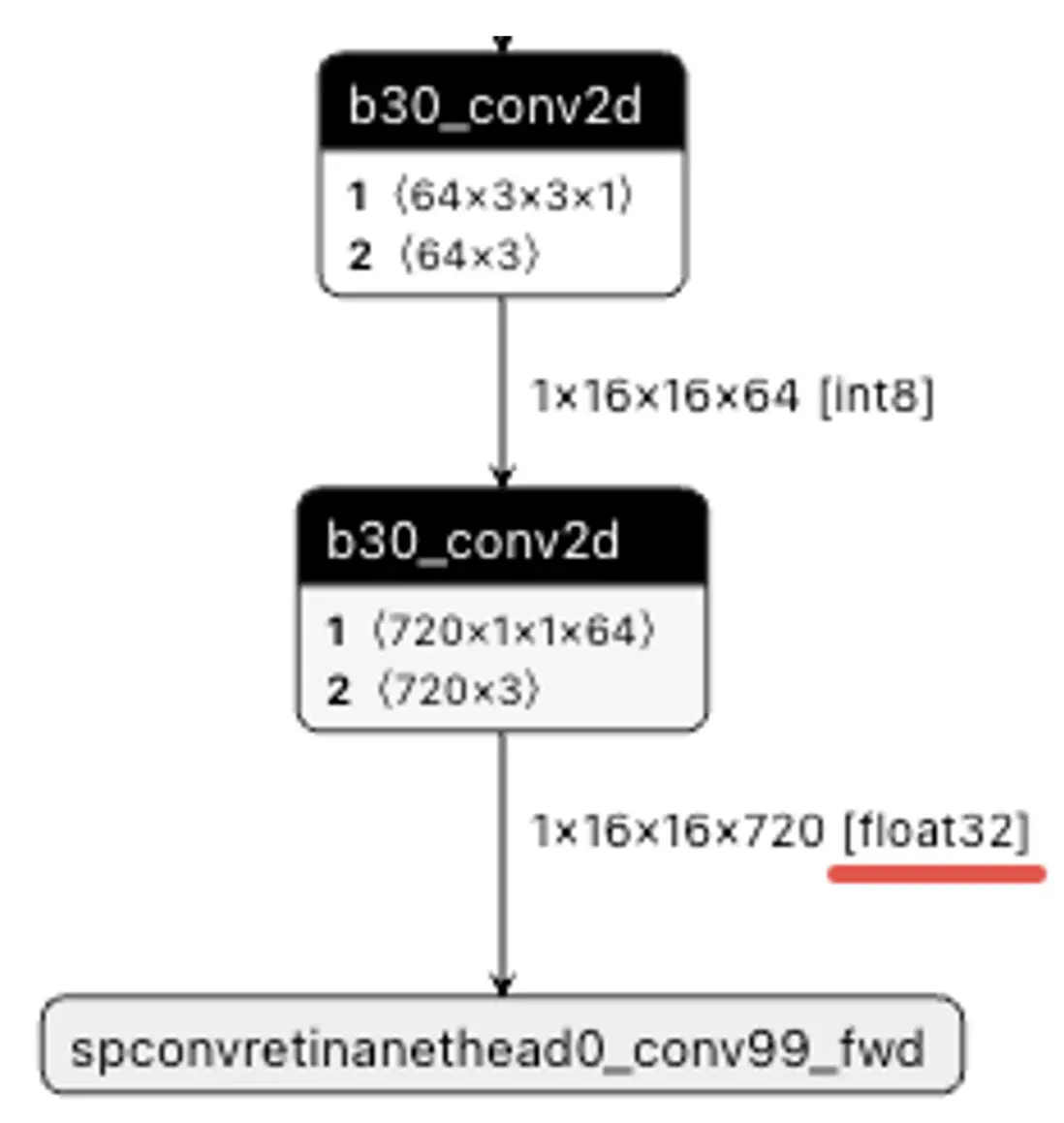
TAE:征程 6B/H/P 支持 fp16 和 fp32 輸出,而征程 6E/M 不支持浮點輸出。這使得在征程 6B/H/P 計算平台上配置模型尾部 conv 高精度輸出,輸出精度是 fp32,而在征程 6E/M 計算平台上配置模型尾部 conv 高精度輸出,輸出精度是 int32,後接一個反量化節點轉 fp32。若在征程 6E/M 計算平台上是刪除尾部反量化部署的話,遷移征程 6B/H/P 時軟件代碼需要注意適配。
征程 6E/M 尾部高精度 conv 輸出 int32:
征程 6B/H/P 尾部高精度 conv 輸出 float32:
VAE:征程 6H/P 支持 fp16
L2M:征程 6H/P 支持 L2 緩存,多 BPU 核共用,征程 6E/M/B 單核,無 L2 緩存。通過命令 cat /sys/kernel/debug/ion/heaps/custom 查看 L2M 大小。
跨距對齊要求不同:征程 6H/P 要求模型 nv12 輸入 stride 要求滿足 64 對齊;征程 6E/M/B 則是要求 32 對齊。同時模型其他輸入輸出節點的對齊要求也有可能不同。
針對 nv12 輸入,金字塔配置文件需要注意修改 stride 參數,如果征程 6E/M/B 內存夠的話,建議可直接按 64 對齊來申請,跨平台遷移時就無需更改配置。
針對其他輸入輸出 tensor,建議編譯時打開編譯參數:input_no_padding=True, output_no_padding=True。或是按推薦方式,結合 stride 和 valid\_shape 來解析有效數據,也可避免跨平台遷移適配。
最小內存單元不同:征程 6H/P tensor 最小申請內存是 256 字節,征程 6E/M 64 字節,征程 6B 128 字節。
3.新功能特性
若已有其他平台使用經驗,可只關注本章節內容,瞭解征程 6H&P 與其他征程 6 計算平台的功能點差異即可。
相較於征程 6E/M/B,征程 6H/P 最主要區別是多核,TAE/VAE/VPU 器件能力的增強以及增加了 L2M,本章節將介紹這幾點差異對於在征程 6H/P 平台上開發算法方案的影響。
3.1 多核部署
3.1.1 多核模型編譯
征程 6H/P 硬件支持單幀多核的部署方式,但是當前多核模型(特指單次模型推理同時使用了兩個及兩個以上 BPU 核心的模型)功能還在開發中,目前支持了 resnet50 雙核模型的 demo,性能數據見下表:
| 單核模型實測延時(ms) | 雙核模型實測延時(ms) | |
|---|---|---|
| Resnet50 | 9.1187 | 5.7458 |
由於 BPU 是獨佔式硬件,若運行雙核模型,則代表該模型運行期間,有兩個 bpu 會被同時佔用,無法運行其他任務;加上多核模型相較於單核能拿到的性能收益與模型結構緊密相關,很難確保理想的雙核利用率。因此出於更高的跨平台遷移效率和硬件資源利用率等因素考慮,建議按下一節建議拆分模型部署。
3.1.2 pipeline 設計
征程 6H/P 分別提供了 3 個和 4 個 BPU 計算核心,給了應用調度更靈活的設計空間,通過多核充分並行,可有效減少系統端到端延時。以下方案僅為示例,並非是標準推薦:
算法架構示意圖:
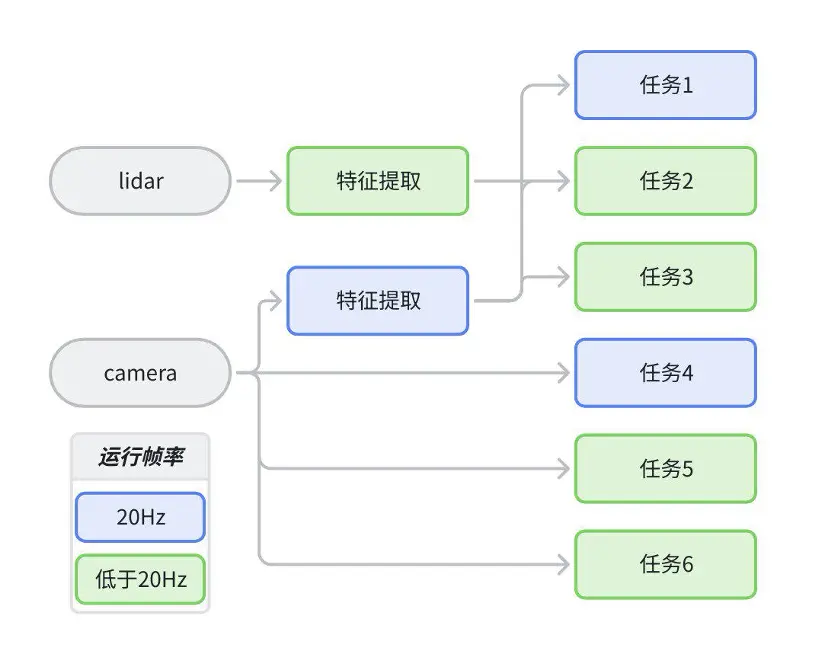
部署 pipeline 設計:

由於工具難以感知模型上下游關係,任務重要程度,不同設計幀率等信息,且多核模型利用率提升難度很大,因此建議用户手動拆分不同功能的模型以提高多核計算資源的利用率。拆分邏輯有如下建議:
- 多任務幀率不同:智駕系統中各個子任務設計幀率可能是不同的,建議拆分部署。
- 無上下游依賴:兩個沒有上下游輸入輸出數據依賴的模型,建議拆分部署,編譯在一起也是順次執行的。拆分後通過放在不同核心上部署,可以縮短整體系統的端到端延時。
- 跨團隊開發,提前做資源分配:算法功能開發團隊約定算力分配後可獨立開發優化,獨立上線測試,若編譯在一起則每次發版都會有相互依賴。
3.2 合理使用 L2M
由於征程 6H/P 算法方案相對會比征程 6E/M/B 的複雜,包括接入的攝像頭數目,模型前後處理和模型體量變大都會導致整個系統對帶寬的需求要高很多。由於帶寬爭搶,不可避免當多核同時運行時會發現模型延時相較於獨佔硬件測試時會變長。為了緩解帶寬爭搶導致模型延時變長的現象,征程 6H/P 提供了 L2M,可使部分與 DDR 交換的數據被緩存在 L2M 內。建議在大部分模型都產出 hbm 後,甚至 pipeline 大致確定之後,使用如下方式離線評估所有模型的帶寬資源使用情況,測試不同 l2 配置的帶寬收益。
3.2.1 L2M 使用説明
需要更新到 OE3.5.0 及以上)。當前僅支持以 BPU 核為粒度配置 L2 大小,暫不支持運行時實時對單模型做配置。啓用 L2M 涉及到模型編譯,以及運行時正確制定環境變量兩項工作。
開發板實際可用 l2m 大小請使用命令 :cat /sys/kernel/debug/ion/heaps/custom 進行查看。
3.2.1.1 模型編譯
編譯時通過指定參數控制模型可用的 l2 大小:
from hbdk4.compiler import load, convert, compile
compile(quantized_bc, ···, max_l2m_size=l2m*1024*1024)
# max_l2m_size單位為bytes,l2m=0及為默認配置,不啓用L2;l2m=6即為6M,l2m=12為12M。
# 詳細説明請閲讀用户手冊 - 進階內容 - HBDK Tool API Reference - compile3.2.1.2 模型推理
無需改動推理代碼,只需通過環境變量控制每個核可申請的 l2 大小(暫不支持運行時動態申請)
建議部署在相同 BPU 核上的模型,編譯時指定相同的 L2M 大小,否則需要按最大需求來配置。
export HB_DNN_USER_DEFINED_L2M_SIZES=6:6:6:6
# 每個核分配6M
export HB_DNN_USER_DEFINED_L2M_SIZES=12:0:0:12
# 核0和核3各分到12M不正確的 L2M 使用可能導致如下問題:
- 未給對應核分配足夠的 L2M 或是沒有分配 L2M
推理將會失敗,打印如下提示日誌信息:
“model [{model name}] node [{node name}] L2 memory not enough, required l2 memspace info: [{model L2M}], user-assigned l2 memspace size: [{HB_DNN_USER_DEFINED_L2M_SIZES}], user-assigned cores: [{core_id}]"
比如模型編譯時指定了 12M L2M,運行時只通過環境變量給該核分配了 6M;或是運行時忘記配置環境變量。
- 發現沒有帶寬收益,或者推理結果錯亂
老版本 ucp 也能推理帶 l2 的模型,只不過會出現推理結果不正確,並且沒有帶寬收益的問題,請從日誌裏確認 ucp 的版本已經升級到 OE3.5.0 及以上集成的版本。
3.2.2 統計並優化系統帶寬
由於目前 hbm\_perf 暫不支持 L2M(perf 看不出 l2m 的收益,預計 2025 年底的版本可支持),因此具體收益需要通過實測獲取。按照經驗,實測與預估偏差非常小(10% 以內),通過預估方式如果發現四個核帶寬佔用差不多,可以直接每個核平分 l2,如果核 0 和核 3 的帶寬佔用最為顯著,可以直接將 l2 平均分給兩個核的模型。
3.2.2.1 按實車 pipeline 設計預估平均帶寬的方式
首先使用 hbm\_perf 評測模型,從 html 或 json 中獲取帶寬信息,結合設計幀率評估模型上線後預計需要的帶寬資源:
平均帶寬(GB/s) = DDR bytes per second( for n FPS) / n * 設計幀率/2^30
以下面這個模型為例,實車設計幀率為 10FPS,則實車時該模型需要的平均帶寬為:
68138917200/10.39*10/2^30 = 61.08GB/s

3.2.2.2 按實車 pipeline 實測平均帶寬的方式
- 修改 hrt\_model\_exec 工具,支持按設計幀率 perf 模型(如何修改工具,以及帶寬數據如何分析請參考社區文章:https://developer.horizon.auto/blog/13054)
- 找一個空閒的開發板,用 hrt\_model\_exec 工具按設計幀率 perf 模型:
hrt_model_exec perf --model_file model.hbm --perf_fps 20 --frame_count 2000 --core_id 1- 使用 hrut\_ddr 獲取 bpu 佔用的平均帶寬
hrut_ddr -t bpu -p 1000000
# 統計週期拉長到1s,看平均值即可,默認-p是1000,即1ms採樣一次,瞬時帶寬受採樣影響不太準確3.3 量化配置
由於征程 6H/P 的硬件增強了浮點能力,為了降低量化難度,提高模型迭代效率,建議初始量化配置使用全局 float16,Conv 類算子回退 int8。
排除 int<->float 的量化反量化開銷,征程 6H/P 上大多數 vector 計算,int16 精度和 float16 精度計算速度相當,因此建議 vector 計算精度直接使用 float16,若基礎配置精度不達標,後續依據敏感度對 conv 類計算加 int16 即可。經實踐證明,除了部分模型有中間計算數值範圍太大超過了 fp16 表示範圍需要切換 int16 之外,fp16 能有效降低 qat 量化難度。更多關於征程 6H/P 精度調優流程的説明請參考後文 4.3.3 精度調優流程 章節。
OE3.5.0 為了支持征程 6H/P 用户更便捷高效的配置浮點精度,horizon-plugin-pytorch 對 qconfig 配置做了優化,若您使用的是舊版本的配置方式,建議參考文檔<u>【地平線 征程 6 工具鏈入門教程】QAT 新版 qconfig 量化模板使用教程</u>(https://developer.horizon.auto/blog/13112),升級使用新的模版。
3.4 部署差異
3.4.1 模型輸出精度可能不同
由於征程 6B/H/P 的 TAE 硬件支持 fp16 和 fp32 輸出而征程 6E/M 不支持,因此若模型以 GEMM 類算子結尾的話,征程 6E/M 配置高精度輸出是 int32,征程 6B/H/P 配置高精度輸出是 fp32。因此征程 6E/M 模型直接編譯到征程 6B/H/P,模型輸出類型有可能會發生改變,軟件代碼需要注意適配。
3.4.2 跨距對齊要求不同
征程 6H/P 要求 nv12 stride 滿足 64 對齊,征程 6E/M/B 是 32 對齊。且輸入輸出 tensor 的對齊規則也有可能不同。
從征程 6E/M/B 遷移征程 6H/P 需要注意金字塔配置文件的 stride 是否滿足 64 對齊,如果征程 6E/M/B 內存夠用的話,建議可直接按 64 對齊來申請,跨平台遷移時就無需更改配置。
若編譯時配置了 input_no_padding=True, output_no_padding bool=True,則無需關心對齊開銷;若編譯時沒有打開這兩個參數,則跨平台編譯模型會發現輸入輸出 tensor 的 stride 參數可能會不同,不過部署代碼是通過 stride 和 valid\_shape 信息來準備/解析數據,沒有強依賴 stride 的 hard code,則也可忽略對齊帶來的影響。
3.4.3 最小內存單元不同
征程 6H/P tensor 最小申請內存是 256 字節,征程 6E/M 64 字節,征程 6B 128 字節。這個差異會體現在模型的 aligned byte size 屬性上,對於小於最小內存單元的數據,或者不滿足最小內存單元整數倍的數據,會要求強制對齊。建議輸入輸出 tensor 內存大小按 aligned byte size 申請,不要寫 hard code,避免遷移時遇到問題。

3.4.4 綁核推理
征程 6H/P 有兩個 dsp 核,提交 dsp 任務時可以指定一下 backend
hbUCPSchedParam sched_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sched_param);
sched_param.backend = dsp_core_id == 0 ? HB_UCP_DSP_CORE_0 : HB_UCP_DSP_CORE_1;
sched_param.priority = 0;
ret = hbUCPSubmitTask(task.task_handle, &sched_param);征程 6H/P 有三/四個 bpu 核,建議所有任務做靜態編排後,運行時做綁核(不建議使用 HB\_UCP\_BPU\_CORE\_ANY,會因系統調用導致 latency 跳變),減少使用搶佔等會產生額外 ddr 開銷的功能:
hbUCPSchedParam sched_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sched_param);
sched_param.backend = HB_UCP_BPU_CORE_0;
sched_param.priority = 200;
ret = hbUCPSubmitTask(task.task_handle, &sched_param);征程 6H/P 單核內支持的搶佔策略與征程 6E/M 一致,多核已經為編排提供了足夠的靈活度,建議多核計算平台上儘量避免使用硬件搶佔,減少搶佔引入的額外帶寬消耗。
4.建議使用流程

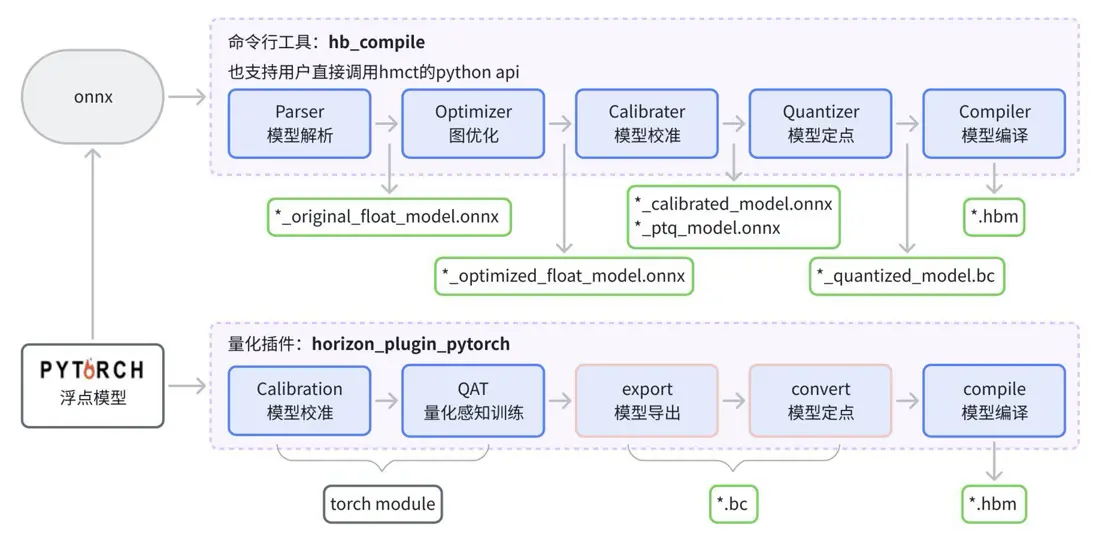
在征程 6 計算平台上,我們建議前期初步做性能評測和性能優化時使用 PTQ 工具,只需要準備浮點 onnx 即可,較易上手。後續正式做量產迭代使用 QAT 量化工具,精度更有保障,對於多階段模型,或者模型新增 head 等變化,可以更靈活複用已有 QAT 權重,有利於模型迭代更新,而 PTQ 則無法拼接歷史量化 onnx。下圖為 PTQ 和 QAT 量化產物對比:
4.1 性能評測
PTQ 環境搭建請參考用户手冊-環境部署-Docker 容器部署。
4.1.1 快速性能評測(默認全 Int8)
hb_compile --fast-perf --model xxx.onnx --march nash-p需要注意的是,fast-perf 默認會刪除模型前後的 Quantize,Transpose,Dequantize,Cast,Reshape,Softmax 算子,如果模型輸入輸出節點較多,會與實際部署性能產生 gap,建議按下面的步驟,手動修改一下 yaml 文件:
執行上面那一行命令之後會在當前路徑下生成。fast\_perf 路徑,路徑下有 yaml 文件,打開 yaml 文件按照實際部署需要,去掉無需刪除的節點,一般來説部署時只需要刪除量化反量化:

修改完成後只要模型輸入沒有變化,則後續可一直複用該 yaml 文件,修改 onnx\_model 路徑即可:
hb_compile -c xxx.yaml4.1.2 int8\_fp16 測試
{
"model_config": {
"all_node_type": "float16"
},
"op_config": {
"Conv": {
"qtype": "int8"
},
"ConvTranspose": {
"qtype": "int8"
},
"MatMul": {
"qtype": "int8"
},
"Gemm": {
"qtype": "int8"
},
"Resize": {
"qtype": "int8"
},
"GridSample": {
"qtype": "int8"
},
"GridSamplePlugin": {
"qtype": "int8"
}
}
}
// Resize依據經驗一般情況下不需要用到fp16精度,且fp16速度較慢,因此建議默認配置int8
// 公版GridSample和horizon 版本GridSamplePlugin都不支持fp16輸入,因此需要手動回退int8,避免被lower到cpu- 先生成模版:hb\_compile --fast-perf --model xxx.onnx --march nash-p,默認生成在。fast\_perf/隱藏目錄下
- 修改 config:
sed -i 's/remove_node_type: .*/remove_node_type: Quantize;Dequantize/' .fast_perf/xxx_config.yaml
sed -i 's/optimization: run_fast/calibration_type: skip/' .fast_perf/xxx_config.yaml
awk '/calibration_type: skip/ { print; print " quant_config: ./fp16.json"; next } 1' .fast_perf/xxx_config.yaml > temp.yaml- 編譯:hb\_compile --config temp.yaml
評測其他精度,如全 int16,softmax/layernorm fp16 等,修改上面的 fp16.json 文件即可,配置方式詳細説明請參考用户手冊 - 訓練後量化(PTQ)- quant\_config 説明。
4.1.3 板端模型性能測試工具
- 進入 OE 包目錄:samples/ucp\_tutorial/tools/hrt\_model\_exec,編譯:
sh build_aarch64.sh- 將結果文件夾中的 output\_shared\_J6\_aarch64/aarch64/bin/hrt\_model\_exec 以及 output\_shared\_J6\_aarch64/aarch64/lib 拷貝到板端的{path}下。
- 新建/修改 setup.sh 文件:
#!/bin/sh
#配置hrt_model_exec所在路徑
export PATH={path}:${PATH}
#配置.so所在路徑
export LD_LIBRARY_PATH={path}/lib:${LD_LIBRARY_PATH}- 執行
source setup.sh,就可在板子上使用 hrt\_model\_exec 文件了 - 評測模型延時常用命令:
hrt_model_exec perf --model_file xxx.hbm --thread_num 1 --frame_count 10004.2 性能分析及優化
相較於征程 6E/M,征程 6H/P 額外需要考慮的是引入了 FP 計算耗時以及多核的帶寬爭搶。
與平台無關,早期評測時建議參考上一章獲取模型性能情況,後續量產過程中進行精度調試之前也建議先測試一下性能,並完成性能優化(部分性能優化策略可能數學不等價,導致需要重訓浮點或 qat)。性能分析和優化建議參考如下步驟:
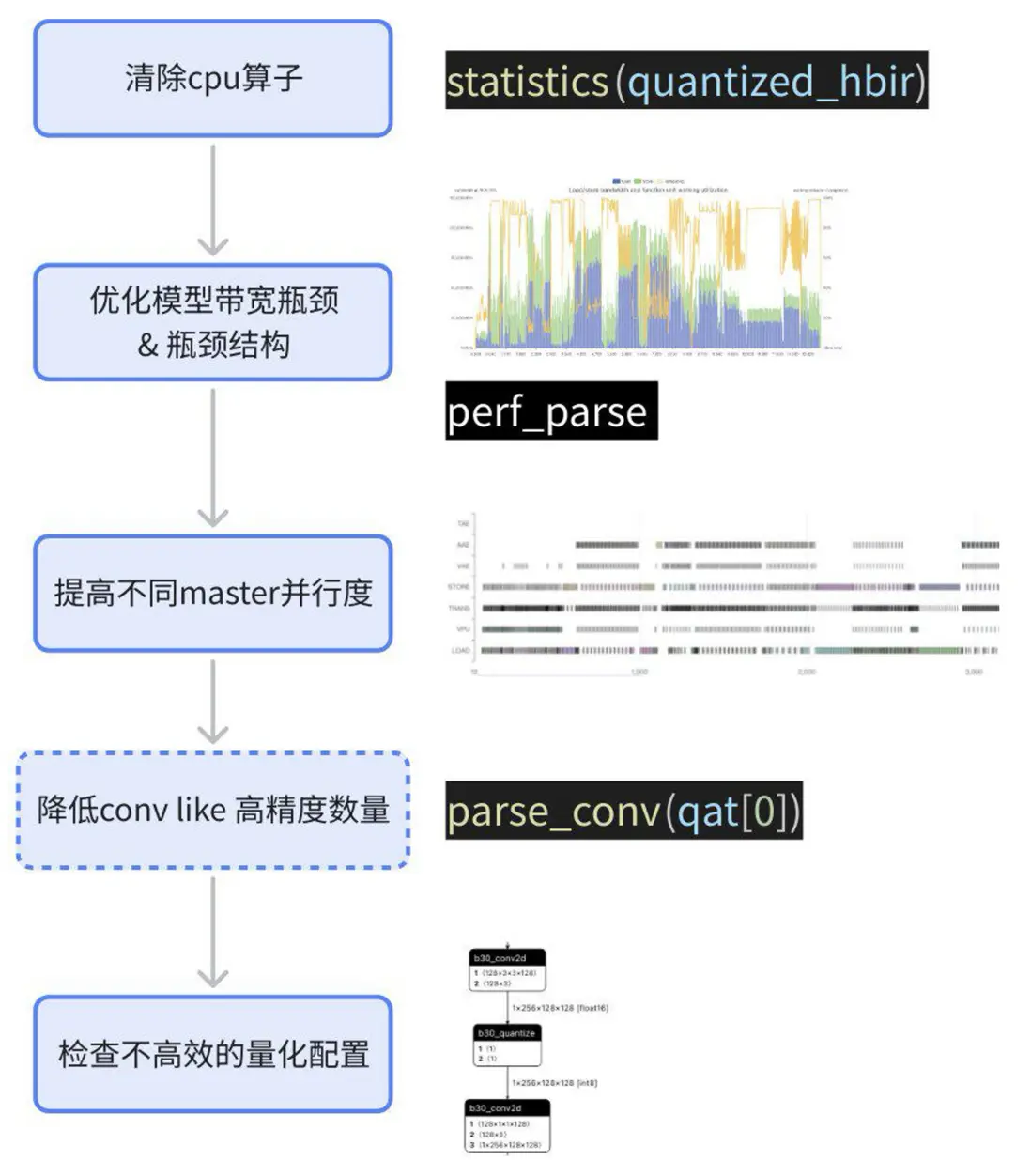
具體分析和優化過程請見《征程 6 性能分析帶寬優化》。
4.3 量化訓練
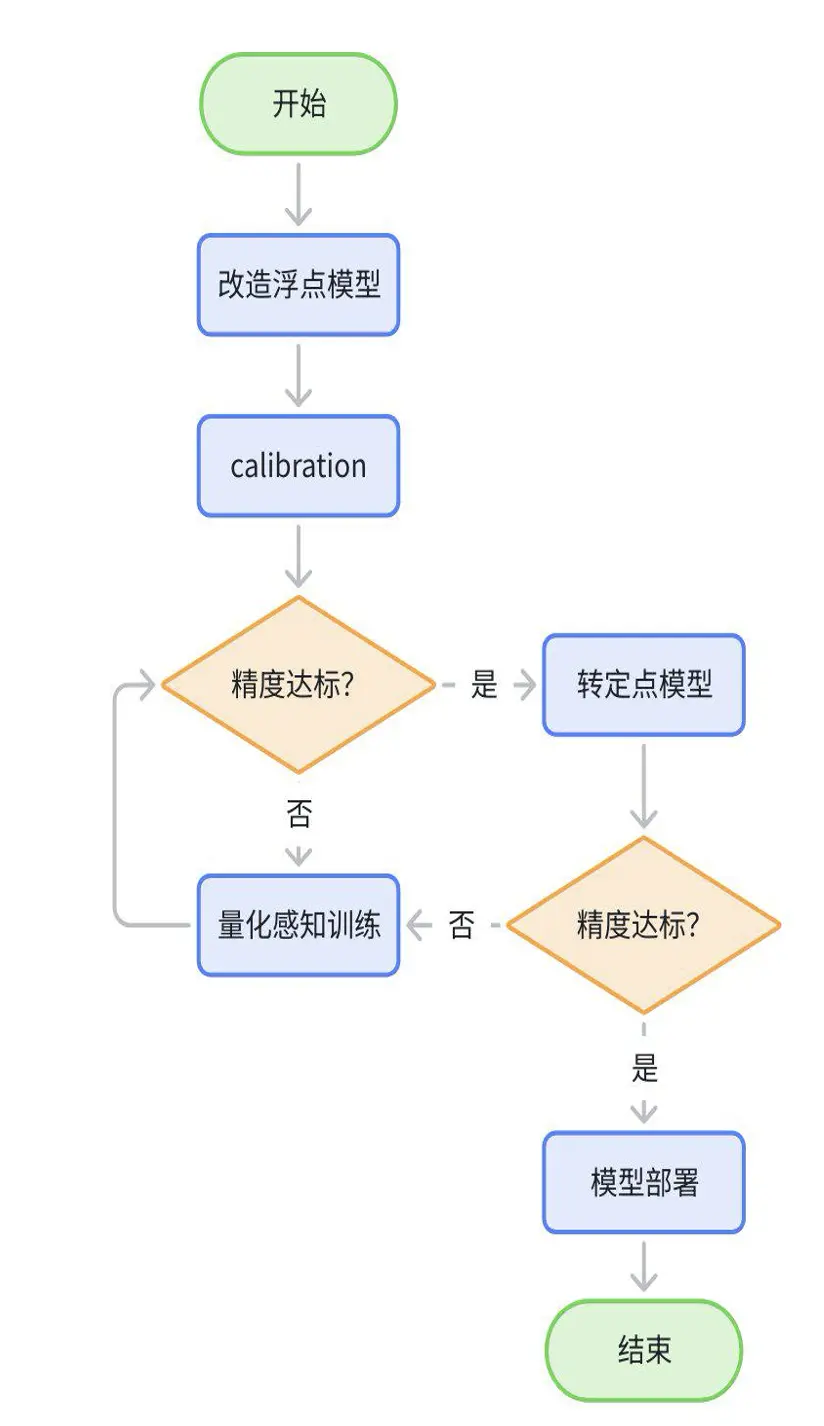
整個量化訓練的過程,大致為如下流程:
- 改造浮點模型:在輸入的地方插入 QuantStub,輸出插入 DequantStub,標記模型需要量化的結構;
- calibration 一個 step 後導出 qat.bc,確認結構是否完整,是否有多餘的結構,是否有不符合預期的 cpu 節點;
- 配置 GEMM 雙 int16+ 其他 float16 做 calibraion,調整訓練參數,fix scale 等直至無限接近浮點。若精度崩掉則先排查流程問題;精度達標的情況下,若延時也滿足預期,則量化訓練結束;
- 配置 GEMM 雙 int8+ 其他 float16 做 calibraion,精度不達標的話進入精度 debug 的流程;若精度達標則量化訓練結束;
- calibration 精度達到浮點 95% 以上,還想繼續提升精度的話,可以進行 qat 訓練;個別模型 calibration 精度較低,可通過 qat 訓練得到較大提升;
- 測試 quantized.bc 或者 hbm 精度確認是否達標。
from horizon_plugin_pytorch.quantization import prepare, QuantStub
from torch.quantization import DeQuantStub
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import observer_v2, get_qconfig
from horizon_plugin_pytorch.dtype import qint16, qint8
from horizon_plugin_pytorch.march import March, set_march
import torch
from torchvision.models.mobilenetv2 import MobileNetV2
from horizon_plugin_pytorch.quantization.hbdk4 import export
from hbdk4.compiler import save, load, convert, compile
class QATReadyMobileNetV2(MobileNetV2):
def __init__(
self,
num_classes: int = 10,
width_mult: float = 1.0,
inverted_residual_setting: Optional[List[List[int]]] = None,
round_nearest: int = 8,
):
super().__init__(
num_classes, width_mult, inverted_residual_setting, round_nearest
)
self.quant = QuantStub()
self.dequant = DeQuantStub()
def forward(self, x: Tensor) -> Tensor:
x = self.quant(x)
x = super().forward(x)
x = self.dequant(x)
return x
# 1.準備浮點模型
float_model = QATReadyMobileNetV2()
float_state_dict = torch.load(float_ckpt_path)
float_model.load_state_dict(float_state_dict)
# 2.數據校準
set_march("nash-p") # 在prepare之前設置計算架構
qconfig_template = [
ModuleNameTemplate({"": torch.float16}), # 全局 feat fp16
MatmulDtypeTemplate( # gemm int8 input
input_dtypes=[qint8, qint8],
),
ConvDtypeTemplate( # gemm int8 input
input_dtype=qint8,
weight_dtype=qint8,
),
]
calibration_qconfig_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig(observer=observer_v2.MSEObserver),
templates=qconfig_template,
enable_optimize = True,
save_dir = "./qconfig",
)
calib_model = prepare(
float_model, example_input, calibration_qconfig_qconfig_setter
)
calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.CALIBRATION)
calibrate(calib_model)
# 評測數據校準精度
calib_model.eval()
set_fake_quantize(calib_model, FakeQuantState.VALIDATION)
evaluate(calib_model)
torch.save(calib_model.state_dict(), "calib-checkpoint.ckpt")
# 3.量化訓練(若數據校準精度已達標,可跳過該步驟)
qat_qconfig_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig(observer=observer_v2.MinMaxObserver),
templates=qconfig_template,
enable_optimize = True,
save_dir = "./qconfig",
)
qat_model = prepare(
float_model, example_input, qat_qconfig_qconfig_setter
)
qat_model.load_state_dict(calib_model.state_dict())
qat_model.train()
set_fake_quantize(qat_model, FakeQuantState.QAT)
train(qat_model)
# 評測量化訓練精度
qat_model.eval()
set_fake_quantize(qat_model, FakeQuantState.VALIDATION)
evaluate(qat_model)
# 4.模型導出
hbir_qat_model = export(qat_model, example_input, name="mobilenetv2", input_names=("input_name1","input_name2"), output_names=("output_name1","output_name2"), native_pytree=False)
save(hbir_qat_model, "qat.bc")
quantized_hbir = convert(hbir_qat_model, march="nash-p")
# 5.模型編譯
compil(quantized_hbir,march="nash-p", path="model.hbm")需要注意的是導出 qat.bc 模型時,建議指定一下模型輸入輸出節點名稱以及模型名字,便於應用集成和後續 trace 分析,也避免 hbm 精度評測時同時加載多個名字相同的模型出錯。

4.3.2 典型量化配置
4.3.2.1 基礎模版(GEMM 雙 int8+ 其他 float16 )
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import observer_v2
from horizon_plugin_pytorch.dtype import qint16, qint8
import torch
model_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig( # 1. 主要用於獲取 observer
observer=(
observer_v2.MSEObserver if is_calib else observer_v2.MinMaxObserver
)
),
templates=[
ModuleNameTemplate({"": torch.float16}), # 全局 feat fp16
MatmulDtypeTemplate( # gemm int8 input
input_dtypes=[qint8, qint8],
),
ConvDtypeTemplate( # gemm int8 input
input_dtype=qint8,
weight_dtype=qint8,
),
],
enable_optimize = True,
save_dir = "./qconfig", # qconfig 保存路徑,有默認值,用户可以改
)4.3.2.2 添加 fix scale(pyramid 和 resizer 輸入請關注)
部署時模型輸入來源為 pyramid 和 resizer 的模型,需要輸入節點量化精度配置為 int8 類型,另外這類輸入一般是經過歸一化的,數值範圍在[-1,1]或者[0,1],因此建議可以直接設置 fix scale。
此外還有一些模型中的節點有明確物理含義,建議也手動配置 fix scale,避免 qat 過程滑動取平均導致部分有效值域不完整。
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import observer_v2
from horizon_plugin_pytorch.dtype import qint16, qint8
import torch
model_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig( # 1. 主要用於獲取 observer
observer=(
observer_v2.MSEObserver if is_calib else observer_v2.MinMaxObserver
)
),
templates=[
ModuleNameTemplate({
"": torch.float16,
"backbone.quant": {"dtype": qint8, "threshold": 1.0},
}), # 全局 feat fp16,輸入節點配置int8,且固定scale=1.0/128
MatmulDtypeTemplate(
input_dtypes=[qint8, qint8],
),
ConvDtypeTemplate( # gemm int8 input
input_dtype=qint8,
weight_dtype=qint8,
),
],
enable_optimize = True,
save_dir = "./qconfig", # qconfig 保存路徑,有默認值,用户可以改
)4.3.2.3 通過敏感度增加高精度配置
敏感度文件 *sensitive_ops.pt 生成方式請見下一節-精度調優流程
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import observer_v2
from horizon_plugin_pytorch.dtype import qint16, qint8
import torch
model_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig( # 1. 主要用於獲取 observer
observer=(
observer_v2.MSEObserver if is_calib else observer_v2.MinMaxObserver
)
),
templates=[
ModuleNameTemplate({"": torch.float16}), # 全局 feat fp16
MatmulDtypeTemplate( # gemm int8 input
input_dtypes=[qint8, qint8],
),
ConvDtypeTemplate( # gemm int8 input
input_dtype=qint8,
weight_dtype=qint8,
),
SensitivityTemplate(
sensitive_table=torch.load("debug/output_0_ATOL_sensitive_ops.pt"),
topk_or_ratio=10,# top10敏感節點配置int16
)
],
enable_optimize = True,
save_dir = "./qconfig", # qconfig 保存路徑,有默認值,用户可以改
)4.3.2.4 多階段模型量化配置
若多階段模型在浮點訓練時就是分開訓的,則 qat 保持和浮點節點一致分為多階段訓練。第一階段按照前面的配置正常 calib 就好(不要 qat,除非 calib 精度實在是達標不了,qat 之後權重變了,二階段需要 finetune 浮點),二階段使用如下方式,將一階段設置成浮點,僅量化二階段:
from horizon_plugin_pytorch.quantization.qconfig_setter import *
from horizon_plugin_pytorch.quantization import observer_v2
from horizon_plugin_pytorch.dtype import qint16, qint8
import torch
stage2 = ["bev_stage2_vehicle_head.head","bev_stage2_vrumerge_head.head"]
model_qconfig_setter = QconfigSetter(
reference_qconfig=get_qconfig( # 1. 主要用於獲取 observer
observer=(
observer_v2.MSEObserver if is_calib else observer_v2.MinMaxObserver
)
),
templates=[
ModuleNameTemplate({"": torch.float32}), # 全局 feat fp32
ModuleNameTemplate(
{n: torch.float16 for n in stage2},# stage2為二階段模型節點的關鍵字
),
MatmulDtypeTemplate( # gemm int8 input
input_dtypes=[qint8, qint8],
),
ConvDtypeTemplate( # gemm int8 input
input_dtype=qint8,
weight_dtype=qint8,
),
],
enable_optimize = True,
save_dir = "./qconfig", # qconfig 保存路徑,有默認值,用户可以改
)若想要一階段和二階段連接部分的 scale 相同,則 qat 階段不要在兩階段連接部分加量化反量化,僅在導出模型時添加:
class EncoderModule(nn.Module):
def __init__(self, ) -> None:
super().__init__()
self.dequant = DeQuantStub()
self.conv = ConvModule(...)
def forward(self, input1, input2):
input1 = self.conv(input1)
output = input1 + input2
if env.get("EXPORT_DEPLOY", 0) == 1:
return self.dequant(output)
return output
class DecoderModule(nn.Module):
def __init__(self, ) -> None:
super().__init__()
self.quant = QuantStub()
self.conv = ConvModule(...)
def forward(self, data):
if env.get("EXPORT_DEPLOY", 0) == 1:
data = self.quant(data)
data = self.conv(data)
return data
class Model(nn.Module):
def __init__(self, ) -> None:
super().__init__()
self.quant1 = QuantStub()
self.quant2 = QuantStub()
self.dequant = DeQuantStub()
self.encoder = EncoderModule(...)
self.decoder = DecoderModule(...)
def forward(self, input1, input2):
input1 = self.quant1(input1)
input2 = self.quant2(input2)
output = self.encoder(input1, input2)
output = self.decoder(output)
return self.dequant(output)兩階段分別 calibration 完之後,使用如下腳本拼接得到完整的 calibration 權重,使用該權重完成後續的 qat 訓練,若還有第三階段,需要基於二階段 qat 權重 finetune 浮點:
stage1 = [
"backbone",
"bifpn_neck",
"bev_stage1_head",
]
e2e_stage2 = [
"task_bev_encoder.bev_quant_stub",
"task_bev_encoder.bev_encoder.dynamic",
"e2e_vehicle_head.head",
"e2e_vrumerge_head.head",
]
def filter_ckpt(ckpt, prefix, exclude=[]):
new_ckpt = OrderedDict()
new_ckpt["state_dict"] = OrderedDict()
new_ckpt["state_dict"]._metadata = OrderedDict()
for k in ckpt["state_dict"].keys():
if any([k.startswith(key) for key in prefix]) and not any([k.startswith(key) for key in exclude]):
new_ckpt["state_dict"][k] = ckpt["state_dict"][k]
for k in ckpt["state_dict"]._metadata.keys():
if any([k.startswith(key) for key in prefix]) and not any([k.startswith(key) for key in exclude]):
new_ckpt["state_dict"]._metadata[k] = ckpt["state_dict"]._metadata[k]
return new_ckpt
def merge_ckpt_func(ckpt_list):
new_ckpt = OrderedDict()
new_ckpt["state_dict"] = OrderedDict()
new_ckpt["state_dict"]._metadata = OrderedDict()
for ckpt in ckpt_list:
new_ckpt["state_dict"].update(ckpt["state_dict"])
new_ckpt["state_dict"]._metadata.update(ckpt["state_dict"]._metadata)
return new_ckpt
stage1_ckpt = filter_ckpt(torch.load(stage1_calibration_checkpoint_path, map_location="cpu"), stage1)
e2e_stage2_3_ckpt = filter_ckpt(torch.load(e2e_calibration_checkpoint_path, map_location="cpu"), e2e_stage2)
merge_ckpt = merge_ckpt_func([stage1_ckpt, e2e_stage2_3_ckpt])
torch.save(merge_ckpt, "merged_stage1-stage2.pth.tar")4.3.3 精度調優流程
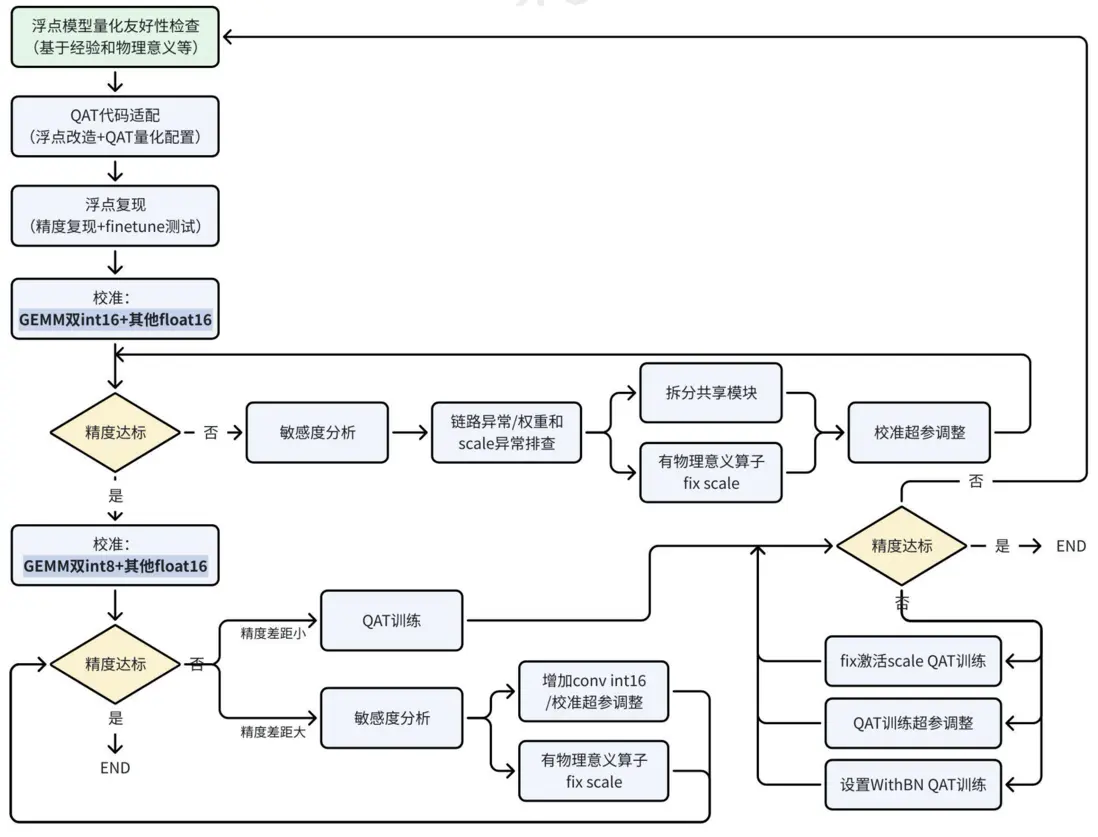
由於征程 6H/P 上大多數 vector 計算,int16 精度和 float16 精度計算速度相當,因此建議 vector 計算精度直接使用 float16,可有效減小量化調優的難度,提升迭代效率。若在其他平台上有全 int8 部署經驗,或依據經驗判斷模型全 int8(或加少量 int16)無精度風險,為追求極致幀率,可不使用 float16。如下為征程 6H/P 的量化調優建議流程:
4.3.4 部署模型編譯
由於模型輸入輸出格式訓練和部署時可能存在區別,因此工具鏈提供了一些 api 用於在量化訓練後調整模型以適配部署要求。差異主要是在圖像輸入格式,以及是否需要刪除首尾量化反量化節點這兩個方面。
4.3.4.1 pyramid 或 resizer 輸入
該操作請在 convert 前完成,且 qat 訓練時對應輸入節點的 quant 需要是 int8 量化。下圖為訓練和部署編譯時模型輸入的差異:
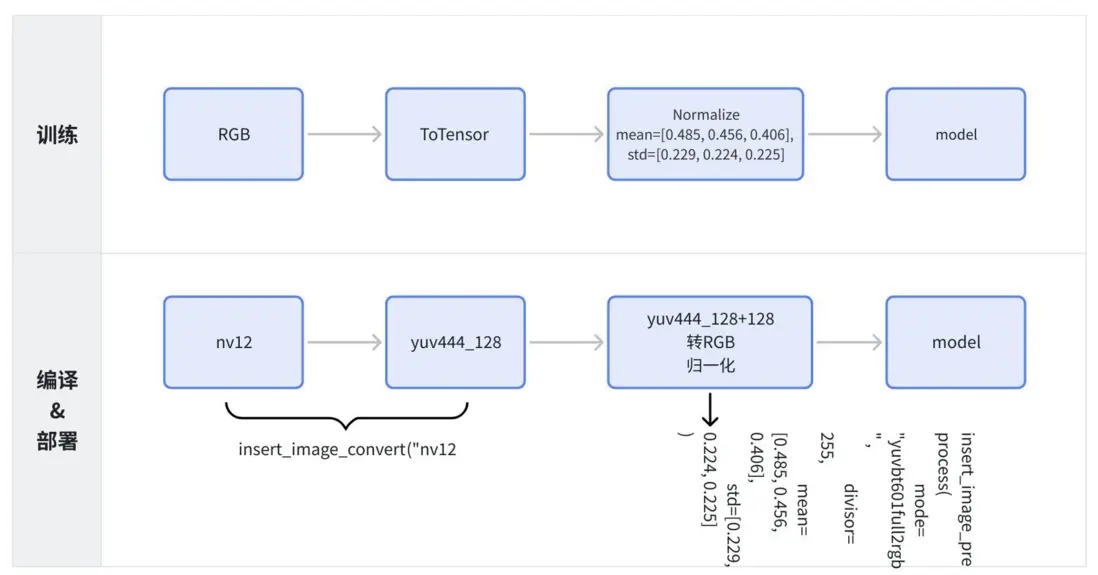
將如下代碼加到編譯生成 hbm 的流程中,只需指定需要修改為 pyramid/resizer 的節點名字即可(注意 type 為訓練時候的數據格式,mean 和 std 也需要結合訓練前處理代碼做配置)
from hbdk4.compiler import load
model = load("qat_model.bc")
func = model[0]
resizer_input = ["input0"] # 部署時數據來源於resizer的輸入節點名稱列表
pyramid_input = ["input3"] # 部署時數據來源於pyramid的輸入節點名稱列表
def channge_source(node, input_source, preprocess):
mode = preprocess["type"]
if mode == "rgb":
mode = "yuvbt601full2rgb"
elif mode == "bgr":
mode = "yuvbt601full2bgr"
elif mode == "yuv":
mode = None
divisor = preprocess["divisor"]
mean = preprocess["mean"]
std = preprocess["std"]
node = node.insert_transpose(permutes=[0, 3, 1, 2])
print(mode,divisor,mean,std)
node = node.insert_image_preprocess(mode=mode, divisor=divisor, mean=mean, std=std)
if input_source == "pyramid":
node.insert_image_convert("nv12")
elif input_source == "resizer":
node.insert_roi_resize("nv12")
for input in func.flatten_inputs[::-1]:
if input.name in pyramid_input:
if input.type.shape[0] > 1:
split_inputs = input.insert_split(0)
for split_input in reversed(split_inputs):
channge_source(split_input, "pyramid", {"type":"yuv","divisor":1,"mean":[128, 128, 128],"std":[128, 128, 128]})
elif input.name in resizer_input:
if input.type.shape[0] > 1:
split_inputs = input.insert_split(0)
for split_input in reversed(split_inputs):
channge_source(split_input, "resizer", {"type":"yuv","divisor":1,"mean":[128, 128, 128],"std":[128, 128, 128]})insert_image_preprocess 方法包括以下參數:
-
mode,可選值包含:"yuvbt601full2rgb"YUVBT601Full 轉 RGB (默認)"yuvbt601full2bgr"YUVBT601Full 轉 BGR"yuvbt601video2rgb"YUVBT601Video 轉 RGB 模式"yuvbt601video2bgr"YUVBT601Video 轉 BGR 模式"bgr2rgb"BGR 轉 RGB"rgb2bgr"RGB 轉 BGR"none"不進行圖像格式的轉換,僅進行 preprocess 處理
- 數據轉換除數
divisor,int 類型,默認為 255 - 均值
mean,double 類型,長度與輸入 c 方向對齊,默認為 [0.485, 0.456, 0.406] - 標準差值
std,double 類型,長度與輸入 c 方向對齊,默認為 [0.229, 0.224, 0.225]
4.3.4.2 算子刪除
該操作需要在 convert 後完成,因為 convert 前模型都還是浮點輸入輸出,沒有生成量化反量化節點:
quantized_model = convert(qat_model, march)
# remove_io_op會遞歸刪除所有可被刪除的節點
quantized_model[0].remove_io_op(op_types = ["Dequantize","Quantize","Cast","Transpose","Reshape"])若進行了刪除動作,需要在後處理中根據業務需要進行功能補全,例如實現量化、反量化的邏輯。
量化計算參考代碼:
torch.clamp(torch.round(x/scales), min=int16_min, max=int16_max).type(torch.int16)float32_t _round(float32_t input) {
std::fesetround(FE_TONEAREST);
float32_t result = nearbyintf(input);
return result;
}
inline T int_quantize(float32_t value, float32_t scale, float32_t zero_point,
float32_t min, float32_t max) {
value = _round(value / scale + zero_point);
value = std::min(std::max(value, min), max);
return static_cast<T>(value);
}如果並不想去掉模型所有的量化反量化,只想刪掉個別輸入輸出節點相連的 op,可採用下面的方法刪除與某輸入/輸出節點直接相連的節點:
def remove_op_by_ioname(func, io_name=None):
for loc in func.inputs + func.outputs:
if not loc.is_removable[0]:
if io_name == loc.name:
raise ValueError(f"Failed when deleting {io_name} ,which id unremovable")
continue
attached_op = loc.get_attached_op[0]
removed = None
output_name = attached_op.outputs[0].name
input_name = attached_op.inputs[0].name
if io_name in [output_name, input_name]:
removed, diagnostic = loc.remove_attached_op()
if removed is True:
print(f"Remove node {io_name} successfully",flush=True)
if removed is False:
raise ValueError(
f"Failed when deleting {attached_op.name} operator,"
f"error: {diagnostic}")
remove_op_by_ioname(func,"_input_0")
remove_op_by_ioname(func,"_output_0")4.3.5 定點模型精度評測
由於 qat 還是偽量化模型,從偽量化轉換真正的定點模型有可能會產生誤差,因此建議模型上線之前除了測試 qat torch module 精度之外,再測試一下定點模型的精度。定點模型精度可以基於 quantized.bc 或者。hbm 做測試,quantized.bc 和 hbm 在模型中無 cpu 算子,無 fp32 精度算子的情況下,模型輸出是二進制一致的。
4.3.5.1 quantized.bc 推理
-
python
quantized.bc 推理輸入格式為 dict,支持 tensor 和 np.array,輸出格式與輸入一致。當前只支持 cpu 推理,建議通過多進程加速推理過程。
inputs = {inputs[0].name: Y, inputs[1].name: UV}
hbir_outputs = hbir[0].feed(inputs)-
C++
與推理 hbm 接口使用無任何區別,便於用户在 x86 端測試系統集成效果,具體使用方式請參考後文第五章,。so 替換成 x86 的即可。
4.3.5.2 hbm 推理
由於本地使用 cpu 推理 hbm 速度非常慢,因此工具鏈提供了一個工具方便用户在服務器端給直連的開發板下發推理任務。本文只介紹最簡單的單進程使用方式,多進程、多階段模型輸入輸出傳輸優化,以及統計模型推理、網絡傳輸耗時等請參考用户手冊 <u>hbm\_infer 工具介紹</u>。
hbm_model = HbmRpcSession(
host="xx.xx.xx.xx",
local_hbm_path="xx.hbm", #也可傳入一個list,推理時通過指定model_name來選擇推理哪個模型,可只傳輸一次推理所用的.so
# core_id=2, #綁核推理,推理開啓L2M模型時建議綁核,與環境變量對應
# extra_server_cmd="export HB_DNN_USER_DEFINED_L2M_SIZES=0:0:12:0" # L2M模型推理所需環境變量
)
# 打印模型輸入輸出信息
hbm_model.show_input_output_info()
# 準備輸入數據
input_data = {
'img': torch.ones((1, 3, 224, 224), dtype=torch.int8)
}
# 執行推理並返回結果
output_data = hbm_model(input_data)
# 若傳入的是list,需要正確指定model_name
# output_data = hbm_model(input_data, model_name=model_name)
print([output_data[k].shape for k in output_data])
# 關閉server
hbm_model.close_server()4.3.5.3 pyramid 輸入模型測試建議
對於 pyramid 模型,由於部署和訓練輸入格式不一致,因此若要使用插入前處理節點後的 quantized.bc 或者 hbm 做精度測試的話,需要適配一下前處理代碼,需要注意的是,把訓練時的 rgb/bgr/yuv444 轉換成 nv12,是存在信息損失的,若模型訓練的時候前處理沒有帶上轉 nv12 的過程,則有可能對這樣的信息損失不夠魯棒,出現掉點的現象。因此若 pyramid 輸入定點模型掉點超出預期,需要再測試一下不插入前處理節點的模型精度,若的確是 nv12 帶來的損失,建議修改模型前處理重訓浮點。
如下為將浮點模型輸入 data 處理為 deploy 定點模型輸入格式的示例代碼,需要注意的是要修改一下評測前處理,只保留讀圖和 resize 的操作,去掉歸一化相關的前處理(這部分通過前文部署模型編譯章節的修改動作已經合入到了模型內部):
def nv12_runtime(data):
import cv2
def img2nv12(input_image):
image = input_image.astype(np.uint8)
image = image.squeeze(0)
image = np.transpose(image, (1, 2, 0))
height, width = image.shape[0], image.shape[1]
# 若讀出的圖片為BGR格式,請做對應修改
yuv420p = cv2.cvtColor(image, cv2.COLOR_RGB2YUV_I420).reshape(
(height * width * 3 // 2,)
)
y = yuv420p[: height * width]
uv_planar = yuv420p[height * width :].reshape((2, height * width // 4))
uv_packed = uv_planar.transpose((1, 0)).reshape((height * width // 2,))
return torch.tensor(
y.reshape(1, height, width, 1), dtype=torch.uint8
), torch.tensor(
uv_packed.reshape(1, height // 2, width // 2, 2), dtype=torch.uint8
)
dict_data = {}
for key in data.keys():
if data[key].shape[0] == 1:
dict_data[f"{key}_y"], dict_data[f"{key}_uv"] = img2nv12(
data[key].cpu().numpy()
)
else:
for i in range(data[key].shape[0]):
(
dict_data[f"{key}_{i}_y"],
dict_data[f"{key}_{i}_uv"],
) = img2nv12(data[key][i : i + 1, :, :, :].cpu().numpy())
return dict_data
input_6v_deploy = nv12_runtime(input_6v_float)5.模型部署
5.1 UCP 簡介
UCP(Unify Compute Platform,統一計算平台)定義了一套統一的異構編程接口, 將 SOC 上的功能硬件抽象出來並進行封裝,對外提供基於功能的 API 進行調用。UCP 提供的具體功能包括:視覺處理(Vision Process)、神經網絡模型推理(Neural Network)、高性能計算庫(High Performance Library)、自定義算子插件開發。
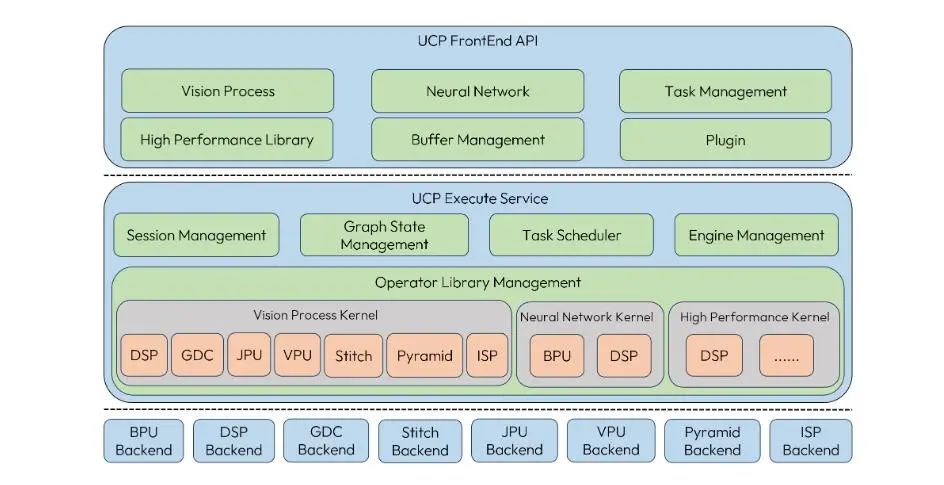
UCP 支持的 Backbend:

5.2 模型推理快速上手
使用 UCP 推理模型的基本代碼參考如下,詳細信息可參考用户手冊《<u>統一計算平台-模型推理開發</u>》、《<u>模型部署實踐指導-模型部署實踐指導實例</u>》、《<u>UCP 通用 API 介紹</u>》等相關章節。
// 1. 加載模型並獲取模型名稱列表以及Handle
{
hbDNNInitializeFromFiles(&packed_dnn_handle, &modelFileName, 1);
hbDNNGetModelNameList(&model_name_list, &model_count, packed_dnn_handle);
hbDNNGetModelHandle(&dnn_handle, packed_dnn_handle, model_name_list[0]);
}
// 2. 根據模型的輸入輸出信息準備張量
std::vector<hbDNNTensor> input_tensors;
std::vector<hbDNNTensor> output_tensors;
int input_count = 0;
int output_count = 0;
{
hbDNNGetInputCount(&input_count, dnn_handle);
hbDNNGetOutputCount(&output_count, dnn_handle);
input_tensors.resize(input_count);
output_tensors.resize(output_count);
prepare_tensor(input_tensors.data(), output_tensors.data(), dnn_handle);
}
// 3. 準備輸入數據並填入對應的張量中
{
read_data_2_tensor(input_data, input_tensors);
// 確保更新輸入後進行Flush操作以確保BPU使用正確的數據
for (int i = 0; i < input_count; i++) {
hbUCPMemFlush(&input_tensors[i].sysMem, HB_SYS_MEM_CACHE_CLEAN);
}
}
// 4. 創建任務並進行推理
{
// 創建任務
hbDNNInferV2(&task_handle, output_tensors.data(), input_tensors.data(), dnn_handle)
// 提交任務
hbUCPSchedParam sched_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sched_param);
sched_param.backend = HB_UCP_BPU_CORE_ANY;
hbUCPSubmitTask(task_handle, &sched_param);
// 等待任務完成
hbUCPWaitTaskDone(task_handle, 0);
}
// 5. 處理輸出數據
{
// 確保處理輸出前進行Flush操作以確保讀取的不是緩存中的髒數據
for (int i = 0; i < output_count; i++) {
hbUCPMemFlush(&output_tensors[i].sysMem, HB_SYS_MEM_CACHE_INVALIDATE);
}
// 對輸出進行後處理操作
}
// 6. 釋放資源
{
// 釋放任務
hbUCPReleaseTask(task_handle);
// 釋放輸入內存
for (int i = 0; i < input_count; i++) {
hbUCPFree(&(input_tensors[i].sysMem));
}
// 釋放輸出內存
for (int i = 0; i < output_count; i++) {
hbUCPFree(&(output_tensors[i].sysMem));
}
// 釋放模型
hbDNNRelease(packed_dnn_handle);
}5.3 Pyramid/Resizer 模型輸入準備説明
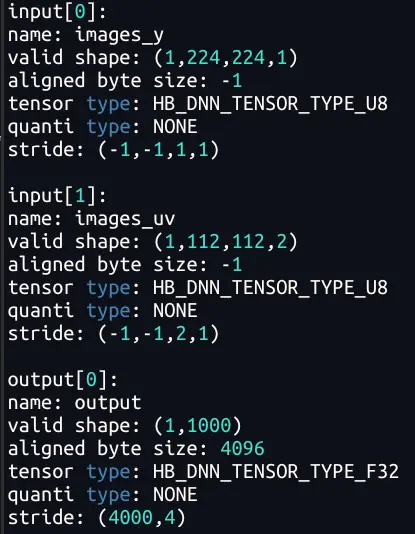
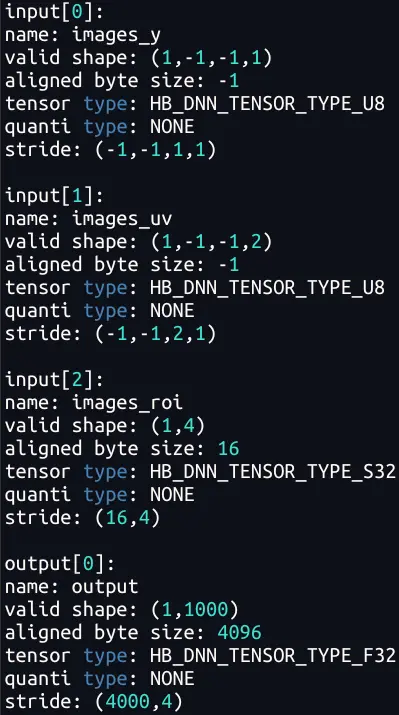
由於 Pyramid/Resizer 模型相對特殊,其輸入是動態 shape/stride,因此單獨介紹一下其輸入 tensor 準備的注意事項和技巧。下表是解析 Pyramid/Resizer 模型觀察到的現象(-1 為佔位符,表示為動態,Pyramid 輸入的 stride 為動態;Resizer 輸入的 H、W、stride 均為動態。) :
Resizer 輸入的 HW 動態,是因為原始輸入的大小可以是任意的;
Pyramid/Resizer 輸入的 stride 動態,可以理解為是支持 Crop 功能(後文 5.4.1 節)


hrt\_model\_exec model\_info
板端可執行程序工具
在征程 6H/P 平台上要求 Pyramid/Resizer 輸入必須滿足 W64 對齊,因此無論是金字塔配置還是模型輸入準備,都需要滿足對齊要求。
輸入 tensor 準備:
#define ALIGN(value, alignment) (((value) + ((alignment)-1)) & ~((alignment)-1))
#define ALIGN_64(value) ALIGN(value, 64)
int prepare_image_tensor(const std::vector<hbUCPSysMem> &image_mem, int input_h,
int input_w, hbDNNHandle_t dnn_handle,
std::vector<hbDNNTensor> &input_tensor) {
// 準備Y、UV輸入tensor
for (int i = 0; i < 2; i++) {
HB_CHECK_SUCCESS(hbDNNGetInputTensorProperties(&input_tensor[i].properties,
dnn_handle, i),
"hbDNNGetInputTensorProperties failed");
// auto w_stride = ALIGN_64(input_w);
// int32_t y_mem_size = input_h * w_stride;
input_tensor[i].sysMem[0] = image_mem[i];
// 配置原圖大小,NHWC
input_tensor[i].properties.validShape.dimensionSize[1] = input_h;
input_tensor[i].properties.validShape.dimensionSize[2] = input_w;
if (i == 1) {
// UV輸入大小為Y的1/2
input_tensor[i].properties.validShape.dimensionSize[1] /= 2;
input_tensor[i].properties.validShape.dimensionSize[2] /= 2;
}
// stride滿足64對齊
input_tensor[i].properties.stride[1] =
ALIGN_64(input_tensor[i].properties.stride[2] *
input_tensor[i].properties.validShape.dimensionSize[2]);
input_tensor[i].properties.stride[0] =
input_tensor[i].properties.stride[1] *
input_tensor[i].properties.validShape.dimensionSize[1];
}
return 0;
}
// 準備roi輸入tensor
int prepare_roi_tensor(const hbUCPSysMem *roi_mem, hbDNNHandle_t dnn_handle,
int32_t roi_tensor_id, hbDNNTensor *roi_tensor) {
HB_CHECK_SUCCESS(hbDNNGetInputTensorProperties(&roi_tensor->properties,
dnn_handle, roi_tensor_id),
"hbDNNGetInputTensorProperties failed");
roi_tensor->sysMem[0] = *roi_mem;
return 0;
}
int prepare_roi_mem(const std::vector<hbDNNRoi> &rois,
std::vector<hbUCPSysMem> &roi_mem) {
auto roi_size = rois.size();
roi_mem.resize(roi_size);
for (auto i = 0; i < roi_size; ++i) {
int32_t mem_size = 4 * sizeof(int32_t);
HB_CHECK_SUCCESS(hbUCPMallocCached(&roi_mem[i], mem_size, 0),
"hbUCPMallocCached failed");
int32_t *roi_data = reinterpret_cast<int32_t *>(roi_mem[i].virAddr);
roi_data[0] = rois[i].left;
roi_data[1] = rois[i].top;
roi_data[2] = rois[i].right;
roi_data[3] = rois[i].bottom;
hbUCPMemFlush(&roi_mem[i], HB_SYS_MEM_CACHE_CLEAN);
}
return 0;
}金字塔配置:
{
"ds_roi_layer": 2,
"ds_roi_sel": 1,
"ds_roi_start_top": 0,
"ds_roi_start_left": 0,
"ds_roi_region_width": 480,
"ds_roi_region_height": 256,
"ds_roi_wstride_y": 512, // 480不滿足64對齊要求
"ds_roi_wstride_uv": 512, // 480不滿足64對齊要求
"ds_roi_out_width": 480,
"ds_roi_out_height": 256
}5.4 模型部署優化
5.4.1 通過地址偏移完成 crop
場景描述:
- Y: validShape = (1,224,224,1), stride = (-1,-1,1,1)
- UV: validShape = (1,112,112,2), stride = (-1,-1,2,1)
該模型的輸入圖片大小為 224x224,假設有一張 H x W = 376 x 384(其中 W 存在大小為 8 的 padding,因為 nv12 需要 W64 對齊)的圖片,可以直接基於 stride 值進行 crop,沒有額外的拷貝開銷

Crop 功能使用:
原始圖片 Y、UV 的 validShape、stride、指針如下:
- Y: validShape = (1, 376, 384, 1), stride = (384*376, 384, 1, 1),內存指針為
y_data - UV: validShape = (1, 188, 192, 2), stride = (384*188, 384, 2, 1),內存指針為
uv_data
模型輸入張量準備-Y:
- Crop 起始點 [h, w] = [50, 64],則: 地址偏移為
y_offset=50*384+ 64*1,內存指針為y_data+y_offset - 模型輸入應設置為
validShape=(1,224,224,1),stride = (224*384,384,1,1)
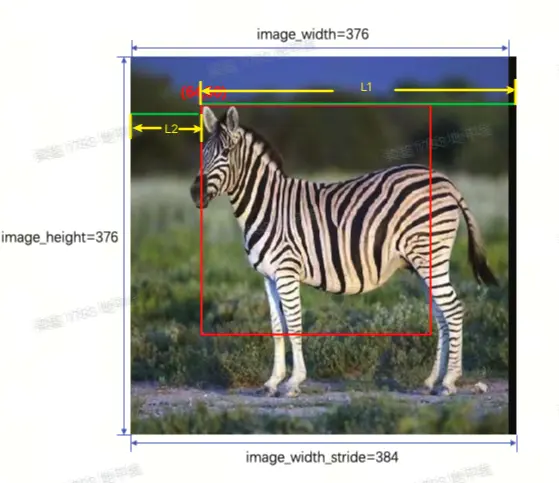
模型輸入張量準備-UV:
- 由於 UV 尺寸為 Y 的 1/2,因此裁剪起始點為 [25, 32],則: 地址偏移為
uv_offset=25*384+ 32*2,內存指針為uv_data+uv_offset - 模型輸入應設置為
validShape=(1,112,112,2),stride = (112*384,384,2,1)
Crop 限制條件:
- 圖像:要求分辨率 ≥ 模型輸入,
w_stride需要 64 字節對齊 - 模型:要求輸入 validShape 為固定值,stride 為動態值,這樣能通過控制 stride 的大小對圖像進行 Crop
- 裁剪位置:由於裁剪是對圖像內存進行偏移,而對於輸入內存的首地址要求 64 對齊
示例:
ucp_tutorial/dnn/basic_samples/code/02_advanced_samples/crop/src/main.cc5.4.2 小模型批處理
由於 BPU 是資源獨佔式硬件,所以對於 Latency 很小的模型而言,其框架調度開銷佔比會相對較大。在 征程 6 平台,UCP 支持通過複用 task\_handle 的方式,將多個小模型任務一次性下發,全部執行完成後再一次性返回,從而可將 N 次框架調度開銷合併為 1 次,以下為參考代碼:
// 獲取模型指針並存儲
std::vector<hbDNNHandle_t> model_handles;
// 準備各個模型的輸入輸出,準備過程省略
std::vector<std::vector<hbDNNTensor>> inputs;
std::vector<std::vector<hbDNNTensor>> outputs;
// 創建任務並進行推理
{
// 創建並添加任務,複用task_handle
hbUCPTaskHandle_t task_handle{nullptr};
for(size_t task_id{0U}; task_id < inputs.size(); task_id++){
hbDNNInferV2(&task_handle, outputs[task_id].data(), inputs[task_id].data(), model_handles[i]);
}
// 提交任務
hbUCPSchedParam sche_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&sche_param);
sche_param.backend = HB_UCP_BPU_CORE_ANY;
hbUCPSubmitTask(task_handle, &sche_param);
// 等待任務完成
hbUCPWaitTaskDone(task_handle, 0);
}5.4.3 優先級調度/搶佔
UCP 支持任務優先級調度和搶佔,可通過 hbUCPSchedParam 結構體進行配置,其中:
priority>customId> submit\_time(任務提交時間)-
priority支持 [0, 255],對於模型任務而言:- [0, 253] 為普通優先級,不可搶佔其他任務,但在未執行時支持按優先級進行排隊
- 254 為 high 搶佔任務,可支持搶佔普通任務
- 255 為 urgent 搶佔任務,可搶佔普通任務和 high 搶佔任務
- 可被中斷搶佔的低優任務,需要在模型編譯階段配置
max_time_per_fc參數拆分模型指令
- 其他 backend 任務,priority 支持 [0, 255],但不支持搶佔,可以認為都是普通優先級
5.5 DSP 開發
為了簡化用户開發,UCP 封裝了一套基於 RPC 的開發框架,來實現 CPU 對 DSP 的功能調用,但具體 DSP 算子實現仍是調用 Cadence 接口去做開發。總體來説可分為三個步驟:
- 使用 Cadence 提供的工具及資料完成算子開發;
int test_custom_op(void *input, void *output, void *tm) {
// custom impl
return 0;
}- DSP 側通過 UCP 提供的 API 註冊算子,編譯帶自定義算子的鏡像;
// dsp鏡像中註冊自定義算子
hb_dsp_register_fn(cmd, test_custom_op, latency)- ARM 側通過 UCP 提供的算子調用接口,完成開發板上的部署使用。
// 將輸入輸出的hbUCPSysMem映射為DSP可訪問的內存地址
hbUCPSysMem in;
hbUCPMalloc(&in, in_size, 0)
hbDSPAddrMap(&in, &in)
hbUCPSysMem out;
hbUCPMalloc(&out, out_size, 0)
hbDSPAddrMap(&out, &out)
// 創建並提交DSP任務
hbUCPTaskHandle_t taskHandle{nullptr};
hbDSPRpcV2(&taskHandle, &in, &out, cmd)
hbUCPSchedParam ctrl_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&ctrl_param);
ctrl_param.backend = HB_UCP_DSP_CORE_ANY;
hbUCPSubmitTask(task_handle, &ctrl_param);
// 等待任務完成
hbUCPWaitTaskDone(task_handle, 0);更多信息可見用户手冊《<u>統一計算平台-自定義算子-DSP 算子開發</u>》。
6. 相關基礎知識
若需要了解 nv12 輸入格式,模型量化等基礎知識,可以在開發者社區<u>《地平線算法工具鏈社區資源整合》 </u>(https://developer.horizon.auto/blog/10364)搜索。